데이터 수집 아키텍처
Metric data?
일정 기간 걸쳐 측정된 성능, 수치 데이터를 의미한다.
server1 과 server2는 ELK로 서버 로그 수집하고 시각화하기를 위해 구축한 서버를 그대로 사용했다.
데이터 수집 테스트를 위해 사용할 아키텍처는 다음과 같다.
- Prometheus가 Metric data를 스크랩(polling)한다.
- Grafana가 같은 서버에 있는 Prometheus에서 data를 조회해서 시각화한다. (data가 대용량이라면 Grafana와 Prometheus를 다른 서버에서 사용하는 것이 좋다.)
- 외부에서 시각화를 확인한다.
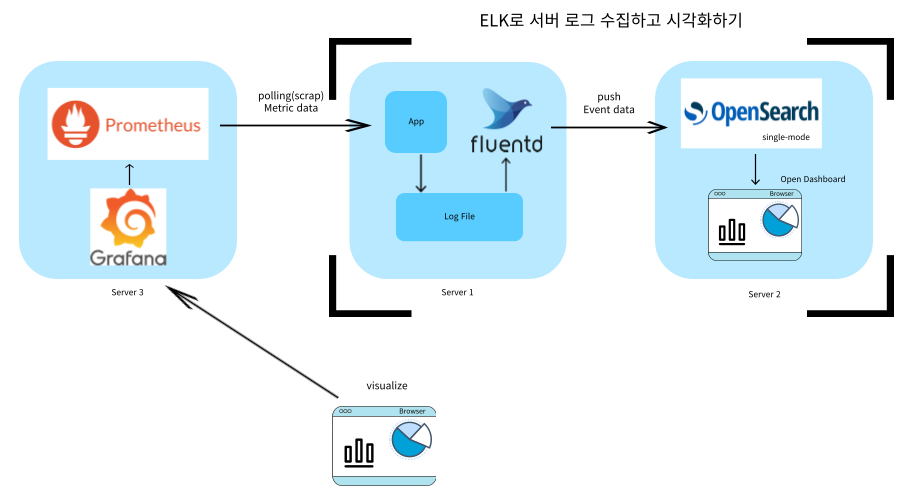
Log 저장소로는 Opensearch(Elasticsearch)를, Metric 저장소로는 Prometheus(저장 + 수집)를, 실시간 통합 모니터링 대시보드는 Grafana를, Log 검색은 Opensearch Dashboard(Kibana)로 구성한다.
통합 모니터링 대시보드로 Opensearch Dashboard(Kibana)를 이용할 수 있으나, Grafana가 성능 측면이나 다른 툴들과의 상호작용에서 강력한 면이 있다.
Prometheus 설치하기
Prometheus 설치
파일 다운로드
wget https://github.com/prometheus/prometheus/releases/download/v2.40.6/prometheus-2.40.6.linux-amd64.tar.gz설치 가능한 패키지 리스트를 최신화 + build-essential 설치
sudo apt update
sudo apt install build-essential -y설치 + 경로 저장
tar xvfz prometheus-*.tar.gz
mv prometheus-2.40.6.linux-amd64 prometheus
cd prometheus
export PROMETHEUS_HOME=$(pwd)실행
./prometheus --config.file=prometheus.yml확인
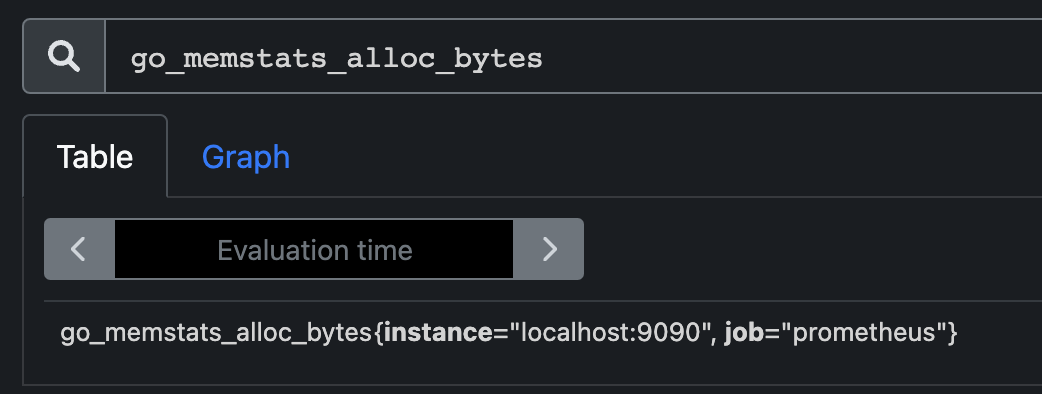
- 다음과 같이
localhost:9090/graph에서 metric 이름으로 검색하면 instance와 job을 확인할 수 있다.
