
chapter 4의 핵심개념
cahpter 4에서는 데이터베이스 모델링에 대한 개념을 파악하고 간단히 모델링 절차를 실습한다.
- 프로젝트 진행 단계는 폭포수 모델이 대표적으로 계획/분석/설계/구현/테스트/유지보수 등의 단계를 거친다.
- 데이터베이스 모델링이란 현 세계에서 사용되는 작업이나 사물을 DBMS의 데이터베이스 개체로 옮기기 위한 과정을 말한다.
- Workbench에는 자체적으로 데이터 모델링 툴을 제공한다.
chapter 4의 학습 흐름
- 프로젝트 진행 단계와 폭포수 모델 개념 파악
- 데이터베이스 모델링 실습
- Workbench의 모델링 툴 실습
프로젝트의 진행 단계
프로젝트란 '현실세계의 업무를 컴퓨터 시스템으로 옮겨놓는 련련의 과정'이라고 할 수 있다.
초창기의 컴퓨터 프로그램은 몇몇 뛰어난 프로그래머에 의해서 작성되었다. 초기에는 이렇게 혼자서 프로그램을 작성해야 하는 규모가 커지고, 예전과 달리 사용자들의 요구사항이 더욱 복잡해지면서 문제가 발생되기 시작했다.
그런데도 소프트웨어 분야에서는 아직도 큰 규모의 프로그램 작업을 수행 시에도 옛날과 같이 계속 몇몇 우수한 프로그래머에게 의존하는 형태를 취해 왔다. 그 결과 프로젝트가 참담한 실패로 이어지는 경우가 너무 많이 발생되었고, 제작 기간의 지연 등 많은 문제에 노출이 되었다.
결론적으로 이러한 문제점을 해결하기 위해서 '소프트웨어 개발 방법론'이 나타났다.
