
탐색 알고리즘 중 스택 자료 구조를 사용하는 깊이우선탐색을 알아보자.
DFS란?
Depth-First Search; 깊이 우선 탐색
그래프나 트리를 탐색하는 알고리즘 중 하나인 DFS는 스택 자료구조로 작업을 한다. DFS는 모든 경우를 탐색(완전탐색)하는 특징을 갖는다.
재귀
BFS와의 차이점은 DFS는 재귀와 관련되었다는 것이다. 따라서 모든 경우를 탐색하는 구조로 작성되긴 하지만 경우에 따라 과도하게 호출이 이루어질 때, 경우가 커짐에 따라 시간복잡도가 과도하게 커질 가능성이 있다.
구현이라는 관점에서 볼 때, 조건을 만족하는 경우 조기에 함수를 중단하고 답을 반환할 필요가 있다.
이 경우에 관한 내용은 아래 게임 맵 최단 거리 문제 해결 과정에서 확인 할 수 있다.
백트래킹
참고로 DFS의 한 형태인 백트래킹은 조건에 따라 뒤로 되돌아갈 수 있기에 완전탐색이라는 단점을 보안할 수 있다.
백트래킹에 관한 내용은 이곳에서 확인
DFS의 동작 원리
탐색 과정은 크게 3단계로 진행된다.
-
탐색 시작 노드를 스택에서 삽입하고 방문 처리한다.
-
스택의 최상단 노드에 방문하지 않은 인접 노드가 있으면, 그 노드를 스택에 넣고 방문처리한다.
방문하지 않은 인접노드가 없으면 스택의 최상단 노드를 꺼낸다. -
2번의 과정을 반복하여 더 이상 수행 할수 없을 때까지 한다.
아래와 같은 그래프가 있다고 하자.
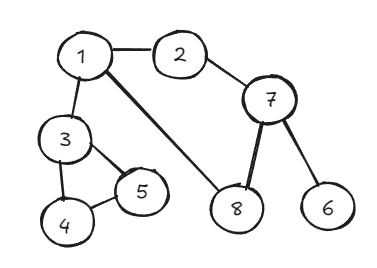
1번 노드부터 탐색을 시작하면 다음과 같은 과정을 통해 방문 순서를 알 수 있다.
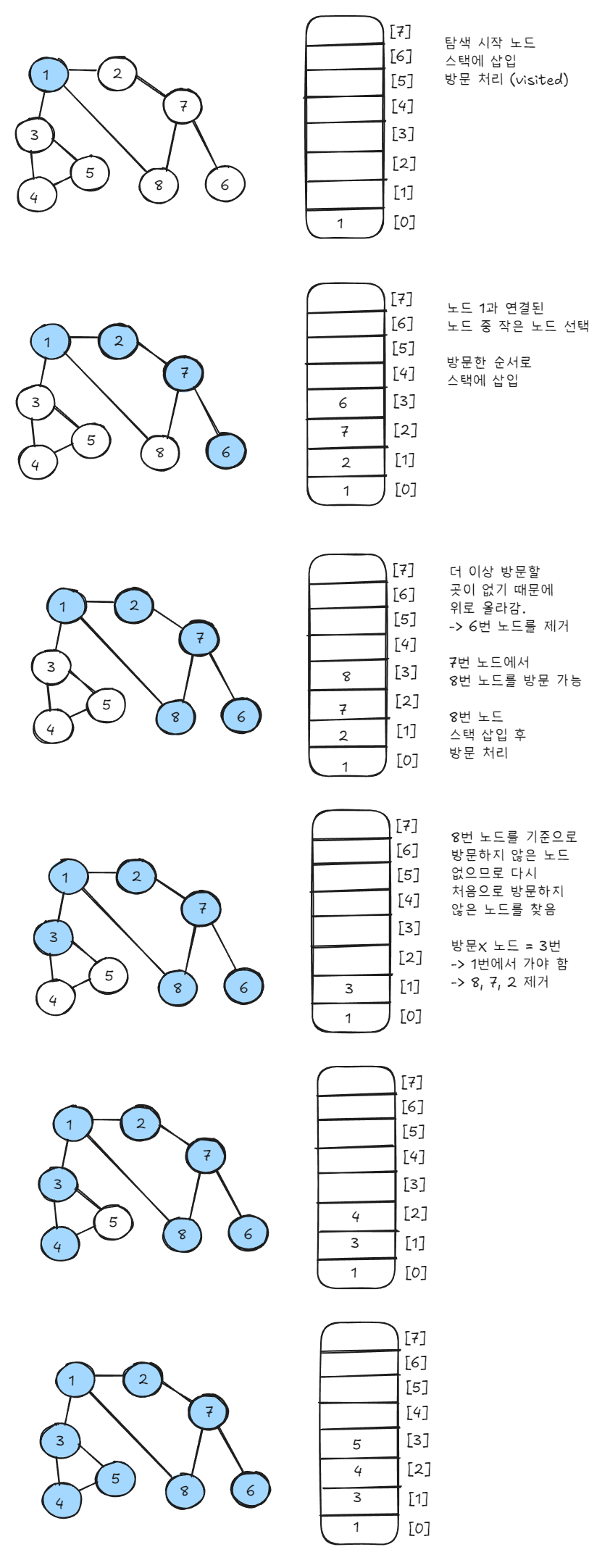
방문한 순서
1 → 2 → 7 → 6 → 8 → 3 → 4 → 5
코드로 구현
위의 과정을 코드로 구현하면 다음과 같다.
graph = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
visited = [False] * 9
def dfs(s, v, visited):
visited[v] = True
print(v, end=' ')
for i in s[v]:
if not visited[i]:
dfs(s, i, visited)
