
chapter 7의 핵심 개념
- 테이블은 Workbench의 그래픽 환경 및 SQL문을 사용한 텍스트 환경 모두에서 생성할 수 있다.
- 제약 조건(Constraint)이란 데이터의 무결성을 지키기 위한 제한된 조건을 의미한다.
- 제약 조건의 종류로는 기본 키, 외래 키, Unique, Default, Null 제약 조건 등이 있다.
- MySQL은 테이블 압축, 임시 테이블 기능을 지원한다.
- 뷰란 한마디로 '가상의 테이블'이라고 생각하면 된다.
chapter 7의 학습 흐름
- 테이블 생성
- 제약 조건: 기본 키, 왜리 키 등
- 테이블 압축과 효율성 및 임시 테이블의 활용
- 뷰의 개념과 장단점
테이블
테이블 만들기
SQL로 테이블 생성

MySQL은 5.0부터 테이블의 압축 기능이 제공된다. 대용량의 데이터가 들어간 테이블의 저장공간을 대폭 절약할 수 있다. 테이블 압축을 위해서는 CREATE TABLE 테이블이름 (열 정의 ···) ROW_FORMAT=COMPRESSED 형식을 사용하면 된다. 테이블 압축한다고 사용법이 특별히 달라지는 것은 없으며, 기존과 동일하게 사용하면 내부적으로 알아서 압축이 되는 것이다.
너무 복잡해 보이지만, 다양한 옵션이 모두 표현되어서 그렇지, 실제로 사용되는 것은 그렇게 복잡하지 않다.
CREATE TABLE test (num INT);실습: SQL을 이용해서 테이블을 생성하자.
step 0: tabledb를 삭제하고 다시 생성하자.DROP DATABASE tabledb; CREATE DATABASE tabledb;
step 1: 기본 키, 외래 키, NULL 값 등을 고려하지 말고 테이블의 기본적인 틀만 구성하자.
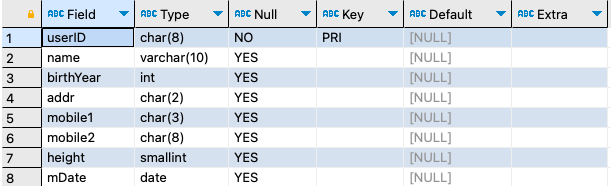
DROP TABLE IF EXISTS buytbl, usertbl; CREATE TABLE usertbl ( userID char(8) comment '사용자 아이디', name varchar(10) comment '이름', birthYear int comment '출생년도', addr char(2) comment '지역 : 경기, 서울, 경남 등으로 글자만 입력', mobile1 char(3) comment '휴대폰의 국번(010, 011, 016 등)', mobile2 char(8) comment '휴대폰의 나머지 전화번호(하이픈 제외)', height SMALLINT comment '키', mData date comment '회원 가입일' ); CREATE TABLE buytbl ( num int , userid char(8) , prodName char(6) , groupName char(4) , price int , amount SMALLINT );
step 2: 추가적인 옵션을 줘서 다시 생성하자.
step 2-1: NULL 및 NOT NULL을 지정해서 테이블을 다시 생성한다.DROP TABLE IF EXISTS buytbl, usertbl; CREATE TABLE usertbl ( userID char(8) NOT NULL comment '사용자 아이디', name varchar(10) NOT NULL comment '이름', birthYear int NOT NULL comment '출생년도', addr char(2) NOT NULL comment '지역 : 경기, 서울, 경남 등으로 글자만 입력', mobile1 char(3) NULL comment '휴대폰의 국번(010, 011, 016 등)', mobile2 char(8) NULL comment '휴대폰의 나머지 전화번호(하이픈 제외)', height SMALLINT NULL comment '키', mData date NULL comment '회원 가입일' ); CREATE TABLE buytbl ( num int NOT NULL, userid char(8) NOT NULL, prodName char(6) NOT NULL, groupName char(4) NULL, price int NOT NULL, amount SMALLINT NOT NULL );
step 2-2: 각 테이블에 기본 키를 설정해 보자.
DROP TABLE IF EXISTS buytbl, usertbl; CREATE TABLE usertbl ( userID char(8) NOT NULL PRIMARY KEY comment '사용자 아이디', name varchar(10) NOT NULL comment '이름', birthYear int NOT NULL comment '출생년도', addr char(2) NOT NULL comment '지역 : 경기, 서울, 경남 등으로 글자만 입력', mobile1 char(3) NULL comment '휴대폰의 국번(010, 011, 016 등)', mobile2 char(8) NULL comment '휴대폰의 나머지 전화번호(하이픈 제외)', height SMALLINT NULL comment '키', mData date NULL comment '회원 가입일' ); CREATE TABLE buytbl ( num int NOT NULL PRIMARY KEY , userid char(8) NOT NULL, prodName char(6) NOT NULL, groupName char(4) NULL, price int NOT NULL, amount SMALLINT NOT NULL );
step 2-3: buytbl의 순번(num)열에 AUTO_INCREMENT를 설정한다. 주의 할 점은 AUTO_INCREMENT로 지정한 열은 PRIMARY KEY나 UNIQUE로 반드시 지정해줘야 한다.
DROP TABLE IF EXISTS buytbl, usertbl; CREATE TABLE usertbl ( userID char(8) NOT NULL PRIMARY KEY comment '사용자 아이디', name varchar(10) NOT NULL comment '이름', birthYear int NOT NULL comment '출생년도', addr char(2) NOT NULL comment '지역 : 경기, 서울, 경남 등으로 글자만 입력', mobile1 char(3) NULL comment '휴대폰의 국번(010, 011, 016 등)', mobile2 char(8) NULL comment '휴대폰의 나머지 전화번호(하이픈 제외)', height SMALLINT NULL comment '키', mData date NULL comment '회원 가입일' ); CREATE TABLE buytbl ( num int NOT NULL PRIMARY KEY AUTO_INCREMENT , userid char(8) NOT NULL, prodName char(6) NOT NULL, groupName char(4) NULL, price int NOT NULL, amount SMALLINT NOT NULL );
step 2-4: 구매 테이블의 아이디 열을 회원 테이블의 아이디 열의 외래 키로 설정해 보자.
DROP TABLE IF EXISTS buytbl, usertbl; CREATE TABLE usertbl ( userID char(8) NOT NULL PRIMARY KEY comment '사용자 아이디', name varchar(10) NOT NULL comment '이름', birthYear int NOT NULL comment '출생년도', addr char(2) NOT NULL comment '지역 : 경기, 서울, 경남 등으로 글자만 입력', mobile1 char(3) NULL comment '휴대폰의 국번(010, 011, 016 등)', mobile2 char(8) NULL comment '휴대폰의 나머지 전화번호(하이픈 제외)', height SMALLINT NULL comment '키', mData date NULL comment '회원 가입일' ); CREATE TABLE buytbl ( num int NOT NULL PRIMARY KEY AUTO_INCREMENT , userid char(8) NOT NULL, prodName char(6) NOT NULL, groupName char(4) NULL, price int NOT NULL, amount SMALLINT NOT NULL , FOREIGN KEY (userid) REFERENCES usertbl(userID) );
step 3: 데이터를 몇 건씩 입력하자.
step 3-1: 회원 테이블에 3건만 입력하자.INSERT INTO usertbl VALUES ('LSG', '이승기', 1987, '서울', '011', '1111111', 182, '2008-8-8'), ('KBS', '김범수', 1979, '경남', '011', '2222222', 173, '2012-4-4'), ('KKH', '김경호', 1971, '전남', '019', '3333333', 177, '2007-7-7');
step 3-2: 구매 테이블의 3건을 입력하자.
INSERT IGNORE INTO buytbl VALUES (NULL, 'KBS', '운동화', NULL, 30, 2), (NULL, 'KBS', '노트북', '전자', 1000, 1), (NULL, 'JYP', '모니터', '전자', 200, 1);
두 개의 행은 잘 들어가고 세 번째 JYP(조용필)는 아직 회원 테이블에 존재하지 않아서 오류가 발생했다.
step 3-3: usertbl에 나머지 데이터를 먼저 입력한 후, 구매 테이블의 3번째 데이터부터 다시 입력하자.
