
chapter 7의 핵심 개념
SQL문의 데이터 형식 및 변수, 대용량 데이터의 저장, MySQL 프로그래밍
- MySQL은 숫자, 문자, 날짜 등의 다양한 데이터 형식을 지원한다.
- 대용량 데이터의 저장과 추출을 위해서는 LONGTEXT, LONGBLOB 데이터 형식을 사용한다.
- MySQL도 변수를 사용할 수 있는데, 앞에 @를 붙여서 사용해야 한다.
- MySQL은 제어 흐름 함수, 문자열 함수, 수학 함수, 날짜/시간 함수, 전체 텍스트 검색 함수, 형 변환 함수 등 다양한 내장 함수를 제공한다.
- LONGTEXT, LONGBLOB 형식은 대용량 텍스트 및 바이너리 파일을 저장할 수 있다.
- MySQL은 데이터 교환을 위한 JSON 데이터 형식을 지원한다.
- 두 개 이상의 테이블을 묶는 조인은 내부 조인, 외부 조인 등이 있다.
- MySQL은 일반 프로그래밍 언어와 비슷한 프로그래밍 문법을 지원한다.
chapter 7의 학습 흐름
- MySQL 데이터 형식
- 변수의 할용
- MySQL 내장 함수
- 테이블 조인
- SQL 프로그래밍
MySQL의 데이터 형식
Data Type은 데이터 형식, 데이터형, 자료형, 데이터 타입 등 다양하게 불릴 수 있다. SELECT문을 더 잘 활용하고 테이블을 효율적으로 생성하기 위해서는 데이터 형식에 대한 이해가 반드시 필요하다.
MySQL에서 지원하는 데이터 형식의 종류
DBMS 회사 별 SQL
한국인에게는 한국어로, 중국인에게는 중국어로 얘기해야 서로 의사소통이 되듯이, DBMS에게는 SQL문으로 질문하고 명령을 지시해야만 DBMS가 알아듣고, 작업을 수행한 후 그 결과 값을 우리에게 준다. 그런데, 우리가 학습하는 MySQL 외에도 많은 DBMS가 있기 때문에 모든 DBMS에서 통용되는 공통의 SQL 표준이 필요하다. 이를 위해 NCITS(INCITS)(국제 표준화 위원회)에서는 ANSI/ISO SQL이라는 명칭의 SQL의 표준을 관리하고 있으며, 이 중에서도 1992년에 제정된 ANSI-92 SQL과 1999년에 제정된 ANSI-99 SQL이라는 명칭의 표준이 대부분의 DBMS 회사에서 적용하는 기준이 되고 있다. 그러나, ANSI-92/99 SQL이 모든 DBMS 제품의 특성을 반영할 수가 없기 때문에, 각 회사들은 ANSI-92/99 SQL의 표준을 준수하면서도 자신들의 제품의 특성을 반영하는 SQL에 별도의 이름을 붙였다. 일례로, MySQL에서는 그냥 SQL이라고 명명한 SQL 문을, Oracle에서는 PL/SQL 이라는 이름의 SQL 문을, SQL Server는 Transact SQL(SQL)이라는 이름의 SQL 문을 사용한다.
숫자 데이터 형식
숫자형 데이터 형식은 정수, 실수 등의 숫자를 표현한다.
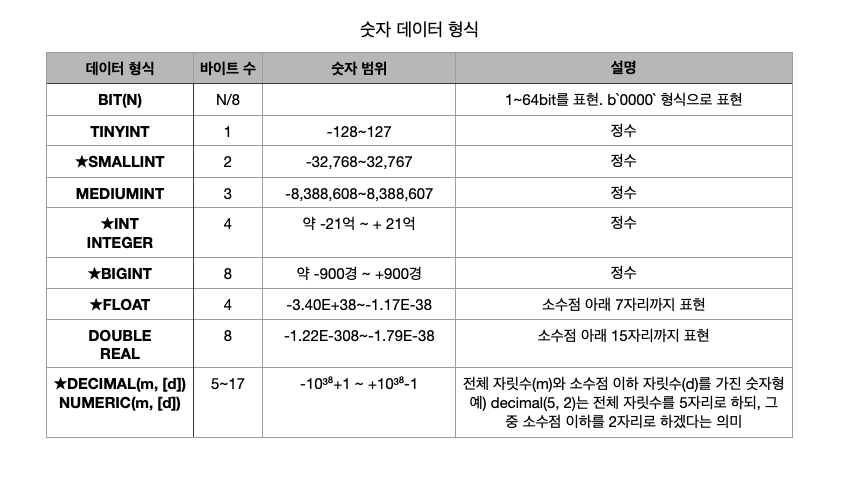
DECIMAL 데이터 형식은 정확한 수치를 저장하게 되고 FLOAT, DOUBLE은 근사치의 숫자를 저장한다. 대신 FLOAT, DOUBLE은 상당히 큰 숫자를 저장할 수 있다는 장점이 있다.
그러므로 소수점이 들어간 실수를 저장하려면 되도록 DECIMAL을 사용하는 것이 바람직하다. 예로 -999999.99부터 +999999.99까지의 숫자를 저장할 경우에는 DECIMAL (9,2)로 설정한다.
또 MySQL은 부호 없는 정수를 지원하는데 부호 없는 정수로 지정하면 TYNYINT는 0~255, SMALLINT는 0~65535, MIDIUMINT는 0~16777215, INT는 0~약 42억, BIGINT는 0~약1800경으로 표현할 수 있다. 부호 없는 정수를 지정할 때는 UNSIGNED 예약어를 뒤에 붙여준다.
FLOAT, DOUBLE, DECIMAL도 UNSIGNED 예약어를 사용할 수 있지만 자주 사용되지는 않는다.
기억해!!
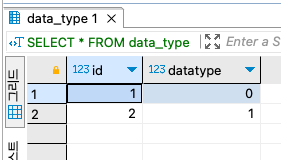
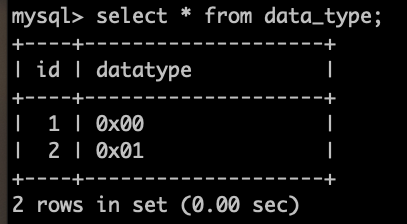
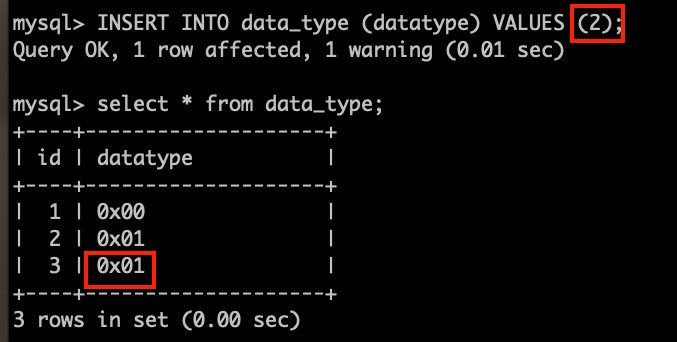
데이터 타입이 bit(1)이다. 그러므로 1비트가 표현할 수 있는 0,1만 INSERT가 가능하다.
그러나 터미널에서 2를 INSERT하면 묵시적으로 변환을 해서 설정한 비트의 최대값인 1을 넣게 된다.
DBeaver는 이런 상황을 오류로 잡아주지만, 터미널은 오류로 잡지 않는다.
이런 상황은 위험할 수 있으니 앞으로는 주의해서 사용해야겠다.



문자 데이터 형식
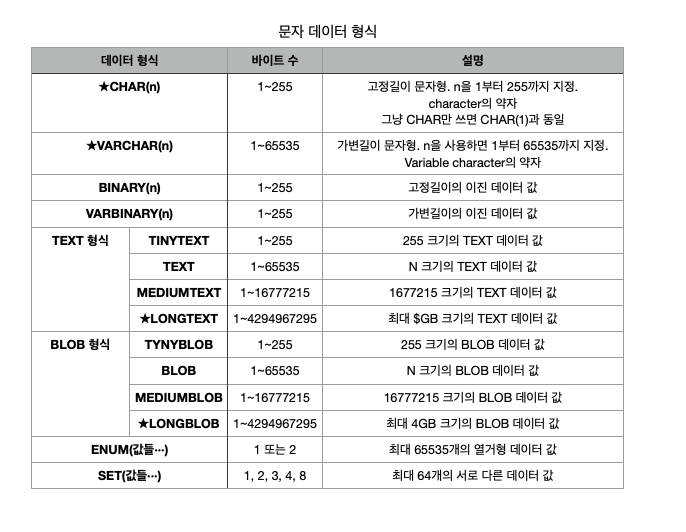
CHAR 형식은 고정길이 문자형으로 자릿수가 고정되어 있다. 예를 들어, CHAR(100)에 'ABC' 3글자만 저장해도 100자리를 모두 확보한 후에 앞에 3자리를 사용하고 뒤의 97자리는 낭비하게 되는 결과가 나온다. VARCHAR 형식은 가변길이 문자형으로 VARCHAR (100)에 'ABC' 3글자를 저장할 경우에 3자리만 사용하게 된다. 그래서 공간을 효율적으로 운영할 수 있다. 하지만, CHAR 형식으로 설정하는 것이 INSERT/UPDATE 시에 일반적으로 더 좋은 성능을 발휘한다.
CHAR, VARCHAR의 내부 크기
MySQL은 기본적으로 CHAR, VARCHAR는 모두 UTF-8 형태를 지니므로, 입력한 글자가 영문, 한글 등에 따라서 내부적으로 크기가 달라진다. 하지만 사용자 입장에서는 CHAR(100)은 영문, 한글 구분 없이 100 글자를 입력하는 것으로 알고 있으면 되며, 내부적인 할당 크기는 신경 쓸 필요가 없다.참고로 MySQL의 기본 문자 세트(Default Character Set)는 my.ini 또는 my.cnf 파일에 다음과 같이 기본적으로 설정되어 있다.
# 클라이언트 문자 세트 [mysql] default-character-set=utf8 # 서버 문자 세트 [mysqld] character-set-server=utf8
BINARY와 VARBINARY는 바이트 단위의 이진 데이터 값을 저장하는 데 사용된다. TEXT형식은 대용량의 글자를 저장하기 위한 형식으로 필요한 크기에 따라서 TINYTEXT, TEXT, MEDIUMTEXT, LONGTEXT 등의 형식을 사용할 수 있다. BLOB(Binary Large Object)은 사진 파일, 동영상 파일, 문서 파일 등의 대용량의 이진 데이터를 저장하는 데 사용될 수 있다. BLOB도 필요한 크기에 따라서 TINYBLOB, BLOB, MEDIUMBLOB, LONGBLOB 등의 형식을 사용할 수 있다.
ENUM은 열거형 데이터를 사용할 때 사용될 수 있는데 예로 요일(월, 화, 수, 목, 금, 토, 일)을 ENUM 형식으로 설정할 수 있다. SET은 최대 64개를 준비한 후에 입력은 그 중에서 2개씩 세트로 데이터를 저장시키는 방식을 사용한다.
날짜와 시간 데이터 형식
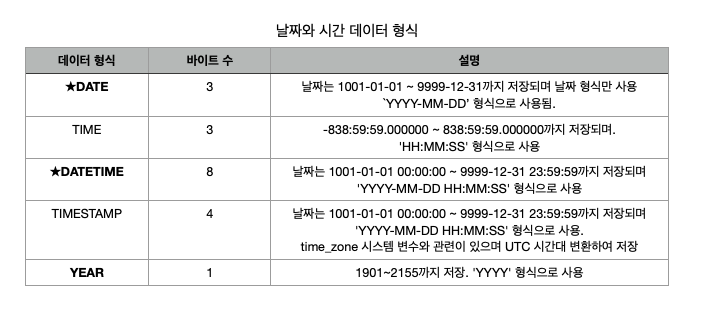
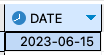
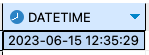
날짜와 시간형 데이터에 대해서는 간단한 예를 통해서 그 차이를 확인하자.


