자바 크롤링 Jsoup
크롤링과 웹 스크래핑
- 크롤링과(crawling)와 스크래핑(scrapping)이란 웹 페이지에 있는 데이터들을 프로그래밍을 이용하여 추출하는 것을 의미
- URL을 탐색해 반복적으로 링크를 찾고 가져오는 과정
웹 크롤링(Web Crawling)이란?
- 웹 크롤링이란 웹상의 정보들을 탐색하고 수집하는 작업을 의미
장점
- 웹 크롤링은 웹상을 돌아다니며 방대한 양의 정보를 수집하기 때문에, 특정 키워드에 대한 심층 분석이 필요할 때 유용
- 크롤러는 실시간 정보 수집을 위해 계속해서 작동하므로 자주 변화하는 데이터를 파악하기가 좋디
웹 스크래핑(Web Scraping)이란?
- 웹 스크래핑은 특정 웹 사이트나 페이지에서 필요한 데이터를 자동으로 추출해 내는 것을 의미
- 우리가 정한 특정 웹 페이지에서 데이터를 추출하는 것
장점
- 특정 사이트나 페이지에 대한 정보를 찾는데 집중하므로 데이터 포인트를 정확히 잡고 확실한 정보만을 수집할 수 있다는 점에서 유용
웹 스크래핑 작동 순서
- 특정 웹 사이트에 콘텐츠를 다운로드하기 위한 HTTP GET 요청
- 사이트가 이에 응답하면 스크래퍼는 HTML 문서를 분석하여 특정 패턴을 지닌 데이터를 가져온다
- 추출된 데이터를 원하는 대로 사용할 수 있도록 데이터베이스에 저장
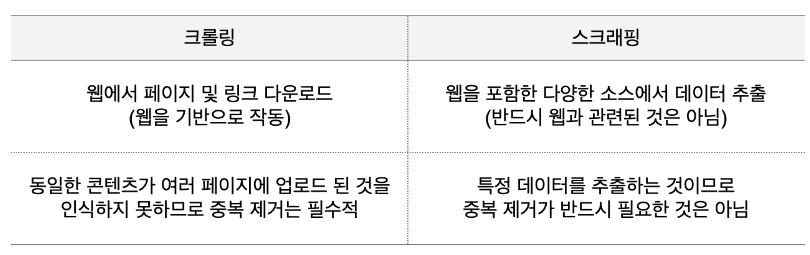
웹 크롤링과 웹 스크래핑의 차이점
- 크롤링과 스크래핑은 ‘원하는 데이터를 모을 수 있다’는 점이 비슷하여 의미가 자주 혼용
- 크롤링 -> 웹 페이지의 링크를 타고 계속해서 탐색을 이어나가지만
- 웹 스크래핑 -> 데이터 추출을 원하는 대상이 명확하여 특정 웹 사이트만을 추적
- 웹 크롤링은 페이지를 모아 색인화(분류)하고 검색 결과에 내가 찾는 키워드와 연관된 링크들만 모아 볼 수 있도록 작동
- 웹 스크래핑은 상품의 가격, 주식 정보, 뉴스 등 원하는 데이터가 명확하며, 흩어져있는 해당 데이터를 자동으로 추출하여 전달
JSOUP 란?
- URL, 파일, 문자열을 소스로 하여 HTML 문서를 파싱할 수 있다.
- 문서 내의 HTML 요소, 속성, 텍스트를 조작할 수 있다.
- CSS 선택자를 사용해 데이터를 추출할 수 있다.
- 요약하면 HTML 문서를 조작할 수 있게 해주는 라이브러리로, 해당 라이브러리를 통해 웹사이트로부터 원하는 데이터를 추출할 수 있다.
DOM 을 찾기 위한 속성
- tag : HTML 문서의 구조를 나타내기 위한 명령어로 중복될 수 있다.
- id : 하나의 DOM을 구분하기 위해서 태그에 붙인 식별자(중복될 수 없다.)
- class : 여러 DOM에 동일한 디자인을 적용하기 위한 이름으로 중복 될 수 있다.
- name : 서버에게 데이터를 전달할 때 서버에서 인식할 이름으로 중복 될 수 있다.
1) Document 클래스
- 연결해서 얻어온 HTML 전체 문서
2) Elements 클래스 - Element가 모인 자료형
3) Element 클래스 - Document의 HTML 요소
DOM을 찾기 위한 메소드
- getElementById(String id) : Element 객체를 반환합니다. 하나를 반환, 없으면 null 을 반환
- getElementsByTag(String tag) : Elements 객체를 반환, 없으면 size() 가 0
- getElementsByClass(String class) : Elements 객체를 반환, 없으면 size() 가 0
- select(String selector) : Elements 객체를 반환, 이 메소드는 CSS 선택자를 사용하여 요소를 선택합니다. 더욱 복잡한 선택이 가능하며, 클래스, ID, 요소 이름, 계층 구조 등을 활용
getElementById 만 Element 이고, 나머지는 Elements 라는 점입니다. Id는 하나의 Element만 가지고 있는 고유 속성이기 때문에 단일 Element를 돌려줍니다. 그리고 Elements는 ArrayList*<Element*> 같은 것이 아니고 Elements라고 하는 객체가 따로 존재합니다. 그래도 Elements는 List 인터페이스를 구현했기 때문에 일반 리스트 처럼 사용할 수 있습니다.