INSERT INTO usertbl VALUES ('JYP', '조용필', 1950, '경기', '011', '4444444', 166, '2009-4-4'); INSERT IGNORE INTO buytbl VALUES (NULL, 'JYP', '모니터', '전자', 200, 1); SELECT * FROM buytbl ;
제약 조건
제약 조건(Constraint)이란 데이터의 무결성을 지키기 위한 제한된 조건을 의미한다. 즉, 특정 데이터를 입력할 때 무조건적으로 입력되는 것이 아닌, 어떠한 조건을 만족했을 때에 입력되도록 제약할 수 있다.
MySQL은 데이터의 무결성을 위해서 다음의 5가지의 제약 조건을 제공한다.
- PRIMARY KEY 제약 조건
- FOREIGN KEY 제약 조건
- UNIQUE 제약 조건
- CHECK 제약 조건
- DEFAULT 정의
- NULL 값 허용
CHECK 제약 조건은 MySQL 8.0.16부터 정식으로 지원한다.
기본 키 제약 조건
테이블에 존재하는 많은 행의 데이터를 구분할 수 있는 식별자를 '기본 키(Primary Key)'라고 부른다.
기본 키에 입력되는 값은 중복될 수 없으며 NULL 값이 입력될 수 없다.
기본 키로 생성한 것은 자동으로 클러스터형 인덱스가 생성된다. 또한, 테이블에서는 기본 키를 하나 이상의 열에 설정할 수 있다.
UNIQUE 제약 조건도 데이터를 구분하긴 하지만 NULL값을 허용하고 DEFAULT에 의해서 같은 값을 가질 수 있다.
MySQL의 PRIMARY Key 이름
MySQL은 Primary Key로 지정하면서 항상 키 이름을 'PRIMARY'로 보여준다. 그러므로 지금과 같이 이름을 Primary Key의 이름을 직접 지정하는 것이 별 의미는 없다. 하지만, Foreign Key는 하나의 테이블에 여러 개가 생성될 수 있으므로 이름을 지정해서 관리하는 것이 편리하다. 참고로 테이블에 지정된 키를 보려면 SHOW KEYS FROM 테이블이름; 구문을 사용하면 된다.
제약 조건을 설정하는 또 다른 방법은 이미 만들어진 테이블을 수정하는 ALTER TABLE 구문을 사용하는 것이다.
ALTER TABLE usertbl
ADD CONSTRAINT PK_usertlb_userID
PRIMARY KEY (userID);기본 키는 각 테이블 별로 하나만 존재해야 하지만, 기본 키를 하나의 열로만 구성해야 하는 것은 아니다. 필요에 따라서 두 개 또는 그 이상의 열을 합쳐서 하나의 기본 키로 설정하는 경우도 종종있다.
예로 다음과 같은 간단한 '제품 테이블'을 생각해 보자.
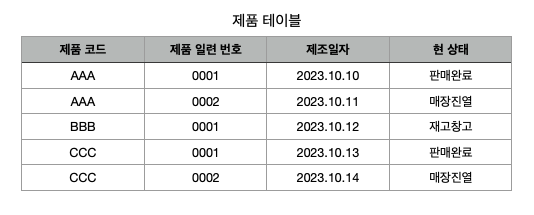
만약 제품코드 AAA가 냉장고, BBB가 세탁기, CCC가 TV라고 가정한다면 현재 제품코드만으로는 중복이 될 수밖에 없으므로, 기본 키로 설정할 수가 없다. 또한, 제품 일련 번호도 마찬가지로 각 제품 별로 0001번부터 부여하는 체계라서 기본 키로 설정할 수 없다.
이러한 경우에는 '제품코드 + 제품일련번호'를 합친다면 유일한 값이 될 수 있으므로 기본 키로 사용할 수 있다.
CREATE TABLE prodtbl(
prodCode char(3) NOT NULL,
prodID char(4) NOT NULL,
prodDate datetime NOT NULL,
prodCur char(10) NULL ,
CONSTRAINT PRIMARY KEY PK_prodtbl_prodCode_prodID(prodCode, prodID)
) ;
또는
CREATE TABLE prodtbl(
prodCode char(3) NOT NULL,
prodID char(4) NOT NULL,
prodDate datetime NOT NULL,
prodCur char(10) NULL
) ;
ALTER TABLE prodtbl
ADD CONSTRAINT PK_prodtbl_prodCode_prodID
PRIMARY KEY (prodCode, prodID);SHOW INDEX FROM prodtbl ;문으로 테이블의 정보를 확인하면 두 열이 합쳐져서 하나의 기본 키 제약 조건을 설정하고 있음이 확인된다.

외래 키 제약 조건
외래 키(Foreign Key) 제약 조건은 두 테이블 사이의 관계를 선언함으로써 데이터의 무결성을 보장해 주는 역할을 한다. 외래 키 관계를 설정하면 하나의 테이블이 다른 테이블에 의존하게 된다.
외래 키를 정의하는 테이블을 '외래 키 테이블'이라고 부르고, 외래 키에 의해서 참조가 되는 테이블을 '기준 테이블'이라고 부르면 좀 더 직관적으로 이해하기가 쉬워진다.
외래 키 테이블에 데이터를 입력할 때는 꼭 기준 테이블을 참조해서 입력하므로 기준 테이블에 이미 데이터가 존재해야 한다. 앞의 실습에서 buytbl에 JYP(조용필)가 입력이 안되던 것을 확인했다. 이것은 외래 키 제약 조건을 위반했기 때문이다.
또, 외래 키 테이블이 참조하는 기준 테이블의 열은 반드시 Primary Key이거나 Unique 제약 조건이 설정되어 있어야 한다.
외래 키를 생성하는 방법은 CREATE TABLE 끝에 FOREIGN KEY 키워드로 설정하는 방법이 있다.
CREATE TABLE buytbl (
num int NOT NULL PRIMARY KEY AUTO_INCREMENT ,
userid char(8) NOT NULL ,
prodName char(6) NOT NULL ,
FOREIGN KEY fk_usertbl_buytbl(userid) REFERENCES usertbl(userID)
);만약, 기준 테이블이 Primary Key 또는 Unique가 아니라면 외래 키 관계는 설정되지 않는다.
UNIQUE 제약 조건
UNIQUE 제약 조건은 '중복되지 않는 유일한 값'을 입력해야 하는 조건이다. 이것은 PRIMARY KEY와 거의 비슷하며 차이점은 UNIQUE는 NULL 값을 허용한다는 점이다.
CREATE TABLE usertbl (
userID char(8) NOT NULL PRIMARY KEY comment '사용자 아이디',
name varchar(10) NOT NULL comment '이름',
birthYear int NOT NULL comment '출생년도',
email char(30) NULL UNIQUE comment '이메일'
);
또는
CREATE TABLE usertbl (
userID char(8) NOT NULL PRIMARY KEY comment '사용자 아이디',
name varchar(10) NOT NULL comment '이름',
birthYear int NOT NULL comment '출생년도',
email char(30) NULL comment '이메일',
CONSTRAINT AK_email UNIQUE (email)
);제약 조건의 이름을 지정할 때 일반적으로 Primary Key는 PK, Foreign Key는 FK, Unique는 AK를 주로 사용한다. 참고로 Unique는 Altermate Key로도 부른다.
CHECK 제약 조건
CHECK 제약 조건은 입력되는 데이터를 점검하는 기능을 한다. 키(height)에 마이너스 값이 들어올 수 없게 한다든지, 출생년도가 1900년 이후이고 현재 시점 이전이어야 한다든지 등의 조건을 지정한다.
DROP TABLE IF EXISTS usertbl ;
CREATE TABLE usertbl (
userID char(8) PRIMARY KEY,
name varchar(10),
birthYear int CHECK (birthYear >= 1900 AND birthYear <= 2023),
mobile1 char(3) NULL,
CONSTRAINT CK_name CHECK (name IS NOT NULL)
);필요하다면 열을 정의한 후에 ALTER TABLE문으로 제약 조건을 추가해도 된다.
ALTER TABLE usertbl
ADD CONSTRAINT CK_mobile1
CHECK (mobile1 IN ('010'));CHECK 제약 조건을 설정한 후에는, 제약 조건에 위배되는 값은 입력이 안 된다. CHECK에서 사용할 수 있는 조건은 SELECT문의 WHERE 구문에 들어오는 조건과 거의 비슷한 것이 들어오면 된다.
