SQL이란?
Structured Query Language의 줄임말로써, 번역하면 구조적인 Query언어를 의미
SQL은 관계형 데이터베이스 관리 시스템(RDBMS)의 데이터를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어이다.
관계형 데이터베이스 관리 시스템에서 자료의 검색과 관리, 데이터베이스 스키마 생성과 수정, 데이터베이스 객체 접근 조정 관리를 위해 고안되었다.
많은 수의 데이터베이스 관련 프로그램들이 SQL을 표준으로 채택하고 있다.
SQL 실행 순서
SQL → Syntax Check → Semantic Check → Library Cache Check → Optimization → Raw Source Generation → Execution
- SQL: 쿼리 실행
- Syntax Check: 문법 체크
- Semantic Check: 객체(Object) 및 권한 유무 체크
- Library Cache Check: Cache에서 쿼리 저장 유무 검사 → 저장되어 있다면 Sofrt Parse로, Library Cache에 저장된 쿼리 바로 사용 → 저장되어 있지 않으면 Hard Parse로 다음 단계로 넘어간다.
- Optimization: 최적화한 쿼리 실행 계획을 만드는 단계
- Raw Source Generation: 위 Optimization 단계에서 생성된 실행 계획을 실제 실행할 수 있게 Formatting
- Execution: 실행
쿼리(Query)란?
직역하면 "질의문" 이라는 뜻
조금더 풀어 쓰자면 저장되어져 있는 정보를 필터하기 위한 질문
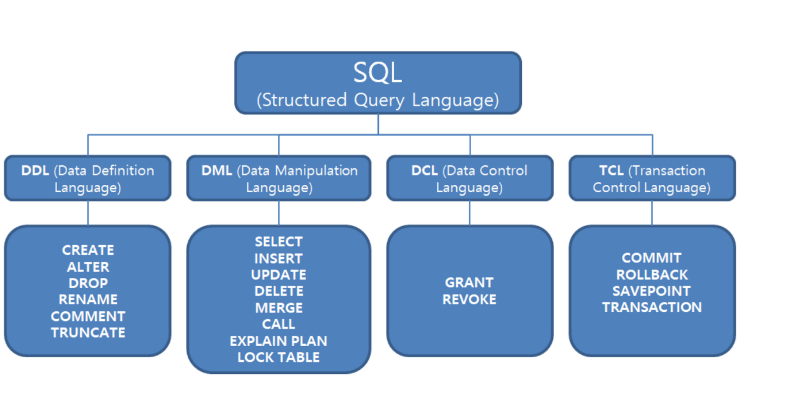
DDL (Data Definition Language): 데이터 정의 언어
DDL이란?
- 테이블과 컬럼을 정의하는 명령어로 생성, 수정, 삭제 등의 데이터 전체 골격을 결정하는 역할을 담당한다.
DDL 특징
- DDL은 명령어를 입력하는 순간 작업이 즉시 반영(Auto Commit)되기 때문에 사용할 때 주의해야 한다.
DDL 종류
| 명령어 | 내용 |
|---|---|
| CREATE | 테이블을 생성하는 역할 |
| ALTER | 테이블의 구조를 수정하는 역할 |
| DROP | 테이블을 삭제하는 역할 |
| RENAME | 테이블을 이름을 변경하는 역할 |
| TRUNCATE | 테이블을 초기화하는 역할 |
CREATE 규칙
- 객체를 의미하는 것이므로 단수형으로 이름을 짓는걸 권고한다.
- 유일한 이름으로 명명해야 한다.
- 테이블 내의 컬럼명 또한 중복되지 않는 유일한 이름으로 명명해야 한다.
- 정의할 때 각 컬럼은 ,으로 구분하며 테이블 생성문의 마지막은 ;이다.
- 컬럼명은 데이터 표준화 관점에서 일관성 있게 사용해야 한다.
- 컬럼 뒤에 데이터 유형을 반드시 지정해야 한다.
- 테이블과 컬럼명은 반드시 문자로 시작한다.
- 대소문자 구분을 하지 않지만, 기본적으로 대문자로 만들어진다.