prometheus 데이터 확인 (스스로 자신의 metric data를 수집) : localhost:9090/metrics

prometheus 의 데이터를 검색할 수 있는 사이트 : localhost:9090/graph
systemctl 로 등록
설정파일
sudo vi /etc/systemd/system/prometheus.service내용
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io/docs/introduction/overview/
Wants=network-online.target
After=network-online.target
[Service]
User=$USER
Group=$USER
Restart=on-failure
WorkingDirectory=$PROMETHEUS_HOME
ExecStart=$PROMETHEUS_HOME/prometheus \
--config.file=$PROMETHEUS_HOME/prometheus.yml \
--web.console.templates=$PROMETHEUS_HOME/consoles \
--web.console.libraries=$PROMETHEUS_HOME/console_libraries \
--web.enable-admin-api
[Install]
WantedBy=multi-user.targe등록
sudo systemctl daemon-reload활성화
sudo systemctl enable prometheus.service"Failed to execute operation: Invalid argument" 메세지가 뜬다면
prometheus.service 파일을 다시 확인하자 (붙혀넣는 과정에서 파일에 문자 인코딩이나 필요 없는 공백 철자 오류 등이 있을 수 있음) 참고
systemctl로 prometheus 시작
sudo systemctl start prometheus.service프로세스 상태 확인
ps -ef | grep prometheusPrometheus Push gateway 설치하기
다운로드
wget https://github.com/prometheus/pushgateway/releases/download/v1.5.1/pushgateway-1.5.1.linux-amd64.tar.gz압축해제 후 폴더 만들기
tar xvfz pushgateway-*.tar.gz
mv pushgateway-1.5.1.linux-amd64 pushgateway폴더로 이동 후 실행
cd pushgateway
./pushgateway확인
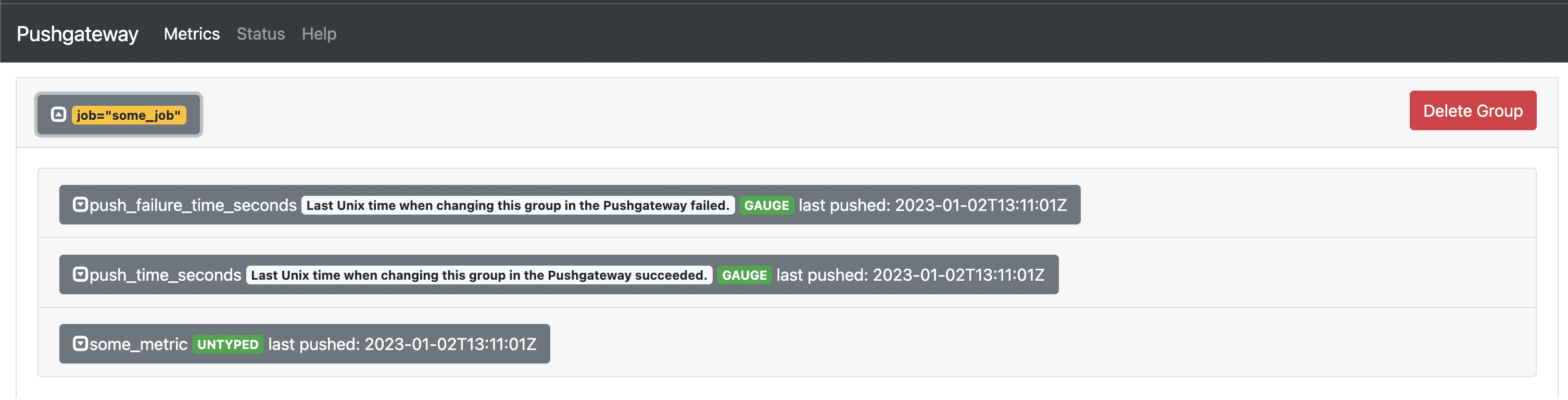
- pushgateway 는 localhost:9091 에 뜬다. - web ui 를 볼 수 있다.
- 현재 저장된 메트릭 정보는 /metrics path 를 활용한다.
some_metric{job=”some_job”} 을 pushgateway 에 전송
echo "some_metric 3.14" | curl -XPOST --data-binary @- http://$IP:9091/metrics/job/some_job확인 완료
systemctl로 등록
sudo vi /etc/systemd/system/pushgateway.service내용 추가
$USER = ubuntu
$PUSHGATEWAY_HOME = /home/ubuntu/pushgateway
-
--web.listen-address=":9091" \ : 9091 포트를 사용
-
--web.telemetry-path="/metrics" \ : 자기 자신의 metric 정보를 보려면 localhost:9091/metrics 로 접속한다
-
--persistence.file="$PUSHGATEWAY_HOME/metric.store" \ (option) :
$PUSHGATEWAY_HOME/metric.store파일에 받은 metric 정보를 저장한다.
--persistence.interval=5m \ : metric 정보를 5분 간격으로 저장한다.
