Fluentd 로 로그파일 읽어서 보내기
설정 형식 매뉴얼
요구사항을 정확하게 정의한 다음 어떤 flugin에 어떤 key value로 설정하고 어떤 순서로 입력할지 요구사항을 정확하게 정의한 다음 Fluentd 설정 파일을 짜야한다.
설정 명령
source: 입력 대상 설정 (input)match: 출력 대상 설정 (output)filter로그 파이프라인(변환하거나 판단) 결정systemdirectives set system-wide configurationlabelinternal routing(라벨링)workerdirectives limit to the specific workers (특정한 worker에 대한 리소스 설정)@includedirectives include other files
예)conf.d디렉토리를 include하고,conf.d하위에 여러개의 로그 파이프라인 설정을 파일로 전략이 가능하다.
input 지정하기
위(Log 생성)에서 생성한 log 파일을 input으로 지정한다.
tail plugin을 사용한다. input으로 지정할 수 있는 plugin 매뉴얼 input 데이터를 어떻게 읽을지를 parse 부분에 설정해야한다. parse 매뉴얼
json 버전
<source> : 입력 대상 설정
@type : 어떤 plugin
tag : source와 연결될 다른 설정에서 tag 정보를 보고 연결을 설정
path : tag의 끝이 *일 경우 / type이 tail일 경우 path 에 오는 내가 읽는 파일 이름이 tag의 *자리에 들어감
pos_file 파일을 읽을 때 어떤 파일을 어디까지 읽었는지 position 정보를 가지고 있음
read_from_head : true (계속해서 head부터 읽음 / false 일 경우 tail부터 읽음 = 새로 추가되는 라인만 읽음)
follow_inodes (파일시스템에서 어떤 파일을 가르키는 유니크한 값): true (true로 하면 log rotating을 해도 문제가 생기지 않음)
<parse> : 입력을 읽는 방법 (파싱을 어떻게 할지)
@type json : json parsing (json은 규칙이 동일)
time_key : json object안에 time을 의미하는 key는 datetime이다.
time_type : time key의 value 는 string 이다.
time_format : string의 포멧은 어떻게 되어있는지
<match> : 매치되면 표준 출력(stdout)으로 출력
<source>
@type tail
tag log.json.*
path $LOG_FILE_PATH/json-*.log
pos_file positions-json.pos
read_from_head true
follow_inodes true
<parse>
@type json
time_key datetime
time_type string
time_format %d/%b/%Y:%H:%M:%S %z
</parse>
</source>
<match log.json.**>
@type stdout
</match>fluentd를 실행 {fluent.conf 파일의 위치} -vv (로그를 다 확인)
fluentd -c ./fluent.conf -vv정규표현식 버전
parsing 방법을 정규표현식으로 지정할 수 있다.
plugin 이름 : regexp
<source>
@type tail
tag log.apache.*
path /home/ubuntu/loggen/apache-*.log
pos_file positions-apache.pos
read_from_head true
follow_inodes true
<parse>
@type regexp
expression /^(?<client>\S+) \S+ (?<userid>\S+) \[(?<datetime>[^\]]+)\] "(?<method>[A-Z]+) (?<request>[^ "]+)? (?<protocol>HTTP\/[0-9.]+)" (?<status>[0-9]{3}) (?<size>[0-9]+|-)/
time_key datetime
time_format %d/%b/%Y:%H:%M:%S %z
</parse>
</source>
<match log.apache.**>
@type stdout
</match>주의사항
- match 옆에는 tag의 조건이 와야한다.
파싱을 제대로 못하거나 match할 것이 없으면 다음과 같은 로그가 뜬다. 이 경우 파싱하는 plugin, 규칙(regex), time 관련 필드와 형식 등을 확인해야한다. 이 파싱 규칙 맞추는 부분이 가장 어렵다. 정규표현식을 도와주는 웹
no patterns matched tag ..Output 지정하기
Opensearch 서버로 로그를 보내기 위해 plugin을 설치한다. 참고
fluentd 최상위 폴더에서 실행
sudo fluent-gem install fluent-plugin-opensearch우선 더미 데이터를 opensearch 보내서 <전송 + index 생성>이 성공적으로 되는지 확인한다.
dummy tag의 데이터를 opensearch에다 fluentd-test 라는 index_name으로 보낸다.