ALTER: 컬럼 변경 문법
| 명령어 | 내용 |
|---|---|
| ADD COLUMN | 컬럼을 추가하는 역할 |
| DROP COLUMN | 컬럼을 삭제하는 역할 |
| MODIFY COLUMN | 컬럼을 수정하는 역할 |
| RENAME COLUMN | 컬럼 이름을 변경하는 역할 |
| DROP CONSTRAIN | 컬럼을 제약조건을 기반해서 삭제하는 역할 |
DML (Data Manipulation Language): 데이터 조작 언어
DML이란?
- 데이터베이스의 내부 데이터를 관리하기 위한 언어이다. 데이터를 조회, 추가, 변경, 삭제 등의 작업을 수행하기 위해 사용된다.
DML 특징
- DDL과 달리 DML은 적는 즉시 반영(Auto Commit)이 되기 않는다. 다시 말해, DML에 의한 데이터 변동은 영구적인 변경이 아니기 때문에 ROLLBACK으로 다시 되돌릴 수 있다.
- 또한, DML은 Target 테이블을 메모리 버퍼 위에 올려두고 변경을 수행하기 때문에, 실시간으로 테이블에 반영되지 않는다. Commit 명령어를 통해 Transaction을 종료해야 해당 변경 사항이 테이블에 반영된다.
DML 종류
| 명령어 | 내용 |
|---|---|
| SELECT | 데이터베이스에서 데이터를 검색하는 역할 |
| INSERT | 테이블에 데이터를 추가하는 역할 |
| UPDATE | 테이블 내에 존재하는 데이터를 수정하는 역할 |
| DELETE | 테이블에서 데이터를 삭제하는 역할 |
DCL (Data Control Language): 데이터 제어 언어
DCL이란?
- 데이터를 관리 목적으로 보안, 무결성, 회복, 병행 제어 등을 정의하는데 사용한다. DCL을 사용하면 데이터베이스에 접근하여 읽거나 쓰는 것을 제한할 수 있는 권한을 부여하거나 박탈할 수 있고 트랜잭션을 명시하거나 조작할 수 있다.
DCL 특징
- 불법적인 사용자로부터 데이터를 보호하기 위한 데이터 보안의 역할을 수행하며, 데이터의 정확성을 위한 무결성을 유지하기도 한다. 마지막으로 시스템 장애에 대비한 회복과 병행수행을 제어한다.
DCL 종류
| 명령어 | 내용 |
|---|---|
| GRANT | 권한을 정의할때 사용하는 명령어 |
| REVOKE | 권한을 삭제할때 사용하는 명령어 |
TCL (Transaction Control Language): 트랜잭션 제어 언어
TCL이란?
- DCL과 비슷한 맥락이지만 데이터를 제어하는 언어가 아닌 트랜잭션을 제어할때 사용한다. 논리적인 작업 단위를 묶어 DML에 의해 조작된 결과를 트랜잭션 별로 제어한다.
트랜잭션(Transaction)이란?
- 데이터베이스의 상태를 변화시키기 위해 수행하는 작업의 단위를 말한다. 보통 DBMS 선능을 초당 트랜잭션이 몇개가 실행되었는지로 측정한다.
트랜잭션의 필요성: 은행 업무를 볼 때, A계좌에서 B계좌로 100만원을 옮기려는데 A계좌에서 돈이 나간 순간 데이터베이스에 오류가나서 B에도 돈이 안들어 오고 A의 계좌 잔액도 0이 되어 버리면 정말 심각한 문제가 발생할 수 있다.
이러한 데이터 유실이라는 무시무시한 상황이 일어나는 것을 막으려면 두 가지 방법을 생각해볼 수 있다.
1 어떤 상황에서든 두 UPDATE문을 모두 완전히 실행하는 것
2 완전히 실행하는 것이 불가능 하다면, 두 UPDATE문을 실행하기 전의 상태,
즉 아무 UPDATE문도 실행하지 않는 상태를 유지할 수 있어야 한다.