[Unit]
Description=Pushgateway
Wants=network-online.target
After=network-online.target
[Service]
User=$USER
Group=$USER
Type=simple
ExecStart=$PUSHGATEWAY_HOME/pushgateway \
--web.listen-address=":9091" \
--web.telemetry-path="/metrics" \
--persistence.file="$PUSHGATEWAY_HOME/metric.store" \
--persistence.interval=5m \
--log.level="info" \
[Install]
WantedBy=multi-user.target등록
sudo systemctl daemon-reload
sudo systemctl enable pushgateway.servicesystemctl로 pushgateway 시작
sudo systemctl start pushgateway.service확인
ps -ef | grep pushgatewayPrometheus 에서 Pushgateway 를 scrap 하도록 세팅
$PROMETHEUS_HOME/prometheus.yml을 수정하여 prometheus의 scrap 목록에 pushgateway를 추가해준다.
scrap_configs의 하위에 다음 내용을 추가.
- $PUSHGATEWAY_IP : localhost_ip
- 들여쓰기 조심할 것
- job_name: 'pushgateway'
honor_labels: true
static_configs:
- targets: ['$PUSHGATEWAY_IP:9091']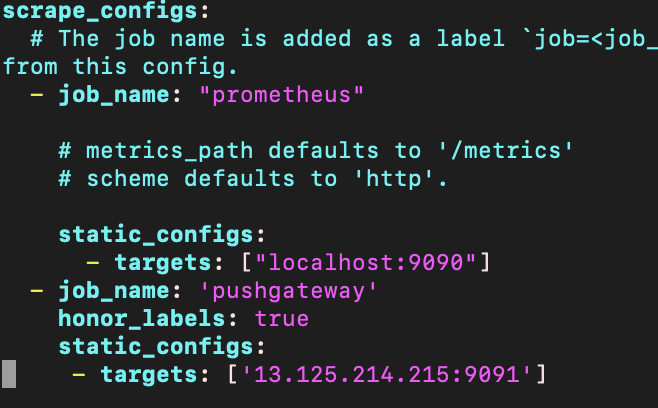
systemctl 을 통해 prometheus 를 재기동한다.
sudo systemctl daemon-reload
sudo systemctl stop prometheus.service
sudo systemctl start prometheus.service재기동을 확인
ps -ef | grep prometheusprometheus 서버의 graph 에서 some_metric. 이 조회되는지 확인.
Prometheus Data
Prometheus Data 예시
// 주석, 데이터를 남기는 유저가 설정 가능
# HELP go_memstats_sys_bytes Number of bytes obtained from system.
// metric data의 타입
# TYPE go_memstats_sys_bytes gauge
// metric 이름과 value(숫자값 or 문자열)
go_memstats_sys_bytes 4.598708e+07
# HELP go_threads Number of OS threads created.
# TYPE go_threads gauge
go_threads 9
# HELP net_conntrack_dialer_conn_attempted_total Total number of connections attempted by the given dialer a given name.
# TYPE net_conntrack_dialer_conn_attempted_total counter
// {} 안에 라벨이 위치함 {label key = "value(string)"} / , 를 통해 여러가지 라벨을 붙힐 수 있음
net_conntrack_dialer_conn_attempted_total{dialer_name="alertmanager"} 0
net_conntrack_dialer_conn_attempted_total{dialer_name="default"} 0
net_conntrack_dialer_conn_attempted_total{dialer_name="prometheus"} 1Prometheus data model
프로메테우스 스토리지는 데이터를 time series로 저장한다. 다만 Prometheus 데이터 모델 자체는 time을 가지고 있지 않다. scrap 하는 쪽(프로메테우스 서버)에서 time 정보를 기록한다.
Prometheus 용 데이터 포맷이 있다. 불필요한 문법 없이 필요한 정보만 명확하게 표시된다는 장점이 있다.
3.1.1 Format
# HELP <metric name> description
# TYPE <metric name> <type name>
<metric name>{<label name>=<label value>, ...} number- prometheus 로 expose 하면, # 으로 시작되는 메트릭에 대한 설명(주석)과 실제 데이터가 라인으로 분되어 기록된다.
- HELP 는 metric 남기는 유저가 기록한다.
- TYPE 은 metric 의 type 이다.
예시
# api_http_requests_total is blah blah
api_http_requests_total{method="POST", handler="/messages"} 1.0-
metric name
ASCII letters and digits 만 가능 underscore 로 띄어쓰기를 구분 metric name 은 convention guide가 있다. (아래에 자세히 기술) -
label name
ASCII letters (숫자 x) -
label values
any Unicode characters
metric name 규칙
가이드에서 발췌
should 로 표현된 것은 꼭 지켜야하는 것은 아니지만, 다른 개발자들 사이에 혼선이 없으려면 웬만하면 지키는 것이 좋다.
-
...must comply with the data model for valid characters.
-
...should have a (single-word) application prefix relevant to the domain the metric belongs to. The prefix is sometimes
referred to as namespace by client libraries. For metrics specific to an application, the prefix is usually the application name itself. Sometimes, however, metrics are more generic, like standardized metrics exported by client libraries.
