study_note
1.[zerobase_데이터 취업스쿨_스터디노트] 1.파이썬중급

31finally32_Exception 클래스33사용자 Exception 클래스34텍스트 파일 쓰기35텍스트 파일 읽기36\_텍스트 파일 열기37_with ~ as문38_writelines()39_readlines(), readline()예외가 발생할 경우 어떤 에러인
2.[zerobase_데이터 취업스쿨_스터디노트] 2. Exception 사용자 예외 클래스
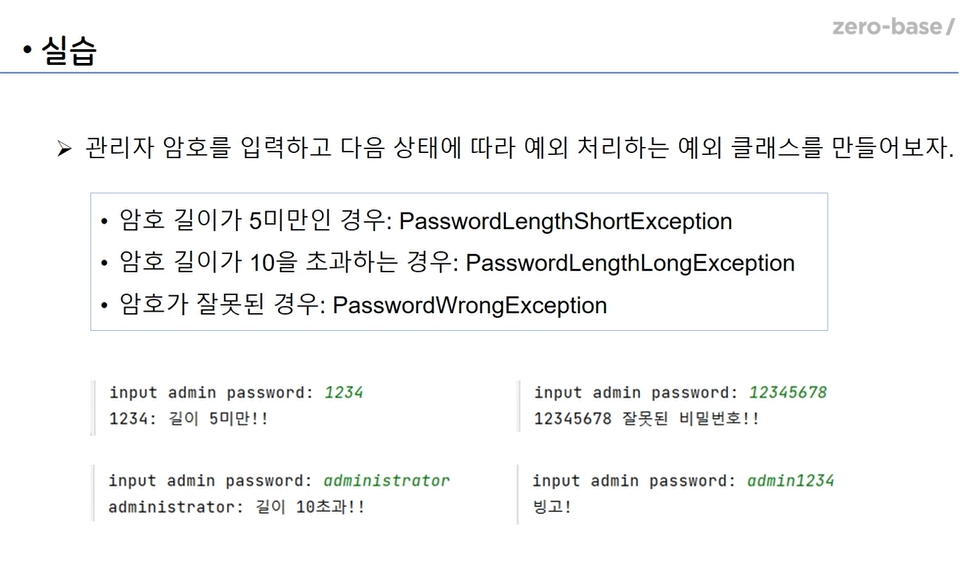
사용자 예외클래스인 Exception 에 대해서 정리해보겠다.나만의 Exception 문을 class 로 만들어서 사용하는 코드이다.class , def , try 문으로 크게 뜯어서 보면 좀 더 이해가 쉬울 것 이다.음..아무래도 클래스를 만들어두고 함수와 실행문을
3.[zerobase_데이터 취업스쿨_스터디노트] 3.수학(등차수열)
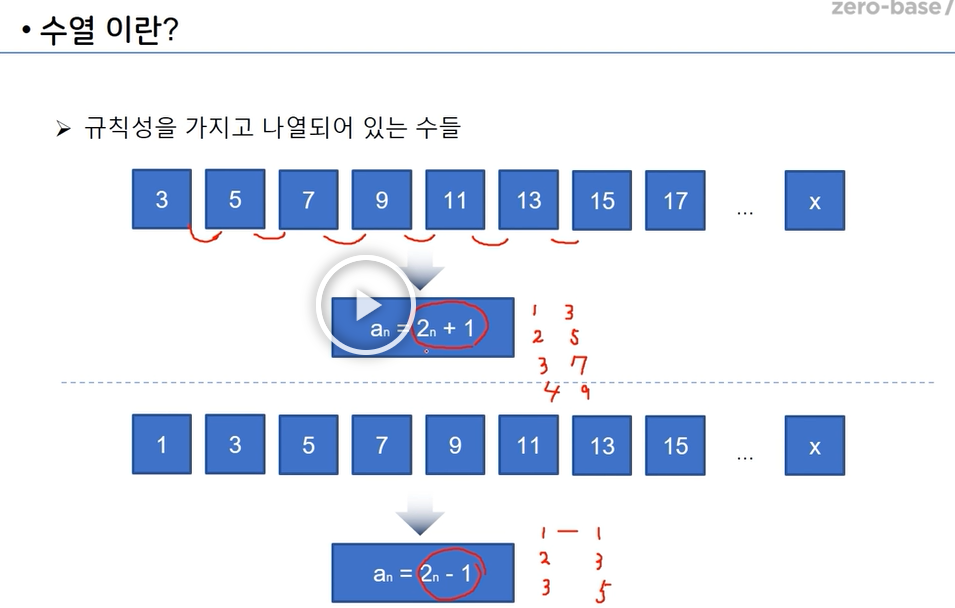
지난 시간에 수열에 대해서 배웠다.수열이란 규칙성을 가지고 나열 되어 있는 수들을 의미하는데저 수열의 규칙성을 갖는 수식은 수열의 일반항 이라고 한다.연속된 두 항의 차이가 일정한 수열을 등차수열이라고 한다.두 항 사이의 차이를 공차(d) 라고 부른다. 두 항의 값이
4.[zerobase_데이터 취업스쿨_스터디노트] 4.조합(파이썬)
조합이라는 것을 배워보자..!! 조합이란 순서 상관없이 R 만큼 선택하는 것! 이게 무슨 말일까 대체... 예시를 들어 바로 파이썬으로 구현해보자. 저번시간 8컴비네이션3 하면 순열로 구하는 방식이 있었다. nPr/r! 로 구하거나 또는 n!/r!(n-r)! 을
5.[zerobase_데이터 취업스쿨_스터디노트] 5. 기초수학 문제풀이
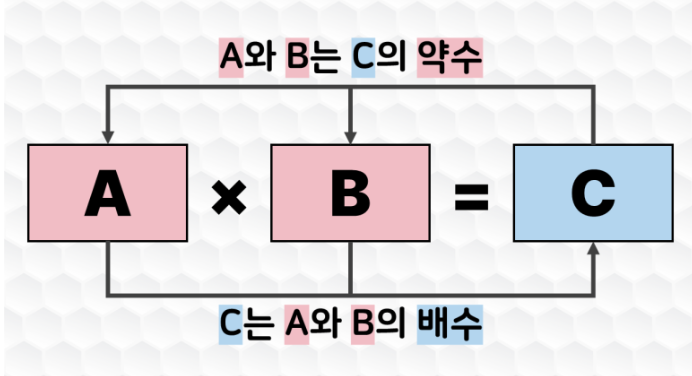
약수와 소수소인수와 소인수분해최대공약수최소공배수진법등차수열등비수열시그마계차수열피보나치수열팩토리얼군 수열순열조합확률이렇게 해서 기초수학 과정이 끝났다!하지만 완전히 다 익혀지지는 않은 것 같다 ㅠㅠㅠㅠ그래서 배웠던 내용을 복습할 겸 몇 가지만 노트정리를 해보려고 한다.약
6.[zerobase_데이터 취업스쿨_스터디노트] 6. 기초수학 문제풀이2탄
최대공약수。。。。어렴풋이 기억나중학교 수준? 고등학교 수준의 수학을 요즘 배우고 있는데 정말 다 까먹었었기 때문에처음부터 개념을 다시 잡아가는 중이다.그것도 파이썬으로 구현하는 방법은 또 처음이라 여러모로 쉽지가 않지만,그래도 이해하면 또 별거 아니다.자, 그럼 최대공
7.[zerobase_데이터 취업스쿨_스터디노트] 7. python 리스트
오늘은 리스트에서 인덱스 값을 찾는 것을 배웠다.이럴 경우 결과는 랜덤한 값에 의해서 나오게 된다.인덱스의 위치를 알려주는 기능은 < .index > 를 이용하면 된다는 것을 처음 알았다!엄청나게 유용하게 쓰일 것 같다는 생각이 든다.저 인덱스값은 곧 위치를 뜻하
8.[zerobase_데이터 취업스쿨_스터디노트] 8. 파이썬 튜플
튜플은 리스트와 매우 흡사하지만 리스트처럼 수정,삭제 등등 아이템 변경이 불가하다!위에 내용 하나만 잘 기억해놓고 있어도 튜플활용은 끝이다.(숫자, 문자열,논리형 등 모든 기본 데이터를 같이 저장할 수 있다.)(튜플 안에 튜플, 다른 컨테이너 자료형 데이터(ex.리스트
9.[zerobase_데이터 취업스쿨_스터디노트] 9. 알고리즘
선형검색이란? 보초법? 오늘은 알고리즘 첫 타임으로 선형검색을 배우는 날 이다. > 선형으로 나열되어 있는 데이터를 순차적으로 스캔하면서 원하는 값을 찾는다. 업로드중.. [출처 제로베이스] 파이썬코드로 구현을 해보자 결과는 사실 이 코드들을 보니까 떠오르
10.[zerobase_데이터 취업스쿨_스터디노트] 10. 순위
오늘은 알고리즘 강의 중 '순위' 에 대해서 실습까지 해보았다. 순위는 '랭킹' 과 같다. 어떤 값들의 순서(인덱스) 를 알아내순서를 정렬해 보았다.결과)왠지 학교 시험점수를 랭킹별로 나타내거나 어떤 시간차 순으로 무언가를 기록하고 정리해야 하는 상황에서 많이 쓰일 수
11.[zerobase_데이터 취업스쿨_스터디노트] 11.버블정렬