소프트웨어 공학에서 제시하는 소프트웨어 개발 모델은 많지만, 가장 오래되고 전통적으로 사용되는 것은 폭포수 모델(Waterfall Model)이다.
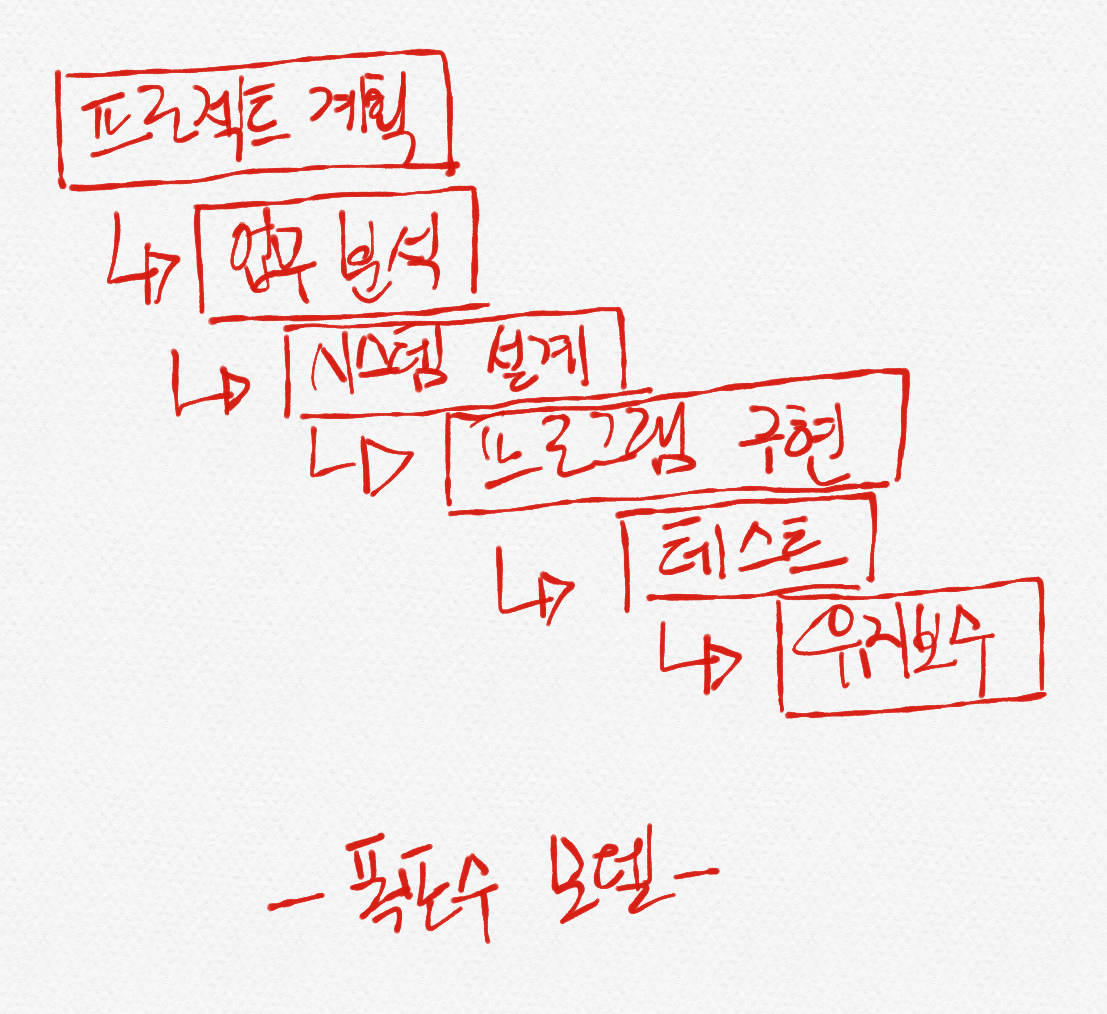
말 그대로 폭포가 떨어지듯이 각 단계가 끝나면 다음 단계로 진행한다. 이 폭포수 모델의 장점은 각 단계가 명확히 구분되어서 프로젝트의 진행 단계가 명확해지는 장점이 있으나 당연히 단점도 존재한다. 이 모델의 가장 큰 단점은 폭포에서 내려가기는 쉬워도 다시 거슬러 올라가기는 어려운 것과 마찬가지로 문제점이 발생될 경우에는 다시 앞 단계로 거슬러 올라가기가 어렵다는 점이다.
데이터베이스 모델링
데이터베이스 모델링 개념
데이터베이스 모델링이란 현 세계에서 사용되는 작업이나 사물들을 DBMS의 데이터베이스 개체로 옮기기 위한 과정이라고 말할 수 있다.
데이터베이스 모델링 실습
데이터베이스 모델링은 크게 3단계를 거쳐서 완성시키는 것이 보편적이다.
개념적 모델링, 논리적 모델링, 물리적 모델링으로 나눌 수 있다.
개념적 모델링은 주로 업무 분석 단계에 포함되며 논리적 모델링은 업무 분석의 후반부와 시스템 설계의 전반부에 걸쳐서 진행된다. 그리고 물리적 모델링은 시스템 설계의 후반부에 주로 진행된다. (이 분류가 절대적인 것은 아니다.)
우리는 지금 새로운 쇼핑몰을 오픈했다고 가정하자. 지금부터 우리 매장을 찾는 고객의 명단을 기록하고 또 물건을 구매할 때 구매한 내역도 기록하겠다. 이러한 업무로 데이터베이스 모델링을 해보자.
