
최단 경로
코딩테스트 문제 중 최단 경로를 구하는 문제가 있다. 목적지로 이동하기 위한 가장 빠른 경로를 찾는 문제인데, 주로 각각의 지점(공간) 간의 이동 시간 혹은 거리가 주어진 상태에서 최소 시간, 최단 거리를 요구한다.
문제 내에 그림이 제시된다면 바로 알 수 있겠지만 그래프로 해결하는 문제이다.
- 각각의 지점 : vertex(node)
- 특정 지점에서 특정 지점으로의 이동 가능 여부 : edge(간선)
- 이동 시간/거리 : 가중치
최단 경로 알고리즘
- 다익스트라 알고리즘
- 벨만-포드 알고리즘
- 프로이드 워셜 알고리즘
다익스트라 알고리즘이란?
여러 노드가 있을 때 특정한 노드에서 출발하여 다른 노드로 가는 각각의 최단 경로를 구하는 알고리즘이다. 음의 간선이 존재 하지 않을 때 사용할 수 있다. 참고로 음의 간선을 가질 수 있는 알고리즘으로는 벨만-포드 알고리즘이 있다.
다익스트라 알고리즘은 가장 작은 비용의 적은 노드를 선택하여 그리디 알고리즘으로 분류된다.
최단경로를 구하는 다익스트라 알고리즘은 가중치가 있는 그래프에서 활용된다. 최단경로를 구할 때 가중치는 이동 거리 혹은 시간이 된다.
가중치 그래프
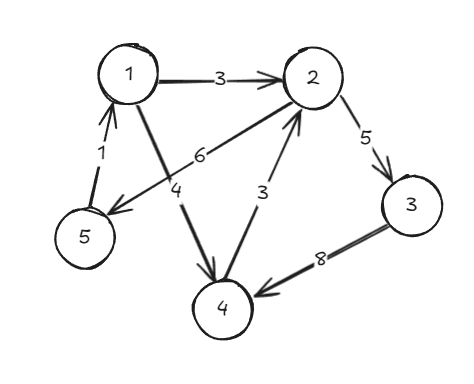
위의 그래프는 가중치 그래프의 예시이다. 방향 그래프로 표현하였으며 특정 노드에서 특정 노드로 이동하는 데에 각각의 가중치가 부여되어 있다. 그래프의 연결된 구조를 다음과 같이 나타낼 수 있다.
1 → 2 (3)
1 → 4 (4)
2 → 3 (5)
2 → 5 (6)
3 → 4 (8)
4 → 2 (3)
5 → 1 (1) 인접리스트
프로그래밍에서 그래프는 인접리스트의 형태로 나타낸다. 인접리스트란 리스트를 이용하여 그래프 혹은 트리의 연결 구조를 표현하는 방식이다. 아래처럼 2차원의 리스트를 이용하거나 딕셔너리를 이용하여 그래프를 표현한다.
graph = [
[],
[(2, 3), (4, 4)],
[(3, 5), (5, 6)],
[(4, 8)],
[(2, 3)],
[(1, 1)],
]구조
graph[i]
- 각각의 리스트에는 i번 노드가 향하는 노드와 가중치가 튜플로 담겨있다. 노드 0은 없기 때문에 빈 리스트로 두었다.
graph[i][j]
- 튜플 형태로
graph[i][j][0]는 i번 노드가 향하는 노드를 담았고graph[i][j][1]는 i번 노드가 특정 노드로 갈 때의 가중치를 담았다.
가중치 그래프를 코드로 표현하는 방법을 알았으니, 이제 다익스트라 알고리즘의 동작 원리를 이해하고 이를 코드로 구현해보자!
동작 원리
다음과 같은 그래프로 다익스트라의 동작 원리를 살펴보겠다.
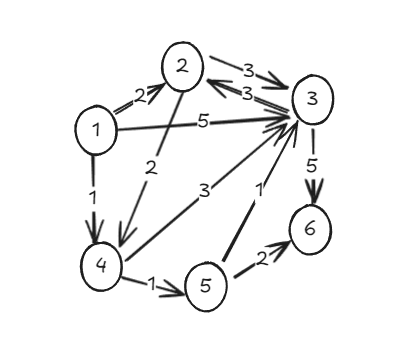
위에서 가중치 그래프를 인접리스트로 표현하는 방법을 알아보았다. 동작 원리를 구현할 때 위의 그래프 또한 인접리스트의 형태로 동일하게 표현한다.