CHECK 제약 조건을 만들되 작동하지 않도록 하려면 제약 조건의 제일 뒤에 NOT ENFORCED구문을 추가하면 되지만, 거의 사용할 일은 없다.
DEFAULT 정의
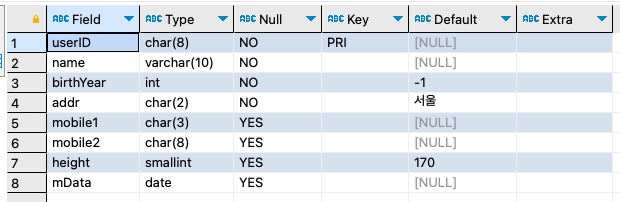
DEFAULT는 값을 입력하지 않았을 때, 자동으로 입력되는 기본 값을 정의하는 방법이다.
예로, 출생년도를 입력하지 않으면 -1을 입력하고, 주소를 특별히 입력하지 않았다면 '서울'이 입력 되며, 키를 입력하지 않으면 170이라고 입력되도록 하고 싶다면 다음과 같이 정의할 수 있다.
DROP TABLE IF EXISTS usertbl;
CREATE TABLE usertbl (
userID char(8) NOT NULL PRIMARY KEY comment '사용자 아이디',
name varchar(10) NOT NULL comment '이름',
birthYear int NOT NULL DEFAULT -1 comment '출생년도',
addr char(2) NOT NULL DEFAULT '서울' comment '지역 : 경기, 서울, 경남 등으로 글자만 입력',
mobile1 char(3) NULL comment '휴대폰의 국번(010, 011, 016 등)',
mobile2 char(8) NULL comment '휴대폰의 나머지 전화번호(하이픈 제외)',
height SMALLINT NULL DEFAULT 170 comment '키',
mData date NULL comment '회원 가입일'
);
또는 ALTER TABLE 사용 시에 열에 DEFAULT를 지정하기 위해서 ALTER COLUMN문을 사용한다.
CREATE TABLE usertbl (
userID char(8) NOT NULL PRIMARY KEY comment '사용자 아이디',
name varchar(10) NOT NULL comment '이름',
birthYear int NOT NULL comment '출생년도',
addr char(2) NOT NULL comment '지역 : 경기, 서울, 경남 등으로 글자만 입력',
mobile1 char(3) NULL comment '휴대폰의 국번(010, 011, 016 등)',
mobile2 char(8) NULL comment '휴대폰의 나머지 전화번호(하이픈 제외)',
height SMALLINT NULL comment '키',
mData date NULL comment '회원 가입일'
);
ALTER TABLE usertbl
ALTER COLUMN birthYear SET DEFAULT -1,
ALTER COLUMN addr SET DEFAULT '서울',
ALTER COLUMN height SET DEFAULT 170;
디폴트가 설정된 열에는 다음과 같은 방법으로 데이터를 입력할 수 있다.
-- default문은 DEFAULT로 설정된 값을 자동 입력한다.
INSERT INTO usertbl
VALUES ('LHL', '이해리', DEFAULT, DEFAULT, '010', '1234567', DEFAULT, '2023.12.12');
-- 열 이름이 명시되지 않으면 DEFAULT로 설정된 값을 자동 입력한다.
INSERT INTO usertbl(userID, name)
VALUES ('KAY', '김아영');
-- 값이 지접 명기되면 DEFAULT로 설정된 값은 무시된다.
INSERT INTO usertbl
VALUES ('WB', '원빈', 1982, '대전', '010', '9876543', 176, '2020.5.5');
Null 값 허용
NULL 값을 허용하려면 NULL을, 허용하지 않으려면 NOT NULL을 사용하면 된다.
NULL 값은 '아무 것도 없다'라는 의미다. 즉, 공백(' ')이나 0과 같은 값과는 다르다는 점에 주의해야 한다.
Null 저장 시에 고정 길이 문자형(CHAR)은 공간을 모두 차지하지만, 가변 길이 문자형(VARCHAR)은 공간을 차지하지 않는다. 그러므로, Null 값을 많이 입력한다면 가변 길이의 데이터 형식을 사용하는 것이 좋다.
테이블 압축
테이블 압축 기능은 대용량 테이블의 공간을 절약하는 효과를 갖는다. MySQL 5.0부터 테이블 압축 기능을 제공하기 시작했으며, MySQL 8.0에서는 내부적인 기능이 더욱 강화되어 MySQL이 허용하는 최대 용량의 데이터도 오류없이 압축이 잘 작동한다.
실습: 테이블 압축 기능을 확인해 보자.
step 1: 테스트용 DB를 생성한 후에 동일한 열을 지닌 간단한 두 테이블을 생성한다. 단, 하나는 열 뒤에 ROW_FORMAT=COMPRESSED문을 붙여서 압축되도록 설정한다.CREATE TABLE normaltbl( emp_no int, first_name varchar(14) ); CREATE TABLE compresstbl( emp_no int, first_name varchar(14) )ROW_FORMAT=COMPRESSED ;
step 2: 두 테이블에 데이터를 30만 건 정도 입력한다. employees.DB의 employees 테이블의 데이터를 가져오자.
INSERT INTO normaltbl SELECT emp_no, first_name FROM employees.employees; INSERT INTO compresstbl SELECT emp_no, first_name FROM employees.employees;
첫 번째 쿼리와 두 번째 쿼리가 실행되는데 걸린 시간을 확인하면 두 번째인 압축된 테이블에 데이터를 입력할 때 더 시간이 오래 걸린 것을 확인할 수 있다. 압축되면서 데이터가 입력되기 때문에 조금 더 시간이 걸린 것으로 예상할 수 있다.
step 3: 입력된 두 테이블의 상태를 확인해 보자.
SHOW TABLE status FROM compressdb;
압축된 테이블의 평균 행 길이(Avg_row_length)나 데이터 길이(Data_length)가 훨씬 작은 것을 확인할 수 있다. 물론, 데이터의 값의 분포에 따라서 이 압축률은 달라질 수 있으나 원래의 데이터보다 작아지는 것은 확실하다.
step 4: 실습한 DB를 제거한다.
DROP DATABASE IF EXISTS compressDB;


디스크 공간의 여유가 별로 없으며 대용량의 데이터를 저장하는 테이블이라면 지금 사용한 테이블 압축을 고려하는 것도 좋은 방법이다. 압축 기능은 테이블을 생성할 때만 지정하면 그 이후로는 압축하지 않은 테이블과 사용법이 완전히 동일하다. 그러므로 테이블 생성 이후에는 별도로 신경쓰지 않아도 된다.
임시 테이블
임시 테이블은 이름처럼 임시로 잠깐 사용되는 테이블이다.
형식:
CREATE TEMPORARY TABLE [IF NOT EXISTS] 테이블이름
( 열 정의 ··· )구문 중에서 TABLE 위치에 TEMPORARY TABLE이라고 써주는 것 외에는 테이블과 정의하는 것이 동일하다. 결국 임시 테이블은 정의하는 구문만 약간 다를 뿐, 나머지 사용법 등은 일반 테이블과 동일하게 사용할 수 있다. 단, 임시 테이블은 세션(Session) 내에서만 존재하며, 세션이 닫히면 자동으로 삭제된다. 또한 임시 테이블은 생성한 클라이언트에서만 접근이 가능하며, 다른 클라이언트는 접근할 수 없다.
임시 테이블은 데이터베이스 내의 다른 테이블과 이름은 동일하게 만들 수 있다. 그러면 기존의 테이블은 임시 테이블이 있는 동안에 접근이 불가능하고, 무조건 임시 테이블로 접근할 수 있다.
기존 테이블과 임시 테이블의 이름이 같으면 혼란스러울 수 있으므로, 가능하면 임시 테이블은 기존 테이블의 이름을 사용하지 않는 것이 좋다.
임시 테이블이 삭제되는 시점은 다음과 같다.
- 사용자가 DROP TABLE로 직접 삭제
- Workbench를 종료하거나 mysql 클라이언트를 종료하면 삭제됨
- MySQL 서비스가 재시작되면 삭제됨
실습: 임시 테이블을 사용하자.
step 1: 임시 테이블을 사용해 보자.
step 1-1: 임시 테이블 2개를 생성하자. 두 번째는 기존의 employees 테이블과 동일한 이름으로 생성해 보자.
