이미지 출처 : https://www.sharetechnote.com/html/NN/NN_HowToLearn.html
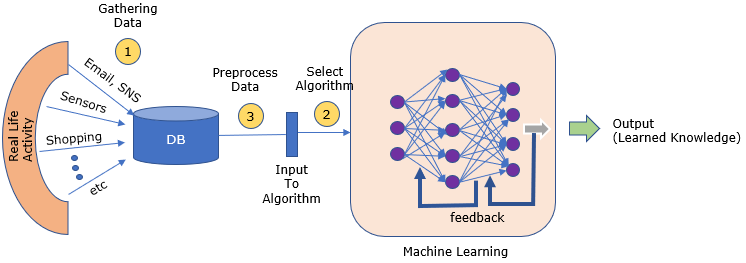
데이터 전처리는 데이터 분석과 모델링 과정에서 반드시 거쳐야 하는 단계입니다.
"좋은 데이터가 좋은 모델을 만든다." 데이터 분석 결과와 모델 성능을 크게 좌우하는 데이터 전처리에 대해 알아봅시다.
🚩 1. EDA의 목적
EDA를 수행하는 이유는 다음과 같습니다.
입력 오류 발견: 데이터 입력 시 실수로 발생한 문제를 확인합니다.
가정 검증: 데이터에 대한 가정이 타당한지 검증합니다.
모델 선정: 데이터 유형에 가장 적합한 모델을 미리 선정합니다.
설명 변수 간 관계 파악: 독립 변수들 사이의 관계를 탐색합니다.
독립변수와 종속변수 관계 탐색: 변수들 간의 상관관계와 영향력을 분석합니다.
📌 2. EDA의 주요 단계
EDA는 다음과 같은 과정을 포함합니다.
기본 통계 분석: 데이터 크기, 타입, 결측값, 평균, 표준편차 등 분석
데이터 시각화: 히스토그램, 박스플롯, 산점도 등을 통해 패턴 파악
이상치 탐지: 박스플롯, IQR, Z-score 등을 활용해 이상치 발견
변수 간 관계 분석: 상관관계 분석으로 변수 간의 상호 관계를 확인
결측값 처리: 평균, 중앙값, 최빈값 등으로 결측치를 처리
데이터 변환: 정규화, 로그 변환, 범주형 변수 인코딩을 통해 데이터를 모델링에 적합하게 변형
🧮 3. 기본 통계 개념
EDA에서 자주 사용되는 통계 개념들을 정리해 보면 다음과 같습니다.
평균(Mean): 데이터 값을 모두 더한 후 데이터 개수로 나눈 값입니다.
표준편차(Standard Deviation): 데이터가 평균을 중심으로 얼마나 퍼져 있는지 나타내는 지표입니다.
Z-score: 데이터 값이 평균에서 얼마나 떨어져 있는지를 표준편차 단위로 나타낸 값입니다.
정규분포(Normal Distribution): 데이터가 평균을 중심으로 대칭적으로 분포하는 모양입니다.
중심극한정리(Central Limit Theorem, CLT): 충분히 큰 표본 크기에서 표본 평균의 분포는 정규 분포를 따른다는 정리입니다.
📈 4. 단변량(Univariate) 분석
단변량 분석은 하나의 변수만을 다루는 분석입니다. 변수 유형에 따라 다음과 같이 나뉩니다.
범주형 변수 분석
그래픽 방법: 막대 그래프 등으로 각 범주의 빈도를 시각화
비그래픽 방법: 각 범주의 빈도, 비율을 수치적으로 표현
수치형 변수 분석
그래픽 방법: 히스토그램, 박스플롯, Q-Q 플롯으로 데이터의 분포 시각화
비그래픽 방법: 평균, 중앙값, 최빈값, 분산, 표준편차 등으로 수치적 분석
📉 5. 다변량(Multivariate) 분석
다변량 분석은 둘 이상의 변수를 동시에 분석합니다.
비그래픽 방법: 교차표, 상관관계 분석 등으로 변수 간의 수치적 관계 파악
그래픽 방법: 페어 플롯(pairplot), 평행 좌표 플롯(parallel plot) 등으로 시각적 관계 분석
🎯 6. 특성 선택(Feature Selection)과 특성 추출(Feature Extraction)
모델링 과정에서 특성(변수)의 선택과 추출은 성능에 큰 영향을 줍니다.
✅ 특성 선택 (Feature Selection)
기존의 변수 중 모델 성능에 가장 영향을 많이 주는 특성을 선택하여 차원 축소를 수행합니다.
방법론:
전진 선택법(Forward Selection)
후진 제거법(Backward Elimination)
정보 이득(Information Gain), 카이제곱 검정(Chi-square), 상관 계수(Correlation Coefficient), 분산 임계값(Variance Threshold) 등
✅ 특성 추출 (Feature Extraction)
원본 데이터의 변수를 조합하여 새로운 특성을 만듭니다.
대표적인 기법:
PCA(주성분 분석): 데이터 분산을 최대한 보존하며 차원을 축소
LDA(선형 판별 분석): 클래스 간 분리를 최대화하여 차원 축소
⚙️ 7. 주요 분석 기법 실습 예제
[중심 극한 정리 예제 코드]
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
np.random.seed(42)
population = np.random.exponential(scale=2, size=10000)
sample_sizes = [5, 10, 30, 50, 100]
plt.figure(figsize=(12, 8))
for i, n in enumerate(sample_sizes, 1):
sample_means = [np.mean(np.random.choice(population, size=n)) for _ in range(1000)]
plt.subplot(2, 3, i)
sns.histplot(sample_means, bins=30, kde=True, color='blue')
plt.axvline(x=np.mean(population), color='red', linestyle='dashed')
plt.title(f"Sample size = {n}")
plt.tight_layout()
plt.show()🛠️ 8. EDA 추천 실습 과제
실습 파일을 통해 다양한 데이터를 직접 분석하면서 실력을 키워 보세요.
타이타닉 데이터 생존율 분석
PCA를 활용한 특성 추출
정보이득을 통한 특성 선택
📝 결론
EDA는 데이터 분석에서 가장 기초적이면서도 필수적인 과정입니다. 데이터를 탐색하고, 이상치를 찾으며, 중요한 특성을 식별하는 능력은 모델링의 성공을 좌우합니다. 이 글을 참고하여 EDA를 효과적으로 활용해 보시기 바랍니다.