<source>
@type dummy
tag dummy
dummy {"hello":"world"}
</source>
<match dummy>
@type opensearch
host $opensearch_server_ip
port 9200
index_name fluentd-test
</match>실행 후 확인
// 실행
fluentd -c ./fluent.conf -vv
// index가 생성되었는지 확인
curl -XGET http://$opensearch_server_ip:9200/_cat/indices?v성공적인 전송을 확인

실제 로그를 보낸다.
- 태그별 인덱스를 다르게 구분했다.
표준 출력 매치태그를 지우고 아래 내용을 입력한다.
<match log.json.**>
@type opensearch
host $opensearch_server_ip
port 9200
index_name json-log
</match>
<match log.apache.**>
@type opensearch
host $opensearch_server_ip
port 9200
index_name apache-log
</match>position 파일을 삭제하고 실행한다.
rm positions-*
fluentd -c ./fluent.conf -vv확인
curl -XGET http://$opensearch_server_ip:9200/_cat/indices?v
Timeformat 으로 index 지정하기
Opensearch의 index lifecycle 을 시간으로 가져가기 때문에, log에 담긴 시간 값에 맞는 index로 전송할 수 있다. 꼭 매뉴얼을 읽고 세팅 할것!
날짜별로 index를 구분
-
logstash_format : logstash 에서 주로 쓰이던 패턴이기 때문에 logstash_format 으로 세팅한다.
-
logstash_prefix : prefix는 logstash임 → 원하는 이름으로 수정
-
include_timestamp : true로 해야 time_key로 지정한 값이 opensearch 안에 timestamp 필드에 기본으로 매핑되서 들어감 (time_key 를 바로 open dashboard의 @timestamp 로 매핑한다)
-
타임키와 포멧 지정 (time_key 의 포맷을 알려줘야 파싱할 수 있다)
<match log.json.**>
@type opensearch
hosts $opensearch_server_ip:9200
logstash_format true
logstash_prefix json-timelog
include_timestamp true
time_key datetime
time_key_format %d/%b/%Y:%H:%M:%S %z
</match>시간별로 index가 생성되었는지 확인한다.
fluentd -c ./fluent.conf -vv
curl -XGET http://$your_opensearch_host:9200/_cat/indices?v성공적으로 생성되었음을 확인

필터링 하기
-
filter로 tag 에 대한 filtering 조건을 걸 수 있다. -
@type grep으로 원하는 조건 걸기. 결과가 true 인 경우만 다음 단계로 넘어간다. 메뉴얼 -
매치 다음에 필터문을 쓰면 앞에 있는 매치에는 필터가 적용되지 않는다.
-
filter 는 순서가 중요하다. match 보다 뒤에오면 해당 match에는 적용되지 않는다.
-
filter 끼리도 선언된 순서대로 적용된다.
특정 로그만 보내기 (@type grep)
HTTP status code 중 200대(성공)가 아닌 로그만 보내는 필터
<filter log.**>
@type grep
<exclude>
# key is status
key status
# except 2** code
pattern /^[2][0-9][0-9]/
</exclude>
</filter>정규표현식으로 같은 필터
regex 는 inverted operation 이 없기 때문에, exclude 로 하면 조건에 반대되는 기능(filterNot)을 할 수 있다.
<filter log.**>
@type grep
<regexp>
key status
pattern /^[1345][01235][0-9]/
</regexp>
</filter>특정 필드만 추가하거나 지우기 (@type record_transformer)
@type record_transformer 로 필드를 추가하거나 삭제할 수 있다. 메뉴얼
<filter log.**>
@type record_transformer
<record>
sent_by fluentd
ftag ${tag}
</record>
remove_keys host
</filter>- <record> 로 원하는 필드를 추가할 수 있다. 이미 예약된 변수를 활용할 수 있다.
- remove_keys 로 필드 이름을 찾아 삭제한다.