CREATE TEMPORARY TABLE IF NOT EXISTS temptbl ( id int, name char(5) ); CREATE TEMPORARY TABLE IF NOT EXISTS employees ( id int, name char(5) );
새로운 임시 테이블 이름 temptbl은 당연히 생성되고, 기존의 테이블 employees가 있더라도 무시하고 임시 테이블 employees(임시 테이블)가 생성되었다.
step 1-2: 데이터를 입력하고 확인해 보자.
INSERT INTO temptbl VALUES (1, 'This'); INSERT INTO employees VALUES (2, 'MySQL'); SELECT * FROM temptbl ; SELECT * FROM employees ;

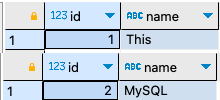
테이블 삭제
형식:
DROP TABLE 테이블이름;단, 주의할 사항은 외래 키(FOREIGN KEY) 제약 조건의 기준 테이블은 삭제할 수가 없다. 먼저, 외래 키가 생성된 외래 키 테이블을 삭제해야 한다.
또, 여러 개의 테이블을 동시에 삭제하려면 DROP TABLE 테이블1, 테이블2, 테이블3; 식으로 계속 나열하면 된다.
테이블 수정
테이블의 수정은 ALTER TABLE문을 사용한다.
이미 생성된 테이블에 무엇인가를 추가/변경/수정/삭제하는 것은 모두 ALTER TABLE을 사용한다.
[
구문이 상당히 길고 복잡하다. 하지만, 실제로 많이 사용되는 것들은 그리 복잡하지 않다.
열의 추가
회원 테이블(usertbl)에 회원의 홈페이지 주소를 추가하려면 다음과 같이 사용한다.
ALTER TABLE userTBL
ADD COLUMN homepage varchar(30) DEFAULT 'http://www.hanbit.co.kr' NULL
AFTER addr;
열을 추가하면서 순서를 지정하려면 제일 뒤에 'FIRST' 또는 'AFTER 열 이름'을 지정하면 된다. FIRST는 제일 앞에 열이 추가되며, AFTER 열 이름은 열 이름 다음에 추가한다. 그리고 아무것도 적지 않으면 가장 뒤에 추가된다.
열의 삭제
전화번호 열을 삭제하려면 다음과 같이 사용한다.
ALTER TABLE userTBL
DROP COLUMN mobile1;그런데, mobile1열은 특별한 제약 조건이 없기 때문에 삭제에 별 문제가 없지만, 제약 조건이 걸린 열을 삭제할 경우에는 제약 조건을 먼저 삭제한 후에 열을 삭제해야 한다.
열의 이름 및 데이터 형식 변경
회원 이름(name)의 열 이름을 uName으로 변경하고 데이터 형식을 VARCHAR(20)으로 변경하고, NULL 값도 허용하려면 다음과 같이 사용한다.
ALTER TABLE userTBL
CHANGE COLUMN name uName varchar(20) NULL ;name은 기존 이름, uName은 새 이름이다. 그런데 마찬가지로 제약 조건이 걸려있는 열은 좀 문제가 있다.
열의 제약 조건 추가 및 삭제
열의 제약 조건을 추가하는 것은 앞에서 여러 번 확인했다. 제약 조건을 삭제하는 것도 간단하다. 기본 키를 삭제하려면 다음과 같이 한다.
ALTER TABLE userTBL
DROP PRIMARY KEY;현재 userTBL의 기본 키인 userID열은 buyTBL에 외래 키로 연결되어 있기 때문에 먼저 다음과 같이 외래 키를 제거한 후에 다시 기본 키를 제거해야 한다.
ALTER TABLE buyTBL
DROP FOREIGN KEY fk_userTBL_buyTBL ;SHOW [ KEYS | INDEX ] FROM 테이블이름으로 외래 키의 이름을 알아낸다.
실습: 지금까지 익힌 테이블의 제약 조건 및 수정 방법을 실습을 통해서 익히자.
step 1: 조건을 제외하고 테이블을 다시 만들자. 단, 구매 테이블(buytbl)의 num열만 AUTO_INCREMENT 및 PRIMARY KEY 속성을 주도록 하자.
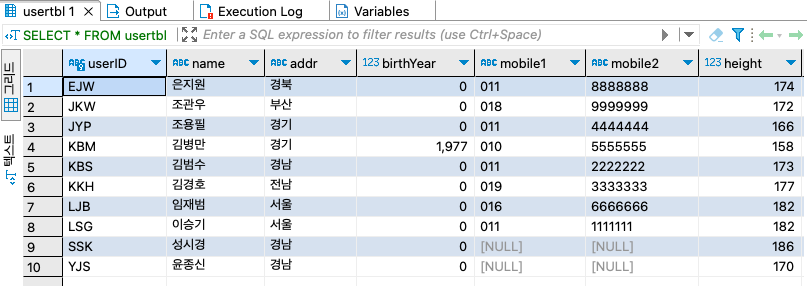
DROP TABLE IF EXISTS userTbl, buyTBL ; CREATE TABLE usertbl( userID char(8), name varchar(10), birthYear int, addr char(2), mobile1 char(3), mobile2 char(8), height SMALLINT, mDate date ); CREATE TABLE buytbl( num int AUTO_INCREMENT PRIMARY KEY, userid char(8), prodName char(6), groupName char(4), price int, amount SMALLINT );
step 2: 먼저 각각의 테이블에 데이터를 테이블당 4건씩만 입력하자. 입력 시에 김범수의 출생년도는 모르는 것으로 NULL 값을 넣고, 김경호의 출생년도는 1871년으로 잘못 입력해 보자.
INSERT INTO usertbl VALUES ('LSG', '이승기', 1987, '서울', '011', '1111111', 182, '2008-8-8'), ('KBS', '김범수', NULL, '경남', '011', '2222222', 173, '2012-4-4'), ('KKH', '김경호', 1871, '전남', '019', '3333333', 177, '2007-7-7'), ('JYP', '조용필', 1950, '경기', '011', '4444444', 166, '2009-4-4'); INSERT INTO buytbl VALUES (NULL, 'KBS', '운동화', NULL, 30, 2), (NULL, 'KBS', '노트북', '전자', 1000, 1), (NULL, 'JYP', '모니터', '전자', 200, 1), (NULL, 'BBK', '모니터', '전자', 200, 5);
아직 FOREIGN KEY 제약 조건이 설정된 것이 아니므로, usertbl에 BBK(바비킴) 회원이 없지만, 입력은 잘 되었다.
step 3: 제약 조건을 생성하자.
step 3-1: 기본 키 제약 조건을 생성하자.ALTER TABLE usertbl ADD CONSTRAINT PRIMARY KEY (userID);step 3-2: DESC usertbl문으로 테이블을 확인해보자. userID열이 NOT NULL로 설정된 것을 확인할 수 있다.
step 4: 외래 키를 설정해 보자.
step 4-1: 외래 키 테이블 buytbl의 userid에 외래 키를 설정하자. 기준 테이블 usertbl의 userID를 기준으로 한다.ALTER TABLE buytbl ADD CONSTRAINT FK_usertbl_buytbl FOREIGN KEY (userid) REFERENCES usertbl (userID);
오류가 발생했다. 그 이유는 buytbl에는 BBK(바비킴)의 구매 기록이 있는데, 이 BBK 아이디가 usertbl에는 존재하지 않기 때문이다.
step 4-2: 문제가 되는 buytbl의 BBK행을 삭제하고, 다시 외래 키를 설정하자.
DELETE FROM buytbl WHERE userid = 'BBK'; ALTER TABLE buytbl ADD CONSTRAINT FK_usertbl_buytbl FOREIGN KEY (userid) REFERENCES usertbl (userID);
step 4-3: buytbl의 네 번째 데이터를 다시 입력해 보자.
INSERT INTO buytblVALUES (NULL, 'BBK', '모니터', '전자', 200, 5);
외래 키가 연결되어 활성화된 상태이므로 새로 입력하는 데이터는 모두 외래 키 제약 조건을 만족해야 한다. BBK가 아직 usertbl에 없기 때문에 나오는 오류다.
물론, 여기서도 usertbl에 BBK를 입력한 후에 다시 buytbl에 입력해도 되지만 어떤 경우에는 대량의 buytbl을 먼저 모두 입력해야 하는 경우도 있을 것이다. 그 건수는 수백만 건 이상의 대용량일 수도 있다.