버블정렬..그건 또 무엇일까버블정렬을 말 그대로 정렬을 하는 것인접한 인덱스의 값을 비교하여 큰 수와 작은 수를 앞뒤로 바꾸며 순서를 정렬하는 것 이다.위의 사진의 경우는 10과 2를 비교했을 때 10이 더 크기 때문에 자리르 바꾸고,10과 7을 또 비교해서 10이 뒤
12.[zerobase_데이터 취업스쿨_스터디노트] 12.pandas데이터합치기_판다스기초_merge

저번 시간에 미니콘다 설치와 가상환경만들기 및 판다스 기초 사용법을 배웠다. 노트정리는 따로 하지 못했지만 github 에 매일 push 하고 있다. 깃헙링크 이번 데이터 합치기부터는 살짝 내용이 어려워져서 스터디노트로 상세히 기록해 두려고 한다. 먼저 다운로드
13.[zerobase_데이터 취업스쿨_스터디노트] 13.데이터시각화_matplotlib_실습(기초)
처음 다루는 사람들에게는 아무리 봐도 그게 그 말 같고,정말 헷갈리고 쉽지가 않다.(나는 그랬다..)이번 데이터취업스쿨에서 matplotlib 을 처음 다루는게 아닌데도 불구하고기초부터 다시 배워야 할 만큼 쓰지 않으니까 금방 까먹는다.그래서 아예 처음부터 천천히 기초
14.[zerobase_데이터 취업스쿨_스터디노트] 14.데이터시각화_matplotlib_실습(기초)2탄
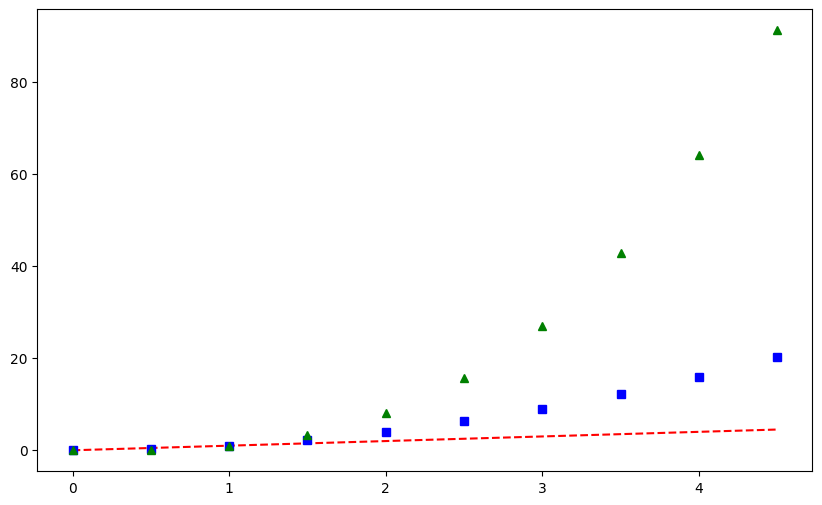
데이터 시각화 matplotlib 라이브러리 기초 2탄! 저번 시간에 이어서 이번에는 그래프 커스터마이징을 해보는 시간을 가져볼 예정이다. 그래프 커스터마이징 1. 0부터 5까지 0.5 단위의 데이터를 하나 넘파이 어레인지 메서드를 통해 만들어준다.
15.[zerobase_데이터 취업스쿨_스터디노트] 15. 강남3구 범죄현황 데이터 다루기(EDA)
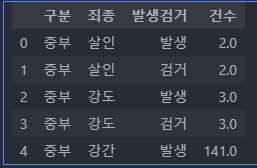
저번시간 cctv 데이터셋에 이어 범죄현황 데이터셋을 다루는 시간이 왔다..!!범죄 관련 데이터도 매우매우 궁금하기 때문에 눈을 크게 뜨고 볼 예정이다.범죄 관련 데이터 쪽으로 일을 하고 싶으면 ... 어떻게 해야 하지...? 보안회사에 가야하나경찰청에 들어가야 한..
16.[zerobase_데이터 취업스쿨_스터디노트] 16. GoogleMaps 를 이용한 데이터정리
저번시간에 google cloud 를 통해 Geocoding API 키를 발급받아 googldmaps API 키를 받을 수 있었다. 그 키를 통해 우리가 원하는 데이터를 추출하여 데이터정리를 하는 시간을 가져보려고 한다. 먼저 구글에 GCP 를 입력하여 구글 클라우드
17.[zerobase_데이터 취업스쿨_스터디노트] 17. 범죄 현황 데이터 시각화

점점 어려워진다....정신을 똑바로 차리자먼저 불러와야 하는 모듈들을 불러온 다음,마이너스로 인한 오류를 방지하고,inline 처리를 해준 다음,폰트는 맑은 고딕을 불러와 준다.( 이 부분은 외워질 때 까지 계속 쓰자. )그 다음 계속해서 만들어 둔 데이터 프레임을 불
18.[zerobase_데이터 취업스쿨_스터디노트] 18. Folium 지도 시각화
오늘은 지금까지 배워보지 않은 새로운 것을 배우는 날 이다.folium 이라는 모듈을 사용하려면 역시나 install 먼저 해야한다.mac , windows 상관없이 pip 로 설치해 주면 되는데, 간혹 windows 에러가 날 경우에는아래 2줄을 먼저 실행해보고 설치
19.[zerobase_데이터 취업스쿨_스터디노트] 19. folium 지도 시각화 2