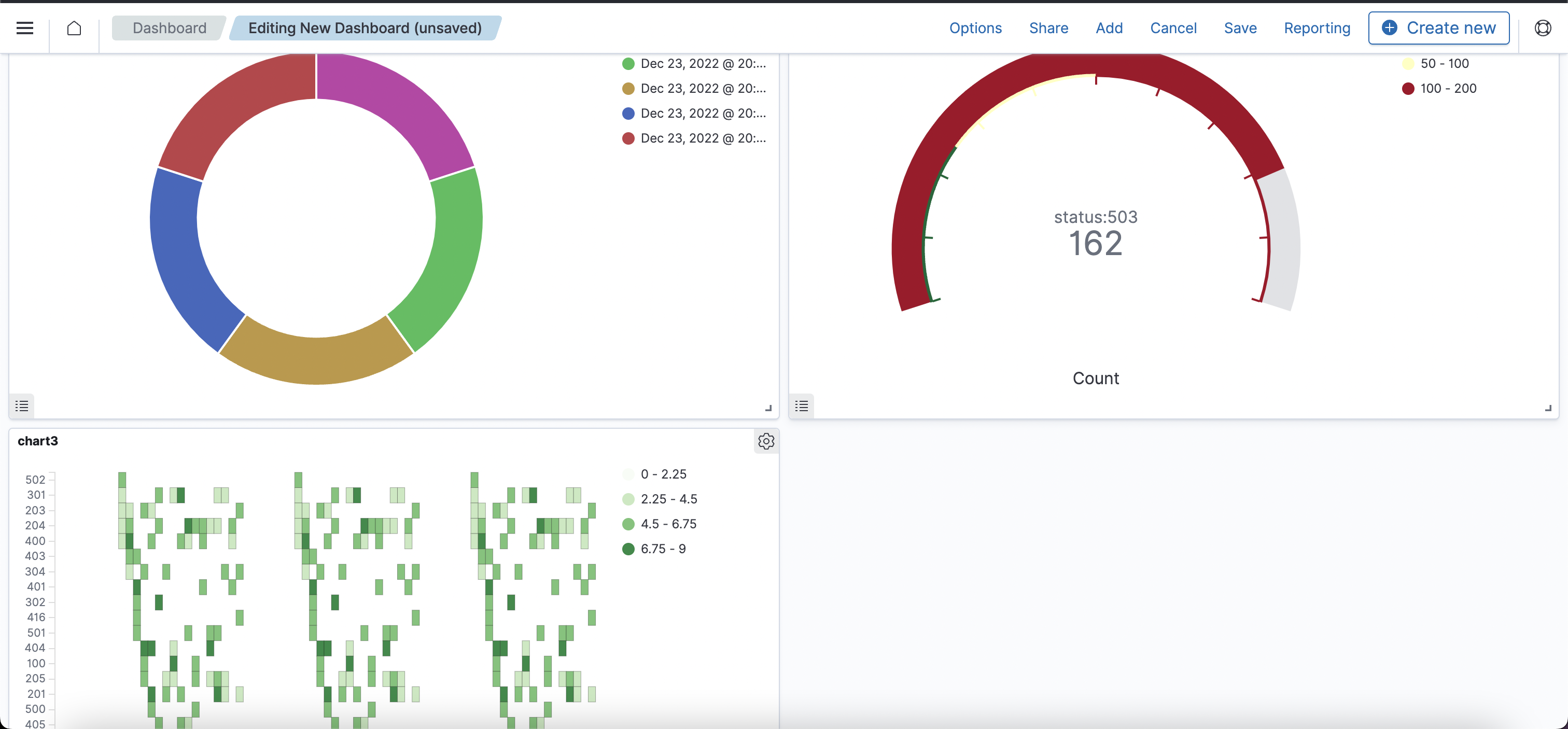
Open Dashboard 에서 시각화 하기
Open Dashboard 에서 인덱스 패턴 생성하기
실행
./bin/opensearch-dashboardsOpenSearch Dashboards 브라우저 → Management → Stack Management → Index Patterns → Create Index pattern
- 여기서 * 로 묶이는 인덱스들은 유사한 schema를 가지는 것이 좋다.
- 필드 이름이 같은데 데이터 형식이 다른 두 개 이상의 document가 있다면, 해당 필드는 conflict 경고가 뜨고, 인덱싱 되지 않는다.