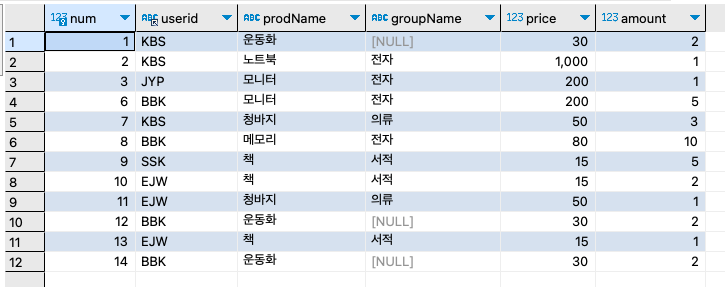
이럴 때는 buytbl에 데이터를 입력하는 동안에 잠시 외래 키 제약 조건을 비활성화 시키고, 데이터를 모두 입력한 후에 다시 외래 키 제약 조건을 활성화 시키면 된다.SET foreign_key_checks = 0; INSERT INTO buytbl VALUES (NULL, 'BBK', '모니터', '전자', 200, 5), (NULL, 'KBS', '청바지', '의류', 50, 3), (NULL, 'BBK', '메모리', '전자', 80, 10), (NULL, 'SSK', '책', '서적', 15, 5), (NULL, 'EJW', '책', '서적', 15, 2), (NULL, 'EJW', '청바지', '의류', 50, 1), (NULL, 'BBK', '운동화', NULL, 30, 2), (NULL, 'EJW', '책', '서적', 15, 1), (NULL, 'BBK', '운동화', NULL, 30, 2); SET foreign_key_checks = 1;
시스템 변수인 foreign_key_checks는 외래 키 체크 여부를 설정하는데 기본 값은 1(On)이다. 이를 0(Off)으로 잠시 변경한 후 입력하는 방법을 사용했다.
step 5: 이번에는 CHECK 제약 조건을 설정하자.
step 5-1: usertbl의 출생년도를 1900~2023까지만 입력되도록 하자. 또, NULL 값을 허용하지 말고 출생년도는 반드시 입력하도록 설정하자.ALTER TABLE usertbl ADD CONSTRAINT CK_birthYear CHECK ((birthYear >= 1900 AND birthYear <= 2023) AND (birthYear IS NOT NULL) );
MySQL 8.0.15까지는 CHECK 제약 조건이 형식만 제공할 뿐 실제로 작동하지 않았다. 즉 위 구분은 오류없이 잘 수행되었다. MySQL 8.0.16 이후부터 오류가 발생한다.
오류가 발생했다. 김범수(KBS)의 출생년도는 모르는 것으로 NULL 값을 넣고, 김경호(KKH)의 출생년도를 1871년으로 잘못 입력했었다.
step 5-2: 출생년도를 김범수는 1979년으로, 김경호는 1971년으로 수정하자.
UPDATE usertbl SET birthYear = 1979 WHERE userID = 'KBS'; UPDATE usertbl SET birthYear = 1971 WHERE userID = 'KKH';
step 5-3: CHECK 제약 조건을 다시 설정하자.
ALTER TABLE usertbl ADD CONSTRAINT CK_birthYear CHECK ((birthYear >= 1900 AND birthYear <= 2023) AND (birthYear IS NOT NULL) );
step 5-4: 출생년도가 잘못된 값을 입력해보자. 오류가 발생하고 입력되지 않을 것이다.
INSERT INTO usertbl VALUES ('TKV', '태권뷔', 2999, '우주', NULL, NULL, 186, '2023-12-12' );
step 6:usertbl의 정삭적인 데이터를 입력하자.
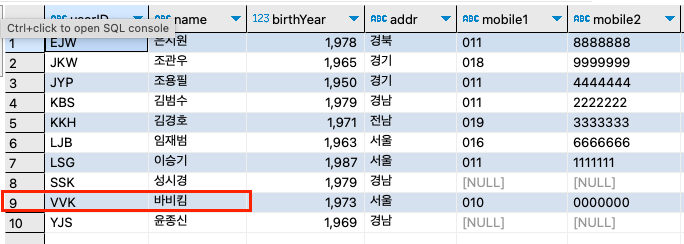
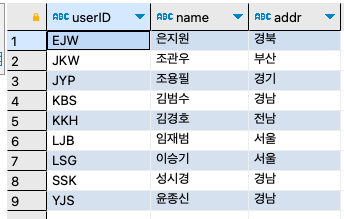
INSERT INTO usertbl VALUES ('SSK', '성시경', 1979, '경남', NULL, NULL, 186, '2013-12-12'), ('LJB', '임재범', 1963, '서울', '016', '6666666', 182, '2009-9-9'), ('YJS', '윤종신', 1969, '경남', NULL, NULL, 170, '2005-5-5'), ('EJW', '은지원', 1978, '경북', '011', '8888888', 174, '2014-3-3'), ('JKW', '조관우', 1965, '경기', '018', '9999999', 172, '2010-10-10'), ('BBK', '바비킴', 1973, '서울', '010', '0000000', 176, '2013-5-5');
step 7: 이제부터는 정상적으로 운영하면 된다.
step 8: 바비킴 회원이 자신의 ID를 변경해달라고 한다. 즉, BBK가 아니라 VVK로 변경하는 경우다.
step 8-1: UPDATE문으로 변경해 보자.UPDATE usertbl SET userID = 'VVK' WHERE userID = 'BBK';
외래 키와 관련된 오류가 발생했다. BBK는 이미 buytbl에서 구매한 기록이 있으므로 바뀌지 않는 것이다. 앞에서 나왔듯이 잠깐 제약 조건을 비활성화한 후에, 데이터를 변경하고 다시 활성화 시켜 보자.
step 8-2: 시스템 변수인 foreign_key_checks를 활용해 보자.
SET foreign_key_checks = 0; UPDATE usertbl SET userID = 'VVK' WHERE userID = 'BBK'; SET foreign_key_checks = 1;
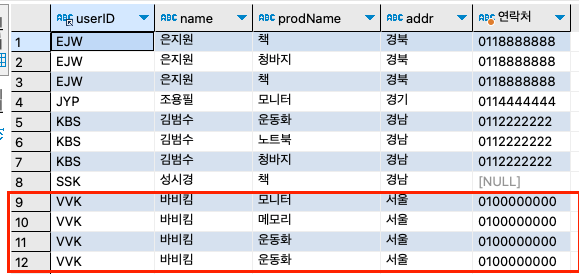
step 8-3: 구매 테이블(buytbl)의 사용자에게 물품 배송을 위해서, 회원 테이블과 조인시켜 보자. 즉, 구매한 회원 아이디, 회원 이름, 구매한 제품, 주소, 연락처가 출력되게 하자.
SELECT u.userID, u.name, b.prodName, u.addr, CONCAT(u.mobile1, u.mobile2) AS '연락처' FROM buytbl b INNER JOIN usertbl u ON u.userID = b.userid;구매한 개수가 12건인데 8건밖에 나오지가 않았다. 4건은 어디 갔을까?
step 8-4: 구매 테이블에 8건만 입력된 것은 아닌지 확인하자.
SELECT count(*) FROM buytbl;
step 8-5: 외부 조인(OUTER JOIN)으로 구매 테이블의 내용은 모두 출력되도록 해보자. 그리고 아이디로 정렬해 보자.
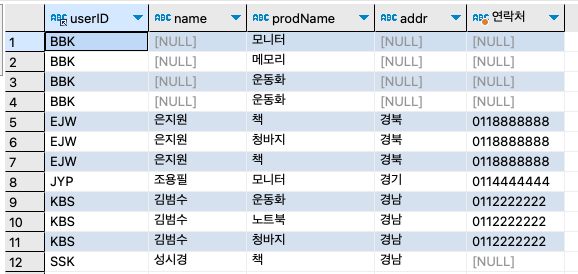
SELECT b.userID, u.name, b.prodName, u.addr, CONCAT(u.mobile1, u.mobile2) AS '연락처' FROM buytbl b LEFT OUTER JOIN usertbl u ON u.userID = b.userid ORDER BY b.userID;
BBK라는 아이디를 가진 회원은 이름, 주소, 연락처가 없다. 앞에서 바비킴(BBK)의 아이디를 'VVK'로 변경해서 이러한 현상이 발생했다. 그러므로, 함부로 외래 키 제약 조건을 끊고 데이터를 수정하는 것은 주의해야 한다.
step 8-6: 바비킴의 아이디를 원래 것으로 돌려 놓자.