Element 객체가 할 수 있는 작업
- attr(String key) 로 속성의 값을 얻습니다. attr(String key, String value)로 속성의 각을 설정할 수 있습니다.
- id(), className() 은 id와 class속성의 값을 가져옵니다. class는 여러개 지정되면 하나의 문자열로 반환됩니다. 예로 요소가 <*div class="center red"> 라면 className() 은 "center red" 를 반환합니다. 하나씩 구하기 위해서는 classNames() 메소드를 사용합니다. Set<*String> 타입으로 반환합니다.
- text()로 순수 텍스트만 구합니다. text(String value)로 요소의 텍스트를 설정할 수 있습니다.
- html()로 html 문자열을 구합니다. html(String value) 메소드로 inner HTML 을 설정합니다.
- outerHtml() 요소의 outer html을 반환합니다.
select
doc.select("a") : <a> 요소를 모두 선택
doc.select("#logo") : id="logo" 인 요소를 선택
doc.select(".list") : class="list"인 요소들을 선택설정
- jpa
- ojdbc
- web
- thymeleaf
- lombok
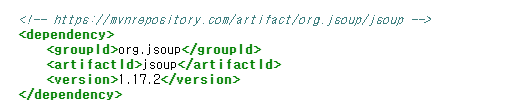
의존성 추가
https://jsoup.org/download
https://mvnrepository.com/artifact/org.jsoup/jsoup
크롤링
https://www.hanbit.co.kr/store/books/new_book_list.html
이 홈페이지에서 도서명과 이미지 가져오기
1. vo 만들기
- NewBook
String title 제목
String link 이미지 링크- dao 만들기
- 인터페이스로 만들기(JpaRepository)
- controller 만들기
// @GetMapping("/newbook")
// public HashMap<String, String> newBook(Model model) {
// HashMap<String, String> map = new HashMap<String, String>();
// String base = "https://www.hanbit.co.kr";
// String url = "https://www.hanbit.co.kr/store/books/new_book_list.html";
// try {
// // jsoup을 통해서 doc객체 생성
// Document doc = Jsoup.connect(url).get();
// // 찾고자 하는 Elements를 찾아서 검색
// // 배열을 반환
// Elements list = doc.select(".book_tit");
//
// for (Element e: list) {
// // 첫번째 자식 Element를 반환
// Element a = e.firstElementChild();
// // attr로 속성 접근
// String link = base + a.attr("href");
// String text = a.text();
//
// map.put(text, link);
// }
// } catch (Exception e) {
// System.out.println(e.getMessage());
// }
//
// model.addAttribute("map", map);
// return map;
// }connect 메소드로 크롤링할 URL을 연결하고get 메소드로 document를 가져온다. 긁어온 document에서 select 메소드를 사용해서 element를 찾으면 된다.
- newbook.html 화면 구성
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<h2>도서목록</h2>
<hr>
<ul>
<li th:each="m:${map}">
<a th:href="${m.value}" th:text="${m.key}"></a>
</li>
</ul>
</body>
</html>2. 전체 페이지 수 구하기
@GetMapping("/newbook")
public List<NewBook> newBook(Model model) {
List<NewBook> bookList = new ArrayList<NewBook>();
// 이 홈페이지의 최대 페이지 수는 86페이지
int i = 1;
try {
// String url2 = "https://www.hanbit.co.kr/store/books/new_book_list.html?page=86";
// 페이지 넘어서 조회시 오류 확인
// Connection conn = Jsoup.connect(url2);
// System.out.println(conn);
// Document doc2 = Jsoup.connect(url2).get();
// Elements list2 = doc2.select(".book_tit");
// list2의 null값을 확인하려 했지만 값이 들어가 있음
// size를 통해 확인
// if (list2.size() == 0) {
// System.out.println("86페이지 없음");
// }
while (true) {
String url = "https://www.hanbit.co.kr/store/books/new_book_list.html?page=" + i;
// jsoup을 통해서 doc객체 생성
Document doc = Jsoup.connect(url).get();
// 찾고자 하는 Elements를 찾아서 검색
// 배열을 반환
Elements list = doc.select(".book_tit");
if (doc.selectFirst(".no-list") != null) {
break;
}
// Elements images = doc.select(".thumb");
// for (Element e:images) {
// System.out.println(e.attr("src"));
// }
for (Element e : list) {
// 첫번째 자식 Element를 반환
Element a = e.firstElementChild();
// attr로 속성 접근
String link = base + a.attr("href");
String text = a.text();
bookList.add(new NewBook(text, link));
}
// for (int j = 0; j < list.size(); j++) {
// Element a = list.get(j).firstElementChild();
// // 도서 상세 주소
// String link = base + a.attr("href");
// // 도서명
// String text = a.text();
//
// Element image = images.get(j);
// String addr = image.attr("src");
//
// imageDownload(base+addr, text.replaceAll("[/?!@#:'\']", ""));