동작 순서
- 출발 노드를 설정한다.
- 최단 거리 테이블(1차원 리스트)을 초기화한다.
- 초기화에는 무한(INF)을 사용한다.
- 참고) 간선이 없는 노드 간의 관계는 '무한' 이라고 하며, 프로그램에서는 'INF'로 표현
- 방문하지 않은 노드 중에서 최단거리가 가장 짧은 노드를 선택한다.
- 해당 노드를 거쳐 다른 노드로 가는 비용(가중치)을 계산하여 최단 거리 테이블을 갱신
- 그리디 알고리즘으로 분류되는 이유다.
- 위 과정 중 3번, 4번을 반복한다.
시각화
위의 그래프를 예시로 구현 코드와 연결지어 이해할 수 있도록 그림으로 표현해 보았다. (graph는 예시 그래프, visited와 distance는 코드 초기 설정과 동일)
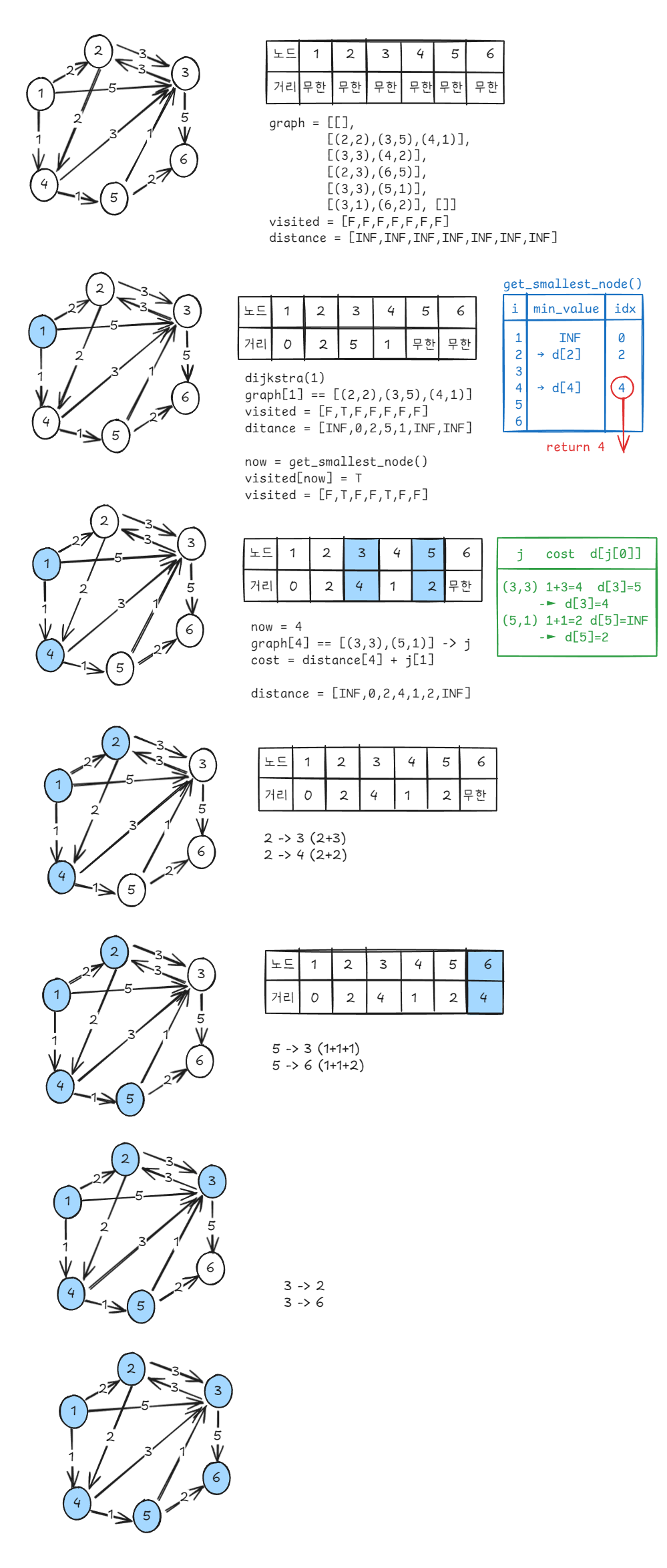
코드를 기준으로 시각화하였기 때문에 위의 그림을 참고하되 정확한 동작 원리는 아래의 코드를 보며 이해해보도록 하자.