저번 시간에 이어서 folium 지도 시각화 2번째 시간을 정리해 보겠다.지도위에 마우스로 클릭했을 때 마커를 생성해 줍니다내가 클릭하는 곳의 위치에 Marker 를 찍어줍니다.지도를 마우스로 클릭했을 떄 위도,경도 정부를 반환해 줍니다.m = folium.Map(
20.[zerobase_데이터 취업스쿨_스터디노트] 20. folium 지도 시각화 3

folium 지도 시각화의 마지막 시간이다.재밌었지만 이제 떠나보내 줄 차례다...................ㅎjson 모듈을 불러온 후, 제로베이스에서 제공해준 데이터를 불러온다.뭔지는 모르겠지만 50개의 이러한 데이터들이 들어있다.먼저 미국데이터이니 미국의 위도
21.[zerobase_데이터 취업스쿨_스터디노트] 21. 웹데이터분석 위키백과 문서 정보 가져오기_BeautifulSoup

이번 웹데이터 분석 과정은 내가 웹개발 공부를 하면서 가장.......머리속에 들여놓기 어려웠던 HTML 과 뗄 수 없는 과정이다. 그냥 눈에 잘 안 들어와서 힘들었는데 이번에는 맘 먹고 익숙해져 보려고 한다..!!!기초 BeautifulSoup 은 전 수업 때 들었고
22.[zerobase_데이터 취업스쿨_스터디노트] 22. List 데이터형
이번에는 파이썬 데이터 타입중 정말 중요한 '리스트' 형에 대해서 배워보겠다.데이터를 긁어오면서 리스트형을 많이 다룰텐데, 그 때 사용하는 함수들을 익혀야 한다.자료형 배울 때 리스트에 대한 기본적인 것은 다 했기 때문에이번 노트정리에서는 크롤링, 웹데이터 수집과 관련
23.[zerobase_데이터 취업스쿨_스터디노트] 23. 시계열데이터

댕댱댕....드디어 시계열데이터 입성....회고지난 1주일간 로마여행으로 ㅠㅠ (제로베이스 전부터 예약해둔 여행이라 취소 안 됨..)때문에 너무나 밀려버린 진도..그리고 1,2회차 EDA 테스트 모두 제출을 못해서 망..해따..ㅎ이렇게 꼬이는 걸 너무 싫어하기 때문에
24.[zerobase_데이터 취업스쿨_스터디노트] 24. Naver API
이제 NAVER API 단계 이다..이번 수업에서는 어떤 걸 배우게 될지 기대가 된다..!!먼저 네이버 개발자 센터로 들어가서 진행이 된다.서비스 API 로 들어간다오픈 API 이용 신청을 클릭한다.rmekdma 순서대로 등록을 해주면 된다.개발가이드 : https&#
25.[zerobase_데이터 취업스쿨_스터디노트] 25. AWS RDS
AWS RDS 는 아마존 웹서비스에서 제공하는 데이터베이스 관련 서비스 이다.SQL 에서는 RDBMS 를 쓰고 있다.클라우드 상에서 PC나 DB 등을 제공하는게 AWS RDS 이다.이곳에 들어가서 데이터 베이스 생성 클릭저 위에처럼 클릭 후, 버전은 최신버전으로 템플릿
26.[zerobase_데이터 취업스쿨_스터디노트] 26. AWS RDS 에 table, column 추가하고 분석하기
오늘은 sql 심화 test 때문에 하루를 다 쓴 것 같다.처음에 csv 파일 3개를 주셨는데 그거를 어떻게 sql 파일로 바꿨더라? 하면서 chat gpt 에게 물어물어기억을 되살려냈다.. 인공호흡..먼저는 aws rds의 db로 접속해서 table 생성을 미리 해두
27.[zerobase_데이터 취업스쿨_스터디노트] 27. git
git clone (git repo의 HTTPS 주소, 혹은 SSH)\-----> 지금 vscode 터미널이 위치한 폴더에 repo를 복제해옵니다.다른 옵션을 안줬을 경우 기본 branch가 복제됩니다.git remote update\-----> git 서버의 저장소의
28.[zerobase_데이터 취업스쿨_스터디노트] 28. window에서 vim 사용하는 법

오늘은 git 수업을 듣는 중에 window cmd 환경에서 생각보다 많은 명령어 들이 (수업에서 사용 하는) 안 되는 것을 느끼고 착잡해졌다. 하지만 이미 선배 개발자들이 닦아놓은 길이 분명히 있을거라는 생각에 구글링을 하면서 하나하나 알아가기 시작했다.ls 는 di
29.[zerobase_데이터 취업스쿨_스터디노트] 29. Tableau Public 가입 설치부터 전처리까지