기타 데이터 형식

LONGTEXT, LONGBLOB
MySQL은 LOB(Large Object: 대량의 데이터)을 저장하기 위해서 LONGTEXT, LONGBLOB 데이터 형식을 지원한다. 지원되는 데이터 크기는 약 4GB 크기의 파일을 하나의 데이터로 저장할 수 있다. 예로 장편소설과 같은 큰 텍스트 파일이라면, 그 내용을 전부 LONGTEXT 형식으로 지정된 하나의 컬럼에 넣을 수 있고, 동영상 파일과 같은 큰 바이너리 파일이라면 그 내용을 전부 LONGBLOB 형식으로 지정된 하나의 컬럼에 넣을 수 있다.
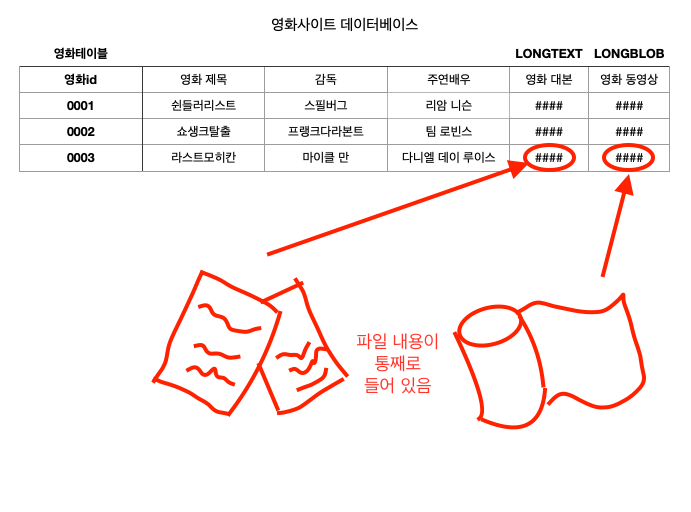
위의 예를 보면 영화 대본 열에는 영화 대본 전체가 들어가고, 영화 동영상 열에는 실제 영화 파일 전체가 들어갈 수 있다. 실무에서는 이러한 방식도 종종 사용되니 잘 기억해 놓으면 도움이 된다.
변수의 사용
SQL도 다른 일반적인 프로그래밍 언어처럼 변수(Variable)를 선언하고 사용할 수 있다. 변수의 선언과 값의 대입은 다음의 형식을 따른다.
SET @변수이름 = 변수의 값; -- 변수의 선언 및 값 대입
SELECT @변수이름 ; -- 변수의 값 출력스토어드 프로시저나 함수 안에서의 변수를 사용하는 방법은 DECLARE문으로 선언한 후에 사용할 수 있다. 또한, 스토어드 프로시저나 함수 안에서는 @변수명 형식이 아닌 그냥 변수명만 사용한다. 구분하자면 @변수명은 '전역 변수'처럼 사용하고, DECLARE 변수명은 스토어드 프로시저나 함수 안에서 '지역 변수'처럼 사용된다.
간단히 변수의 사용을 실습하자.
step 1: 변수를 몇 개 지정하고, 변수에 값을 대입한 후에 출력해 본다.
SET @myVar1 = 5, @myVar2 = 3, @myVar3 = 4.25, @myVar4 = '가수 이름==>'; SELECT @myVar1, @myVar2 + @myVar3, @myVar4, name FROM userTBL WHERE height > 180;변수의 값은 일반적인 SELECT…FROM문과도 같이 사용할 수 있다.
step 2: LIMIT에는 원칙적으로 변수를 사용할 수 없으나 PREPARE와 EXECUTE문을 활용해서 변수의 활용도 가능하다.SET @myVar1 = 3; PREPARE myQuery FROM 'SELECT name, height FROM userTBL ORDER BY height LIMIT ?'; EXECUTE myQuery USING @myVar1;
LIMIT는 LIMIT 3과 같이 직접 숫자를 넣어야 하며 LIMIT @변수 형식으로 사용하면 오류가 발생하기 때문에 다른 방식을 사용해야 한다. PREPARE 쿼리이름 FROM '쿼리문'은 쿼리이름에 '쿼리문'을 준비만 해놓고 실행하지는 않는다. 그리고 EXECUTE 쿼리이름을 만나는 순간에 실행된다. EXECUTE는 USING @변수를 이용해서 '쿼리문'에서 ?으로 처리해 놓은 부분에 대입된다. 결국 LIMIT @변수 형식으로 사용된 것과 동일한 효과를 갖는다.


데이터 형식과 형 변환
데이터 형식과 관련된 함수는 자주 사용되므로 잘 기억하자.
데이터 형식 변환 함수
가장 일반적으로 사용되는 데이터 형식 변환과 관련해서는 CAST(), CONVERT() 함수를 사용한다. CAST(), CONVERT()는 형식만 다를 뿐 거의 비슷한 기능을 한다.
형식:
CAST ( expression AS 데이터형식 [ (길이) ] )
CONVERT ( expression, 데이터형식 [(길이) ] )데이터 형식 중에서 가능한 것은 BINARY, CHAR, DATE, DATETIME, DECIMAL, JSON, SIGNED INTEGER, ITME, UNSIGNED INTEGER 등이다.
SELECT AVG(amount) AS '평균 구매 개수' FROM buyTBL ;
개수이므로 정수로 보기 위해서 다음과 같이 CAST() 함수나 CONVERT() 함수를 사용할 수 있다.
SELECT CAST(AVG(amount) AS SIGNED INTEGER) AS '평균 구매 개수' FROM buyTBL ;
또는
SELECT CONVERT(AVG(amount), SIGNED INTEGER) AS '평균 구매 개수' FROM buyTBL ;
위의 결과를 보면 반올림한 정수의 결과를 확인할 수 있다.
다양한 구분자를 날짜 형식으로 변경할 수 있다.
SELECT CAST('2020$12$12' AS DATE);
SELECT CAST('2020/12/12' AS DATE);
SELECT CAST('2020%12%12' AS DATE);
SELECT CAST('2020@12@12' AS DATE);쿼리의 결과를 보기 좋도록 처리할 때도 사용된다. 단가(price)와 수량(amount)을 곱한 실제 입금액을 표시하는 쿼리는 다음과 같이 사용할 수 있다.
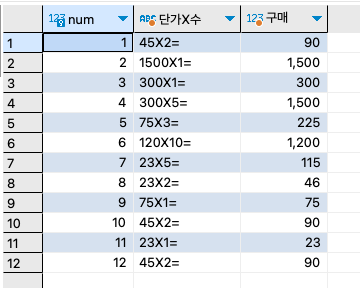
암시적인 형 변환
형 변환 방식에는 명시적인 변환과 암시적인 변환, 두 가지가 있다. 명시적인 변환(Explicit conversion)이란 위에서 한 CAST() 또는 CONVERT() 함수를 이용해서 데이터 형식을 변환하는 것을 말한다. 암시적인 변환(Implicit conversion)이란 CAST()나 CONVERT() 함수를 사용하지 않고 형이 변환되는 것을 말한다.
SELECT '100' + '200' ; -- 문자와 문자를 더함(정수로 변환되서 연산됨)
SELECT concat('100', '200'); -- 문자와 문자를 연결(문자로 처리)
SELECT concat(100, '200'); -- 정수와 문자를 연결(정수와 문자로 변환되서 처리)
SELECT 1 > '2mega'; -- 정수인 2로 변환되어서 비교
SELECT 3 > '2MEGA'; -- 정수인 2로 변환되어서 비교
SELECT 0 = 'mega2'; -- 문자는 0으로 변환됨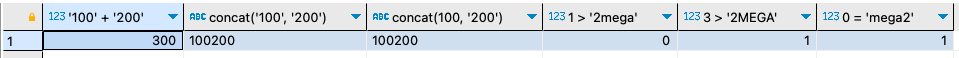
첫 번째 결과인 문자열+문자열은 더하기 연산자 때문에 문자열이 숫자로 변경되어서 계산되었다.
두 번째는 문자열을 연결해주는 CONCAT() 함수이기에 문자열이 그대로 문자열로 처리되었다.
세 번째도 CONCAT() 함수 안의 숫자는 문자열로 변환되어 처리되었다.
네 번째와 비교 연산자인데 앞에 '2'가 들어간 문자열이 숫자로 변경되어서 결국 '1 > 2'의 비교가 된다. 결과는 거짓(0)이 나왔다. 다섯 번째도 마찬가지 방식이다. 마지막 'mega2' 문자열은 숫자로 변경되어도 그냥 0으로 되기 때문에 결국 '0 = 0'이 되어 true(1)의 결과가 나왔다.
다른 DBMS에서는 암시적인 형 변환의 결과가 MySQL과 다를 수 있다. 예로 어떤 DBMS에서 SELECT '100' + '200'의 결과가 '100200' 문자열로 처리되기도 한다.
MySQL 내장 함수
MySQL은 많은 내장 함수를 포함하고 있다. 내장 함수는 크게 제어 흐름 함수, 문자열 함수, 수학 함수, 날짜/시간 함수, 전체 텍스트 검색 함수, 형 변환 함수, XML 함수, 비트 함수, 보안/압축 함수, 정보 함수, 공간 분석 함수, 기타 함수 등으로 나눌 수 있다. 전체 함수의 개수는 수백 개가 넘으며, 이 중 일부는 이미 책의 중간중간에 사용해 왔다.
제어 흐름 함수
제어 흐름 함수는 프로그램의 흐름을 제어한다.
-
IF(수식, 참, 거짓)
수식이 참 또는 거짓인지 결과에 따라서 2중 분기한다.SELECT IF (100>200, '참이다', '거짓이다');
-
IFNULL(수식1, 수식2)
수식1이 NULL이 아니면 수식1이 반환되고, 수식1이 NULL이면 수식2가 반환된다.SELECT IFNULL(NULL, '널이군요'), IFNULL(100, '널이군요');
-
NULLIF(수식1, 수식2)
수식1과 수식2가 같으면 NULL을 반환하고, 다르면 수식1을 반환한다.SELECT NULLIF(100, 100), NULLIF(200, 100);
-
CASE ~ WHEN ~ ELSE ~ END
CASE는 내장 함수는 아니며 연산자(Operator)로 분류된다. 다중 분기에 사용될 수 있으므로 내장 함수와 함께 알아두자SELECT CASE 10 WHEN 1 THEN '일' WHEN 5 THEN '오' WHEN 10 THEN '십' ELSE '모름' END AS 'CASE연습';
CASE 뒤의 값이 10이므로 세 번째 WHEN이 수행되어 '십'이 반환된다. 만약, 해당하는 사항이 없다면 ELSE 부분이 반환된다.
문자열 함수
문자열 함수는 문자열을 조작한다.