트랜잭션(Transaction) 단위
게시판을 예로 들어보자. 1) 게시판 사용자는 게시글을 작성하고, 올리기 버튼을 누른다. 2) 그러면 글 올리기가 처리되고 자동으로 다시 게시판에 돌아오게 된다. 3) 게시판에서 자신의 글이 포함된 업데이트된 게시글들을 볼 수 있다.이러한 상황을 데이터베이스 작업으로 옮기면, 사용자가 올리기 버튼을 눌렀을 시, Insert 문을 사용하여 사용자가 입력한 게시글의 데이터를 넣는다.그 후에, 게시판을 구성할 데이터를 다시 Select 하여 최신 정보로 유지한다. 여기서 작업의 단위는 insert문과 select문 둘다 를 합친것이다. 이러한 작업단위를 하나의 트랜잭션이라 한다.
트랜잭션 특징 4가지
- 원자성(Atomicity)
- 원자성은 트랜잭션이 데이터베이스에 모두 반영되던가, 아니면 전혀 반영되지 않아야 한다는 것이다. 트랜잭션은 사람이 설계한 논리적인 작업 단위로서, 일처리는 트랜잭션의 작업이 부분적으로 실행되다가 중단되 않고 작업단위 별로 이루어져야 사람이 다루는데 무리가 없다.
- 일관성(Consistency)
- 일관성은 트랜잭션의 작업 처리 결과가 항상 일관성이 있어야 한다는 것이다. 즉, 데이터 타입이 반환 후와 전이 항상 동일해야 한다. 트랜잭션이 진행되는 동안에 데이터베이스가 변경 되더라도 업데이트된 데이터베이스로 트랜잭션이 진행되는것이 아니라, 처음에 트랜잭션을 진행 하기 위해 참조한 데이터베이스로 진행된다. 예시) 갑자기 데이터 타입이 정수형에서 문자열로 변화하면 안됨
- 독립성(Isolation)
- 독립성은 하나의 트랜잭션은 다른 트랜잭션에 끼어들 수 없고 마찬가지로 독립적임을 의미한다. 각각의 트랜잭션은 서로 간섭이 불가하기 때문에 하나의 특정 트랜잭션이 완료될때까지, 다른 트랜잭션이 특정 트랜잭션의 결과를 참조할 수 없다.
- 지속성(Dutability)
지속성은 트랜잭션이 성공적으로 완료되었을 경우, 결과는 영구적으로 반영되어야 한다는 점이다. 보통 Commit이 완료되면 지속성은 자연스럽게 충족되는 특징이다.
트랜잭션의 상태 5가지
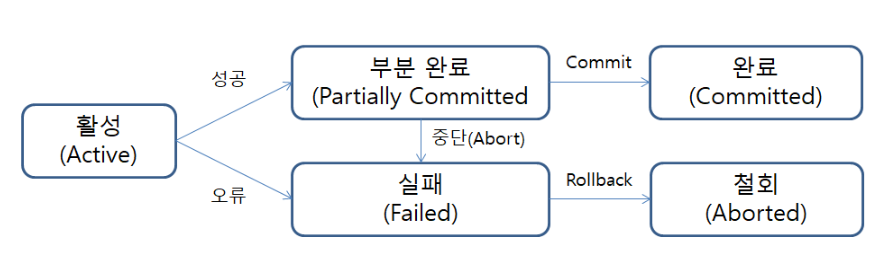
- 활성(Active) : 트랜잭션이 정상적으로 실행중인 상태를 의미한다.
트랜잭션이 시작되면, 해당 트랜잭션의 상태는 활동(Active)상태가 된다. 해당 상태는 설계자가 설계한 대로 연산들이 정상적으로 실행중인 상태를 의미한다.