오늘은 정말로 배우고 싶었던 Tableau 를 드디어 꺼내든 날 이다. 아주 영광스러운 날 이다.그런데, 생각보다 어렵다는 사람들이 있어서 살짝 걱정도 되지만 ...그런건 필요없다!그냥 해보면서 느는겨먼저 나는 태블로 퍼블릭을 설치하여 사용하기로 했다.https
30.[zerobase_데이터 취업스쿨_스터디노트] 30. Tableau Public 기본컨셉이해(인터페이스)
오늘은 꽤나 어려운 것을 배울 것 같다는 생각이 든다.그치만 또 새로운 것을 배운다는 게 기대가 된다.메뉴바 다양한 옵션들을 제공하고 있음.툴바오름차순, 내림차순, 행,열변환 등 여러가지 처리 가능왼쪽 데이터 클릭데이터분석 / 차트 표현 변경 가능업로드중..이렇게 아주
31.[zerobase_데이터 취업스쿨_스터디노트] 31. Tableau 기본컨셉 - 차원vs측정값
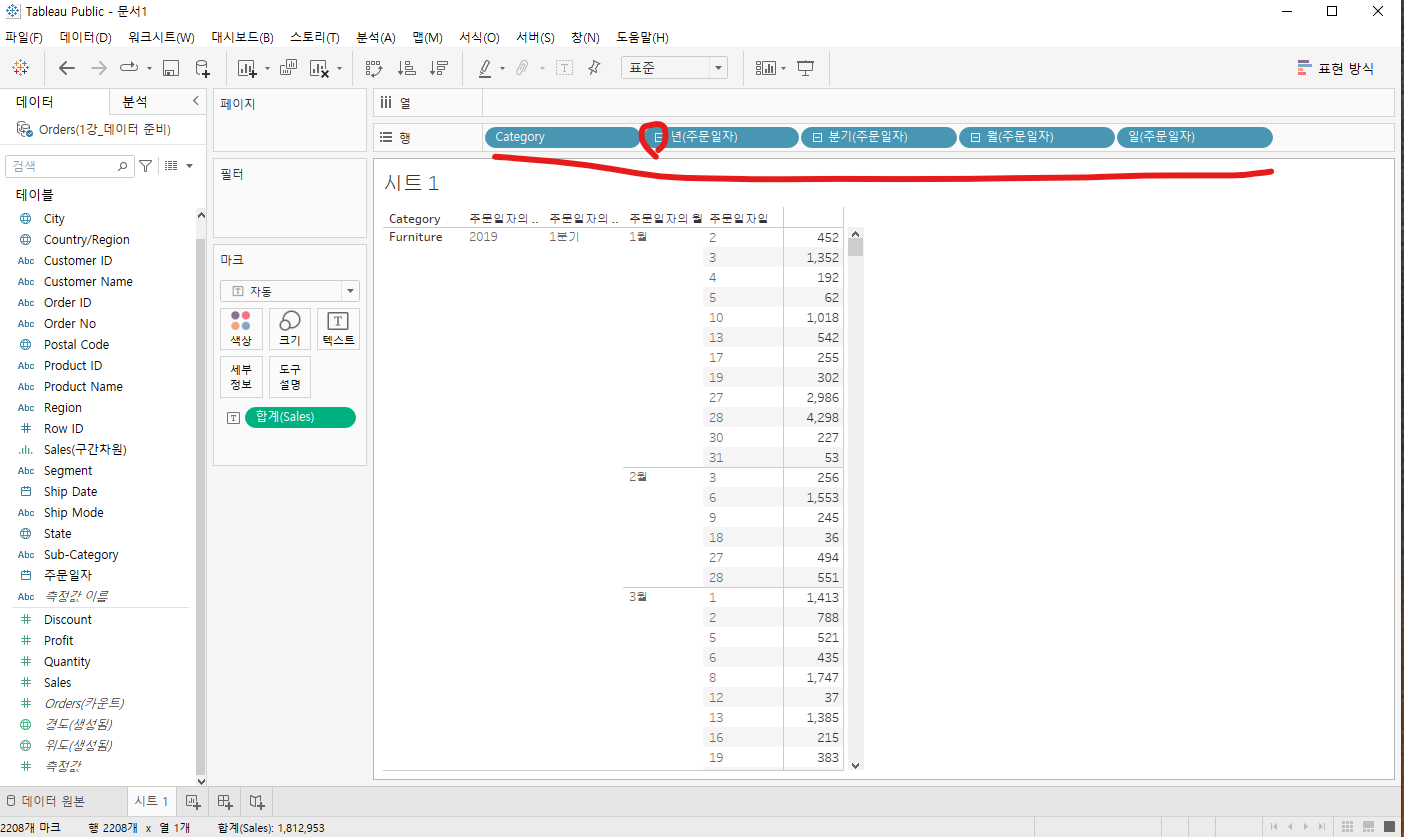
차원과 측정값에 대해서 알아보자태블로 공식사이트를 가면 알 수 있는 내용차원 : 이름,날짜,지리적 데이터 등을 포함합니다. 차원을 사용하여 데이터의 세부 정보를 분류하고 나누고 표시할 수 있습니다. 차원은 뷰의 세부 수준에 영향을 미칩니다.측정값 : 측정할 수 있는 정
32.[zerobase_데이터 취업스쿨_스터디노트] 31. Tableau 기본컨셉 - 차원vs측정값
차원과 측정값에 대해서 알아보자태블로 공식사이트를 가면 알 수 있는 내용차원 : 이름,날짜,지리적 데이터 등을 포함합니다. 차원을 사용하여 데이터의 세부 정보를 분류하고 나누고 표시할 수 있습니다. 차원은 뷰의 세부 수준에 영향을 미칩니다.측정값 : 측정할 수 있는 정
33.[zerobase_데이터 취업스쿨_스터디노트] 32. 기초통계