접두사는 metric data가 어떤 내용에 대한 data인지를 알 수 있는 namespace 역할을 하면 좋다.
Examples:
prometheus_notifications_total (specific to the Prometheus server)
process_cpu_seconds_total (exported by many client libraries)
http_request_duration_seconds (HTTP requests에 관한 metric)- ...must have a single unit (i.e. do not mix seconds with milliseconds, or seconds with bytes).
하나의 데이터는 하나의 유닛만을 가진다.
http_request_duration_seconds 라면 second로만 서빙해야 한다. (ms로 서빙 불가)base unit이 미리 정해져 있다.
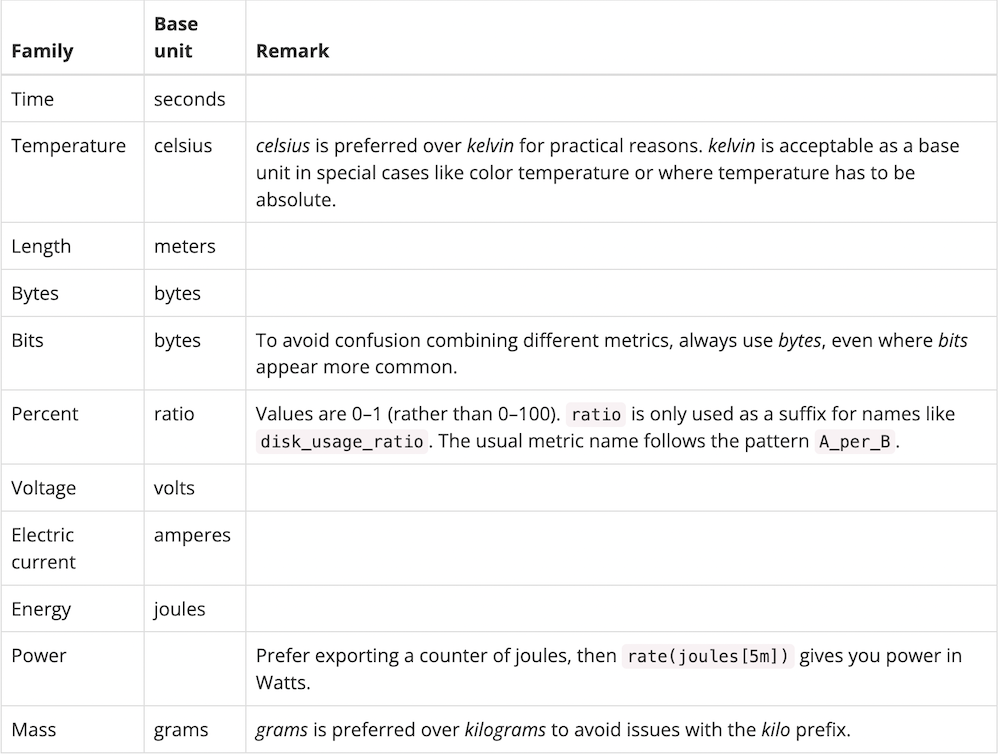
-
...should use base units (e.g. seconds, bytes, meters - not milliseconds, megabytes, kilometers). See below for a list of base units.
-
...should have a suffix describing the unit, in plural form. Note that an accumulating count has total as a suffix, in addition to the unit if applicable.
접미사는 unit이 위치하거나 count가 누적되는 경우는 total을 쓴다.
http_request_duration_seconds (seconds = unit)
node_memory_usage_bytes (bytes = unit)
http_requests_total (for a unit-less accumulating count)
process_cpu_seconds_total (for an accumulating count with unit)
foobar_build_info (for a pseudo-metric that provides metadata about the running binary)
data_pipeline_last_record_processed_timestamp_seconds (for a timestamp that tracks the time of the latest record processed in a data processing pipeline)- ...should represent the same logical thing-being-measured across all label dimensions.
request duration
bytes of data transfer
instantaneous resource usage as a percentageJob 과 Instance
-
같은 목적, 또는 같은 일을 하는 대상을 job이라고 한다.
-
job은 여러개의 instance를 가질 수 있다. 같은 job 내의 여러 instance의 구분은 instance의 이름을 다르게 해서 구성한다.
-
만약 prometheus 서버가 여러대로 클러스터 구성이 되어있다면.
job 의 value는 ”prometheus_server”
instance의 value는 ”server1”, “server2”.. 등으로 실제 서버의 이름이 올 수 있다.
실습에서는 실제 서버의 ip, port 또는 DNS 정보를 instance로 한다.Metric Type (Type name)
메트릭 정보는 크게 4가지 타입이 있다. 타입마다 사용하는 PromQL(query) 이나 대시보드의 형태가 달라진다.
Counter
Counter는 축적되는 단방향으로 증가하는 숫자 metric이다. (계속 쌓이기만 하고 돌아가지 않음) 어플리케이션이 재기동되면 다시 0부터 시작한다.