작업 성공시
2-1. 부분 완료(Partially Committed) : 트랜잭션의 마지막까지 실행되었지만, Commit 연산이 실행되기 직전의 상태
2-2. 완료(Committed) : 트랜잭션이 성공이 종료되어 Commit 연산을 실행한 후의 상태
설계된 트랜잭션대로 명령을 성공적으로 수행하면 그 다음 상태는 부분적 완료(Partially Committed)상태가 된다. 설계된 작업대로 작업이 성공하였다고 하여 무조건 반영하는 것이 아니라, 설계자의 최종 승인(Commit)이 있을 때 까지 실제 데이터베이스에 작업 내용을 반영하지 않고 기다리고 있는 상태이다.설계자가 작업 결과에 대하여 반영을 승인(Commit)한다면 트랜잭션이 성공적으로 종료된다(Committed)
작업 실패시
2-1. 실패(Failed) : 트랜잭션 실행에 오류가 발생하여 중단된 상태.
2-2. 철회(Aborted) : 트랜잭션이 비정상적으로 종료되어 Rollback 연산을 수행한 상태.
트랜잭션을 수행하는 중간에 모종의 원인으로 인하여 오류가 발생하여 실행이 중단된 상태를 실패(Failed)상태라고 한다.이때 트랜잭션이 비정상적으로 종료되었으니, 설계되어있는 트랜잭션 내부의 작업을 다시 수행 이전의 상태로 돌리는 (ROLLBACK) 연산을 수행하면 그 상태를 철회(Aborted)라고 한다.
트랜잭션의 Commit과 Rollback
Commit
- Commit은 모든 작업들을 정상 처리하겠다고 확정하는 명령어이다.
- 해당 처리 과정을 DB에 영구 저장하겠다는 의미로 Commit을 수행하면 하나의 트랜잭션 과정이 종료된다.
- Commit을 하기 전에는 다른 사용자가 트랜잭션 내용을 확인할 수 없다. 또한, 변경된 행은 잠금이 설정되어 있어서 다른 사용자가 변경할 수 없다.
Rollback
- Roll-back은 작업 중 문제가 발생되어 트랜잭션의 처리 과정에서 발생한 변경사항을 취소하는 명령어이다.
- 해당 명령을 트랜잭션에게 하달하면 트랜잭션은 Commit 되기 이전의 데이터오 돌아가 변경에 대하여 취소한다.
- 관련된 행에 대한 잠금이 풀리고 데이터 변경 사항이 복구되는 것이다.
TCL 종류
| 명령어 | 내용 |
|---|---|
| COMMIT | 모든 작업을 정상적으로 처리하겠다는 명령어 |
| ROLLBACK | 모든 작업을 다시 돌려 놓겠다는 명령어 |
| SAVEPOINT | Commit 전에 특정 시점까지만 반영하거나 Rollback하겠다는 명령어 |
TRUNCATE와 DELETE
DELETE FROM TABLE
- 시스템 부하가 크다. 데이터 전체를 삭제 하는것이 아니라 복구할 수 있게끔 삭세하기 때문에 메모리를 많이 차지한다. 하지만 반대로 정상적인 복구가 가능성이 높다.
TRUNCATE TABLE
- 시스템 부하가 적다. DELETE와 다르게 데이터 전체를 날려버리기 때문에 메모리를 많이 차지 하지 않는다. 하지만 이때문에 정상적인 데이터 복구가 불가능하다.
DISTINCT와 GROUP BY
DISTINCT
- DISTINCT 키워드를 사용하여 데이터 중복을 제거할 때는 DISTINCT 키워드만 명시하면 되므로 쿼리문이 간결하다. 하지만 TEMP TABLESPCE를 생성하여 임시로 저장하고 작업하는 방식이라 시스템 부하가 크다.
GROUP BY
- GROUP BY 절을 이용하면 간결하게 명시할 수 있으며 DISTINCT와 다르게 시스템 부하가 적다.
SQL 쿼리문
오라클 DB 계정추가
CREATE DATABASE
- 데이터 베이스를 새로 생성할 때 사용.