드디어 통계다 신난다..!이번 강의는 기초 통계 이다.머신러닝, EDA, 태블로를 이해하기 위해서는 통계에 대한 이해도가 있어야 하기 때문에ADsP 자격증 딸 때 배웠던 기억을 다시 끄집어내고 정리해 볼 수 있는 시간이 될 것 같다!용어 설명변수(variable): 수
34.[zerobase_데이터 취업스쿨_스터디노트] 33. 연속형확률분포
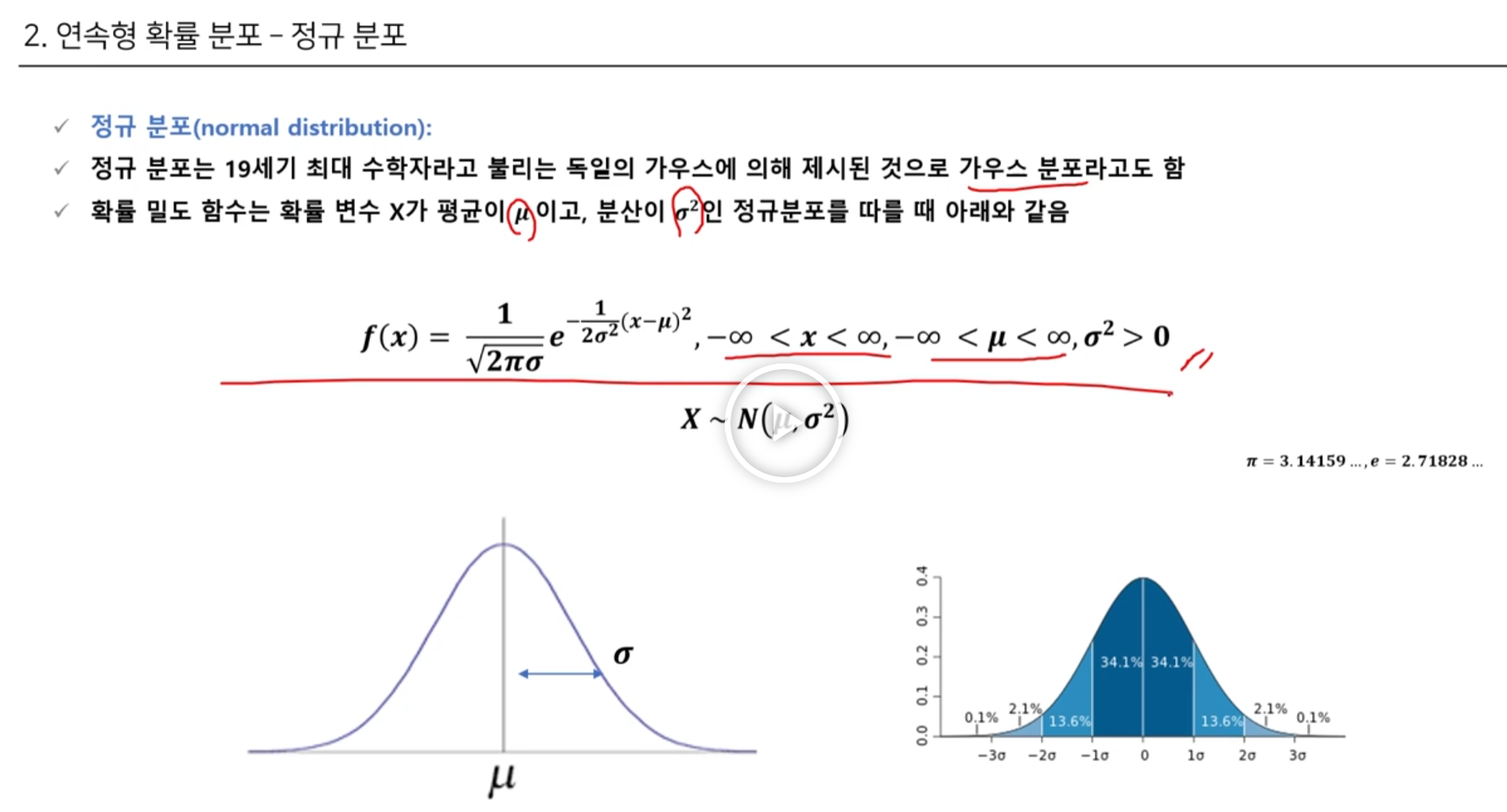
이건 무조건 중요해서 외우라고 하심이건 내가 외워야 할 것 같아서 가져옴.정규분포를 구하는 공식이 있는데 그걸 외워야 할 것 같다.그런데, 왜 0.5가 나오는지 왜 0.9857 이 나오는지 모르겠다..gpt 에게 물어봐야겠다.세상에..ㅎ 생각보다 너무 이미지를 잘 해석
35.[zerobase_데이터 취업스쿨_스터디노트] 34. 모집단과 표본분포 및 추정
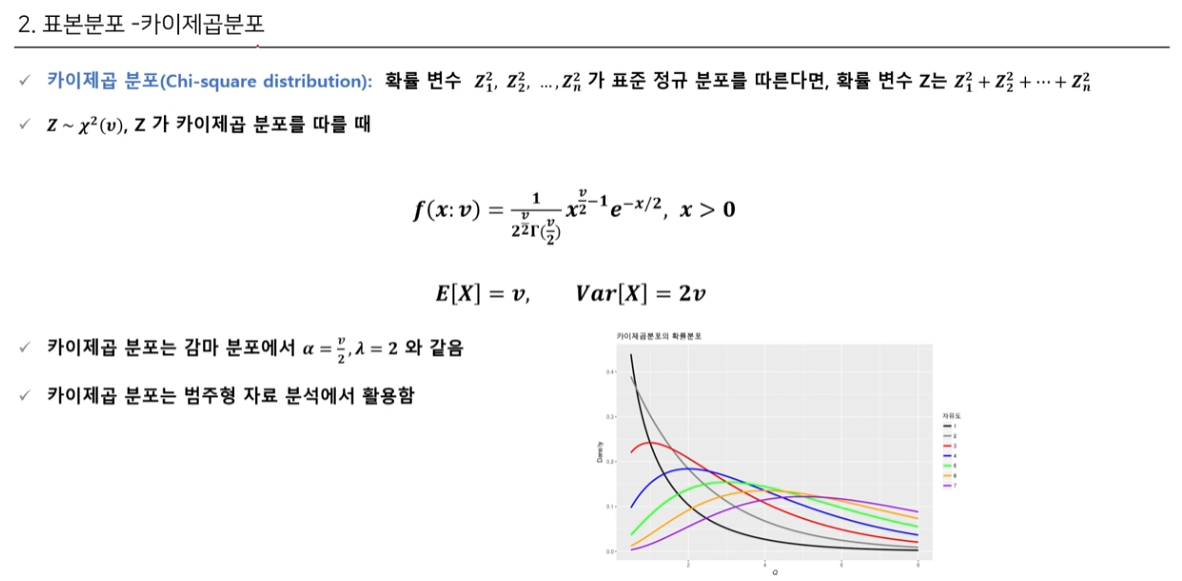
카이제곱분포는 표준정규분포의 합으로 이루어진 분포다 라고 해도 70% 정도는 맞는 대답이라고 볼 수 있다.카이제곱분포는 범주형자료분석에서 활용이 가능하다.\*자유도라는 개념이 굉장히 중요하다.F분포는두 모집단의 분산을 비교하거나 분석할 때 주로 사용한다. \*표본의 크
36.[zerobase_데이터 취업스쿨_스터디노트] 35. 머신러닝 알고리즘과 실제 활용
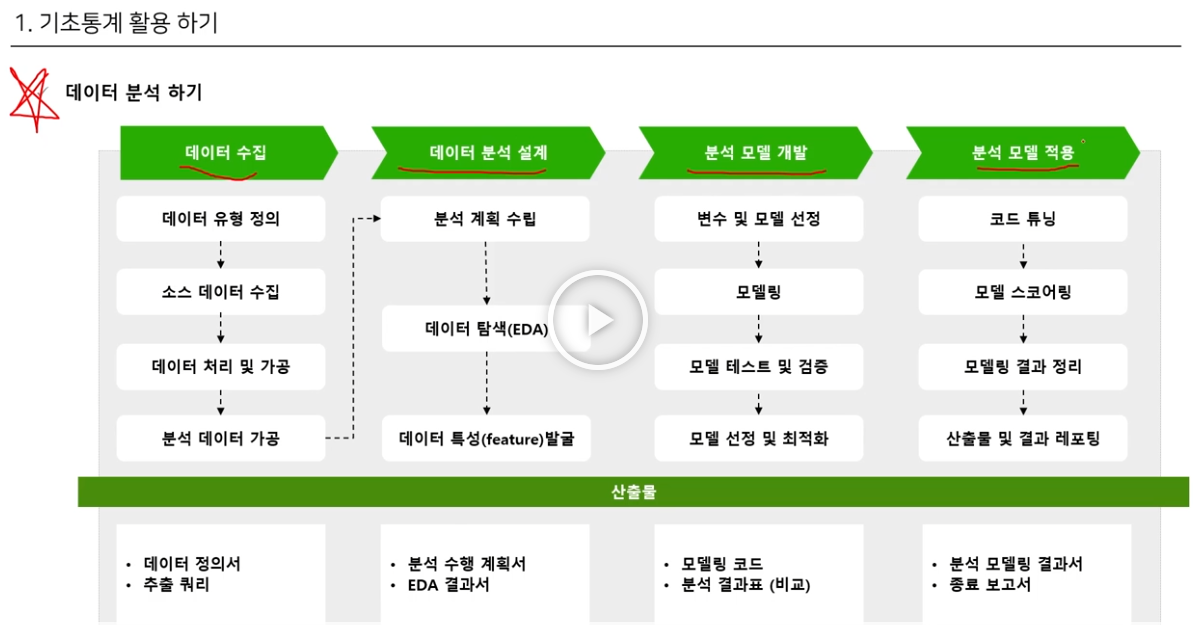
드디어 머신러닝 알고리즘으로 들어가려고 한다..설레서 미치겠다.우선 데이터를 분석하기 전에는 명확한 프로세스가 머리속에 정리되어 있어야 한다.가장 먼저는 아무래도데이터수집 - 데이터 분석 설계 - 분석 모델 개발 - 분석 모델 적용 이런 사이클로 진행이 될 것 같다.데
37.[zerobase_데이터 취업스쿨_스터디노트] 36. 머신러닝

먼저 사이킷런에서 제공하는 데이터셋을 활용해서 vscode 로 직접 머신러닝 실습을 해보기로 한다.dict_keys('data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'dat
38.[zerobase_데이터 취업스쿨_스터디노트] 37. 데이터나누기1 (Decision tree 를 이용한 iris 분류 - 과적합)

