Data
1.데이터 분석 환경 구축의 중요성
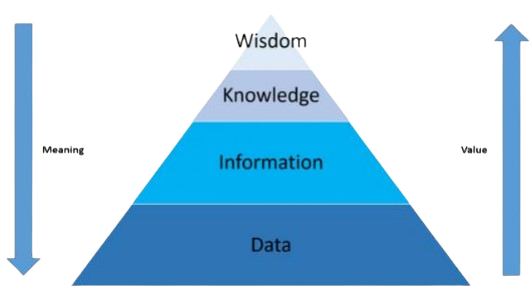
오늘날 데이터는 단순한 숫자와 기호 이상의 가치를 지닙니다. 수집된 데이터는 정리되고 가공되어 정보가 되고, 이를 바탕으로 도출된 통찰은 지식으로 승화됩니다. 이처럼 데이터, 정보, 지식의 계층 구조를 이해하는 것은 효율적인 데이터 분석 환경을 구축하는 첫 걸음입니다.
2.데이터와 변수 분류

데이터 분석의 첫 단계는 데이터와 변수의 특성을 정확히 이해하는 것입니다.데이터는 그 특성에 따라 정형, 반정형, 비정형 등으로 분류되며, 변수는 데이터 안에서 분석하고자 하는 대상이 되는 요소를 의미합니다.이를 체계적으로 분류하면 분석 방향과 전처리, 모델링 전략을
3.인공지능(AI) 모델링을 위한 필수 Python 라이브러리

인공지능 모델링 과정은 데이터 수집부터 전처리, 시각화, 모델 학습 및 평가까지 다양한 단계로 이루어져 있습니다. 이 과정에서 생산성을 높이고 효율적인 분석을 위해 여러 Python 라이브러리를 사용합니다. 여기서는 대표적인 파이썬 라이브러리인 Pandas, OpenC
4.탐색적 데이터 분석 EDA (Exploratory Data Analysis)
EDA(Exploratory Data Analysis, 탐색적 데이터 분석)는 데이터 과학 프로젝트의 필수 단계로, 데이터에 숨겨진 패턴, 관계, 특이점을 발견하는 과정입니다. 이번 글에서는 EDA의 목적과 방법, 주요 분석 기법을 체계적으로 정리하여 안내합니다.EDA
5.데이터 전처리(Data Pre-processing)
데이터 전처리는 데이터 분석과 모델링 과정에서 반드시 거쳐야 하는 단계입니다."좋은 데이터가 좋은 모델을 만든다." 데이터 분석 결과와 모델 성능을 크게 좌우하는 데이터 전처리에 대해 알아봅시다.EDA를 수행하는 이유는 다음과 같습니다.입력 오류 발견: 데이터 입력 시
6.데이터 스케일링(Data Scaling)
데이터 분석과 머신러닝에서 필수적으로 사용되는 데이터 스케일링(Data Scaling)에 대해 심층적으로 살펴보겠습니다. 스케일링이 무엇인지, 왜 중요한지, 그리고 다양한 스케일링 방법을 코드와 함께 상세히 소개합니다.데이터 스케일링(Data Scaling)이란 데이터
7.시계열 데이터 프로젝트 주제 선정 예시
연구 동향 (2018–2025) TCN vs LSTM: 2024년 TCN 모델, 상관계수 0.98·RMSE ≈5 sfu (LSTM 대비 개선) LSTM-WGAN: 2025년 흑점수 예측에 활용, 25주기 피크 정확히 예측 물리모델+통계보정: 2018년 Bhowmi
8.토크나이저(Tokenizer)
분할(Splitting) 텍스트를 모델이 처리할 단위로 나눕니다. 단순 공백 기반, 형태소 기반, 서브워드(subword) 기반 등 방식이 다양함. 정수화(Indexing) 각 토큰을 미리 정의된 어휘(vocabulary)에 매핑해 정수 ID로 변환. 패딩(P
9.시계열 데이터(Time Series Data) 심화 학습
시계열 분석의 이론적 토대를 체계적으로 정리하고, 통계·신호처리·머신러닝 관점에서 주요 알고리즘과 활용 기법을 심화 탐구해 보았다. 특히 비정상성(non-stationarity) 처리, 주파수 영역 분석, 상태 공간 모델(State-Space Model), 그리고 딥러
10.Retrieval-Augmented Generation(RAG)
최근 “LLM과 RAG 기술 활용편” 해커톤에 참여하며, 대형 언어 모델(LLM)의 한계와 이를 극복하기 위한 Retrieval-Augmented Generation(RAG)의 개념을 깊이 탐구했습니다. 본 TIL에서는 RAG의 이론적 원리, 구성 요소, 구현 파이프라