-
ASCILL(아스키 코드), CHAR(숫자)
문자의 아스키 코드값을 돌려주거나 숫자의 아스키 코드값에 해당하는 문자를 돌려준다.SELECT ASCII('A'), CHAR(65);
-
BIT_LENGTH(문자열), CHAR_LENGTH(문자열), LENGTH(문자열)
할당된 Bit 크기 또는 문자 크기를 반환한다. CHAR_LENGTH()는 문자의 개수를 반환하며 LENGTH()는 할당된 Byte 수를 반환한다.SELECT BIT_LENGTH('abc'), CHAR_LENGTH('abc'), LENGTH('abc'); SELECT BIT_LENGTH('가나다'), CHAR_LENGTH('가나다'), LENGTH('가나다');


-
CONCAT(문자열1, 문자열2, ···), CONCAT_WS(구분자, 문자열1, 문자열2, ···)
문자열을 이어준다. CONCAT_WS()는 구분자와 함께 문자열을 이어준다.SELECT CONCAT_WS('/', '2025', '01', '01');
-
ELT(위치, 문자열1, 문자열2, ···), FIELD(찾을 문자열, 문자열1, 문자열2, ···), FIND_IN_SET(찾을 문자열, 문자열 리스트), INSTR(기준 문자열, 부분문자열), LOCATE(부분 문자열, 기준 문자열)
ELT()는 위치 번째에 해당하는 문자열을 반환한다. FIELD()는 찾을 문자열의 위치를 찾아서 반환한다. FILED()는 매치되는 문자열이 없으면 0을 반환한다. FIND_IN_SET()은 찾을 문자열을 문자열 리스트에서 찾아서 위치를 반환한다. 문자열 리스트는 콤마(,)로 구분되어 있어야하며 공백이 없어야 한다. INSTR()는 기준 문자열에서 부분 문자열을 찾아서 그 시작 위치를 반환한다. LOCATE()는 INSTR()와 동일하지만 파라미터의 순서가 반대로 되어 있다.SELECT ELT(2, '하나', '둘', '셋'), FIELD('둘', '하나', '둘', '셋'), FIND_IN_SET('둘', '하나,둘,셋'), INSTR('하나둘셋', '둘'), LOCATE('둘', '하나둘셋');
-
FORMAT(숫자, 소수점 자릿수)
숫자를 소수점 아래 자릿수까지 표현한다. 또한 1000 단위마다 콤마(,)를 표시해 준다.SELECT FORMAT(123456.123456, 4);
-
BIN(숫자), HEX(숫자), OCT(숫자)
2진수, 16진수, 8진수의 값을 반환한다.SELECT BIN(31), HEX(31), OCT(31);
-
INSERT(기준 문자열, 위치, 길이, 삽입할 문자열)
기준 문자열의 위치부터 길이만큼을 지우고 삽입할 문자열을 끼워 넣는다.SELECT INSERT('abcdefghi', 3, 4,'@@@@'), INSERT('abcdefghi', 3, 2, '@@@@');
-
LEFT(문자열, 길이), RIGHT(문자열, 길이)
왼쪽 또는 오른쪽에서 문자열의 길이만큼 반환한다.SELECT LEFT ('abcdefghi', 3), RIGHT ('abcdefghi', 3);
-
UPPER(문자열), LOWER(문자열)
소문자를 대문자로, 대문자를 소문자로 변경한다.SELECT LOWER('abcdEFGH') , UPPER('abcdEFGH') ;
LOWER()는 LCASE()와 UPPER()는 UCASE()와 동일한 함수다.
-
LPAD(문자열, 길이, 채울 문자열), RPAD(문자열, 길이, 채울 문자열)
문자열을 길이만큼 늘린 후에, 빈 곳을 채울 문자열로 채운다.SELECT LPAD('이것이', 5, '##') , RPAD('이것이', 5, '##') ;
-
LTRIM(문자열), RTRIM(문자열)
문자열의 왼쪽/오른쪽 공백을 제거한다. 중간의 공백은 제거되지 않는다.SELECT LTRIM(' 이것'), RTRIM('이것 ') ;
-
TRIM(문자열), TRIM(방향 자를문자열 FROM 문자열)
TRIM(문자열)은 문자열의 앞뒤 공백을 모두 없앤다. TRIM(방향 자를문자열 FROM 문자열)에서 방향은 LEADING (앞), BOTH(양쪽), TRAILING(뒤)가 나올 수 있다.SELECT TRIM(' 이것이 '), TRIM(LEADING 'ㅋ' FROM 'ㅋㅋㅋ재밌어요.ㅋㅋㅋ'), TRIM(BOTH 'ㅋ' FROM 'ㅋㅋㅋ재밌어요.ㅋㅋㅋ'), TRIM(TRAILING 'ㅋ' FROM 'ㅋㅋㅋ재밌어요.ㅋㅋㅋ') ;
-
REPEAT(문자열, 횟수)
문자열을 횟수만큼 반복한다.SELECT REPEAT ('이것이', 3);
-
REPLACE(문자열, 원래 문자열, 바꿀 문자열)
문자열에서 원래 문자열을 찾아서 바꿀 문자열로 바꿔준다.SELECT REPLACE ('이것이 MySQL이다.', '이것이', 'This is') ;
-
REVERSE(문자열)
문자열의 순서를 거꾸로 만든다.SELECT REVERSE('MySQL') ;
-
SPACE(길이)
길이만큼의 공백을 반환한다.SELECT CONCAT('이것이', SPACE (10), 'MySQL이다') ;
-
SUBSTRING(문자열, 시작위치, 길이) 또는 SUBSTRING(문자열 FROM 시작위치 FOR 길이)
시작 위치부터 길이만큼 문자를 반환한다. 길이가 생량되면 문자열의 끝까지 반환한다.SELECT SUBSTRING('대한민국만세', 3, 2) ;
SUBSTRING(), SUBSTR(), MID()는 모두 동일한 함수다.
-
SUBSTRING_INDEX(문자열, 구분자, 횟수)
문자열에서 구분자가 왼쪽부터 횟수 번째 나오면 그 이후의 오른쪽은 버린다. 횟수가 음수면 오른쪽부터 세고 왼쪽을 버린다.SELECT SUBSTRING_INDEX('cafe.naver.com', '.', 2) ;
수학 함수
-
ABS(숫자)
숫자의 절댓값을 계산한다SELECT ABS(-100) ;
- ACOS(숫자), ASIN(숫자), ATAN(숫자), ATAN2(숫자1, 숫자2), SIN(숫자), COS(숫자), TAN(숫자)
삼각 함수와 관련된 함수를 제공한다.
-
CEILING(숫자), FLOOR(숫자), ROUND(숫자)
올림, 내림, 반올림을 계산한다.SELECT CEILING(4.7), FLOOR(4.7) , ROUND(4.7) ;
-
CONV(숫자, 원래 진수, 변환할 진수)
숫자를 원래 진수에서 변환할 진수로 계산한다.SELECT CONV('AA', 16, 2), CONV(100, 10, 8) ;
-
DEGREES(숫자), RADIANS(숫자), PI()
라디안 값을 각도값으로, 각도값을 라디안 값으로 변환한다. PI()는 파이값인 3.141592를 반환한다.SELECT DEGREES(PI()) , RADIANS(180) ;
-
EXP(X), LN(숫자), LOG(숫자), LOG(밑수, 숫자), LOG2(숫자), LOG10(숫자)
지수, 로그와 관련된 함수를 제공한다
-
MOD(숫자1, 숫자2) 또는 숫자1 % 숫자2 또는 숫자1 MOD 숫자2
숫자1을 숫자2로 나눈 나머지 값을 구한다.SELECT MOD(157, 10), 157 % 10, 157 MOD 10;
-
POW(숫자1, 숫자2), SQRT(숫자)
거듭제곱값 및 제곱근을 구한다.SELECT POW(2, 3), SQRT(9) ;
-
RAND()
RAND()는 0 이상 1 미만의 실수를 구한다. 만약 'm <= 임의의 정수 < n'를 구하고 싶다면 FLOOR (m + (RAND() * (n-m))을 사용하면 된다.SELECT RAND(), FLOOR(1 + (RAND() * (7-1)));
-
SIGN(숫자)
숫자가 양수, 0, 음수인지를 구한다. 결과는 1, 0, -1 셋 중에 하나를 반환한다.SELECT SIGN(1), SIGN(0), SIGN(-1);
-
TRUNCATE(숫자, 정수)
숫자를 소수점을 기준으로 정수 위치까지 구하고 나머지는 버린다.SELECT TRUNCATE(12345.12345, 2), TRUNCATE(12345.12345, -2) ;
날짜 및 시간 함수
-
ADDDATE(날짜, 차이), SUBDATE(날짜, 차이)
날짜를 기준으로 차이를 더하거나 뺀 날자를 구한다.SELECT ADDDATE('2025-01-01', INTERVAL 31 DAY), ADDDATE('2025-01-01', INTERVAL 1 MONTH) ; SELECT SUBDATE('2025-01-01', INTERVAL 31 DAY), SUBDATE('2025-01-01', INTERVAL 1 MONTH) ;
ADDDATE()와 DATE_ADD()는 동일한 함수이며 SUBDATE()와 DATE_SUB()도 동일한 함수다.
-
ADDTIME(날짜/시간, 시간), SUBTIME(날짜/시간, 시간)
날짜/시간을 기준으로 시간을 더하거나 뺀 결과를 구한다.SELECT ADDTIME('2025-01-01 23:59:59', '1:1:1'), ADDTIME('15:00:00', '2:10:10') ;
-
CURDATE(), CURTIME(), NOW(), SYSDATE()
CURDATE()는 현재 연-월-일을, CURTIME()은 현재 시:분:초를 구한다. NOW()와 SYSDATE()는 현재 '연-월-일 시:분:초'를 구한다.SELECT CURDATE(), CURTIME(), NOW(), SYSDATE() ;
CURDATE(), CURRENT_DATE(), CURRENT_DATE는 모두 동일하며
CURTIME(), CURRENT_TIME(), CURRENT_TIME도 모두 동일하다.
NOW(), LOCALTIME, LOCALTIME(), LOCALTIMESTAMP, LOCALTIMESTAMP()도 모두 동일하다.
- YEAR(날짜), MONTH(날짜), DAY(날짜), HOUR(시간), MINUTE(시간), SECOND(시간), MICROSECOND(시간)
날짜 또는 시간에서 연, 월, 일, 시, 분, 초, 밀리초를 구한다.
SELECT
YEAR (CURDATE()),
MONTH (CURDATE()),
DAYOFMONTH (CURDATE()) ;
SELECT
HOUR (CURTIME()),
MINUTE (CURRENT_TIME()),
SECOND (CURRENT_TIME),
MICROSECOND (CURRENT_TIME) ;


DAYOFMONTH()와 DAY()는 동일한 함수다.
-
DATE(), TIME()
DATETIME 형식에서 연-월-일 및 시:분:초만 추출한다.SELECT DATE(NOW()), TIME(NOW());
-
DATEDIFF(날짜1, 날짜2), TIMEDIFF(날짜1 또는 시간1, 날짜1 또는 시간2)
DATEDIFF()는 날짜1-날짜2의 일수를 결과로 구한다. 즉, 날짜2에서 날짜1까지 몇 일이 남았는지 구한다. TIMEDIFF()는 시간1-시간2의 결과를 구한다.SELECT DATEDIFF('2025-01-01', NOW()) , TIMEDIFF('23:23:59', TIME(NOW()));
-
DAYOFWEEK(날짜), MONTHNAME(), DAYDFYEAR(날짜)
요일(1:일, 2:월~7:토) 및 1년 중 몇 번째 날짜인지를 구한다.SELECT DAYOFWEEK(CURDATE()) , MONTHNAME(CURDATE()) , DAYOFYEAR(CURDATE()) ;
-
LAST_DAY(날짜)
주어진 날짜의 마지막 날짜를 구한다. 주로 그 달이 몇 일까지 있는지 확인할 때 사용한다.SELECT LAST_DAY('2025-02-01');
-
MAKEDATE(연도, 정수)
연도에서 정수만큼 지난 날짜를 구한다.SELECT MAKEDATE(2025, 32);
-
MAKETIME(시, 분, 초)
시, 분, 초를 이용해서 '시:분:초'의 TIME형식을 만든다.SELECT MAKETIME(12, 11, 10) ;
-
PERIOD_ADD(연월, 개월수), PERIOD_DIFF(연월1, 연월2)
PERIOD_ADD()는 연월에서 개월만큼의 개월이 지난 연월을 구한다. 연월은 YYYY 또는 YYYYMM 형식을 사용한다. PERIOD_DIFF()는 연월1-연월2의 개월수를 구한다.SELECT PERIOD_ADD(202501, 11), PERIOD_DIFF(202501, 202312) ;
-
QUARTER(날짜)
날짜가 4분기 중에서 몇 분기인지를 구한다.SELECT QUARTER('2025-07-07') ;
-
TIME_TO_SEC(시간)
시간을 초 단위로 구한다.SELECT TIME_TO_SEC('12:11:10');
시스템 정보 함수
-
USER(), DATABASE()
현재 사용자 및 현재 선택된 데이터베이스를 구한다.SELECT CURRENT_USER(), DATABASE();
USER(), SESSION_USER(), CURRENT_USER()는 모두 동일하다.