// System.out.println("이미지 다운 완료");
// bookList.add(new NewBook(text, link));
// }
i++;
}
} catch (Exception e) {
System.out.println(e.getMessage());
}
return bookList;
}3. 전체 페이지의 이미지와 도서명 가져오기, newbook 페이징
<script>
$(function () {
var arr;
var pageSize = 30; // 한 화면에 보여줄 레코드의 수
var totalRecord;
var totalPage;
var pageGroup = 5; // 한 화면에 보여줄 페이지의 수
// 페이징 그룹화 및 페이징
function printPage(pageNum) {
$("#paging").empty();
var startPage = Math.floor((pageNum - 1) / pageGroup) * pageGroup + 1;
var endpage = startPage + pageGroup - 1;
// 이전 버튼 생성
if (startPage > 1) {
var span = $("<span></span>").html("이전")
.addClass("page").attr("pageNum", startPage - 1);
$("#paging").append(span);
}
for (i = startPage; i <= endpage; i++) {
var span = $("<span></span>").html(i)
.addClass("page").attr("pageNum", i);
$("#paging").append(span);
}
// 다음 버튼 생성
if (endpage < totalPage) {
var span = $("<span></span>").html("다음")
.addClass("page").attr("pageNum", endpage + 1);
$("#paging").append(span);
}
}
// 현재 페이지 번호 맞는 도서30개 가져오기
function loadDate(pageNum) {
// 값을 지우고 넣어야한다
$("#list").empty();
var start = (pageNum - 1) * pageSize;
var end = pageNum * pageSize
if (end > totalRecord) {
end = totalRecord;
}
for (i = start; i < end; i++) {
var book = arr[i];
var title = book.title;
var link = book.link;
var a = $("<a></a>").html(title).attr("href", link);
var li = $("<li></li>");
$(li).append(a);
$("#list").append(li);
}
printPage(pageNum);
}
// 페이징을 위한 함수
/*
function printPage(){
for (i = 1; i <= totalPage; i++) {
var span = $("<span></span>").html(i)
.addClass("page");
$("#paging").append(span);
}
}
*/
$("#paging").on("click", ".page", function () {
var pageNum = eval($(this).attr("pageNum"));
loadDate(pageNum);
});
$.ajax({
url: "/newbook",
success: function (r) {
arr = r;
totalRecord = arr.length;
totalPage = Math.ceil(totalRecord / pageSize);
loadDate(1);
//printPage();
/*
$.each(arr, function(){
var title = this.title;
var link = this.link;
var a = $("<a></a>").html(title).attr("href",link);
var li = $("<li></li>");
$(li).append(a);
$("#list").append(li);
});
*/
}
});
$.ajax({
url:"/getWating",
success: function (r){
$("#wait").html(r);
}
});
});
</script>이미지 저장 코드
public void imageDownload(String addr, String fname) {
try {
URL url = new URL(addr);
InputStream is = url.openStream();
FileOutputStream fos = new FileOutputStream("C:/data/"+fname+".jpg");
FileCopyUtils.copy(is.readAllBytes(), fos);
is.close();
fos.close();
} catch (Exception e) {
System.out.println(e.getMessage());
}
}4. 빈자리 구하기
마포평생학습관 자리 사진 주소
http://mpllc-seat.sen.go.kr/seatinfo/Seat_Info/1_count.asp
@GetMapping("/seats")
// public String seats() {
// String r = "";
// try {
// String url = "http://mpllc-seat.sen.go.kr/seatinfo/Seat_Info/1_count.asp";
// Document doc= Jsoup.connect(url).get();
// r = doc.select(".wating_f").get(0).text();
// }catch (Exception e) {
// System.out.println("예외발생:"+e.getMessage());
// }
// return r;
// }다른 버전 : http://mpllc-seat.sen.go.kr/seatinfo
@GetMapping("/getWating")
public int getWating() {
int cnt = 0;
// String url = "http://mpllc-seat.sen.go.kr/seatinfo/Seat_Info/1_count.asp";
String url = "http://mpllc-seat.sen.go.kr/seatinfo/";
try {
Document doc = Jsoup.connect(url).get();
Elements iframe = doc.select("iframe");
url += iframe.get(0).attr("src");
doc = Jsoup.connect(url).get();
// Elements list = doc.select(".wating_f");
Element e = doc.select(".wating_f").get(0);
cnt = Integer.parseInt(e.text());
System.out.println(cnt);
} catch (Exception e) {
System.out.println(e.getMessage());
}
return cnt;
}