머신러닝 1주차 이어서 ~~
< 데이터 셋 분할 >
- Training set (학습 데이터셋, 트레이닝셋) = 교과서
머신러닝 모델을 학습시키는 용도로 사용한다. 전체 데이터셋의 약 80% 정도를 차지.
- Validation set (검증 데이터셋, 밸리데이션셋) = 모의고사
머신러닝 모델의 성능을 검증하고 튜닝하는 지표의 용도로 사용한다.이 데이터는 정답 라벨이 있고,
학습 단계에서 사용하기는 하지만, 모델에게 데이터를 직접 보여주지는 않으므로 모델의 성능에 영향을 미치지는 않는다.
손실 함수, Optimizer 등을 바꾸면서 모델을 검증하는 용도로 사용합니다.
전체 데이터셋의 약 20% 정도를 차지.
- Test set (평가 데이터셋, 테스트셋) = 수능
정답 라벨이 없는 실제 환경에서의 평가 데이터셋이다. 검증 데이터셋으로 평가된 모델이 아무리 정확도가 높더라도
사용자가 사용하는 제품에서 제대로 동작하지 않는다면 소용이 없다.
< Colab >
Colaboratory 란?
구글에서 만든 개활 환경.
Colab 패키지 불러오기
import numpy as np
from matplotlib import pyplot as plt\
Kaggle이란?
- 데이터 사이언티스트를 위한 커뮤니티.
kaggle username = sonsanghun
kaggle key = f059267b38e0b44ebb7e64af5ba1eb6d
< 머신러닝 2주차 >
< 논리 회귀 >
- sigmoid를 써서 0,1로 나누고 CrossEntropy를 써서 최소화함.
< 다항 논리 회귀 >
- Softmax를 쓰고 똑같이 CrossEntropy를 쓴다.

- random forest란? 민주주의라고 생각하면 됨. 가장 많이 뽑힌, 투표가 많은 것이 최종 답이 됨.
- 전처리(Preprocessing)란? 전처리는 넓은 범위의 데이터 정제 작업을 뜻합니다. 필요없는 데이터를 지우고 필요한 데이터만을 취하는 것, null 값이 있는 행을 삭제하는 것, 정규화(Normalization), 표준화(Standardization) 등의 많은 작업들을 포함하고 있습니다.
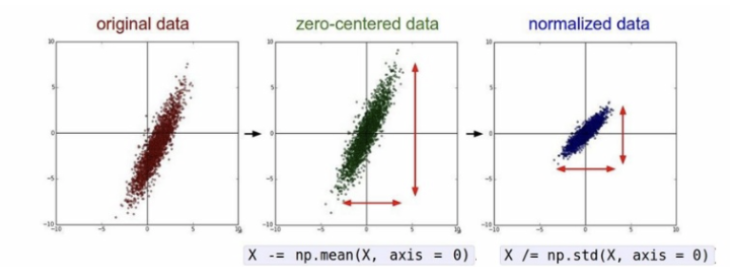
- 전처리(Preprocessing)란? 전처리는 넓은 범위의 데이터 정제 작업을 뜻합니다. 필요없는 데이터를 지우고 필요한 데이터만을 취하는 것, null 값이 있는 행을 삭제하는 것, 정규화(Normalization), 표준화(Standardization) 등의 많은 작업들을 포함하고 있습니다.
< 거북이반 장고 복습반 >
< git 장고시작 명령어 >
- venv 생성 python -m venv venv
- source ./venv/scripts/activate
- pip install django
- git init
- 깃 초기화
- ls -a
- 숨겨진 파일까지 다 나온다.
- ls -al
- 숨겨진 파일까지 리스트로 보겠다.
- cd .git
- 깃 폴더를 들어감.
8.django-admin startproject django_project . - 띄고 . 은 현재폴더안에서 만들어준다.
- git remote add origin 깃허브주소
remote란 원격이다. - git hub
remote 반대는 local - 깃허브를 올리기 전 명령어
add . 와 commit을 해야 된다. 이후 push를 하면 된다. - git reset
add . 한 파일들을 초기화 시킨다. - .gitignore을 해준다.
- venv파일은 수천가지이기 때문에 깃허브에 다 올라가면 곤란하다.
- touch .gitignore을 해주면 파일생성.
- git commit -m 'init project'
- master에서 main으로 바꿔주기
- git config --global init.defaultBranch main 후 git init을 해줘야 적용됨.
- git commit만 했을 시 내용입력하기
- i를 누르고 커밋내용상세하게 적고 esc후 :w 저장 후 q 나가기쓰기.
- git push origin main
- add . 이랑 commit 후 마지막으로 파일 푸쉬해주기.
- pip3 freeze > requirements.txt
- 무슨 패키지를 설치했는데 보여줄 텍스트 파일을 추가해줌.
- git branch users
- 브랜치 생성
- git checkout use
- use 폴더로 감
- git hub에서 pull request하기 (merge하기)
- git pull해서 github원격에서 local로 가져오기
- mkdir test
- 테스트란 파일을 만듬
- rm hello.txt
- 헬로우 텍스트파일을 날림.
- rm -r test
- 폴더안에 있는 전부를 지울때 씀
- rm -rf test
- yes,no 뜰 경우를 대비해 전부를 강제지움

< 코린이의 코딩모험기 >