DATABASE()와 SCHEMA()도 동일한 함수다.
-
FOUND_ROWS()
바로 앞의 SELECT문에서 조회된 행의 개수를 구한다.SELECT * FROM userTBL ; SELECT FOUND_ROWS();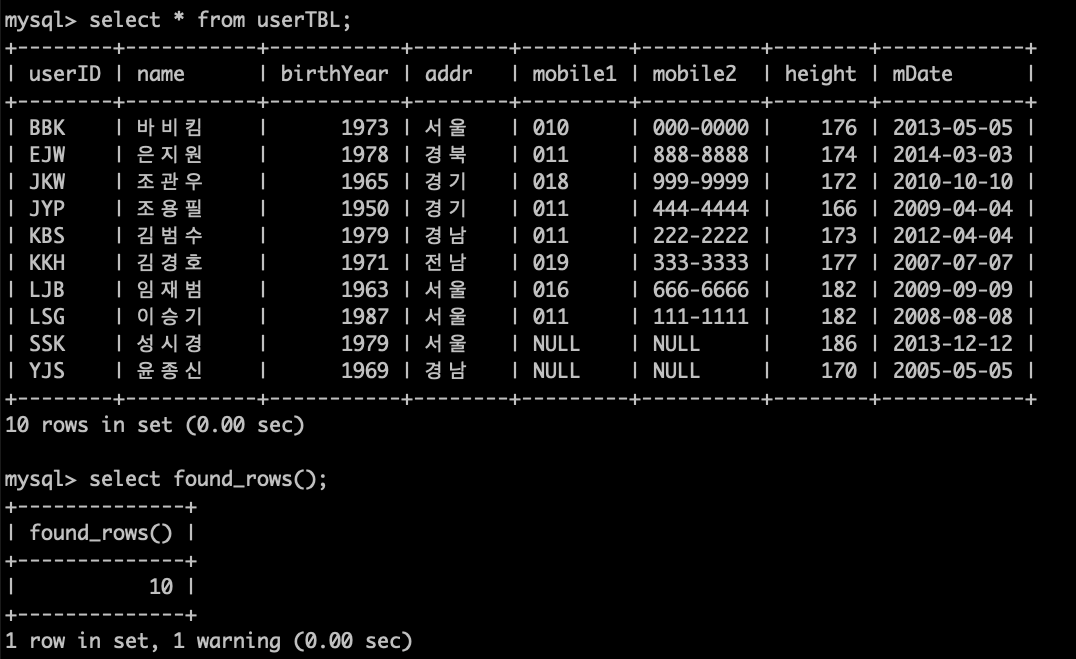
-
ROW_COUNT()
바로 앞의 INSERT, UPDATE, DELETE문에서 입력, 수정, 삭제된 행의 개수를 구한다.
CREATE, DROP문은 0을 반환하고, SELECT문은 -1을 반환한다.UPDATE buyTBL SET price = price * 2; SELECT ROW_COUNT();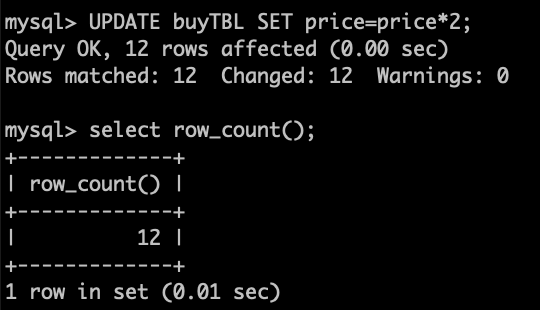
-
VERSION()
현재 MySQL의 버전을 구한다
-
SLEEP(초)
쿼리의 실행을 잠깐 멈춘다.SELECT SLEEP(5) ; SELECT '5초후에 이게 보여요';
그 외의 함수
이 책에서 생략된 MySQL 8.0에서 제공하는 나머지 내장 함수에 대해서는 https://dev.mysql.com/doc/refman/8.0/en/functions.html에서 확인할 수 있다.
대용량 데이터를 넣을 데이터베이스를 구축해보자
step 0: 대용량 텍스트 파일과 대용량 동영상 파일을 준비하자.
step 1: 영화 데이터베이스(movieDB) 및 영화 테이블(movieTBL)을 만들자.
CREATE TABLE movietbl( id int, title varchar(30), director varchar(20), star varchar(20), script LONGTEXT, film LONGBLOB );영화 대본(script)은 LONGTEXT 형식으로, 영화 동영상(film)은 LONGBLOB 형식으로 설정했다.
step 2: 데이터를 한 건 입력하자.INSERT INTO movietbl VALUES ( 1, '쉰들러 리스트', '스필버그', '리암 니슨', LOAD_FILE('/Volumes/share/ASCII.txt'), LOAD_FILE('/Volumes/share/testmovie.mp4') );step 2-1: 파일을 데이터로 입력하려면 LOAD_FILE() 함수를 사용하면 된다.
step 3: 영화 대본과 영화 동영상이 입력되지 않은 이유는 두 가지다.
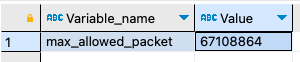
step 3-1: 먼저 최대 패킷 크기(= 최대 파일 크기)가 설정된 시스템 변수인 max_allowed_packet 값을 조회해 보자.SHOW variables LIKE 'max_allowed_packet';
step 3-2: 파일을 업로드/다운로드할 폴더 경로를 별도로 허용해 줘야만 한다. 시스템 변수인 secure_file_priv값을 조회해 보자. 이 경로도 수정해야 한다.SHOW variables LIKE 'secure_file_priv';
step 4: 최대 파일 크기 및 허용된 파일의 경로를 추가하자.
step 4-1: my.ini 또는 my.cnf 파일을 확인하자
step 4-2: max_allowed_packet 값 수정
step 4-3: secure_file_priv 값 수정
step 4-4: my.ini 또는 my.cnf 설정 파일을 변경하면 MySQL 서버를 재시작해야 한다.
step 5: 다시 데이터를 넣어보자.
step 5-1: 기존 데이터를 모두 지우고 다시 데이터를 입력해보자.TRUNCATE movietbl; INSERT INTO movietbl VALUES ( 1, '쉰들러 리스트', '스필버그', '리암 니슨', LOAD_FILE('/Volumes/share/ASCII.txt'), LOAD_FILE('/Volumes/share/testmovie.mp4') );
step 5-2: 전체 글자(script) 확인하기
step 6: 입력된 데이터를 파일로 내려받기 해보자.
step 6-1: LONGTEXT 형식인 영화 대본(movie_script)은 INTO OUTFILE문을 사용하면 텍스트 파일로 내려받을 수 있다.SELECT script FROM movietbl WHERE id = 1 INTO OUTFILE '/Volumes/share/ASCII_out.txt' LINES TERMINATED BY '\\n';step 6-2: 메모장에서 내려받은 파일을 열면 기존과 동일하게 보일 것이다.
step 6-3 LONGBLOB 형식인 영화 동영상(film)은 INTO DUMPFILE문을 사용하면 바이너리 파일로 내려받을 수 있다.
SELECT film FROM movietbl WHERE id = 1 INTO DUMPFILE '/Volumes/share/testmovie_out.mp4';




피벗의 구현
피벗(Pivot)은 한 열에 포함된 여러 값을 출력하고, 이를 여러 열로 변환하여 테이블 반환 식을 회전하고 필요하면 집계까지 수행하는 것을 말한다.
간단한 피벗 테이블을 실습해 보자.
step 1: 샘플 테이블을 만든다.
CREATE TABLE pivotTest( uName char(3), season char(2), amount int );
step 2: 데이터를 9건 입력한다.
INSERT INTO pivotTest VALUES ('김범수', '겨울', 10), ('윤종신', '여름', 15), ('김범수', '가을', 25), ('김범수', '봄', 3), ('김범수', '봄', 37), ('윤종신', '겨울', 40), ('김범수', '여름', 14), ('김범수', '겨울', 22), ('윤종신', '여름', 64);
step 3: SUM()과 IF() 함수, 그리고 GROUP BY를 활용해 보자.
SELECT uName, SUM(IF(season = '봄', amount, 0)) '봄', SUM(IF(season = '여름', amount, 0)) '여름', SUM(IF(season = '가을', amount, 0)) '가을', SUM(IF(season = '겨울', amount, 0)) '겨울' FROM pivotTest GROUP BY uName;
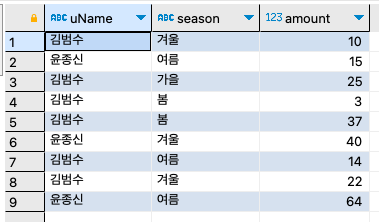

QUIZ: 다음과 같이 계절 별로 나오도록 피벗 테이블을 만드는 SQL을 만들자.

JSON 데이터
현대의 웹과 모바일 응용 프로그램 등과 데이터를 교환하기 위한 개방형 표준 포맷을 말하는데, 속성(Key)과 값(Value)으로 쌍을 이루며 구성되어 있다. JSON은 비록 JavaScript언어에서 파생되었지만 특정한 프로그래밍 언어에 종속되어 있지 않은 독립적인 데이터 포맷이라고 생각하면 된다. 즉, 그 포맷이 단순하고 공개되어 있기에 거의 대부분의 프로그래밍 언어에서 쉽게 읽거나 쓸 수 있도록 코딩할 수 있다.
JSON은 MySQL 5.6.7부터 지원하며, MySQL 8.0에서는 인라인 패스라 불리는 -> 연산자 및 JSON_ARRAYAGG(), JSON_OBJECTAGG(), JSO"N_PRETTY(), JSON_STORAGE_SIZE(), JSON_STORAGE_FREE(), JSON_MERGE_PATCH() 등의 함수가 추가되었다.
한 명의 사용자를 JSON 형태로 표현한 것이다.
{
"아이디" : "BBK",
"이름" : "바비킴",
"생년" : "1973",
"지역" : "서울",
"국번" : "010",
"전화번호" : "00000000",
"키" : "178",
"가입일" : "2013.5.5",
}MySQL은 JSON 관련된 다양한 내장 함수를 제공해서 다양한 조작이 가능하다.
SELECT name, height FROM userTBL WHERE height > 180;
SELECT JSON_OBJECT('name', name, 'height', height) 'JSON 값'
FROM userTBL
WHERE height >= 180 ;

결과 값은 JSON 형태로 구성되었다. 이렇게 구성된 JSON을 MySQL에서 제공하는 다양한 내장 함수를 사용해서 운영할 수 있다.
SET @json = '{
"usertbl" :
[
{"name":"임재범","height":182},
{"name":"이승기","height":182},
{"name":"성시경","height":186}
]
}';
SELECT JSON_VALID(@json) AS JSON_VALID;
SELECT JSON_SEARCH(@json, 'one', '성시경') JSON_SEARCH;
SELECT JSON_EXTRACT(@json, '$.usertbl[2].name') JSON_EXTRACT;
SELECT JSON_INSERT(@json, '$.usertbl[0].mDate', '2009-09-09') JSON_INSERT;
SELECT JSON_REPLACE(@json, '$.usertbl[0].name', '홍길동') JSON_REPLACE;
SELECT JSON_REMOVE(@json, '$.usertbl[0]') JSON_REMOVE;위의 코드에서 @json 변수에 JSON 데이터를 우선 대입하면서 테이블의 이름은 usertbl로 지정했다.