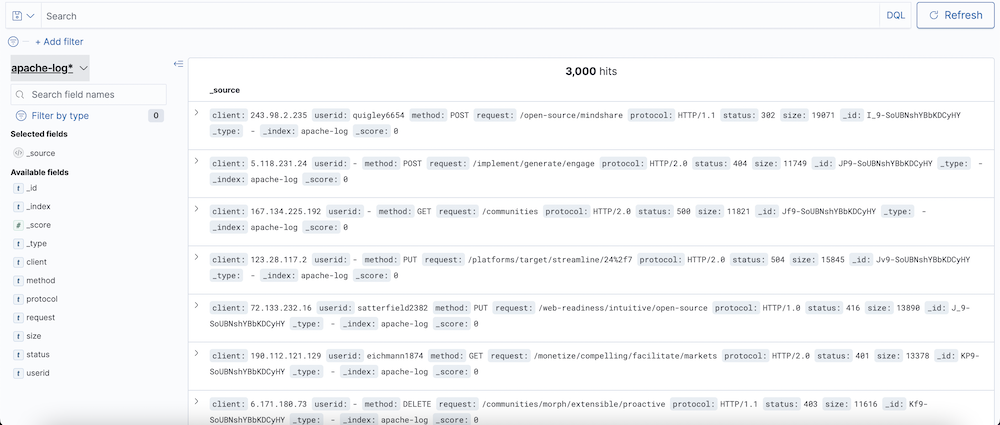
Index pattern 을 추가하고 Discover 메뉴로 가면 다음과 같이 로그를 개별적으로 확인할 수 있다.
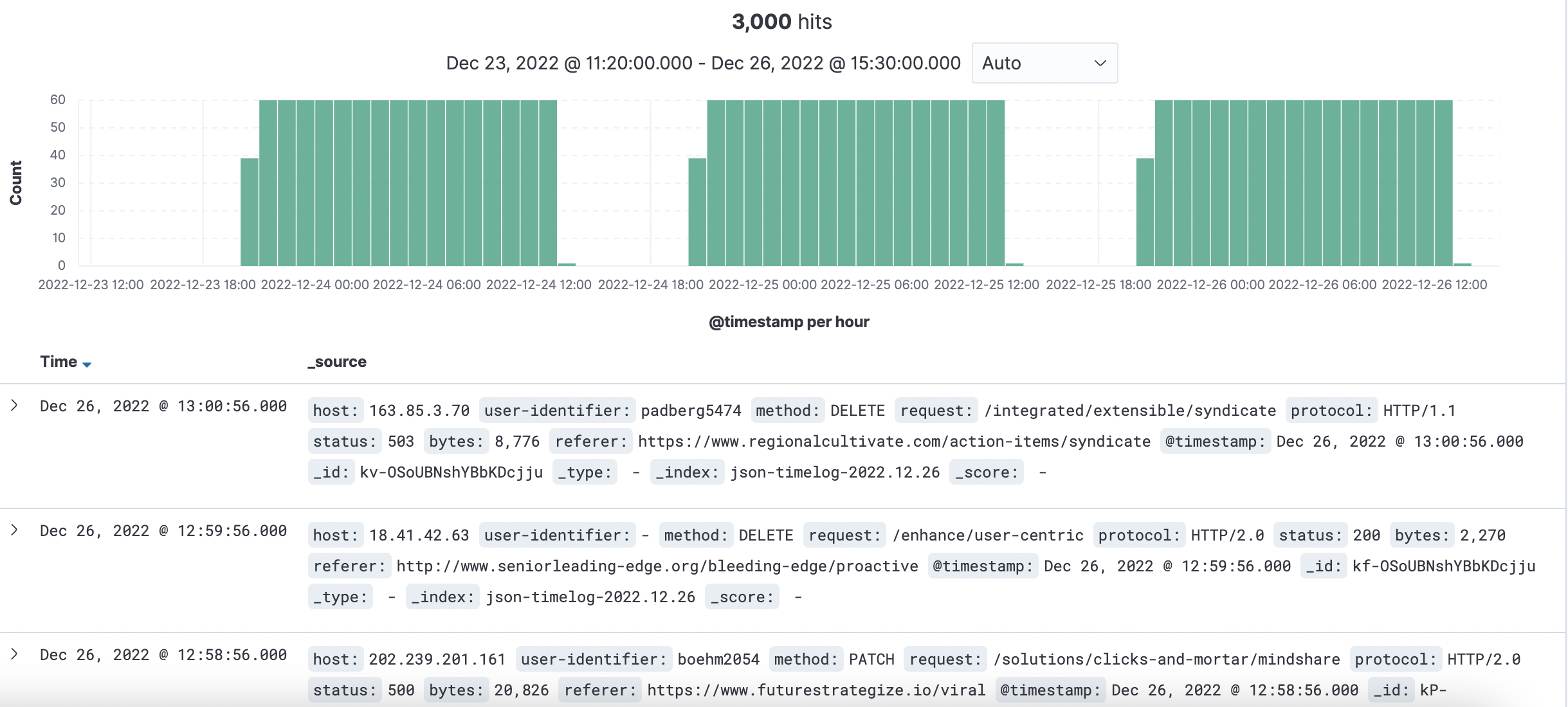
타임스탬프 필드가 있다면 다음과 같이 확인할 수 있다.