예시
number of requests
number of tasks completed
number of errors
Counter는 감소하는 숫자로 사용하면 안된다.잘못된 예시 (감소하는 숫자로 사용할 수 없음)
active thread countGauge (계기판)
Gauge 는 증가하거나 감소할 수 있는 숫자 값을 나타낼 때 쓴다.
예시
current temperatures (온도)
current memory usage (메모리)
active thread count (쓰레드 카운터)Histogram
Histogram은 관찰 대상에 대해서 sampling을 해서 버킷별로 구분해서 저장하고 조회할 수 있는 metric이다.
예시
database I/O latency - 0.99, 0.95, 0.90, 0.50 percentile
response data size - 0.99, 0.95, 0.90, 0.50 percentile
99%, 95% 의 시스템에 부정적인 값을 위주로 모니터링 한다.히스토그램은 <basename>을 기준으로 여러개의 time series 를 expose한다.
-
cumulative counters for the observation buckets, exposed as
<basename>_bucket{le="<upper inclusive bound>"} -
the total sum of all observed values, exposed as
<basename>_sum -
the count of events that have been observed, exposed as
<basename>_count(identical to<basename>_bucket{le="+Inf"}above)
histogram 으로 남은 metric 은 PromQL에서 histogram_quantile() function quantitle을 계산하고 aggregtion할 수 있다.
Summary
Summary는 Histogram 과 비슷하게 관찰 대상에 대해서 sampling을 한다. 뿐만 아니라 관찰 대상에 대한 total count 를 제공하고, 모든 관찰값에 대한 sum 도 제공한다. 이를 활용해 sliding window 에 걸쳐있는 quantitle 정보를 계산할 수 있다.