- JSON_VALID()
문자열이 JSON 형식을 만족하면 1을, 그렇지 않으면 0을 반환한다. - JSON_SEARCH()
세 번째 파라미터에 주어진 문자열의 위치를 반환한다. 두 번째 파라미터는 'one'과 'all'중 하나가 올 수 있다. 'one'은 처음으로 매치되는 하나만 반환하면 'all'은 매치되는 모든 것을 반환한다. 결과를 보면 '성시경'은 usertbl의 두 번째의 name에 해당하는 부분에 위치하는 것을 확인할 수 있다. - JSON_EXTRACT()
JSON_SEARCH()와 반대로 지정된 위치의 값을 추출한다. - JSON_INSERT()
새로운 값을 추가한다. 결과를 보면 usertbl의 첫 번째(0)에 mDate를 추가했다. - JSON_REPLACE()
값을 변경한다. 이 예에서는 첫 번째(0)의 name 부분을 '홍길동'으로 변경했다. - JSON_REMOVE()
지정된 항목을 삭제한다. 이 예에서는 첫 번째(0)의 항목을 통째로 삭제했다.
조인
두 개 이상의 테이블을 서로 묶어서 하나의 결과 집합으로 만들어 내는 것을 말한다.
데이터베이스의 테이블은 중복과 공간 낭비를 피하고 데이터의 무결성을 위해서 여러 개의 테이블로 분리하여 저장한다. 그리고 이 분리된 테이블들은 서로 관계(Relation)를 맺고 있다.
INNER JOIN(내부 조인)
SELECT <열 목록>
FROM <첫 번째 테이블>
INNER JOIN <두 번째 테이블>
ON <조인될 조건>
[WHERE 검색조건]위의 형식에서 INNER JOIN을 그냥 JOIN이라고만 써도 INNER JOIN으로 인식한다.
구매 테이블 중에서 JYP라는 아이디를 가진 사람이 구매한 물건을 발송하기 위해서 이름/주소/연락처 등을 조인해서 검색하려면 다음과 같이 작성하면 된다.
SELECT *
FROM buyTBL b
INNER JOIN userTBL u
ON b.userID = u.userID
WHERE b.userID = 'JYP';
위 결과를 생성하기 위해서 다음과 같은 과정을 거친다.
- 구매 테이블의 userID(buyTBL.userID)인 'JYP'를 추출한다.
- 'JYP'와 동일한 값을 회원 테이블의 userID(userTBL.userID)열에서 검색한다.
- 'JYP'라는 아이디를 찾으면 구매 테이블과 회원 테이블의 두 행을 결합(JOIN)한다.
만약 WHERE buyTBL.userID = 'JYP'를 생략하면 buyTBL의 모든 행에 대해서 위와 동일한 방식으로 반복하게 된다.
SELECT *
FROM buyTBL b
INNER JOIN userTBL u
ON b.userID = u.userID
ORDER BY num;
MySQL 8.0.16 버전까지는 ORDER BY num 구문을 넣지 않아도 기준 테이블인 buyTBL의 num열에 의해서 정렬되었으나 MySQL 8.0.17 버전에서는 ORDER BY num 구문을 넣지 않으면 userID열로 정렬된다. 정렬되는 것 외에 결과값이 달라지는 것이 없고, 별로 중요한 사항은 아니다. MySQL 버전에 따라서 차례가 조금 다르게 나오더라도 무시하고 넘어가자.
아이디/이름/구매물품/주소/연락처만 추출하자.
SELECT
b.userId,
name,
prodName,
addr,
CONCAT(mobile1, mobile2) '연락처'
FROM buyTBL b
INNER JOIN userTBL u
ON b.userID = u.userID
ORDER BY num;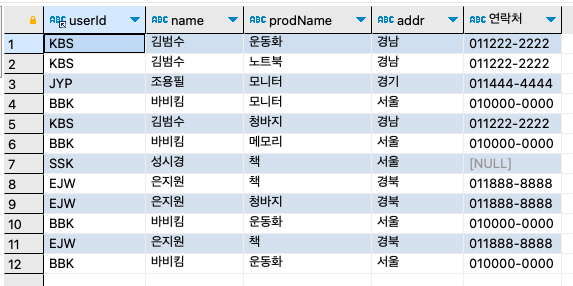
다음과 같은 WHERE 구문으로도 INNER JOIN을 표현할 수도 있다. 하지만, 호환성 등의 문제로 별로 권장하지 않는 방식이다. 개발자에 따라서 다음의 방식으로 조인하는 경우도 있으니 알아둘 필요는 있다.
SELECT
b.userId,
name,
prodName,
addr,
CONCAT(mobile1, mobile2) '연락처'
FROM buyTBL b, userTBL u
WHERE b.userID = u.userID
ORDER BY num;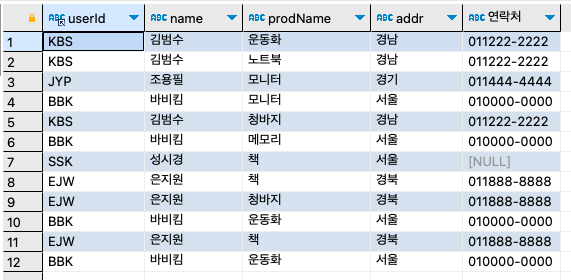
이번에는 회원 테이블(userTBL)을 기준으로 JYP라는 아이디가 구매한 물건의 목록을 보자.
SELECT
u.userID,
u.name,
b.prodName,
u.addr,
CONCAT(u.mobile1, '-', u.mobile2) 'phone'
FROM userTBL u
INNER JOIN buyTBL b
ON u.userID = b.userID
WHERE u.userID = 'JYP' ;
이번에는 전체 회원들이 구매한 목록을 모두 출력해 보자. 그리고 결과를 보기 쉽게 회원ID순으로 정렬하도록 하자.
SELECT
u.userID,
u.name,
b.prodName,
u.addr,
CONCAT(u.mobile1, '-', u.mobile2) 'phone'
FROM userTBL u
INNER JOIN buyTBL b
ON u.userID = b.userID
ORDER BY u.userID ;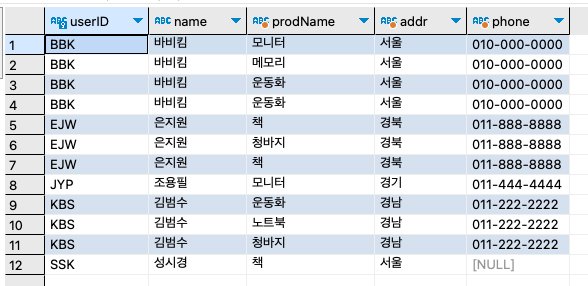
결과가 아무런 이상이 없기는 하지만 조금 전에 말했던 '전체 회원들'과는 차이가 있다. '전체 회원들'이 아닌 '구매한 기록이 있는 회원들'의 결과다.
한 번도 구매하지 않은 회원인 이승기, 김경호, 임재범, 윤종신, 조관우는 나타나지 않았다. 여기서는 구매한 회원의 기록도 나오면서, 더불어 구매하지 않았어도 회원의 이름/주소 등은 나오도록 조인할 필요도 있을 수 있다. 이렇게 조인해주는 방식이 OUTER JOIN이다. 결국 INNER JOIN은 양쪽 테이블에 모두 내용이 있는 것만 조인되는 방식이고, OUTER JOIN은 INNER JOIN과 마찬가지로 양쪽에 내용이 있으면 당연히 조인되고, 한쪽에만 내용이 있어도 그 결과가 표시되는 조인 방식이다.
상황에 따라 유용한 조인을 사용하자.
예를 들어, "쇼핑몰에서 한번이라도 구매한 기록이 있는 우수회원들에게 감사의 안내문을 발송하도록 하자"의 경우에는 다음과 같이 DISTINCT문을 활용해서 회원의 주소록을 뽑을 수 있다.
SELECT
DISTINCT u.userID,
u.name,
u.addr
FROM userTBL u
INNER JOIN buyTBL b
ON u.userID = b.userID
ORDER BY u.userID ;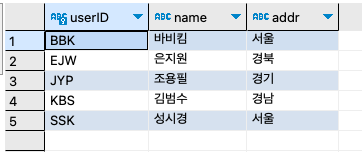
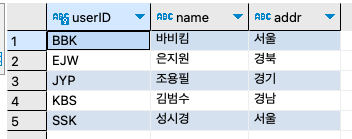
위의 결과를 EXISTS문을 사용해서도 동일한 결과를 낼 수 있다.
SELECT
DISTINCT u.userID,
u.name,
u.addr
FROM userTBL u
WHERE EXISTS (
SELECT *
FROM buyTBL b
WHERE u.userID = b.userID
);
이번에는 세 개 테이블의 조인을 살펴보자.
학생과 동아리의 관계를 생각해 보자. 한 학생은 여러 개의 동아리에 가입해서 활동할 수 있고, 하나의 동아리에는 여러 명의 학생이 가입할 수 있으므로 두 개는 서로 '다대다(many-to-many)'의 관계라고 표현할 수 있다. 다대다 관계는 논리적으로 구성이 가능하지만 이를 물리적으로 구성하기 위해서는 두 테이블의 사이에 연결 테이블을 둬서 이 연결 테이블과 두 테이블이 일대다 관계를 맺도록 구성해야 한다.
실습: 세 개 테이블의 조인을 실습하자.
step 1: 테이블을 생성하고, 데이터를 입력하는 쿼리문을 작성하자.
CREATE TABLE stdtbl( name varchar(10) PRIMARY KEY, addr char(4) NOT NULL ); CREATE TABLE clubtbl( clubName varchar(10) PRIMARY KEY, roomNo char(4) NOT NULL ); CREATE TABLE stdclubtbl( num int AUTO_INCREMENT PRIMARY KEY, stdName varchar(10), clubName varchar(10), CONSTRAINT fk_stdtbl FOREIGN KEY(stdName) REFERENCES stdtbl(name), CONSTRAINT fk_clubtbl FOREIGN KEY(clubName) REFERENCES clubtbl(clubName) ); INSERT INTO stdtbl VALUES ('김범수', '경남'), ('성시경', '서울'), ('조용필', '경기'), ('은지원', '경북'), ('바비킴', '서울'); INSERT INTO clubtbl VALUES ('수영', '101호'), ('바둑', '102호'), ('축구', '103호'), ('봉사', '104호'); INSERT INTO stdclubtbl VALUES (NULL, '김범수', '바둑'), (NULL, '김범수', '축구'), (NULL, '조용필', '축구'), (NULL, '은지원', '축구'), (NULL, '은지원', '봉사'), (NULL, '바비킴', '봉사');
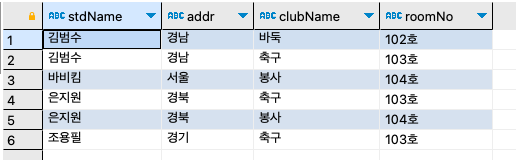
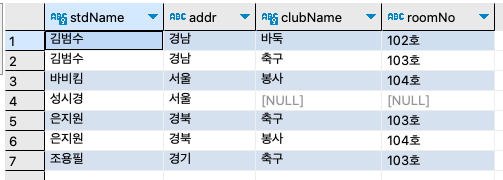
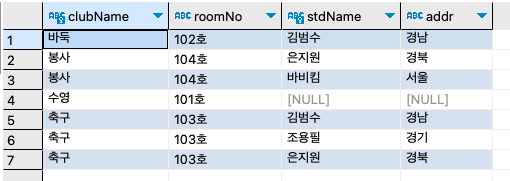
step 2: 학생 테이블, 동아리 테이블, 학생동아리 테이블을 이용해서 학생을 기준으로 학생 이름/지역/가입한 동아리/동아리방을 출력하자.