CREATE DATABASE [데이터베이스 명]DROP
- 데이터 베이스 자체를 삭제할때 사용
DROP DATABASE [데이터베이스 명]모든 데이터베이스 조회
SHOW DATABASES;sys 관리자 계정 비밀번호 변경
alter user sys identified by 1234; -- sys 계정의 암호를 1234로 변경새로운 계정 만들기
create user [계정명] identified by [비밀번호];
create user test identified by 1234;권한 부여 하기
grant [권한1], [권한2] ... to [계정명];
grant connect, resource, dba to test;권한 해지
REVOKE [권한1], [권한2..] USER FROM [유저명];
REVOKE [오브젝트권한] ON [유저명].[테이블명] FROM [권한을부여할유저명];| 명령어 | 설명 |
|---|---|
| RESOURCE | 개체 생성, 변경, 제거 권한 |
| CONNECT | DB 연결 권한 |
| DBA | DB 관리자 권한 |
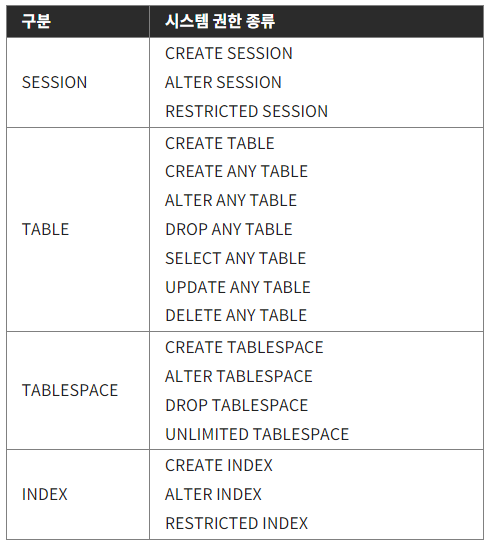
시스템 권한
CREATE SESSION (데이터베이스 접속 권한)
GRANT CREATE SESSION TO [사용자명]
GRANT CREATE SESSION TO scott;사용자를 생성 후 세션 권한이 부여되어야 데이터베이스 접속이 가능하다.
세션 권한이 부여되지 않은 상태에서 데이터베이스 접속을 하면 아래와 같은 오류가 발생한다.
ORA-01045: 사용자 SCOTT는 CREATE SESSION 권한을 가지고있지 않음; 로그온이 거절되었습니다
CREATE TABLE (테이블 생성 권한)
GRANT CREATE TABLE TO scott;테이블 생성 권한이 부여되면 자신의 스키마(scott)에 테이블 생성 및 삭제가 가능하다.
GRANT CREATE ANY TABLE TO scott;
GRANT DROP ANY TABLE TO scott;CREATE ANY TABLE 권한을 부여하면 다른 사용자의 스키마에 테이블을 생성할 수 있다. 예를 들어 hr이라는 스키마에 테이블을 생성할 수 있으며, DROP ANY TABLE 권한이 부여되어야 다른 스키마에 생성한 테이블을 삭제할 수 있다.
UNLIMITED TABLESPACE (테이블스페이스 사용 권한)
GRANT UNLIMITED TABLESPACE TO scott;UNLIMITED TABLESPACE 권한은 모든 테이블스페이스를 제한 없이 사용할 수 있는 권한이다. 일반 사용자가 모든 테이블스페이스를 제한 없이 사용하는 것은 운영 측면에서 좋지 않기 때문에 아래와 같이 사용할 것을 권장한다.
ALTER USER scott QUOTA 10M ON tblspace1;ALTER USER [사용자명] QUOTA [제한용량] ON [테이블스페이스명]
해당 사용자에 지정된 테이블스페이스에 제한용량 및 권한을 부여할 수 있다.
CREATE INDEX (인덱스 생성 권한)
GRANT CREATE ANY INDEX TO scott;
GRANT DROP ANY INDEX TO scott;CREATE ANY INDEX, DROP ANY INDEX 권한을 부여하면 인덱스 생성 및 제거를 할 수 있다.
권한 회수(제거) 방법 (REVOKE)
REVOKE CREATE SESSION FROM scott;
REVOKE CREATE TABLE FROM scott;
REVOKE DROP ANY TABLE FROM scott;
REVOKE CREATE ANY TABLE FROM scott;
REVOKE UNLIMITED TABLESPACE FROM scott;
REVOKE CREATE ANY INDEX FROM scott;
REVOKE DROP ANY INDEX FROM scott;REVOKE [권한 구분] FROM [사용자명]
REVOKE 문을 사용하여 부여된 권한을 회수(제거) 할 수 있다.