A summary with a base metric name of <basename> exposes multiple time series during a scrape:
-
streaming φ-quantiles (0 ≤ φ ≤ 1) of observed events, exposed as
<basename>{quantile="<φ>"} -
the total sum of all observed values, exposed as
<basename>_sum
Histogram과 Summary 중 어떤 것을 선택해야 할까?
-
aggregate 가 필요하면, histogram을 선택
-
1번이 아니면서, value의 범위나 분포를 보고싶다면 histogram 을 선택
-
1번이 아니면서, 정확한 quantitle 이 필요하거나, 값의 범위나 분포과 상관 없다면 summary
scrap 하는 Metric 에 대해 정확한 값을 기대하지는 않기 때문에 대부분 Histogram을 사용한다.
PromQL
prometheus metric 에 대한 집계 또는 변환 작업을 수행하는 쿼리이다.
아래는 PromQL 메뉴얼이다.
Basics
https://prometheus.io/docs/prometheus/latest/querying/basics/
Operators
https://prometheus.io/docs/prometheus/latest/querying/operators/
Functions
https://prometheus.io/docs/prometheus/latest/querying/functions/
Examples
https://prometheus.io/docs/prometheus/latest/querying/examples/
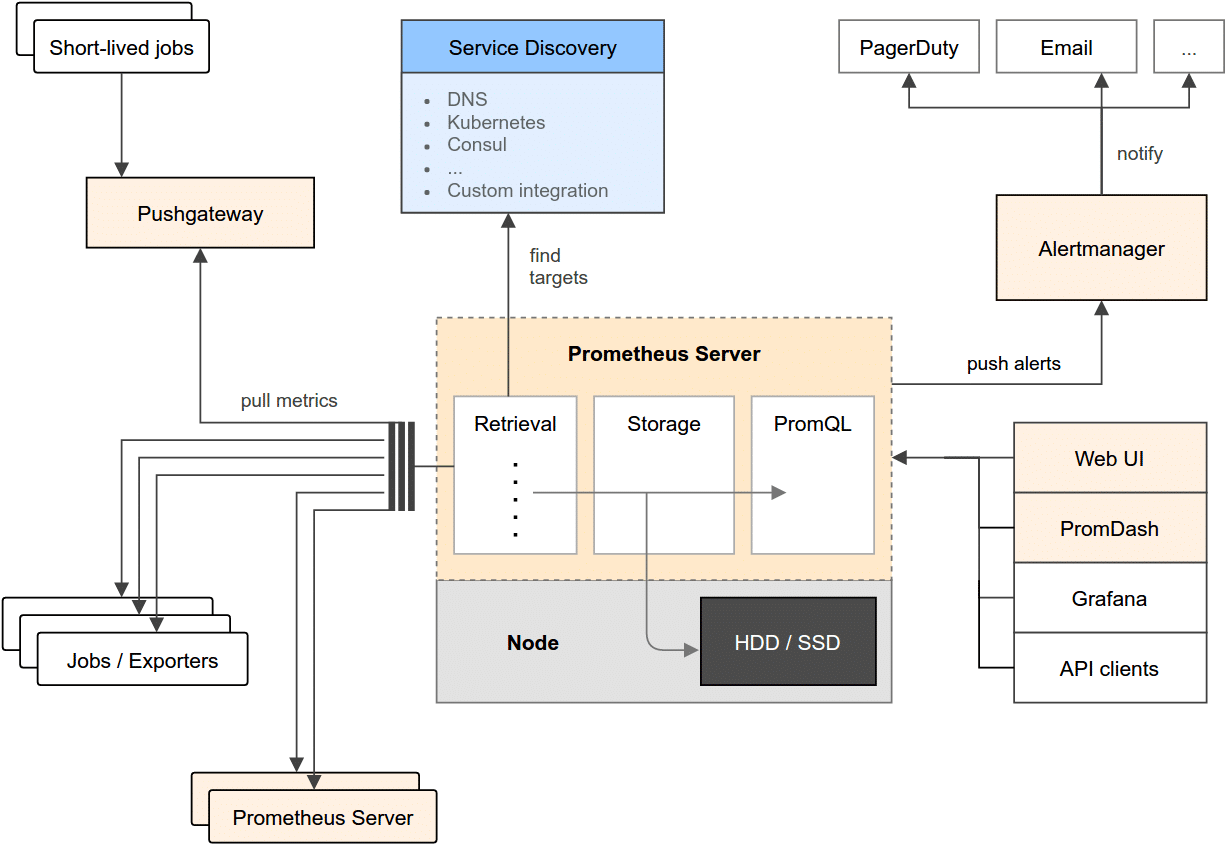
Prometheus Server
Prometheus Architecture
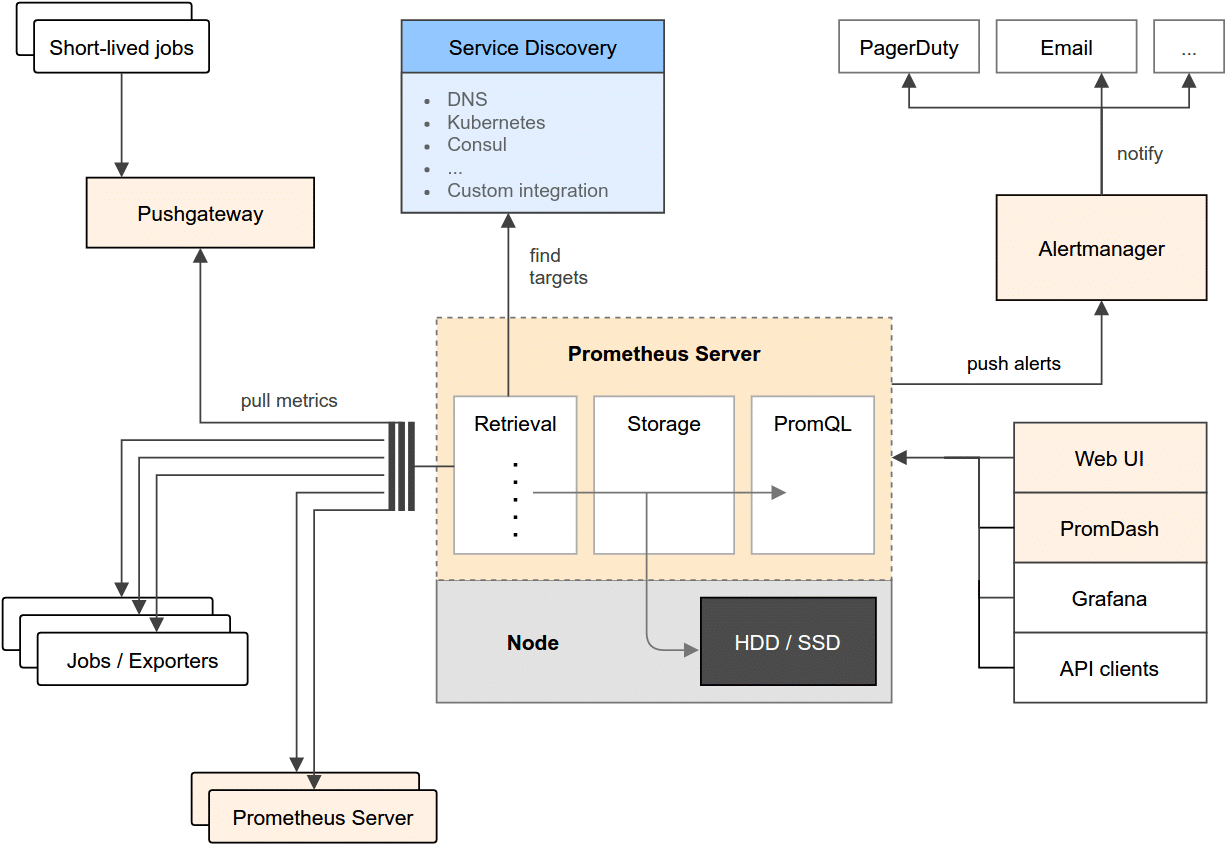
{kind=link}
Prometheus Server
내부적으로는 논리적으로 세 part로 구성된다.