SELECT s.stdName, s.addr, c.clubName, c.roomNo FROM stdtbl s INNER JOIN stdclubtbl sc ON s.stdName = sc.stdName INNER JOIN clubtbl c ON sc.clubName = c.clubName ORDER BY s.stdName;
이 쿼리문은 학생동아리 테이블과 학생 테이블의 일대다 관계를 INNER JOIN하고, 또한 학생동아리 테이블과 동아리 테이블의 일대다 관계를 INNER JOIN한다.
세 개의 테이블이 조인되는 쿼리를 만드는 순서는 stdtbl과 stdclubtbl이 조인 그 결과와 clubtbl이 조인되는 형식으로 쿼리문을 작성하면 된다
step 3: 이번에는 동아리를 기준으로 가입한 학생의 목록을 출력하자.
SELECT s.stdName, s.addr, c.clubName, c.roomNo FROM stdtbl s INNER JOIN stdclubtbl sc ON s.stdName = sc.stdName INNER JOIN clubtbl c ON sc.clubName = c.clubName ORDER BY c.clubName ;
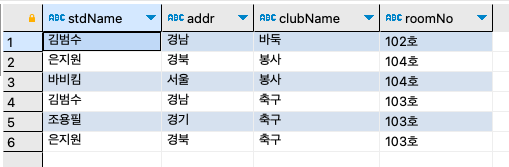
OUTER JOIN(외부 조인)
조인의 조건에 만족되지 않는 행까지도 포함시킨다.
SELECT <열 목록>
FROM <첫 번째 테이블(LEFT 테이블)>
<LEFT | RIGHT | FULL> OUTER JOIN <두 번째 테이블(RIGHT 테이블)>
ON <조인될 조건>
[WHERE 검색조건] ;전체 회원의 구매기록을 보자. 단, 구매 기록이 없는 회원도 출력되어야 한다.
SELECT
u.userID,
u.name,
b.prodName,
u.addr,
CONCAT(u.mobile1, u.mobile2) 'phone'
FROM userTBL u
LEFT OUTER JOIN buyTBL b
ON u.userID = b.userID
ORDER BY u.userID ;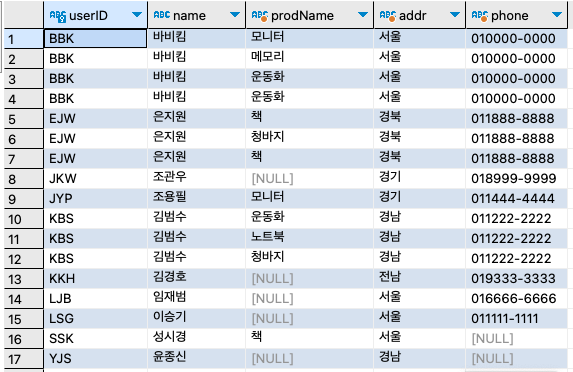
동일한 결과를 얻기 위해서 구문을 RIGHT OUTER JOIN으로 바꾸려면 단순히 왼쪽과 오른쪽 테이블의 위치만 바꿔주면 된다.
SELECT
u.userID,
u.name,
b.prodName,
u.addr,
CONCAT(u.mobile1, u.mobile2) 'phone'
FROM buyTBL b
RIGHT OUTER JOIN userTBL u
ON u.userID = b.userID
ORDER BY u.userID ;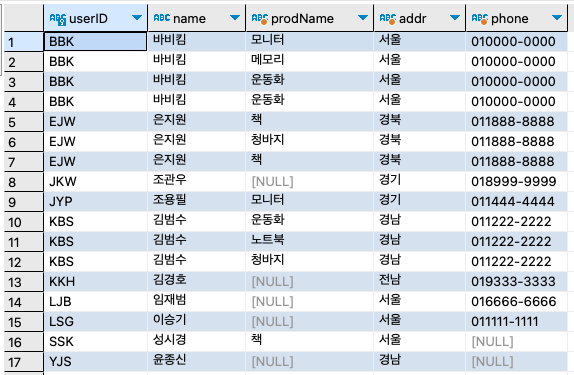
한 번도 구매한 적이 없는 유령(?) 회원의 목록을 뽑아보자.
SELECT
u.name,
b.prodName
FROM userTBL u
LEFT OUTER JOIN buyTBL b
ON u.userID = b.userID
WHERE b.prodName IS NULL
ORDER BY u.userID ;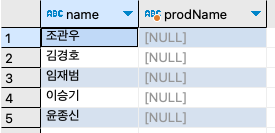
이번에는 FULL OUTER JOIN(전체 조인 또는 전체 외부 조인)에 대해서 살펴보자. FULL OUTER JOIN은 LEFT OUTER JOIN과 RIGHT OUTER JOIN을 합쳐진 것이라고 생각하면 된다.
즉, 한쪽을 기준으로 조건과 일치하지 않는 것을 출력하는 것이 아니라, 양쪽 모두에 조건이 일치하지 않는 것을 모두 출력하는 개념이다.
실습5: LEFT/RIGHT/FULL OUTER JOIN을 실습하자.
앞의 <실습 4>에서 3개의 테이블을 가지고INNER JOIN 했던 결과를 OUTER JOIN으로 고려하자. 또 두 개의 조인을 고려한FULL JOIN을 테스트하자.
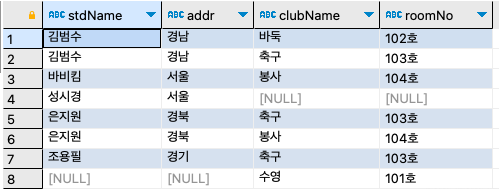
step 1: 앞에서 했던 <실습 4> step2의 학생을 기준으로 출력된 결과를 보면, 동아리에 가입하지 않은 학생 성시경은 출력이 안됐다. OUTER JOIN으로 동아리에 가입하지 않은 학생도 출력되도록 수정하자.
간단히 INNER JOIN을 LEFT OUTER JOIN으로 변경하면 된다.SELECT s.stdName, s.addr, c.clubName, c.roomNo FROM stdtbl s LEFT OUTER JOIN stdclubtbl sc ON s.stdName = sc.stdName LEFT OUTER JOIN clubtbl c ON sc.clubName = c.clubName ORDER BY s.stdName ;
step 2: 이번에는 동아리를 기준으로 가입된 학생을 촐력하되, 가입 학생이 하나도 없는 동아리도 출력되게 하자.
SELECT c.clubName, c.roomNo, s.stdName, s.addr FROM stdtbl s LEFT OUTER JOIN stdclubtbl sc ON s.stdName = sc.stdName RIGHT OUTER JOIN clubtbl c ON sc.clubName = c.clubName ORDER BY c.clubName ;
step 3: 위의 두 결과를 하나로 합쳐보자. 즉, 동아리에 가입하지 않은 학생도 출력되고 학생이 한 명도 없는 동아리도 출력되게 하자. 앞의 두 쿼리를 UNION으로 합쳐주면 된다.
SELECT s.stdName, s.addr, c.clubName, c.roomNo FROM stdtbl s LEFT JOIN stdclubtbl sc ON s.stdName = sc.stdName LEFT JOIN clubtbl c ON sc.clubName = c.clubName UNION SELECT s.stdName, s.addr, c.clubName, c.roomNo FROM stdtbl s LEFT OUTER JOIN stdclubtbl sc ON s.stdName = sc.stdName RIGHT OUTER JOIN clubtbl c ON sc.clubName = c.clubName;
CROSS JOIN(상호 조인)
CROSS JOIN은 한쪽 테이블의 모든 행들과 다른 쪽 테이블의 모든 행을 조인시키는 기능을 한다.
그래서 CROSS JOIN의 결과 개수는 두 테이블 개수를 곱한 개수가 된다.
이러한 CROSS JOIN을 카티션곱(Cartesian Product)이라고도 부른다.
SELECT *
FROM buyTBL
CROSS JOIN userTBL ;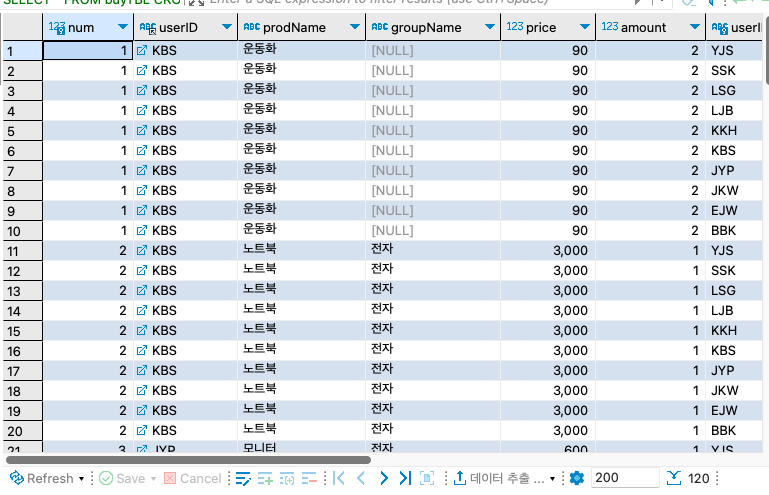
CROSS JOIN을 하려면 위와 동일한 구문으로 WHERE 구문 없이 FROM절에 테이블 이름들을 나열해도 된다.
이 역시 별로 권장하는 바는 아니다.
CROSS JOIN에는 ON 구문을 사용할 수 없다. CROSS JOIN의 용도는 테스트로 사용할 많은 용량의 데이터를 생성할 때 주로 사용한다.
SELECT count(*) '데이터개수'
FROM employees
CROSS JOIN titles;
SELF JOIN(자체 조인)
자기 자신과 자기 자신이 조인한다. SELF JOIN을 활용하는 경우의 대표적인 예가 조직도와 관련된 테이블이다.
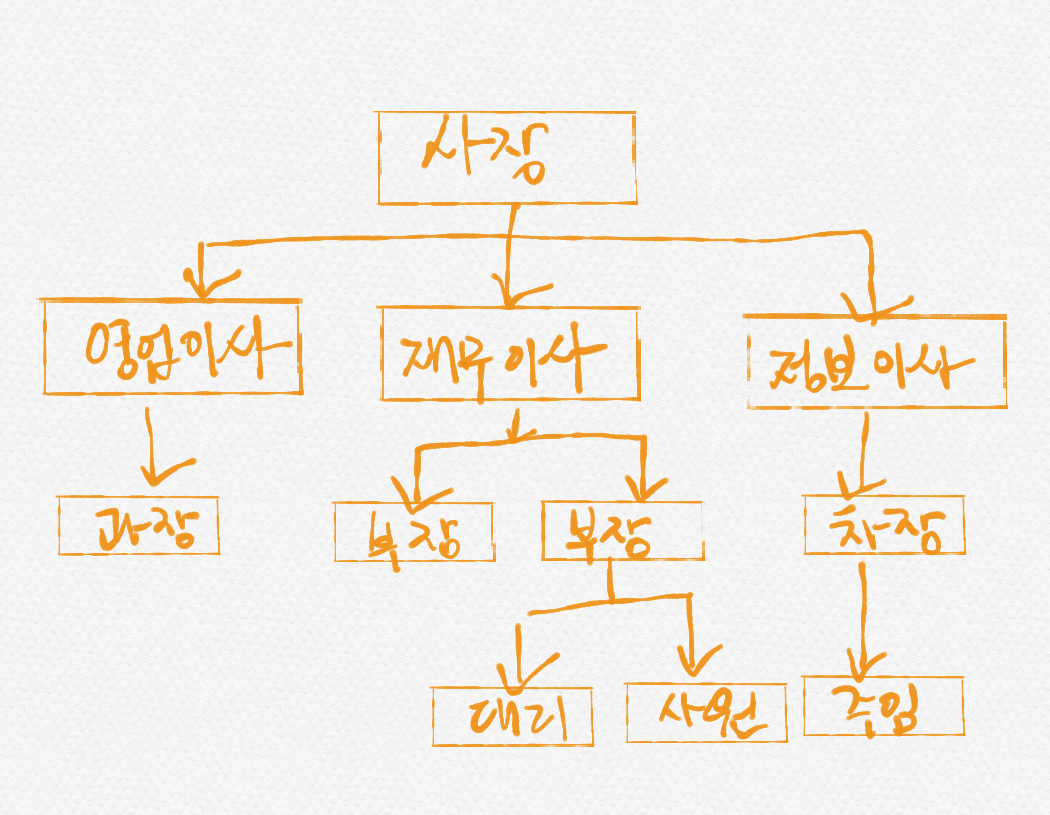
위 조직도를 테이블로 나타내 보자.