시스템 권한 부여 방법 정리
테이블 다루기
테이블 조회하기
SHOW TABLES;테이블 구조 확인하기
DESC [테이블명];테이블 생성하기
create table member (
name varchar2(10),
userid varchar2(10),
pwd varchar2(10)
);생성된 테이블 조회
select * from [테이블명];테이블 삭제하기
DROP DATABASE기존 테이블에서 새로운 필드 추가 / 삭제
필드 추가
alter table 테이블명 add 추가필드명 데이터타입;기존 필드 삭제
alter table 테이블명 drop column 삭제필드명; (데이터 타입 안써도 된다)기존 테이블 구조 변경
컬럼명 변경
ALTER TABLE 테이블명 RENAME COLUMN 컬럼명 TO 변경컬럼명;테이블에 이미 존재하는 컬럼 수정
ALTER TABLE 테이블명 MODIFY (컬럼명 변경데이터 타입 OR 제약조건);
ALTER TABLE test MODIFY (job VARCHAR(30));
ALTER TABLE EMP MODIFY (NUMBER DEFAULT 0);
ALTER TABLE EMP MODIFY (ENAME CONSTRAINTS EMP_ENAME_NN NOT NULL);단, NOT NULL을 제외한 제약조건은 수정 불가하므로 삭제 후 재생성
데이터 다루기
SELECT
SELECT 컬럼명 FROM 테이블명- 테이블명에 해당하는 테이블의 칼럼명에 데이터를 불러는 구문
- 모든 칼럼을 불러오고 싶을 때는 컬럼 명부분에 ' * ' 사용
WHERE - 특정 조건만 조회하기
SELECT 컬럼명 FROM 테이블명 WHERE 조건- WHERE 구문을 추가해서 WHERE절 뒤에 오는 조건이 참인 데이터만 불러온다
- [ 컬럼명 = 값 ]으로 적을 경우 컬럼 명의 값이 지정한 값인 데이터행의 데이터만 불러온다
- 관계 연산자 / 논리 연산자 사용 가능
논리 연산자 AND, OR 사용 가능
SELECT * FROM 테이블명 WHERE height between 160 and 165;- between 연산자를 이용하여 특정 범위에 해당하는 데이터를 조회할 수 있다.
- 160이상 165이하 데이터 조회
IN () - 여러 값 매칭
SELECT * FROM 테이블명
WHERE addr IN('경기', '전남', '경남');
SELECT * FROM 테이블명
WHERE addr = '경기' AND addr = '전남' AND addr = '경남';- IN() 연산자를 이용하여 특정 값이 포함된 데이터를 조회할 수 있다.
- IN 연산자는 동등비교 '=' 를 여러번 수행하는 효과를 가진다. 따라서 인덱스를 최적으로 활용할 수 있다.
LIKE - 문자열의 일부 글자 검색
-- mem_name 컬럼 값이 '블'로 시작하는 4글자 글자 데이터 조회
SELECT * FROM 테이블명 WHERE mem_name LIKE '블___';
-- mem_name 컬럼 값이 '블'로 시작하는 모든 데이터 조회
SELECT * FROM 테이블명 WHERE mem_name LIKE '블%';
-- mem_name 컬럼 값에 '블'이 들어가는 모든 데이터 조회
SELECT * FROM 테이블명 WHERE mem_name LIKE '%블%';_ : 한 글자만 매치
% : 몇 글자든 매치
ORDER BY - 조회된 데이터를 정렬
SELECT 컬럼명 FROM 테이블명 WHERE 조건 ORDER BY 컬럼명 ASC or DESC- ORDER BY 뒤에 오는 칼럼명을 기준으로 대하여 불러오는 데이터를 정렬
- WHERE 절 다음에 나와야 함
- ASC는 오름차순, DESC는 내림차순입니다 기본값은 오름차순으로 정렬
- 콤마 , 로 여러 정렬 조건 지정 가능
LIMIT - 출력 개수 제한
SELECT 컬러명 FROM 테이블명 WHERE 조건 ORDER BY 컬럼명 ASC or DESC LIMIT 개수- LIMIT 구문을 추가하여 데이터행이 많을 때에는 LIMIT절의 개수만큼 데이터를 불러온다
DISTINCT - 중복 데이터 제거
SELECT DISTINCT addr FROM 테이블명;- DISTINCT를 열 이름 앞에 붙이면 중복된 값은 1개만 출력된다.