- Retrieval : 수집
- Storage : 저장
- PromQL : PromQL을 받아 쿼리 수행
Prometheus Server 는 메트릭을 여러 노드로부터 수집하고, Local Storage에 저장한다. Local Storage 는 선택할 수 있지만, 기본으로 TSDB를 사용한다.
Prometheus Server 는 scraping (pull, polling) 방식으로 메트릭을 수집한다.
Metric 대상은 static 하게 설정해서 IP:Port 로 찾을수도 있고, Service Discovery 도구와 연동하면 dynamic 하게 대상을 찾을 수 있다.
Push Gateway
scrap 대상으로 지정할 수 없는 경우 직접 push 할 수 있는 기능이다. push된 metric은 pushgateway가 보관하고, prometheus는 pushgateway를 scrap 해서 데이터를 가져오는 방식이다. prometheus server 의 동작 방식에는 변화가 없다.
다음의 경우에 pushgateway를 사용한다.
- ad-hoc 하게 잠깐 띄운 서비스인데, prometheus 에 저장하고 싶은 경우.
- service discovery를 하기 힘든 경우
단, push gateway는 기본적으로 메모리에 메트릭을 저장하고 있고, 파일로 저장하더라도 로컬 디스크에만 가능하다.
→ 많은 양의 데이터를 push gateway로 보내면 안되고, 너무 빈번하게 데이터를 보내면 안된다.
pushgateway로의 데이터 전송은 REST API로 호출할 수도 있고, 각 언어의 라이브러리로도 구현이 가능하다.
Alert Manager
Alert 에 대한 정보를 관리한다. Alert 조건이되면 설 널된 채널로 alert 를 보낸다.
시각화
prometheus 데이터 자체로는 데이터에 대한 기준을 확인하기 어렵다. PromQL이 있긴 있지만, 기본적으로 time series 데이터로 시간에 따른 변화를 확인해야 하기 때문이다. 따라서 prometheus metric 을 사용하려면 시각화 도구가 필수적이다. 시각화 도구가 있어야 alert 기준이나 규칙도 파악하기 쉽다.