dfs(graph, 1, visited)graph는 인접 리스트의 형태로 표현하였다. 0번 노드는 없으므로 비워두었다. (인덱스를 노드 번호로 사용하기 위함) 가중치 그래프가 아니므로 노드 번호 별로 연결된 노드를 배열로 저장했다.
visited는 방문 여부를 확인하기 위해 초기값을 False로 세팅해두었다.
dfs로 함수를 선언하였다. v(vertex)는 각각의 노드 번호다.
함수에 들어온 노드는 visited리스트에 해당 노드의 (인덱스로 접근) 방문 처리가 되며, 방문 순서를 출력하기 위해 출력한다.
이후 graph에서 해당 노드로 접근한다. 해당 노드는 i 노드와 연결되어 있다. 각각의 노드의 방문 여부를 따진다. 이는 visited에 저장되어 있다.
해당 노드가 방문 되지 않았다면 (visited[i] 가 False라면) 다시 dfs 함수를 호출하여 탐색을 진행한다.
참고로 DFS는 파이썬의 list로 스택처럼 구현할 수 있어 별도 자료구조 선언이 필요 없지만, BFS는 큐 구조가 필요하므로 deque를 사용하는 것이 일반적이다.
dq = deque([])와 같은 구조를 볼 수 있음
문제
1. 타겟넘버
주어진 숫자의 배열을 더하는 경우와 뺴는 경우 전부를 확인해야 하는 완전탐색의 문제다.
내 풀이
def search_tree(graph, path, start, end, result):
if start == end:
result.append(sum(path))
return
path.append(graph[start][0])
search_tree(graph, path, start+1, end, result)
path.pop()
path.append(graph[start][1])
search_tree(graph, path, start+1, end, result)
path.pop()
def solution(numbers, target):
result = []
search_tree([(i, -i) for i in numbers], [], 0, len(numbers), result)
return result.count(target)작성한 코드의 문제점
- path 필요 없음
- sum 연산이 매번 수행
- 다리를 지나는 트럭 문제를 풀며 리스트의 sum 연산으로 인해 시간초과가 난 경험이 있었다.