코드 구현
INF 설정
자기 자신의 노드에서 그 다음 노드를 방문하기 전까지의 가중치 값은 무한대로 표시하므로 다음과 같이 INF를 설정하고 가중치 테이블을 INF로 초기화 한다.
INF = int(1e9) # 무한대
distance = [INF] * (n + 1) # 가중치 테이블- 1e9는 파이썬에서 부동소수점 방식으로 표현된 10억 (1,000,000,000)을 의미한다. ()
- 파이썬에서
1e9는 float로 간주되므로 int로 형변환
그래프 입력
코드에서의 그래프 형태 부분은 사용자의 입력을 받도록 구현하였다.
-
노드와 간선의 개수를 입력받는다.
n, m = map(int, input().split()) #노드 n개, 간선 m개 -
입력받은 노드 개수
n을 기준으로 해당 노드a가 향하는 (연결된)노드b와 가중치c를 입력 받는다.for _ in range(m): a, b, c = map(int, input().split()) graph[a].append((b, c))
Dijkstra
dijkstra(start)
우선 시작점을 받아서 시작 노드에서 인접한 노드를 찾아 가중치를 갱신 한 뒤 탐색을 시작한다.
다익스트라 알고리즘은 하나의 시작점에서 다른 모든 정점까지의 최단 경로를 찾는 알고리즘이다. 따라서 for _ in range(n-1) 는 각각의 정점의 최단 경로를 찾는 구조로 볼 수 있다.
그래프 알고리즘이므로 방문 가능 조건에 순환을 확인할 필요 없다.
방문한 노드에 대해서는 가중치를 누적하여 갱신해야 한다. 다만 그 값이 현재의 가중치보다 작을 때만 해당된다. 갱신된다는 것은 더 적은 비용으로 이동하는 새로운 루트를 찾았음을 뜻한다.
for _ in range(n-1):
now = get_smallest_node() # 다음 이동할 노드
if now == 0:
break
visited[now] = True # 방문처리
for j in graph[now]:
cost = distance[now] + j[1]
if cost < distance[j[0]]:
distance[j[0]] = cost방문할 다음 노드 찾기
get_smallest_node()
다익스트라 알고리즘은 방문할 다음 노드를 탐색하는 기준이 가중치의 누적값이다. 따라서 아래는 방문하지 않은 노드 중에서 가중치 값이 가장 작은 노드를 찾는 함수다.
min_value를 INF로 초기화하여 작은 값을 찾는다. 시작 노드의 가중치는 0 이므로 반복문을 돌릴때 시작 노드 이후부터 확인하도록 한다. (각 노드의 가중치) < min_value 로 INF가 아닌 값이 들어왔을 경우 해당 값으로 min_value가 갱신된다.
반복이 끝나면 index가 반환된다. 그럼 해당 인덱스가 탐색의 결과로 다음 방문할 노드가 된다. 조건을 모두 만족하지 않은 경우 index가 갱신되지 못하고 0이 되는데, 이는 알고리즘의 종료 시점으로 볼 수 있다. 남은 노드들이 모두 INF 거리(= 시작점에서 경로가 없음)거나 이미 방문한 상태라는 뜻이다.
def get_smallest_node():
min_value = INF
index = 0
for i in range(1, n+1): # 시작 노드 제외
if (distance[i] < min_value) and not visited[i]:
min_value = distance[i]
index = i
return index우선순위 큐
가중치 테이블에서 뽑아내고 싶은 값은 항상 가장 작은 값이다. 내부의 값 중 가장 작은 값(혹은 큰 값)을 pop 할 수 있는 자료구조가 바로 우선순위 큐다. 우선순위 큐는 파이썬의 heapq 모듈을 사용하여 쉽게 구현할 수 있다.