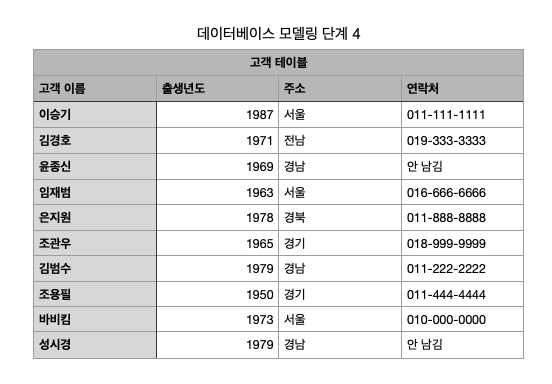
step 1:고객이 방문한 내역은 다음과 같이 기록될 것이다. 이 기록이 메모장 또는 엑셀이 기록되어 있다고 가정하자.
당연히 고객은 여러 번 방문할 수도 있고, 방문해서 아무것도 사지 않고 갈 수도 있다.
step 2: 기록된 내용에서 물건을 구매한 적이 없는 고객을 위쪽으로 다시 정렬해 보자.
전체 테이블이 L자 모양의 테이블이 되었다. 이러한 것을L자형 테이블이라는 용어를 쓴다. L자형 테이블의 문제는 공간이 낭비된다는 것이다.
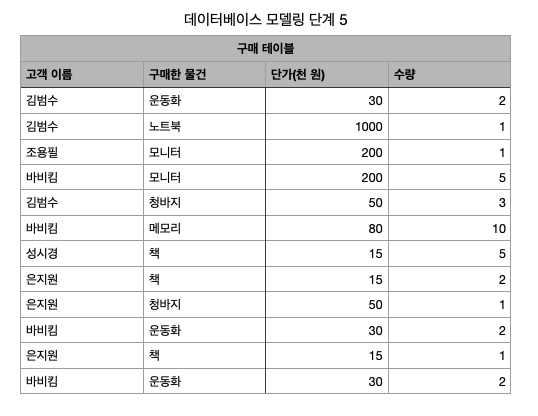
step 3: L자형 테이블을 빈칸이 있는 곳과 없는 곳으로 분리해 보자.
이제는 빈 부분이 없어졌다. 즉, 공간을 절약할 수가 있다. 그런데 고려해야 할 사항이 두 가지가 생겼다. 우선 고객 테이블에서 똑같은 정보가 중복된다는 것이다.
step 3-1: 고객 테이블의 중복을 없앤다.
step 3-2: 이번에는 구매 테이블만 보니 누가 구매한 것인지를 알 수 없다. 그래서 구매 테이블의 앞에 회원을 구분할 수 있는 회원의 기본 키로 설정된 이름을 넣어주자.
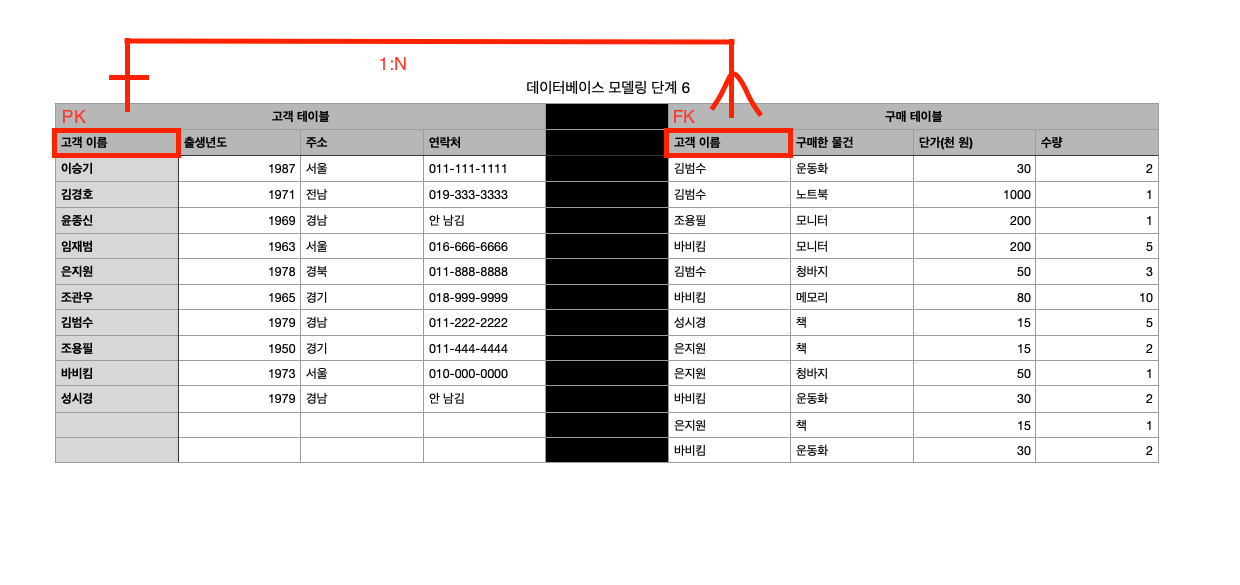
step 4: 테이블의 구분이 잘 되었다. 그런데, 고객 테이블과 구매 테이블은 밀접한 관련이 있는 테이블이다. 즉, 구매 테이블만으로는 고객에게 배송할 수가 없다. 고객의 주소와 연락처는 고객 테이블에 존재하기 때문이다. 그래서 이 두 테이블의 업무적인 연관성을 맺어줘야 한다. 이를 '관계(Relation)'라고 부른다. 여기서 두 테이블 중에서 부모 테이블과 자식 테이블을 결정해 보도록 하자. 부모와 자식을 구분하는 방법 중에서 주(Master)가 되는 쪽은 부모로, 상세(Detail)가 되는 쪽을 자식으로 설정할 수 있다.