과적합지도학습에 대한 전체적인 프로세스 이다.먼저 사이킷런으로 이전에 불러온 데이터를 학습시켜보는 과정을 해보겠다.array(\[5.1, 3.5, 1.4, 0.2, 4.9, 3. , 1.4, 0.2, 4.7, 3.2, 1.3, 0.2,
39.[zerobase_데이터 취업스쿨_스터디노트] 38. 데이터나누기2 - 데이터분리
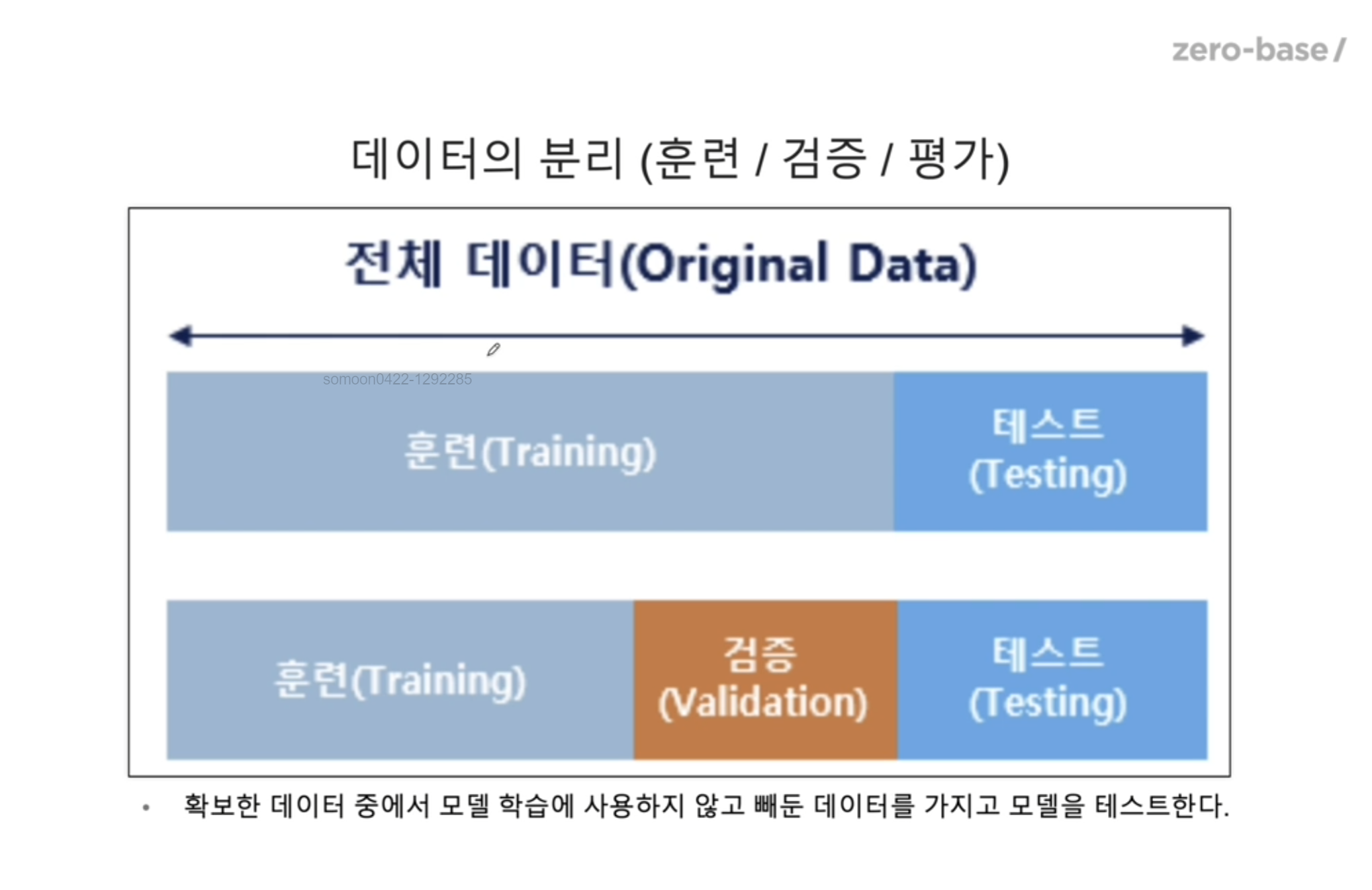
데이터 분리과적합 여부를 판정해보는 방법 .. 데이터를 분리해서 사용하는 것 !전체데이터에서 훈련데이터셋/테스트데이터셋 을 나누는 것이 최소이고,그러나 , 테스트를 하기전 훈련데이터를 다시 나누어서 일부를 Validation 용으로 (검증용) 으로 사용한다.이것은 내가
40.[zerobase_데이터 취업스쿨_스터디노트] 39. 데이터나누기3 -zip과 언패킹