파이썬의 heapq 모듈
heapq는 파이썬의 list를 완전 이진 트리의 배열 표현으로 간주하고, heappush, heappop, heapify 등을 통해 그 리스트를 최소 힙(min-heap) 속성이 유지되도록 재배치한다.
- heapq.heapify(배열) : 최소 힙 상태로 만든다.
- heapq.heappush(배열, 값) : 최소 힙 상태를 유지하며 푸쉬
- heapq.heappop(배열) : 최소 힙 상태를 유지하며 팝
from heapq import heapify, heappush, heappop
mylist = [4, 3, 8, 1, 0]
heapify(mylist) # [0, 1, 8, 4, 3]
print(mylist)
min_num = heappop(mylist)
print(min_num) # 0 코드 구현
- heapq 모듈을 사용한 코드와 사용하지 않은 코드 2가지를 알아보자
코드 1
# 표준 입력을 더 빠르게 읽기 위한 단축 설정(한줄로 읽어옴)
# 기본 입력 함수 input()은 좀 느릴 수 있음
import sys
input = sys.stdin.readline
# ========= 그래프 설정 =========
INF = int(1e9) # 무한대
n, m = map(int, input().split()) # 노드 개수 n,
start = int(input()) # 시작 노드 설정
graph = [[] for _ in range(n+1)] # 인접 리스트
visited = [False] * (n + 1) # 방문 테이블(과거)
distance = [INF] * (n + 1) # 가중치 테이블(비용)
# 방향 그래프 a → b (가중치 c)
for _ in range(m):
a, b, c = map(int, input().split())
graph[a].append((b, c))
# ========= 다익스트라 =========
def get_smallest_node():
# 가중치 누적값으로 노드를 선택한다 (당장의 가중치 X)
min_value = INF # 처음 비교를 위한 초기값을 INF로 세팅
index = 0
# 방문한 노드 중 가중치가 작은 노드 찾기
for i in range(1, n+1):
if (distance[i] < min_value) and not visited[i]:
# 가장 작은 가중치를 가진 노드를 찾기 위함
min_value = distance[i]
index = i
return index # 방문할 노드 반환. 0 반환 가능
def dijkstra(start):
# 시작 설정
distance[start] = 0 # 시작점의 가중치는 0
visited[start] = True # 방문 처리
for j in graph[start]: # 해당 노드와 인접한 노드 찾기
distance[j[0]] = j[1] # 인접한 노드들의 가중치 갱신
# 탐색 시작
# 가중치를 기준으로 남은 노드 수(시작노드를 제외)만큼 반복함
for _ in range(n-1):
now = get_smallest_node() # 다음 이동할 노드 now
if now == 0: # 더 이상 방문할 노드가 없는 경우
break
visited[now] = True # 방문처리
# 새로운 노드에서 가중치 갱신
for j in graph[now]:
cost = distance[now] + j[1]
# 최소 비용인 경우 갱신
if cost < distance[j[0]]:
distance[j[0]] = cost
# ========= 실행 부분 =========
dijkstra(start)
for i in range(1, n+1):
if distance[i] == INF:
print("INF")
else:
print(distance[i])코드 2 (heapq)
- 그래프는 위와 동일한 형태로 주어졌다고 가정
from heapq import heappop, heappush
visited = [False] * (n + 1)
distance = [INF] * (n + 1)
hq = [] # 최소 힙
def dijkstra(start):
distance[start] = 0
visited[start] = True
heappush(hq, (0, start)) # (가중치, 노드번호)
while hq:
cost, vertex = heappop(hq)
# 이미 짧은 경로로 갱신된 노드는 패스
if cost != distance[vertex]:
continue
# 시작인 0은 같으므로 not continue
# (노드, 가중치)
for v, w in graph[vertex]: # 인접 노드 탐색
next_cost = cost + w
# 작은 값일 때 갱신 후 최소힙에 추가
if next_cost < distance[v]:
distance[v] = next_cost
heappush(hq, (next_cost, v))
dijkstra(start)
다다익선스트라