SET foreign_key_checks = 0; UPDATE usertbl SET userID = 'BBK' WHERE userID = 'VVK'; SET FOREIGN_key_checks = 1;
step 8-7: 이러한 문제를 없애기 위해서 만약 회원 테이블의 userID가 바뀔 때 이와 관련되는 구매 테이블의 userID도 자동 변경되도록 하고 싶다.
외래 키 제약 조건을 삭제한 후에 다시 ON UPDATE cASCADE 옵션과 함께 설정한다.ALTER TABLE buytbl DROP FOREIGN KEY FK_usertbl_buytbl; ALTER TABLE buytbl ADD CONSTRAINT FK_usertbl_buytbl FOREIGN KEY (userid) REFERENCES usertbl(userID) ON UPDATE CASCADE ;
step 8-8: usertbl의 바비킴의 ID를 다시 변경하고, buytbl에도 바뀌었는지 확인해 본다.
UPDATE usertbl SET userID = 'VVK' WHERE userID = 'BBK'; SELECT b.userID, u.name, b.prodName, u.addr, CONCAT(u.mobile1, u.mobile2) AS '연락처' FROM buytbl b LEFT OUTER JOIN usertbl u ON u.userID = b.userid ORDER BY b.userID;
step 8-9: 이번에는 바비킴(VVK)이 회원을 탈퇴하면(= 회원 테이블에서 삭제되면) 구매한 기록도 삭제되는지 확인하자.
DELETE FROM usertbl WHERE userID = 'VVK';
외래 키 제약 조건 때문에 삭제되지 않았다. 이런 경우에는 기준 테이블의 행 데이터를 삭제할 때, 외래 키 테이블의 연관된 행 데이터도 함께 삭제되도록 설정할 필요가 있다.
step 8-10: ON DELETE CASCADE문을 추가하면 된다.ALTER TABLE buytbl DROP FOREIGN KEY FK_usertbl_buytbl; ALTER TABLE buytbl ADD CONSTRAINT FK_usertbl_buytbl FOREIGN KEY (userid) REFERENCES usertbl(userID) ON UPDATE CASCADE ON DELETE CASCADE ;
step 8-11: 다시 삭제한 후에 buytbl에도 따라 삭제되었는지 확인해 보자.
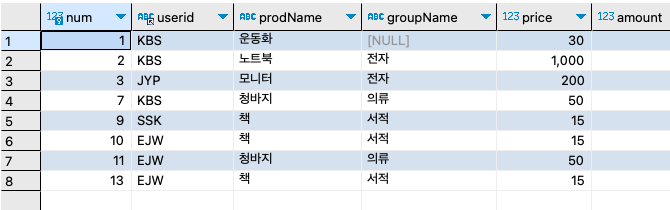
DELETE FROM usertbl WHERE userID = 'VVK'; SELECT * FROM buytbl;
바비킴(VVK)이 구매한 기록 4건은 삭제되고, 전체 8건만 남아 있음을 확인할 수 있다.
step 9: 이번에는 usertbl에서 CHECK 제약 조건이 걸린 출생년도(birthYear)열을 삭제해 보자.
step 9-1: ALTER TABLE로 출생년도를 삭제하자.ALTER TABLE usertbl DROP COLUMN birthYear;잘 삭제 된다. MySQL은 CHECK 제약 조건이 설정된 열은 제약 조건을 무시하고 제거한다.
다른 DBMS에서는 CHECK 제약 조건이 설정된 열은 삭제되지 않는다.








뷰
뷰(View)는 일반 사용자 입장에서는 테이블과 동일하게 사용하는 개체다.
뷰의 개념
쿼리 창에서 SELECT문을 수행해서 나온 결과를 생각해 보자.
결과가 결국 테이블의 모양을 가지고 있는 것이 확인된다.
뷰는 바로 이러한 개념이다. 그래서, 뷰의 실체는 SELECT문이 되는 것이다.
SELECT의 결과를 v_usertbl이라고 부른다면, 앞으로는 v_usertbl을 그냥 테이블이라고 생각하고 접근하면 될 것 같다.
CREATE VIEW v_usertbl AS
SELECT userID, name, addr
FROM usertbl;뷰를 새로운 테이블로 생각하고 접근하면 된다.
SELECT * FROM v_usertbl;
뷰는 기본적으로 '읽기 전용'으로 많이 사용되지만, 뷰를 통해서 원테이블의 데이터를 수정할 수도 있다. 뷰를 통해서 테이블의 데이터를 수정하는 것이 그다지 바람직하지는 않지만, 꼭 필요한 경우도 있을 수 있으니 어떠한 제한이 있는지 알아둘 필요는 있다.
뷰의 장점
-
보안에 도움이 된다.
뷰 v_usertbl에는 사용자의 이름과 주소만이 있을 뿐, 사용자의 중요한 개인정보인 출생년도, 연락처, 키, 가입일 등의 정보는 들어 있지 않다. -
복잡한 쿼리를 단순화 시켜 줄 수 있다.
다음은 물건을 구매한 회원들에 대한 쿼리다.SELECT u.userID, u.name, b.prodName, u.addr, CONCAT(u.mobile1, u.mobile2) AS '연락처' FROM usertbl u INNER JOIN buytbl b ON u.userID = b.userid ;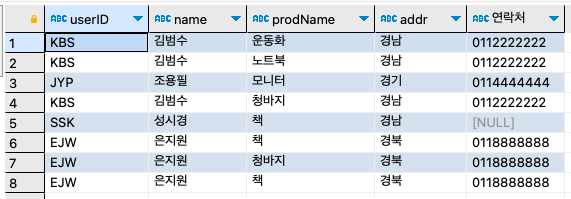
만약 이 쿼리를 자주 사용해야 한다면 사용자들은 매번 위와 같은 복잡한 쿼리를 입력해야 할 것이다. 이를 뷰로 생성해 놓고 사용자들은 해당 뷰만 접근하면 간단히 해결된다.
CREATE VIEW v_userbuytbl AS
SELECT
u.userID,
u.name,
b.prodName,
u.addr,
CONCAT(u.mobile1, u.mobile2) AS '연락처'
FROM usertbl u
INNER JOIN buytbl b
ON u.userID = b.userid ;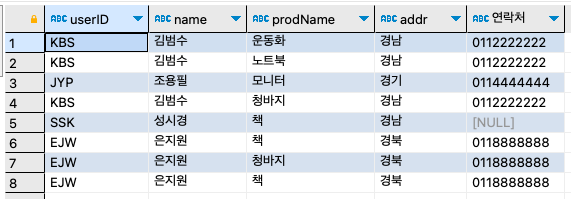
접근할 경우에는 v_userbuytbl을 그냥 테이블이라 생각하고 접근하면 된다. WHERE절도 사용할 수 있다. '김범수'의 구매 기록을 알고 싶다면 다음과 같이 사용하면 된다ㅣ.
SELECT * FROM v_userbuytbl
WHERE name = '김범수';
실습: 뷰를 생성해서 활용하자.
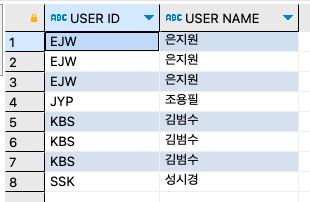
step 1: 기본적인 뷰를 생성한다. 뷰의 생성 시에 뷰에서 사용될 열의 이름을 변경할 수도 있다.
CREATE VIEW v_userbuytbl AS SELECT u.userID AS 'USER ID', u.name AS 'USER NAME', b.prodName AS 'PRODUCT NAME', u.addr, CONCAT(u.mobile1, u.mobile2) AS 'MOBILE PHONE' FROM usertbl u INNER JOIN buytbl b ON u.userID = b.userid ; SELECT `USER ID`, `USER NAME` FROM v_userbuytbl;
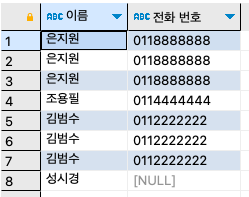
step 2: 뷰의 수정은 ALTER VIEW 구문을 사용하면 된다.