먼저 리스트 두개를 만들어준다.zip 을 해준다.결과물을 dict 형태로 변경해 준다.이 과정을 한 줄로 끝내는 방법x,y = zip(\*pairs)
41.[zerobase_데이터 취업스쿨_스터디노트] 40. 데이터 탐색적 분석EDA- Titanic
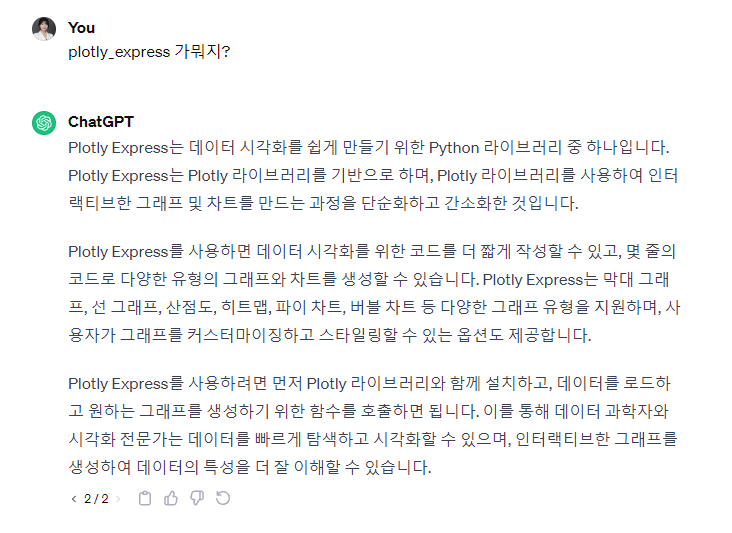
데이터 탐색적 분석EDA- Titanic먼저 모듈 하나를 다운 받고 시작한다.python 라이브러리에 데이터 시각화 모듈이다.그런데 seaborn 을 사용하지 않고 왜 이걸 사용하지? 의문이 들었다.어떤 시각화, 어떤 분석이 진행되냐에 따라서 선택적으로 사용하면 되는
42.[zerobase_데이터 취업스쿨_스터디노트] 41. 타이타닉 생존자 분석 EDA 2
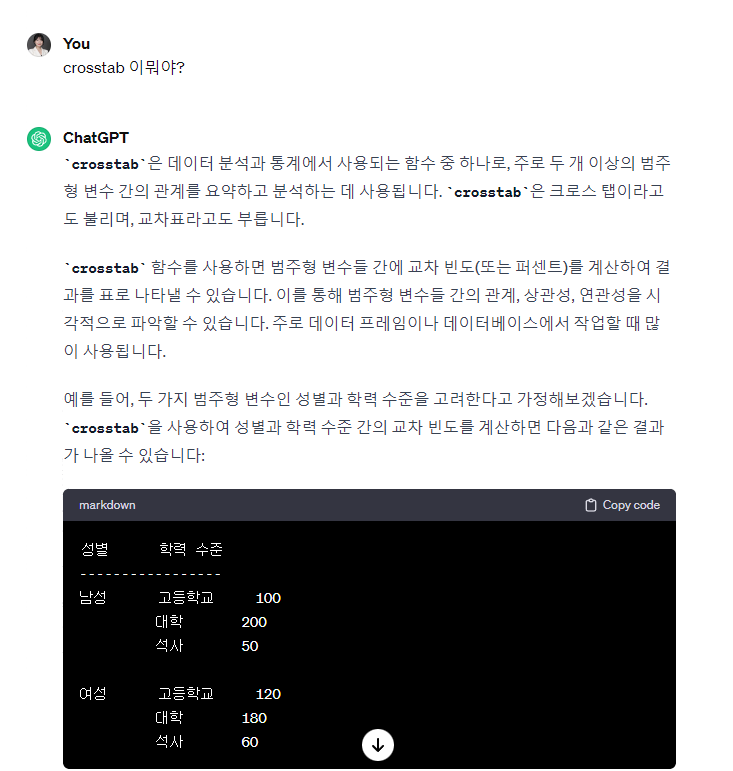
타이타닉 생존자 분석 EDA2pclass 는 객실등급을 뜻한다.crosstab 은 데이터 분석과 통계에서 주로 사용되는 함수라고 한다. 2개의 범주형 변수를 비교할 수 있어서 pclass 범주형 변수와 survived 범주형 변수를 넣어서 사용해 보겠다.1등실의 생존
43.[zerobase_데이터 취업스쿨_스터디노트] 42. 머신러닝을 이용한 생존자예측 - titanic
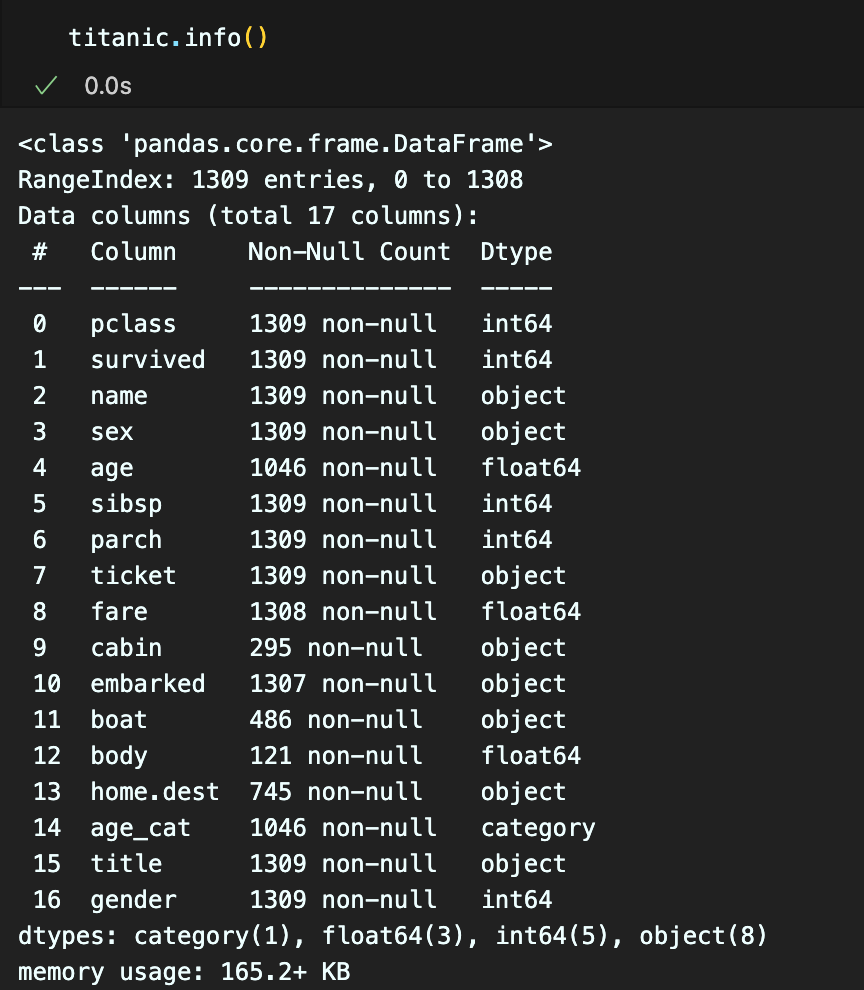
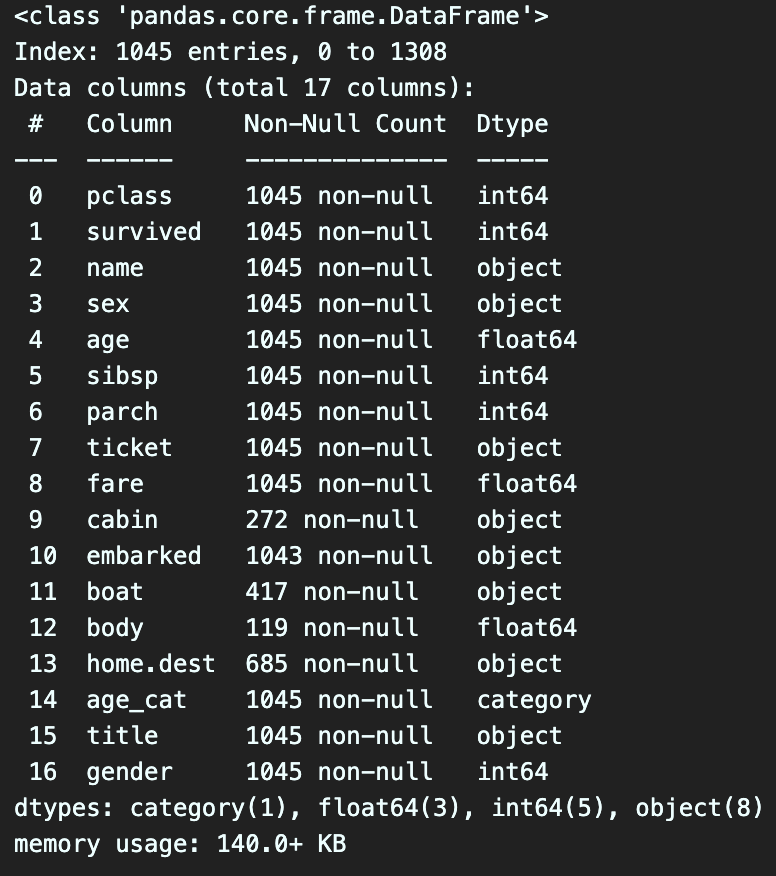
이제 드디어 머신러닝을 활용하여 생존자를 예측하는 모델을 만들어 본다.먼저 머신러닝 데이터에는 문자열 데이터가 오는게 아닌 숫자형만 와야 하는데,info() 를 찍어보니,내가 사용 할 feature 인 sex가 문자로 되어있다.그래서 이것을 형변환 해주기 위해 사이킷런
44.[zerobase_데이터 취업스쿨_스터디노트] 43. Min-Max-Scaler
Min-Max-Scaler / 정규화하기(array(25., 3.), array(-10., 0.), array(35., 3.))array(\[0.57142857, 0.33333333, 0.85714286, 0.66666667, 0\.
45.[zerobase_데이터 취업스쿨_스터디노트] 44. Basic of Regression -OLS