GROUP BY - 그룹화
SELECT [컬럼명], ....
FROM 테이블명
GROUP BY [그룹할 컬럼명];- 컬럼이 같은 데이터를 그룹화 해주는 기능
- 보통 집계 함수와 같이 쓰임
- ORDER BY앞에 온다
집계 함수 (Aggregate Function)
- SUM() : 컬럼의 합계를 반환
- AVG() : 컬럼의 평균을 반환
- MIN() : 컬럼의 최소값을 반환
- MAX() : 컬럼의 최대값을 반환
- COUNT() : 행의 개수를 셈
- COUNT(DISTINCT) : 행의 개수를 셈
COUNT()
-- member 테이블의 모든 데이터 개수를 셈
SELECT COUNT(*)
FROM member;
-- member 테이블의 phone1 컬럼이 NULL인 것을 제외한 모든 데이터 개수를 셈
SELECT COUNT(phone1)
FROM member;- COUNT(*) 연산은 모든 row를 대상으로 이루어지기 때문에 NULL값이 포함되어있어도 카운트됨
- COUNT(phone1) 연산은 phone1 값에 NULL이 있을 경우 카운트하지 않음
HAVING - 그룹 조건
SELECT 컬럼명
FROM 테이블명
GROUP BY 그룹할 컬럼명
HAVING 그룹할 컬럼에 대한 조건;- 그룹화된 데이터에 대해서 조건을 제한함
- GROUP BY 뒤에 와야함
INSERT
데이터를 삽입하는 쿼리문
INSERT INTO 테이블명 (칼럼명1, 칼럼명2, 칼럼명3) VALUES (값1, 값2, 값3)- 테이블명에 있는 칼럼명에 순서에 맞게 값을 입력합니다, 칼럼명과 값의 개수는 동일해야한다
- 만약에 문자열을 값으로 입력하는 경우에는 작은따옴표로 문자열을 감싸줘야 한다
INSERT INTO 테이블명 VALUES (값1, 값2, 값3)- 테이블명 다음에 칼럼명을 입력하지 않은 경우입니다 이 경우는 테이블에 모든 칼럼에 값을 입력한다는 의미로 모든 칼럼의 수에 맞게 값을 줘야한다
UPDATE
데이터를 수정하는 쿼리문
UPDATE 테이블명 SET 칼럼명 = 변경할 값- 테이블에 있는 모든 데이터의 칼럼 값을 변경
UPDATE 테이블명 SET 칼럼명 = 변경할 값 WHERE 조건- WHERE절에 조건에 해당하는 데이터만 변경
UPDATE 테이블명 SET 칼럼명1 = 변경할 값1, 칼럼명2 = 변경할 값2 WHERE 조건- 변경할 칼럼이 여러 개일 때 콤마( , )를 사용하여 여러 개 값을 변경
DELETE
테이블에 데이터를 삭제하는 쿼리문
DELETE FROM 테이블명- 테이블에 있는 모든 데이터를 삭제
DELETE FROM 테이블명 WHERE 조건- WHERE절에 조건에 합하는 데이터만 삭제
참고
https://velog.io/@alicesykim95/DB-DDL-DML-DCL-TCL%EC%9D%B4%EB%9E%80
https://inpa.tistory.com/entry/MYSQL-%F0%9F%93%9A-%ED%8A%B8%EB%9E%9C%EC%9E%AD%EC%85%98Transaction-%EC%9D%B4%EB%9E%80-%F0%9F%92%AF-%EC%A0%95%EB%A6%AC
https://gent.tistory.com/534
https://jy-beak.tistory.com/15