- 현재 문제에서는 시간초과가 발생하지는 않았지만 불필요한 리스트의 sum 연산은 주의할 필요가 있다.
개선된 코드
다른 사람의 코드로 dfs로 문제를 해결하는 구조를 이해해 보았다.
def solution(numbers, target):
if not numbers:
return 1 if target == 0 else 0
return solution(numbers[1:], target+numbers[0]) + solution(numbers[1:], target-numbers[0])해당 풀이는 파이썬의 슬라이싱과 인덱스를 사용하여 주어진 nunbers 리스트를 순차적으로 이동하고 있다.
탐색의 시작을 두가지 경우로 나누었다.
- 첫 숫자를 더하는 경우
+numbers[0] - 빼는 경우
-numbers[0]
문제에서는 탐색 결과를 만족하는 경우의 개수를 묻고 있으므로solution(...) + solution(...)을 통해 총 합을 구할 수 있다.
- (탐색을 마쳤을 때 0 또는 1이 반환됨.)
시각화
numbers = [4, 1, 2, 1], target = 4 인 경우 코드가 동작하는 구조를 그림으로 표현해보았다.
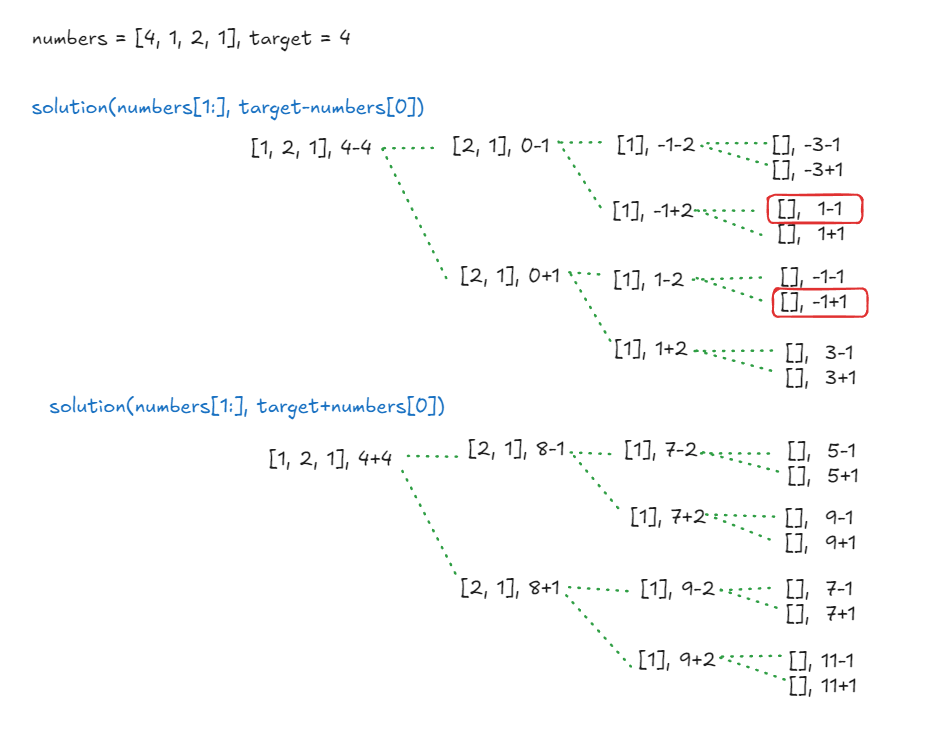
총 만큼의 탐색이 이루어지며(완전탐색) 최종 결과 2개가 target == 0을 만족하므로 최종 답이 0+0+1+0+0+1+0+0+0+0+0+0+0+0+0+0 = 2 로 계산되어 2가 반환된다.

깊이 우선 탐색에 대해 깊이 잘 읽었습니다.