실습데이터프레임을 하나 만들어준다.전통적인 회귀분석모형을 구축하고 평가하기 위해서는 파이썬 라이브러리 statsmodels을 이용할 수 있음OLS 회귀분석 모델statsmodel.formula에 ols라는 모델을 사용해서 학습을 시켜준다.사용방법\-> statsmode
46.[zerobase_데이터 취업스쿨_스터디노트] 45. Logistic Regression
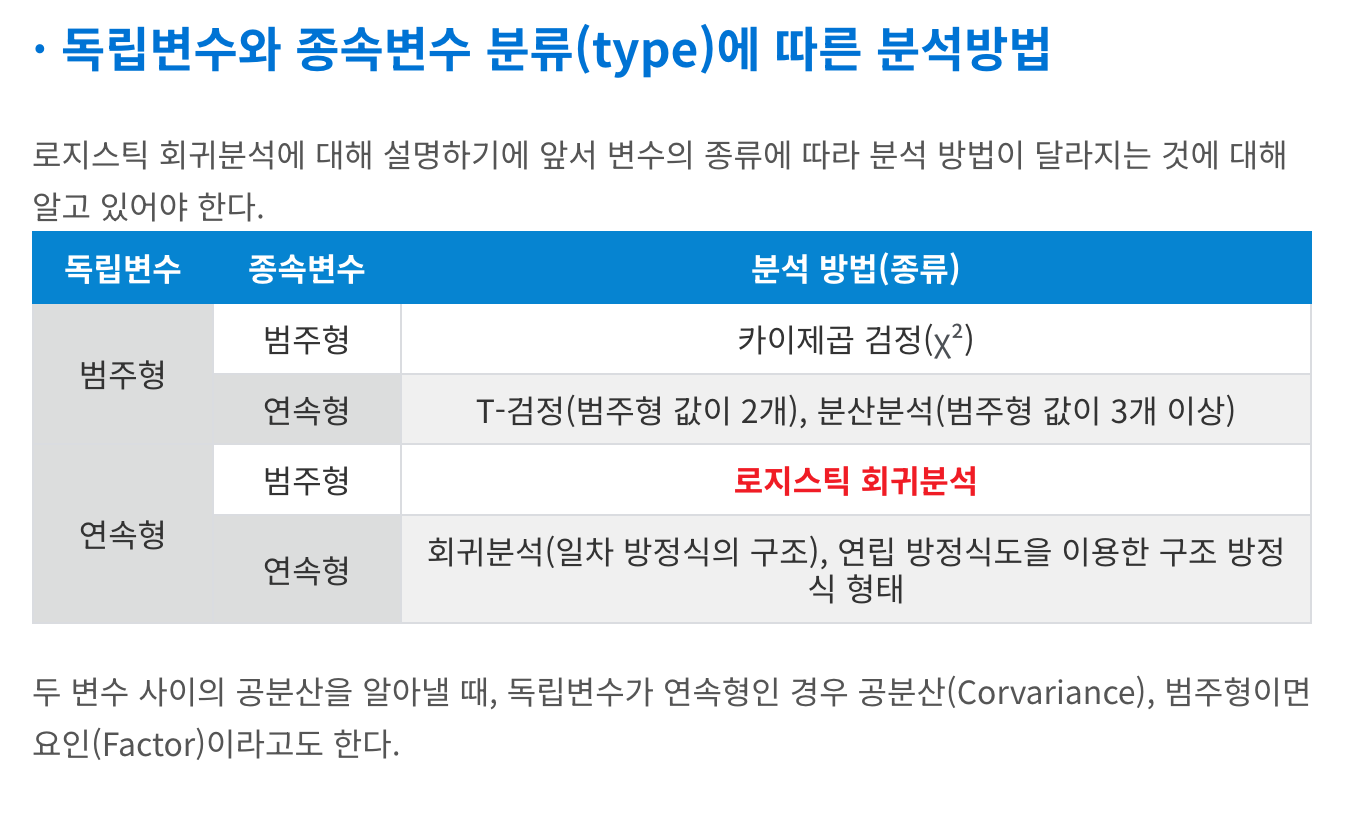
Logistic Regression 은 회귀가 아닌 분류모델이다.간단히 직접 그려서 알아보자!0,0.5를 딱 지나가는 그래프가 그려진다.시그모이드는 아무리 작아도 0이고 아무리 커도 1이 나오는 함수이다.체크! h\\theta(x) 는 주어진 입력 x(종양의 크기) 에
47.[zerobase_데이터 취업스쿨_스터디노트] 46. 정밀도와 재현율

정밀도와 재현율 (precision & recall) 의 트레이드오프Train Acc: 0.7425437752549547Test Acc: 0.7438461538461538 macro avg 0.73 0.71 0.71 1300w
48.[zerobase_데이터 취업스쿨_스터디노트] 47. 앙상블 기법
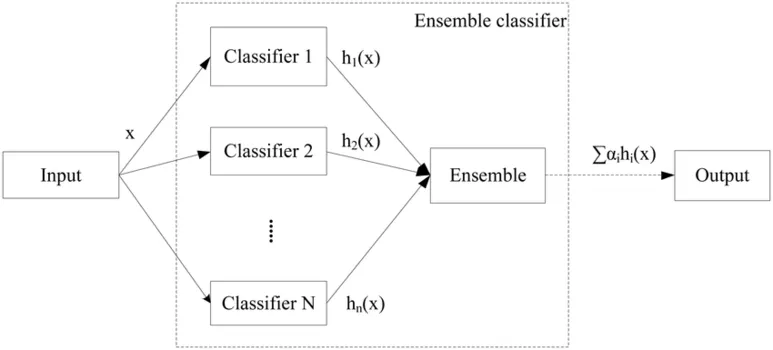
머신러닝이던 딥러닝이던, 결국 모델이 달라지는 것은 코드 조금 수정하는 차이기 때문에크게 중요하지 않아진다. 모델을 바꾸는 것보다 중요한 건 데이터를 들여다 보는 일이라고 한다.결국..나는 평생 데이터의 노예가 되어야 할 것 같다..!ㅎ힣테슬라의 수석 엔지니어 중 한
49.[zerobase_데이터 취업스쿨_스터디노트] 48. Boosting Algorithm
boosting algorithm..!부스팅(Boosting)은 머신러닝에서 사용되는 앙상블 학습 기법 중 하나로, 약한 학습기(weak learner)를 결합하여 강력한 학습기(strong learner)를 만드는 방법입니다. 부스팅 알고리즘은 성능이 상대적으로 낮은
50.[zerobase_데이터 취업스쿨_스터디노트] 49. kNN (k-Nearest Neighbor)
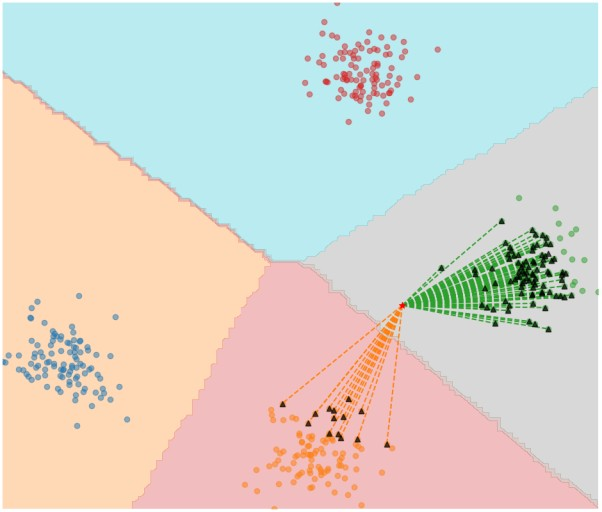
kNN 알고리즘..!새로운 데이터가 있을 때 기존 데이터의 그룹 중 어떤 그룹에 속하는지를 분류하는 문제K 는 몇 번째 가까운 데이터까지 볼 것 인가를 정하는 수치k 값에 따라 결과가 달라진다는 특징이 있다.두 점 사이의 거리를 계산 하는 법은 유클리드 기하학이 가장