ALTER VIEW v_userbuytbl AS SELECT u.userID AS '사용자 아이디', u.name AS '이름', b.prodName AS '제품 이름', u.addr, CONCAT(u.mobile1, u.mobile2) AS '전화 번호' FROM usertbl u INNER JOIN buytbl b ON u.userID = b.userid ; SELECT `이름`, `전화 번호` FROM v_userbuytbl;
step 3: 뷰의 삭제는 DROP VIEW를 사용하면 된다.
DROP VIEW v_userbuytbl;
step 4: 뷰에 대한 정보를 확인해 보자.
step 4-1: 간단한 뷰를 다시 생성하자CREATE VIEW는 기존에 뷰가 있으면 오류가 발생하지만, CREATE OR REPLACE VIEW는 기존에 뷰가 있어도 덮어쓰는 효과를 내기 때문에 오류가 발생하지 않는다. 즉, DROP VIEW와 CREATE VIEW를 연속 쓴 효과를 갖는다.
CREATE OR REPLACE VIEW v_usertbl AS SELECT userID, name, addr FROM usertbl; SELECT * FROM v_usertbl;
step 4-2: 뷰의 정보를 확인해 보자.
DESC v_usertbl;
마치 테이블과 동일하게 보여준다. 주의할 점은 PRIMARY KEY 등의 정보는 확인되지 않는다는 점이다.
step 4-3: 뷰의 소스 코드를 확인해 보자.
SHOW CREATE VIEW v_usertbl;
step 5: 뷰를 통해서 데이터를 변경해 보자.
step 5-1: v_usertbl 뷰를 통해 데이터를 수정해 보자.UPDATE v_usertbl SET addr = '부산' WHERE userID = 'JKW';
step 5-2: 데이터를 입력해 보자.
INSERT INTO v_usertbl(userID, name, addr) VALUES ('KBM', '김병만', '충북');
v_usertbl이 참조하는 테이블 usertbl의 열 중에서 birthYear열은 NOT NULL로 설정되어서 반드시 값을 입력해 주거나 DEFAULT가 지정되어 있으면 된다. 하지만 현재의 v_usertbl에서는 birthYear를 참조하고 있지 않으므로 값을 입력할 수 없다.
값을 v_usertbl을 통해서 입력하고 싶다면 v_usertbl에 birthYear를 포함하도록 재정의하거나 usertbl에서 birthYear를 NULL 또는 DEFAULT 값을 지정해야 한다.
step 6: 이번에는 그룹 함수를 포함하는 뷰를 정의해 보자.
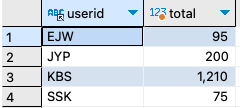
step 6-1: SUM() 함수를 사용하는 뷰를 간단히 정의해 보자.CREATE VIEW v_sum AS SELECT userid AS 'userid', SUM(price*amount) AS 'total' FROM buytbl GROUP BY userid;
step 6-2: v_sum 뷰를 통해서 데이터의 수정이 될까? 당연히 SUM() 함수를 사용한 뷰를 수정할 수는 없다. 시스템 데이터베이스 중 하나인 INFORMATION_SCHEMA의 VIEWS 테이블에서 전체 시스템에 저장된 뷰에 대한 다양한 정보를 가지고 있다.
SELECT * FROM information_schema.views WHERE table_schema = 'shopdb' AND table_name = 'v_sum';
IS_UPDATABLE열이 NO로 되어 있으므로, 이 뷰를 통해서는 데이터를 변경(INSERT, UPDATE, DELETE)할 수 없다.
이 외에도 뷰를 통해서 데이터의 수정이나 삭제할 수 없는 경우는 다음과 같다.
- 집계 함수를 사용한 뷰
- UNION ALL, JOIN 등을 사용한 뷰
- DISTINCT, GROUP BY 등을 사용한 뷰
step 7: 지정한 범위로 뷰를 생성하고 데이터를 입력하자.
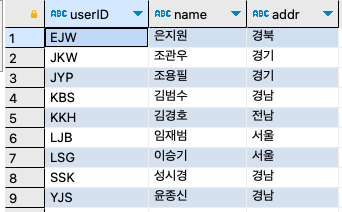
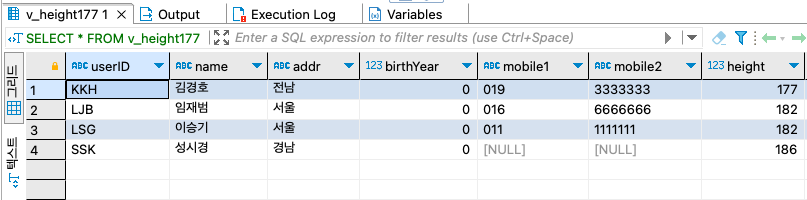
step 7-1: 키가 177 이상인 뷰를 생성하자.CREATE VIEW v_height177 AS SELECT * FROM usertbl WHERE height >= 177; SELECT * FROM v_height177 ;
step 7-2: v_height177 뷰에서 키가 177미만인 데이터를 삭제하자.
DELETE FROM v_height177 WHERE height < 177; SELECT * FROM v_height177 ;
step 7-3: v_height177 뷰에서 키가 177 미만인 데이터를 입력해 보자.
INSERT INTO v_height177 VALUES ('KBM', '김병만', '경기', 1977, '010', '5555555', 158, '2023-01-01');입력은 된다. v_height177 뷰를 확인해 보라. 입력된 값이 보이지 않을 것이다. 입력이 되더라도 입력된 값은 키가 177 미만이므로 v_height177 뷰에는 보이지 않는다. 직접 usertbl을 확인해야 김병만이 보인다.
SELECT * FROM v_height177 ; SELECT * FROM usertbl ;
step 7-4: 그런데 키가 177 이상인 뷰를 통해서 158의 키를 입력한 것은 별로 바람직해 보이지 않는다. 즉, 예상치 못한 경로를 통해서 입력되지 말아야 할 데이터가 입력된 듯한 느낌이 든다. 키가 177 이상인 뷰이므로 177 이상의 데이터만 입력되는 것이 바람직할 듯하다. 이럴 때는 WITH CHECK OPTION문을 사용하면 된다.
ALTER VIEW v_height177 AS SELECT * FROM usertbl WHERE height >= 177 WITH CHECK OPTION ; INSERT INTO v_height177 VALUES ('SJH', '서장훈', '서울', 2006, '010', '3333333', 155, '2023-3-3');
키가 177 미만은 이제는 입력이 되지 않고, 177 이상의 데이터만 입력될 것이다.
step 8: 두 개 이상의 테이블이 관련되는 복합 뷰를 생성하고 데이터를 입력하자.
INSERT INTO v_userbuytbl VALUES ('PKL', '박경리', '운동화', '경기', '00000000000', '2023-2-2');
두 개 이상의 테이블이 관련된 뷰는 업데이트할 수 없다.
step 9: 뷰가 참조하는 테이블을 삭제해보자.
step 9-1: 두 테이블을 삭제한다.DROP TABLE usertbl, buytbl;
step 9-2: 뷰를 다시 조회해 본다.
SELECT * FROM v_userbuytbl;
당연히 참조하는 테이블이 없기 때문에 조회할 수 없다는 메시지가 나온다.
step 9-3: 뷰의 상태를 체크해 보자.
CHECK TABLE v_userbuytbl;
뷰가 참조하는 테이블이 없는 것을 확인할 수 있다.









테이블스페이스
소용량의 데이터를 다룰 때는 테이블이 저장되는 물리적 공간인 '테이블스페이스(Tablespace)'에 대해서 별로 신경쓰지 않아도 되지만, 대용량의 데이터를 다룰 때는 성능 향상을 위해서 테이블스페이스에 대한 설정을 하는 것이 좋다.
테이블스페이스의 개념
데이터베이스가 테이블이 저장되는 논리적 공간이라면, 테이블스페이스는 테이블이 실제로 저장되는 물리적인 공간을 말한다. 지금까지는 테이블을 생성할 때 별도의 테이블스페이스를 지정하지 않았기 때문에 시스템 테이블스페이스(System Tablespace)에 테이블이 저장되었다. 시스템 테이블스페이스에 대한 정보는 시스템 변수 innodb_data_file_pate에 관련 내용이 저장되어 있다.