step 4-1: 부모 테이블인 고객 테이블과 자식 테이블인 구매 테이블의 관계를 맺어주는 역할은 기본 키와 외래 키를 설정함으로써 이뤄진다.
step 4-2: 이렇게 관계가 맺어진 후에는, 제약 조건이라는 관계가 자동으로 설정된다. 예로 '존밴이'라는 사람이 모니터를 1개 구매하려고 한다고 생각해 보자. 그러면 구매 테이블에는 '존밴이/모니터/200/1'이라는 행이 하나 추가되어야 한다. 그런데, 구매 테이블의 FK로 설정된 '존밴이'가 고객 테이블에 존재하지 않는다. 그러므로 이 행은 PK, FK 제약조건을 위배하므로 추가될 수가 없다. (이를 참조 무결성으로도 부른다.) 그러므로 '존밴이'가 물건을 구매하기 위해서는 먼저 부모 테이블인 고객 테이블에 '존밴이'의 정보를 입력해야 한다. 또한, 부모 테이블(고객 테이블)의 '김범수'가 회원탈퇴를 한다고 가정해 보자. 이는 '김범수' 행을 삭제하는 것이다. 그런데, 김범수는 자식 테이블(구매 테이블)에 구매한 기록이 있기 때문에 삭제되지 않는다. 부모 테이블의 데이터를 삭제하기 위해서는 먼저 자식 테이블에 연관된 데이터를 삭제해야만 삭제가 가능하다.
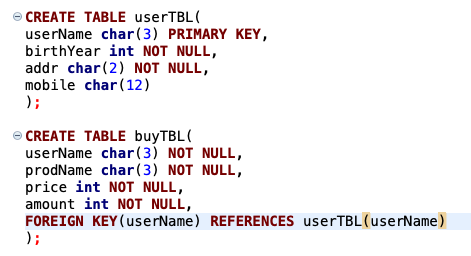
step 5: 이제는 완성된 고객 테이블과 구매 테이블의 테이블 구조를 정의하자. 즉, 열 이름, 데이터 형식, Null 여부 등을 결정하는 과정이다.
자체평가 - 학습 흐름을 잘 이해하고 있는가?
프로젝트 진행 단계와 폭포수 모델 개념 파악
데이터베이스 모델링 실습
Workbench의 모델링 툴 실습