가장 많이 사용하는 도구로 Grafana가 있다.
Prometheus 의 한계
prometheus 는 기본적으로 Local Storage 에 데이터를 구성하고, 해당 데이터를 색인한다. 그렇다고 클러스터 구성할 수 있는 아키텍처도 아니다.
- 기본적으로 시간이 지나면 휘발되는 TTL 기반의 데이터 이기 때문에 처음부터 대용량을 고려하지 않았다.
따라서 확장성 있는 저장소와 그에 맞는 아키텍처의 적용이 필요하다. 대안이 여럿 있지만, 현재 가장 안정적으로 사용되는 도구는 Thanos 이다.
- Thanos 를 만든 GrafanaLab 에서 cortex도 만들었다. cortex는 아키텍처 복잡도가 높기 때문에 잘 사용되지 않는다.
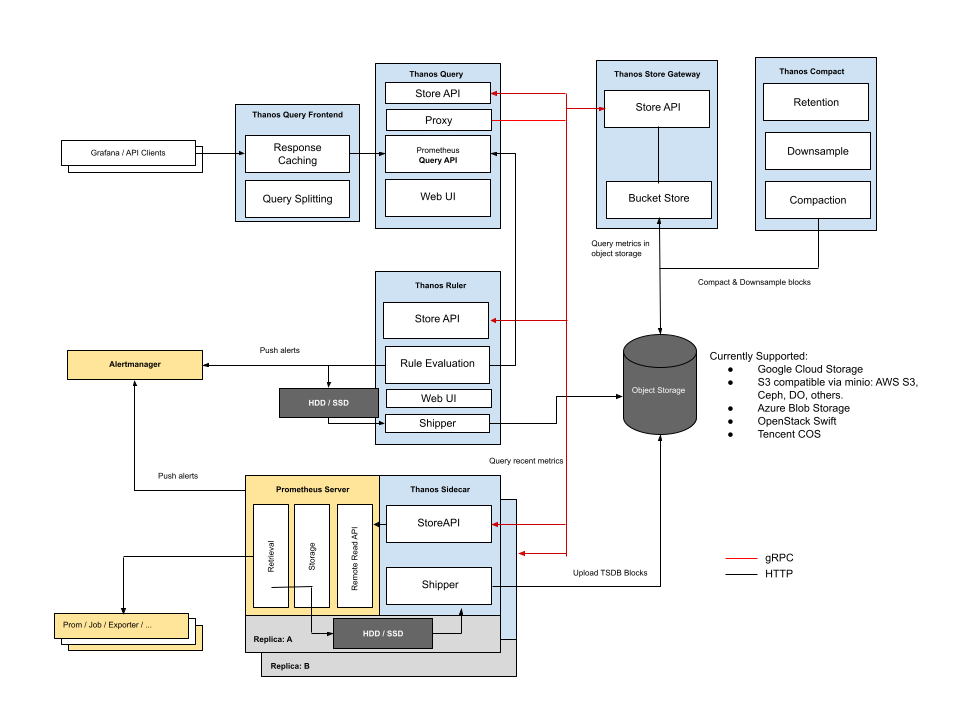
Prometheus - Thanos Architecture
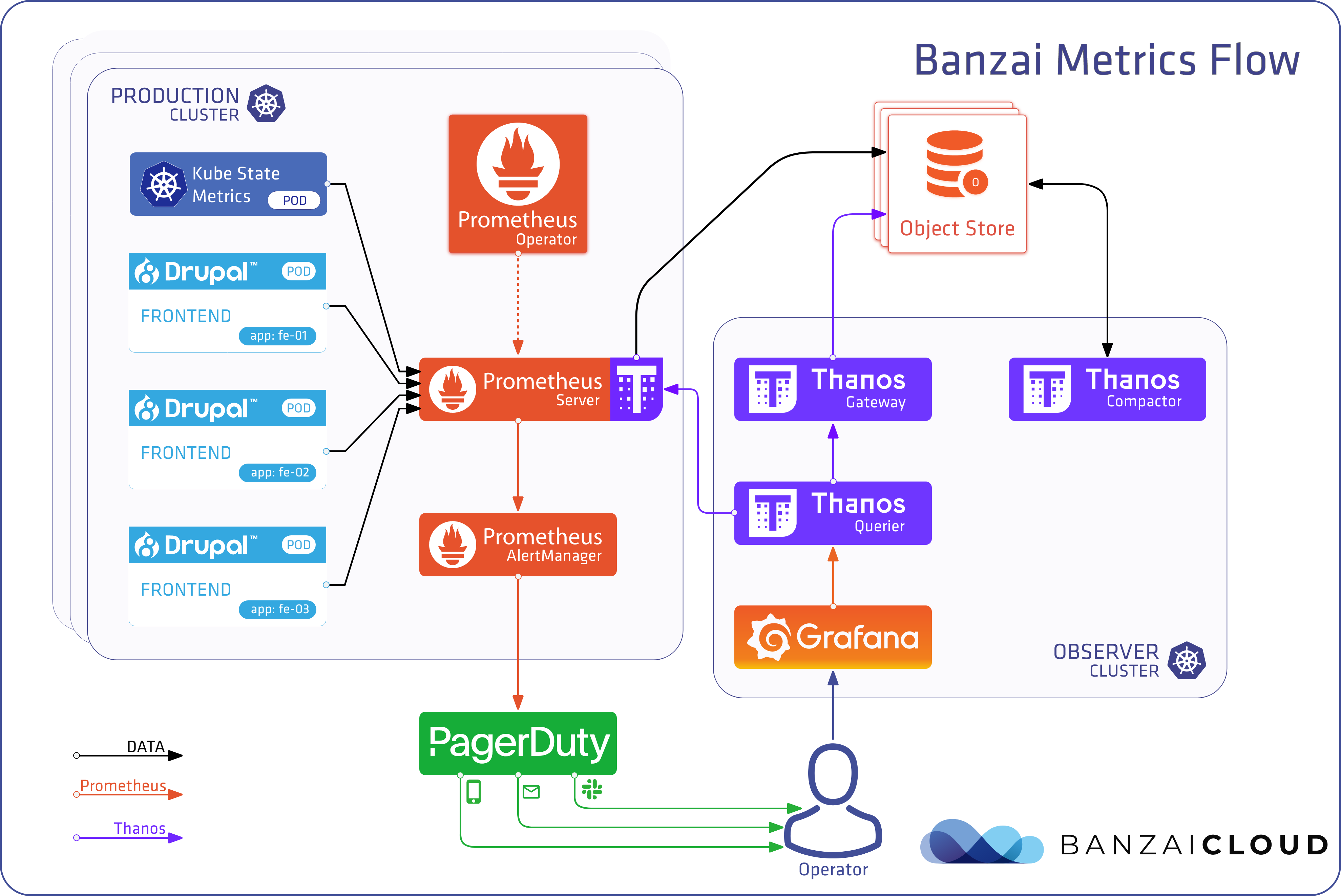
Prometheus server가 데이터를 수집
sidecar로 Thanos를 띄움
Prometheus가 local에 저장하고 싶을 땐 Thanos에게 전달
Thanos가 Object Store(대용량 저장 가능)에 저장
Prometheus는 데이터 수집에만 집중
Thanos 저장과 관리에 집중
- Gateway : Storage 접근
- Compactor : 데이터를 관리
- Querier : 모든 쿼리를 받아줌
Prometheus 가 scrap 한 데이터는 Thanos sidecar 에서 chunk 단위로 object storage 로 보낸다. Thanos 가 설치되면 Grafana 등의 visualizer 는 Thanos query 로 prometheus data, PromQL 을 조회한다. 이때 query 는 Thanos gateway 와 Thanos sidecar 에 조회를해서 long-term 데이터(object storage)와 최신 데이터 모두를 조회할 수 있도록 한다.
아래는 좀더 자세한 아키텍처 구성도이다.