SHOW VARIABLES LIKE 'innodb_data_file_path';
값의 정보는 '파일명:파일크기:최대파일크기'를 의미하는데, 기본적으로 파일은 ibdata 이고, 파일 크기는 12MB, 최대 파일 크기는 허용하는 최대값까지 자동 증가한다. MySQL 8.0에서 테이블스페이스 파일은 기본적으로 'C:\Programdata\MySQL\MySQL Server 8.0\Data' 폴더에 저장 되어 있다.
SHOW VARIABLES LIKE 'datadir';
MAC ARM Home brew의 경우엔/opt/homebrew/var/mysql/이다.
성능 향상을 위한 테이블스페이스 추가
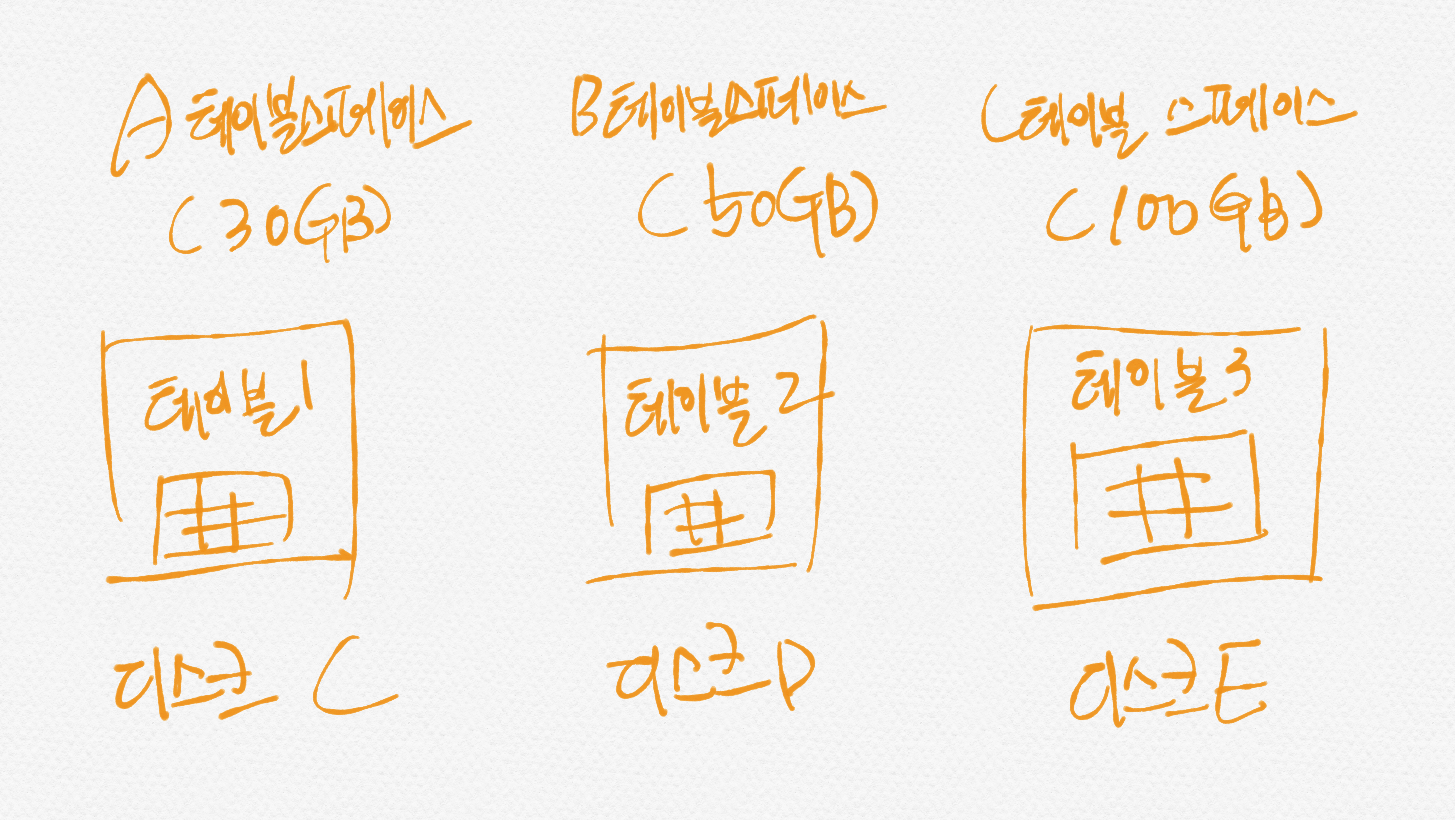
기본 설정은 모든 테이블이 시스템 테이블스페이스에 저장되지만, 대용량 테이블을 동시에 여러 개 사용하는 상황이라면 테이블마다 별도의 테이블스페이스에 저장하는 것이 성능에 효과적이다. 다음과 같이 각 테이블스페이스마다 별도의 대용량 테이블을 저장하는 상황을 가정해 보자.
실습: 대용량의 데이터를 운영한다는 가정하에, 테이블스페이스를 분리해서 사용해 보자.
step 0: 먼저 각 테이블이 별도의 테이블스페이스에 저장되도록 시스템 변수 innodb_file_per_table이 ON으로 설정되어 있어야 한다. MySQL 8.0은 기본적으로 ON으로 설정되어 있다.
SHOW VARIABLES LIKE 'innodb_file_per_table';
step 1: 3개의 테이블 스페이스를 생성하자.
CREATE TABLESPACE ts_a ADD DATAFILE 'ts_a.ibd'; CREATE TABLESPACE ts_b ADD DATAFILE 'ts_b.ibd'; CREATE TABLESPACE ts_c ADD DATAFILE 'ts_c.ibd';테이블스페이스는 데이터베이스와 관련이 없다. 그러므로 USE문으로 데이터베이스를 선택할 필요가 없다. 또한, 테이블스페이스의 확장명은 꼭 ibd이여야 한다.
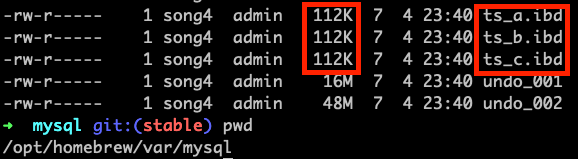
step 2: 파일 탐색기에서 폴더를 확인해 보자. 아직은 빈 테이블스페이스여서 파일의 크기가 상당히 작을 것이다.
step 3: 각 테이블스페이스에 파일을 생성하자.
step 3-1: 간단히 CREATE TABLE문으로 테이블을 생성할 때, 제일 뒤에 TABLESPACE문으로 저장하고자 하는 테이블스페이스를 지정하면 된다.CREATE TABLE table_a (id int) TABLESPACE ts_a;
step 3-2: 테이블을 만든 후에 ALTER TABLE문으로 테이블스페이스를 변경할 수도 있다.
CREATE TABLE table_b (id int); ALTER TABLE table_b TABLESPACE ts_b;
step 4: 대용량의 테이블을 복사한 후, 테이블스페이스를 지정해 보자.
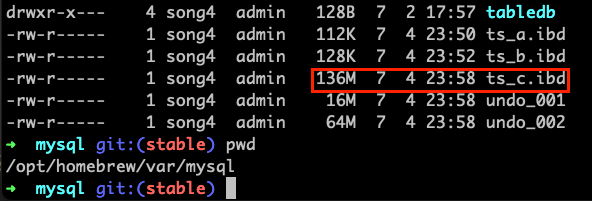
step 4-1: employees 데이터베이스의 salaries 테이블에는 약 280만 건의 데이터가 저장되어 있다.CREATE TABLE table_c (SELECT * FROM employees.salaries); ALTER TABLE table_c TABLESPACE ts_c;
step 4-2: 파일 탐색기에서 C테이블스페이스(ts_c.ibd)를 확인해 보자.
소용량의 데이터를 사용할 경우에는 특별히 테이블스페이스를 신경쓰지 않아도 되지만, 대용량의 데이터를 운영할 경우에는 성능 향상을 위해서 테이블스페이스의 분리를 적극적으로 고려해 보는 것이 바람직하겠다.

자체평가 - 학습 흐름을 잘 이해하고 있는가?
테이블 생성
제약 조건: 기본 키, 왜리 키 등
테이블 압축과 효율성 및 임시 테이블의 활용
뷰의 개념과 장단점
