드디어 머신러닝 알고리즘으로 들어가려고 한다..설레서 미치겠다.
우선 데이터를 분석하기 전에는 명확한 프로세스가 머리속에 정리되어 있어야 한다.
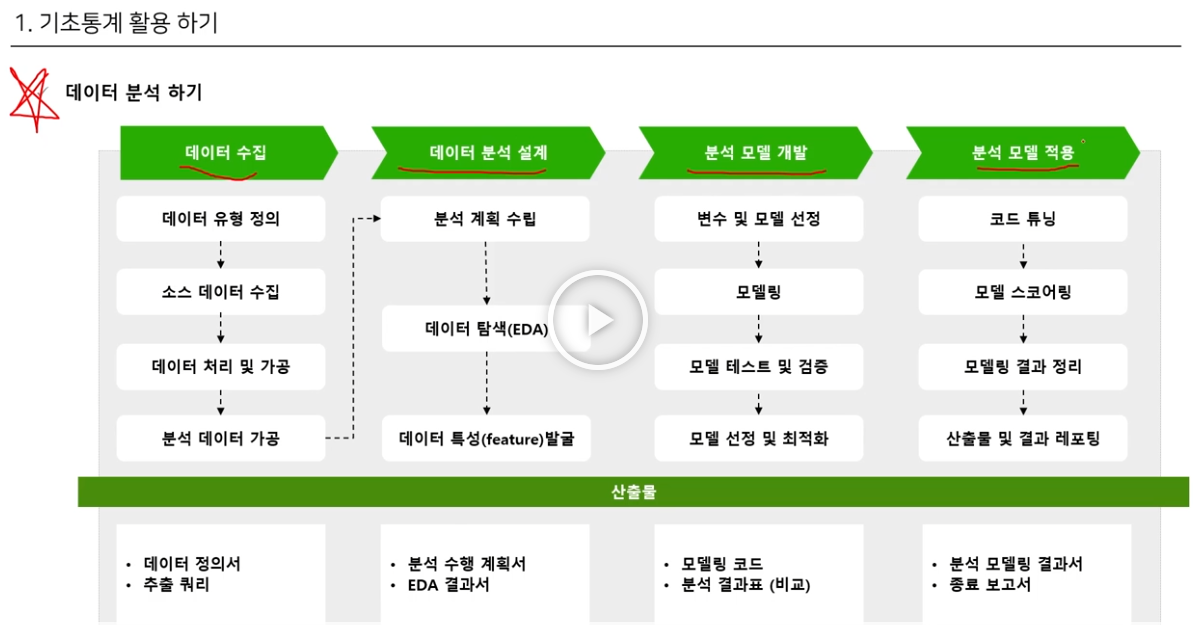
가장 먼저는 아무래도
데이터수집 - 데이터 분석 설계 - 분석 모델 개발 - 분석 모델 적용
이런 사이클로 진행이 될 것 같다.
데이터 수집
데이터 유형 정의 -> 소스 데이터 수집 -> 데이터 처리 및 가공 -> 분석 데이터 가공 ->
- 산출물 : 데이터 정의서 / 추출 쿼리
데이터 분석 설계
분석 계획 수립 -> 데이터 탐색(EDA) -> 데이터 특성(feature) 발굴 ->
- 산출물 : 분석 수행 계획서 / EDA 결과서
분석 모델 개발
변수 및 모델 선정 -> 모델링 -> 모델 테스트 및 검증 -> 모델 선정 및 최적화 ->
- 산출물 : 모델링 코드 / 분석 결과표 (비교)
분석 모델 적용
코드 튜닝 -> 모델 스코어링 -> 모델링 결과 정리 -> 산출물 및 결과 리포팅
- 산출물 : 분석 모델링 결과서 / 종료 보고서
외우자.. 외워야 산다!
인공지능 > 머신러닝 > 딥러닝 이러한 구조로 인공지능의 큰 테두리 속에서 머신러닝 / 딥러닝이 파생되어 기술이 계속 발전되어 왔다고 볼 수 있다.