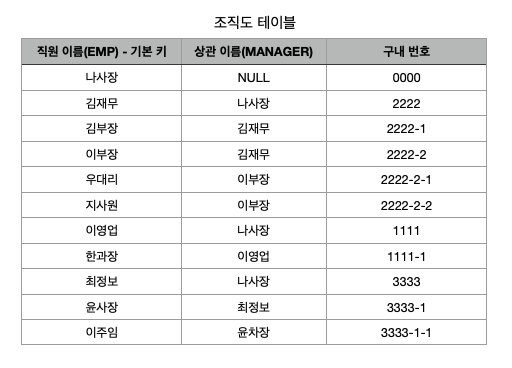
이부장을 보면 이부장은 직원이므로 직원 이름 열에 존재한다. 그러면서 동시에 우대리와 지사원의 상관이어서 상관 이름 열에도 존재한다. 만약, 우대리의 상관의 구내번호를 알려면 EMP열과 MANAGER열을 조인해야 이부장의 구내번호를 알 수 있다.
실습 6: 하나의 테이블에서 SELF JOIN을 활용해 보자.
step 1: 우선 조직도 테이블을 정의하고 데이터를 입력하자.
step 1-1: 테이블을 정의하자.CREATE TABLE emptbl ( emp char(3), manager char(3), empTel varchar(8) );step 1-2: 데이터를 입력하자.
INSERT INTO emptbl VALUES ('나사장', NULL, '0000'), ('김재무', '나사장', '2222'), ('김부장', '김재무', '2222-1'), ('이부장', '김재무', '2222-2'), ('우대리', '이부장', '2222-2-1'), ('지사원', '이부장', '2222-2-2'), ('이영업', '나사장', '1111'), ('한과장', '이영업', '1111-1'), ('최정보', '나사장', '3333'), ('윤차장', '최정보', '3333-1'), ('이주임', '윤차장', '3333-1-1');
step 2: SELF JOIN을 활용해 보자.
step 2-1: 우대리 상관의 연락처를 확인하고 싶다면 다음과 같이 사용할 수 있다.SELECT a.emp '부하직원', b.emp '직속상관', b.empTel '직속상관연락처' FROM emptbl a INNER JOIN emptbl b ON a.manager = b.emp WHERE a.emp = '우대리';

UNION / UNION ALL / NOT IN / IN
UNION은 두 쿼리의 결과를 행으로 합치는 것을 말한다.
SELECT
stdName,
addr
FROM stdtbl ;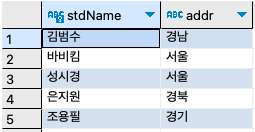
SELECT
clubName, roomNo
FROM clubtbl ;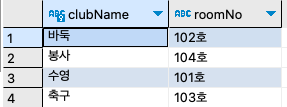
SELECT
stdName,
addr
FROM stdtbl
UNION
SELECT
clubName, roomNo
FROM clubtbl ;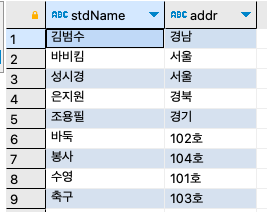
UNION 형식
SELECT 문장1
UNION [ALL]
SELECT 문장2SELECT 문장1과 SELECT 문장2의 결과 열의 개수가 같아야 하고, 데이터 형식도 각 열 단위로 같거나 서로 호환되는 데이터 형식이어야 한다. 당연히 문장1의 결과는 INT인데, 문장2의 결과는 CHAR이라면 오류가 발생할 것이다. 또한 열 이름은 위에 표현되어 있듯이 문장1의 열 이름을 따른다. UNION만 사용하면 중복된 열은 제거되고 데이터가 정렬되어 나오며, UNION ALL을 사용하면 중복된 열까지 모두 출력된다.
SELECT
stdName,
addr
FROM stdtbl
UNION ALL
SELECT
clubName, roomNo
FROM clubtbl ;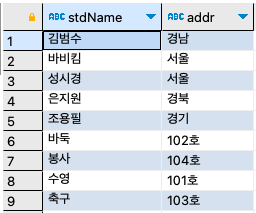
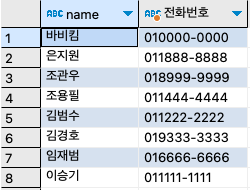
NOT IN은 첫 번째 쿼리의 결과 중에서, 두 번째 쿼리에 해당하는 것을 제외하기 위한 구문이다. 예로 사용자를 모두 조회하되 전화가 없는 사람을 제외하고자 한다면 다음과 같이 사용하면 된다.
SELECT
name,
concat(mobile1, mobile2) '전화번호'
FROM userTBL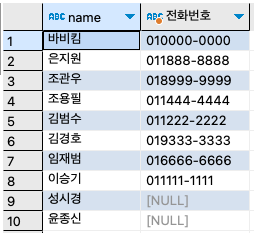
SELECT
name,
concat(mobile1, mobile2) '전화번호'
FROM userTBL
WHERE name
NOT IN (
SELECT name
FROM userTBL
WHERE mobile1 IS NULL
);
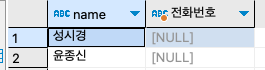
NOT IN과 반대로 첫 번째 쿼리의 결과 중에서, 두 번째 쿼리에 해당되는 것만 조회하기 위해서는 IN을 사용하면 된다. 예로 전화가 없는 사람만 조회하고자 할 때 다음과 같이 사용한다.
SELECT
name,
concat(mobile1, mobile2) '전화번호'
FROM userTBL
WHERE name
IN (
SELECT name
FROM userTBL
WHERE mobile1 IS NULL
);
SQL 프로그래밍
스토어드 프로시저, 스토어드 함수, 커서, 트리거 부분의 기본이 되므로 잘 알아두자.
SQL에서도 다른 프로그래밍 언어와 비슷한 분기, 흐름 제어, 반복의 기능이 있다.
SQL 프로그래밍을 진행하기 전에 우선 스토어드 프로시저를 만들고 사용하는 방법을 간단히 요약하고 넘어가자.
DELIMITER $$
CREATE PROCEDURE 스토어드 프로시저이름()
BEGIN
SQL 프로그래밍
END $$
DELIMITER ;
CALL 스토어드 프로시저이름();DELIMITER $$ ~ END $$ 부분까지는 스토어드 프로시저의 코딩할 부분을 묶어준다고 보면 된다. MySQL의 종료 문자는 세미콜론인데 CREATE PROCEDURE 안에서도 세미콜론이 종료 문자이므로 어디까지가 스토어드 프로시저인지 구별이 어렵다. 그래서 END $$가 나올 때까지를 스토어드 프로시저로 인식하게 하는 것이다. 그리고 다시 DELIMITER ;로 종료 문자를 세미콜론으로 변경해 놓아야한다. CALL 스토어드 프로시저이름();은 CREATE PROCEDURE로 생성한 스토어드 프로시저를 호출(=실행)한다.
IF···ELSE
조건에 따라 분기한다. 한 문장 이상이 처리되어야 할 때는 BEGIN.. END와 함께 묶어줘야만 하며, 습관적으로 실행할 문장이 한 문장이라도 BEGIN.. END로 묶어주는 것이 좋다.
형식:
IF <부울 표현식> THEN
SQL문장들1..
ELSE
SQL문장들2..
END IF;
--------------------------------
DROP PROCEDURE IF EXISTS ifProc;
DELIMITER $$
CREATE PROCEDURE ifProc()
BEGIN
DECLARE var1 int; -- var1 변수 선언
SET var1 = 100; -- 변수에 값 대입
IF var1 = 100 THEN -- 만약 @var1이 100이라면,
SELECT '100입니다.';
ELSE
SELECT '100이 아닙니다.';
END IF;
END $$
DELIMITER ;
CALL ifProc();MySQL은 사용자 정의 변수를 만들 때 앞에 @를 붙인다고 배웠다. 하지만 스토어드 프로시저나 함수 등에서는 DECLARE문을 사용해서 지역변수를 선언할 수 있다. 이 지역변수 앞에는 @를 붙이지 않고, 일반 프로그래밍 언어의 변수처럼 사용하면 된다.
이번에는 employees DB의 employees테이블을 사용해 보자.
직원번호에 10001번에 해당하는 직원의 입사일이 5년이 넘었는지를 확인해 보자.
DROP PROCEDURE IF EXISTS ifProc2;
USE employees;
DELIMITER $$
CREATE PROCEDURE ifProc2()
BEGIN
DECLARE hireDATE DATE; -- 입사일
DECLARE curDATE DATE; -- 오늘
DECLARE days INT; -- 근무한 일수
SELECT hire_date INTO hireDATE --hire_date열의 결과를 hireDATE에 대입
FROM employees
WHERE emp_no = 10001;
SET curDATE = current_date(); -- 현재 날짜
SET days = datediff(curDATE, hireDATE); -- 날짜의 차이, 일 단위
IF (days/365) >= 5 THEN -- 5년이 지났다면
SELECT CONCAT('입사한지 ', days, '일이나 지났습니다. 축하드립니다!');
ELSE
SELECT '입사한지 ', days + '일밖에 안되었네요. 열심히 일하세요.';
END IF;
END $$
DELIMITER ;
CALL ifProc2();
SELECT 열 이름 INTO 변수이름 FROM 테이블이름 구문은 조회된 열의 결과 값을 변수에 대입한다.
CASE
delimiter $$
CREATE PROCEDURE ifProc3()
BEGIN
DECLARE point int;
DECLARE credit char(1);
SET point = 77 ;
IF point >= 90 THEN
SET credit = 'A';
ELSEIF point >= 80 THEN
SET credit = 'B';
ELSEIF point >= 70 THEN
SET credit = 'C';
ELSEIF point >= 60 THEN
SET credit = 'D';
ELSE
SET credit = 'F';
END IF;
SELECT CONCAT('취득점수==> ', point) '취득점수' , CONCAT('학점==> ', credit) '학점';
END $$
DELIMIRE ;
CALL ifProc3();
IF문을 CASE문으로 변경할 수도 있다.
delimiter $$
CREATE PROCEDURE caseProc()
BEGIN
DECLARE point int;
DECLARE credit char(1);
SET point = 77 ;
CASE
WHEN point >= 90 THEN
SET credit = 'A';
WHEN point >= 80 THEN
SET credit = 'B';
WHEN point >= 70 THEN
SET credit = 'C';
WHEN point >= 60 THEN
SET credit = 'D';
ELSE
SET credit = 'F';
END CASE;
SELECT CONCAT('취득점수==> ', point) '취득점수' , CONCAT('학점==> ', credit) '학점';
END $$
DELIMIRE ;
CALL caseProc();
CASE문은 혹시 조건에 맞는 WHEN이 여러 개더라도 먼저 조건이 만족하는 WHEN이 처리된다.
CASE문의 활용은 SELECT문에서 더 많이 사용된다.
실습 7: CASE문을 활용하는 SQL 프로그래밍을 작성하자.