원하는 조건 필터링 하기
- 필터링 바에서 + 를 누른 후
- 원하는 필드를 선택
- 조건을 선택
- 조건을 판단할 값 선택
공유 링크 만들기
- 우측 상단에 Share 버튼
- copy
Open Dashboard 에서 다양한 시각화하기
OpenSearch Dashboards 브라우저 → Visualize → Create new visualization
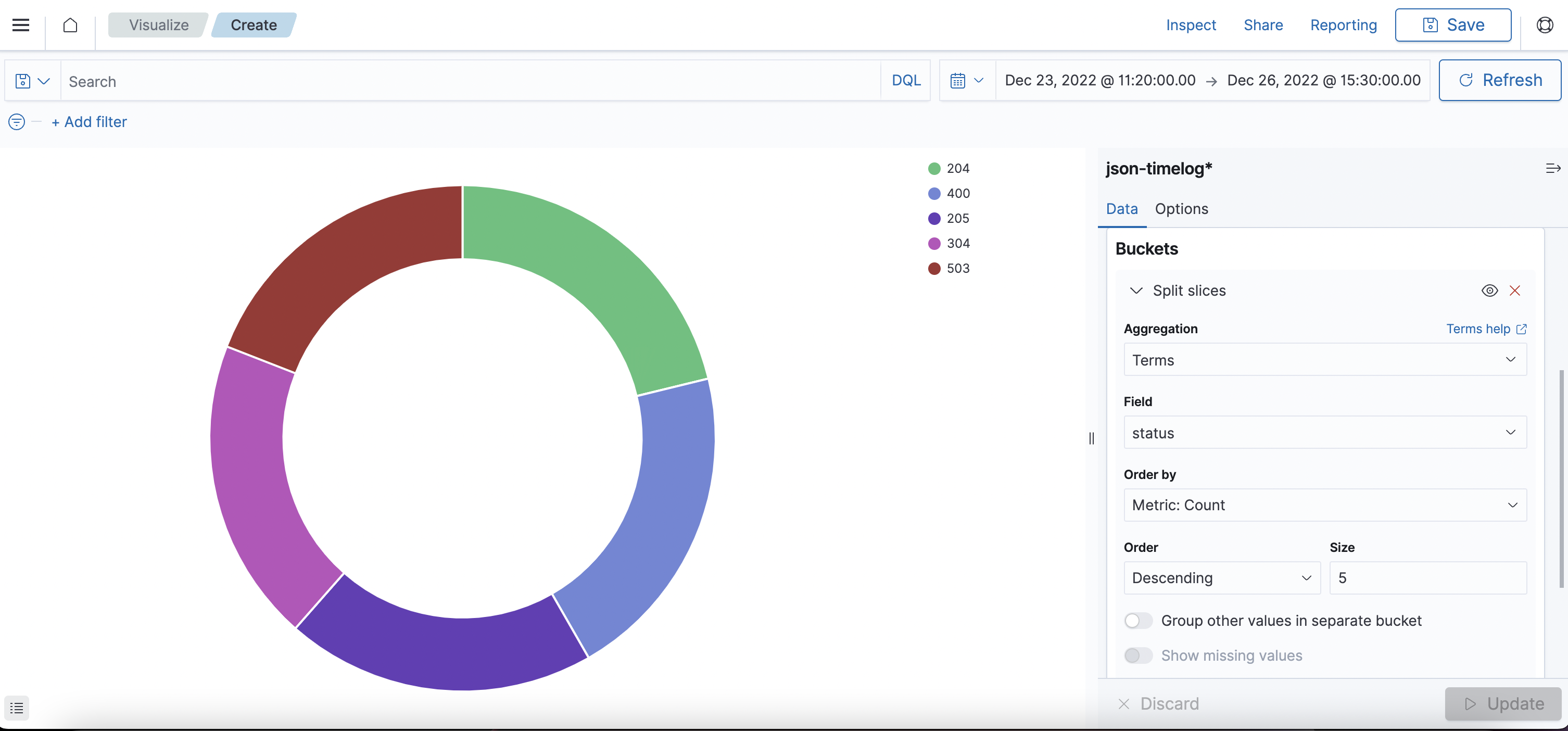
HTTP status를 기준으로 pie 그래프 생성
날짜와 status로 Heatmap 그래프 생성
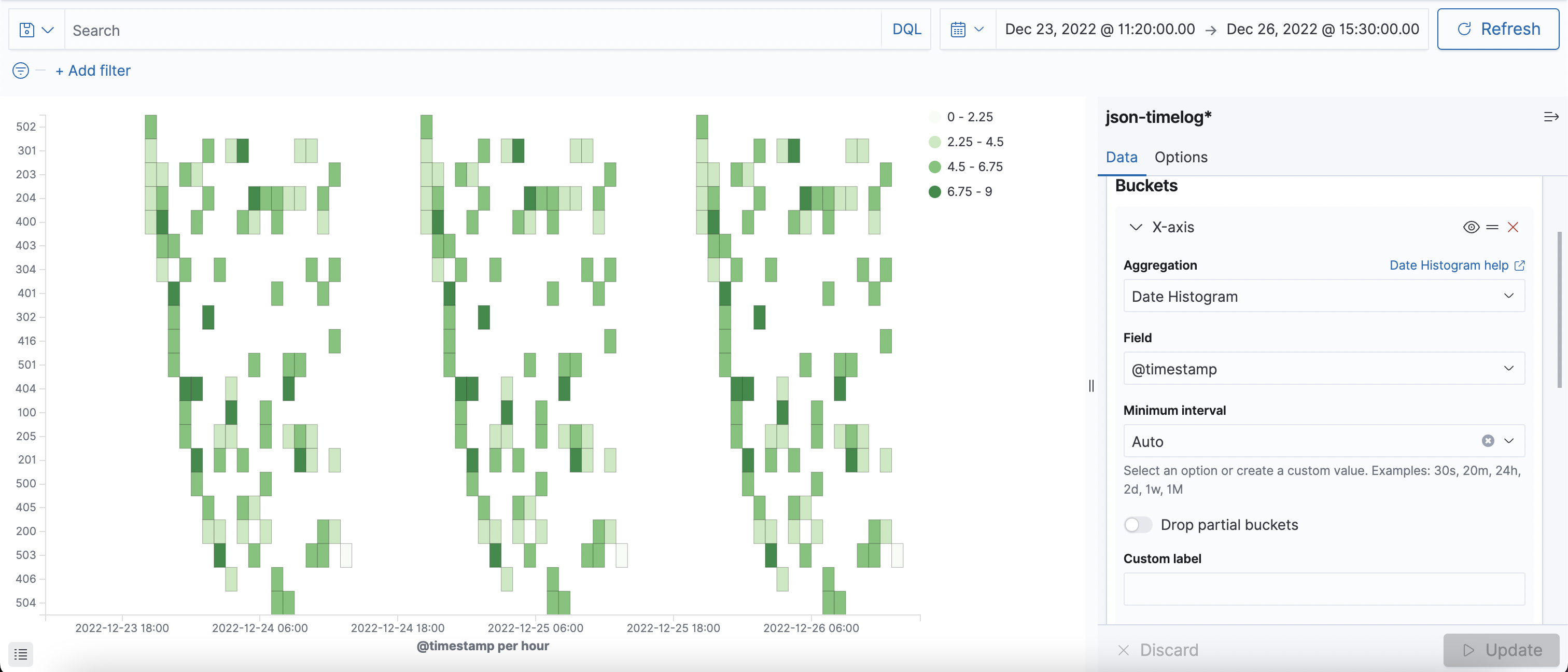
Dashborad 로 한눈에 보기
OpenSearch Dashboards 브라우저 → Dashboards → Create new dashboard