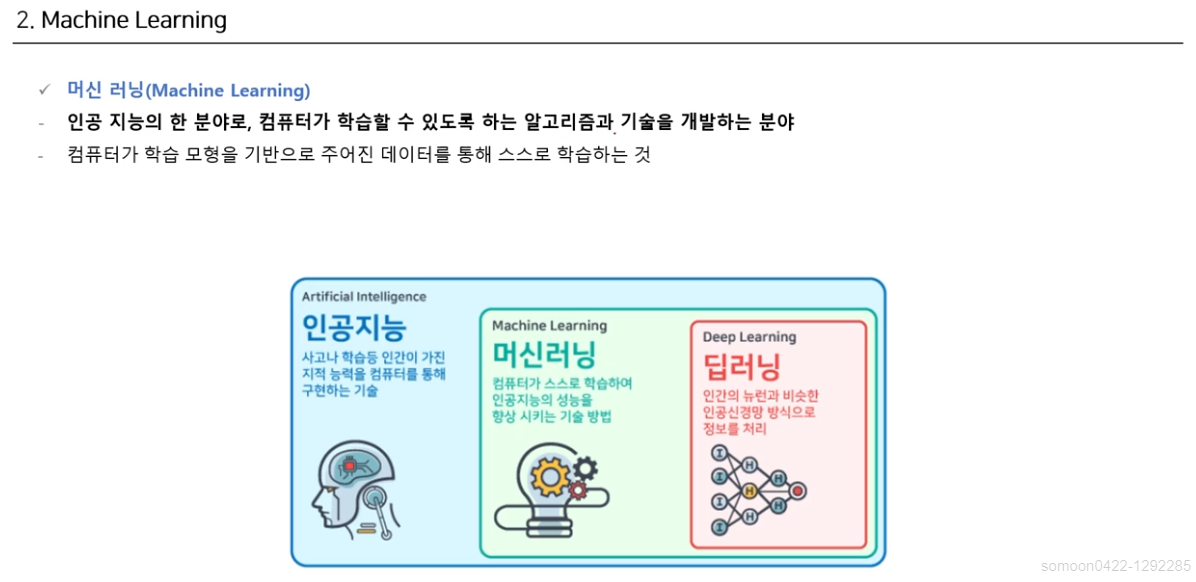

Machine Learning
-
Supervised Learning : Label 이 있는 데이터에 대해서 분석하는 방법으로 과거의 데이터로 미래를 예측하는 방법
-
Unsupervised : 군집 분석
-
Decision tree : 과적합우려
- 앙상블 모형
- Bagging : 랜덤복원추출
- Boosting : 랜덤복원샘플링 + 가중치 부여 (AdaBoosting / XGBoost / GradientBoost)
★추천모형★
Association CF 모형( 현업 필터링 방식 )
-
User based => 사용자들간 비슷한 행동 (클러스터링) , 목표 사용자가 속하는 군집에서 다른 사람들이 높은 점수의 평가를 부여한 아이템을 추천
-
Item based => 아이템 사이의 연관성 파악 / 비슷한 아이템의 군집 생성 / 그 군집 내에서 목표 사용자의 행동기록을 기반으로 다른 아이템을 추천
Deep Learning
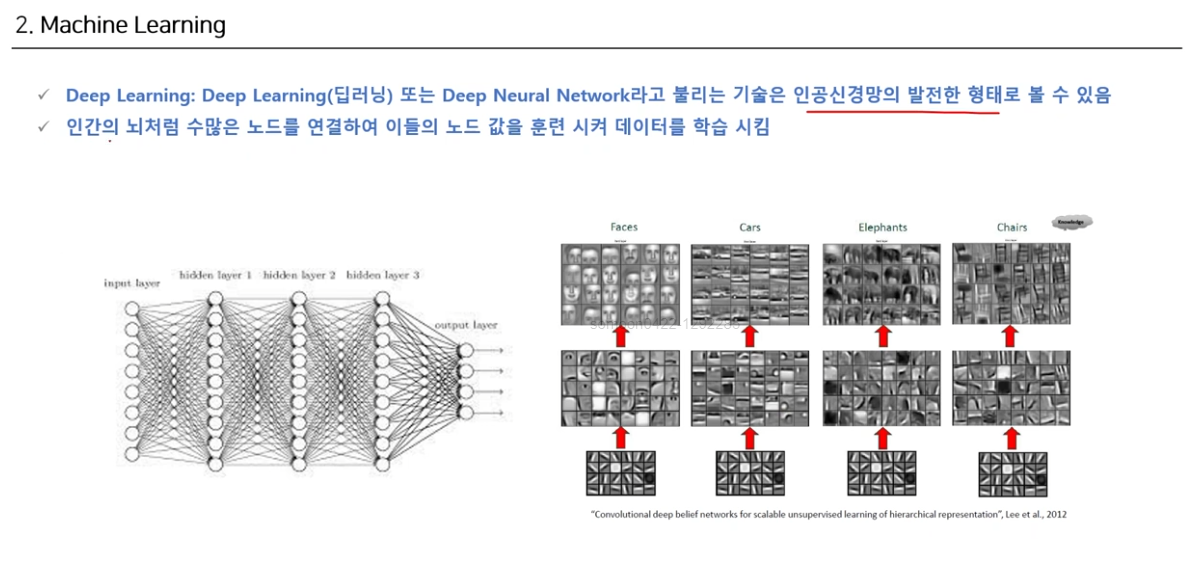
- CNN : 데이터 - 특징(Feature) - 지식
- RNN : 시계열 데이터 분석에 사용함 / 매순간마다 인공신경망 구조를 쌓아올린 상태