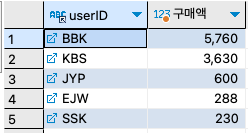
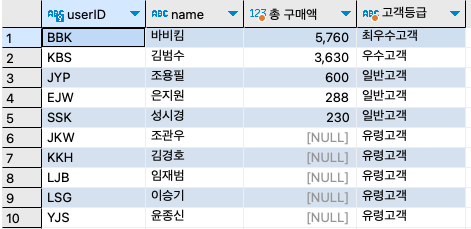
구매 테이블(buttbl)에 구매액(price*amount)이 1500원 이상인 고객은 '최우수 고객', 1000원 이상인 고객은 '우수고객', 1원 이상인 고객은 '일반고객'으로 출력하자. 또, 전혀 구매 실적이 없는 고객은 '유령고객'이라고 출력하자.
@@@@@@@@@@@이미지@@@@@@@@@@@@@
step 1: buytbl에서 구매액(price*amount)을 사용자 아이디(userID)별로 그룹화 한다. 또, 구매액이 높은 순으로 정렬한다.
SELECT userID, SUM(price * amount) '구매액' FROM buyTBL b GROUP BY userID ORDER BY SUM(price * amount) DESC ;
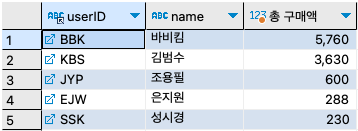
step 2: 사용자 이름이 빠졌으므로 usertbl과 조인해서 사용자 이름도 출력하자.
SELECT b.userID, u.name, SUM(price*amount) '총 구매액' FROM buyTBL b INNER JOIN userTBL u ON b.userID = u.userID GROUP BY b.userID ORDER BY SUM(price*amount) DESC ;
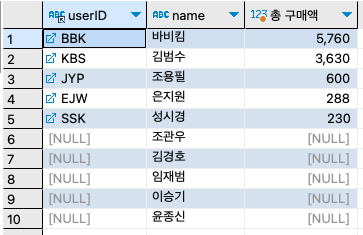
step 3: 그런데, buytbl에서 구매한 고객의 명단만 나왔을 뿐 구매하지 않은 고객의 명단은 나오지 않았다. 오른쪽 테이블(usertbl)의 내용이 없더라도 나오도록 하기 위해 RIGHT OUTER JOIN으로 변경한다.
SELECT b.userID, u.name, SUM(price*amount) '총 구매액' FROM buyTBL b RIGHT OUTER JOIN userTBL u ON b.userID = u.userID GROUP BY b.userID, u.name ORDER BY SUM(price*amount) DESC ;
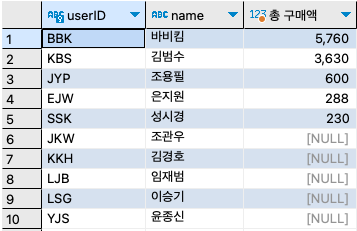
step 4: 그런데 결과를 보니 name은 제대로 나왔으나 구매한 기록이 없는 고객은 userID 부분이 null로 나왔다. 또, 메시지 탭을 보면 경고도 나왔다. 이유는 SELECT절에서 b.userID를 출력하기 때문이다. buytbl에는 윤종신, 김경호 등이 구매한 적이 없으므로 아예 해당 아이디가 없다. userID의 기준을 buytbl에서 usertbl로 변경하자.
SELECT u.userID, u.name, SUM(price*amount) '총 구매액' FROM buyTBL b RIGHT OUTER JOIN userTBL u ON b.userID = u.userID GROUP BY u.userID, u.name ORDER BY SUM(price*amount) DESC ;
step 5: 이제는 총 구매액에 따른 고객 분류를 처음에 제시했던 대로 CASE문만 따로 고려해 보자.
CASE WHEN (총구매액 >= 5000) THEN '최우수고객' WHEN (총구매액 >= 3000) THEN '우수고객' WHEN (총구매액 >= 1) THEN '일반고객' ELSE '유령고객' END
step 6: 작성한 CASE 구문을 SELECT에 추가한다.
SELECT u.userID, u.name, SUM(price*amount) '총 구매액' , CASE WHEN (SUM(price*amount) >= 5000) THEN '최우수고객' WHEN (SUM(price*amount) >= 3000) THEN '우수고객' WHEN (SUM(price*amount) >= 1) THEN '일반고객' ELSE '유령고객' END '고객등급' FROM buyTBL b RIGHT OUTER JOIN userTBL u ON b.userID = u.userID GROUP BY u.userID, u.name ORDER BY SUM(price*amount) DESC ;
WHILE과 ITERATE/LEAVE
형식:
WHILE <부울 식> DO
SQL 명령문들···
END WHILE;1에서 100까지의 값을 모두 더하는 간단한 기능을 구현해 보자.
DELIMITER $$
CREATE PROCEDURE whileProc()
BEGIN
DECLARE i int;
DECLARE hap int;
SET i = 1;
SET hap = 0;
WHILE i != 101 DO
SET hap = hap + i;
SET i = i + 1;
END WHILE ;
SELECT hap;
END $$
DELIMITER ;
CALL whileProc();
그런데, 1에서 100까지 합계에서 7의 배수를 제외시키려면 어떻게 해야 할까? 즉 1+2+3+4+5+6+8+9+···100의 합계를 구하고 싶다. 또, 더하는 중간에 합계가 1000이 넘으면 더하는 것을 그만두고, 출력을 하고 싶다면? 그럴 경우에는 ITERATE문과 LEAVE문을 사용할 수 있다.
ITERATE문은 다른 프로그래밍 언어의 CONTINUE와 LEAVE문은 BREAK문과 비슷한 역할을 한다.
DROP PROCEDURE IF EXISTS whileProc2;
DELIMITER $$
CREATE PROCEDURE whileProc2()
BEGIN
DECLARE i int;
DECLARE hap int;
SET i = 1;
SET hap = 0;
myWhile: WHILE i != 101 DO
IF (i%7 = 0) THEN
SET i = i + 1;
ITERATE myWhile;
END IF ;
SET hap = hap + i;
SET i = i + 1;
IF hap > 1000 THEN
LEAVE myWhile;
END IF;
END WHILE ;
SELECT hap;
END $$
DELIMITER ;
CALL whileProc2();
QUIZ 1부터 1000까지의 숫자 중에서 3의 배수 또는 8의 배수만 더하는 스토어드 프로시저를 만들어 보자. 즉, 3+6+8+9+12+15+16···..만 더해지도록 한다.
오류 처리
DECLARE 액셕 HANDLER FOR 오류조건 처리할_문장;-
액션
오류 발생 시에 행동을 정의하는데 CONTINUE와 EXIT 둘 중 하나를 사용한다. CONTINUE가 나오면 제일 뒤의 '처리할_문장' 부분이 처리된다. -
오류조건
어떤 오류를 처리할 것인지를 지정한다. 여기에는 MySQL의 오류 코드 숫자가 오거나 SQLSTATE(상태코드), SQLEXCEPTION, SQLWARNING, NOT FOUND 등이 올 수 있다. SQLSTATE에서 상태코드는 5자리 문자열로 되어 있다. SQLEXCEPTION은 대부분의 오류를, SQLWARNING은 경고 메시지를, NOT FOUND는 커서나 SELECT···INTO에서 발생되는 오류를 의미한다. -
처리할_문장
처리할 문장이 하나라면 한 문장이 나오면 되며, 처리할 문장이 여러 개일 경우에는 BEGIN···END로 묶어줄 수 있다.
MySQL 8.0의 오류 코드(Error Code)는 서버 오류가 1000~1906, 3000~3186까지 정의되어 있으며, 클라이언트 오류는 2000~2062까지 정의되어 있다. 예로 SELECT * FROM noTable;문을 실행할 때 noTable이 없을 경우에는 오류코드는 1146이, 상태코드는 '42S02'가 발생된다. 각 오류코드 상태코드에 대한 상세한 설명은 이 책에서는 지면상 어려우므로 https://dev.mysql.com/doc/mysql-errors/8.0/en/server-error-reference.html을 참조하자.
다음의 예는 테이블이 없을 경우에 오류를 직접 처리하는 코드다. DECLARE행이 없다면 MySQL이 직접 오류 메시지를 발생시키지만, DECLARE 부분이 있어서 사용자가 지정한 메시지가 출력된다.
DROP PROCEDURE IF EXISTS errorProc;
DELIMITER $$
CREATE PROCEDURE errorProc()
BEGIN
DECLARE CONTINUE HANDLER FOR 1146 SELECT '테이블이 없어요ㅠㅠ' AS '메시지';
SELECT * FROM noTable;
END $$
DELIMITER ;
CALL errorProc();
위 코드에서 1146 대신에 SQLSTATE '42S02'로 써줘도 된다. 둘다 테이블이 없을 경우를 의미한다.
usertbl에 이미 존재하는 'LSG'라는 아이디를 생성시켜 보도록 하자. userID열은 기본 키로 지정되어 있으므로, 같은 ID를 입력할 수 없으므로 오류가 발생할 것이다.
DROP PROCEDURE IF EXISTS errorProc2;
DELIMITER $$
CREATE PROCEDURE errorProc2()
BEGIN
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION
BEGIN
SHOW ERRORS;
SELECT '오류가 발생했네요. 작업은 취소시켰습니다.' AS 'message';
ROLLBACK ;
END;
INSERT INTO userTBL
VALUES ('LSG', '이상구', 1988, '서울', NULL, NULL, 170, CURRENT_DATE());
END $$
DELIMITER ;
CALL errorProc2();

SHOW ERRORS문은오류에 대한 코드와 메시지를 출력한다. ROLLBACK은 진행중인 작업을 취소시키며, COMMIT은 작업을 완전히 확정시키는 구문이다.
SHOW COUNT(*) ERRORS문은 발생된 오류의 개수를 출력해 주며, SHOW WARNINGS문은 경고에 대한 코드와 메시지를 출력한다.
동적 SQL
이전에 잠깐 살펴본 PREPARE와 EXECUTE문을 다시 확인해 보자. PREPARE는 SQL문을 실행하지는 않고 미리 준비만 해놓고, EXECUTE문은 준비한 쿼리문을 실행한다. 그리고 실행후에는 DEALLOCATE PREPARE로 문장을 해제해 주는 것이 바람직하다.
PREPARE myQuery
FROM
'SELECT *
FROM userTBL
WHERE userID = "EJW"';
EXECUTE myQuery;
DEALLOCATE PREPARE myQuery;
즉, SELECT * FROM usertbl WHERE userID = "EJW" 문장을 바로 실행하지 않고, myQuery에 입력시켜 놓는다. 그리고 EXECUTE문으로 실행할 수 있다.
이렇게 미리 쿼리문을 준비한 후에 나중에 실행하는 것을 '동적 SQL'이라고도 부른다.
또한, PREPARE문에서 ?으로 향후에 입력될 값을 비워놓고, EXECUTE에서는 USING을 이용해서 값을 전달해서 사용할 수 있다. 다음은 쿼리를 실행하는 순간의 날짜와 시간이 입력되는 기능을 한다.
DROP TABLE IF EXISTS myTable;
CREATE TABLE myTable(
id int AUTO_INCREMENT PRIMARY KEY,
mDate datetime
);
SET @curDATE = CURRENT_TIMESTAMP();
PREPARE myQuery FROM 'INSERT INTO myTable VALUES (NULL, ?)';
EXECUTE myQuery USING @curDate;
DEALLOCATE PREPARE myQuery;
SELECT * FROM myTable ;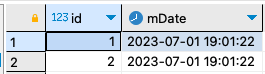
자체평가 - 학습 흐름을 잘 이해하고 있는가?
MySQL 데이터 형식
변수의 할용
MySQL 내장 함수
테이블 조인
SQL 프로그래밍
