내가 컴퓨터공학과에 진학한 이유는 인터넷 세계가 너무 알고싶어서였다. 가장 좋아하는 전공수업도 네트워크였다. 통신과 네트워크에 관심이 많은 나로썬 너무 재밌었던 6주차였다. 여전히 코드 짜는건 고통스러웠지만 프레임워크를 안쓰고 웹서버를 만들면서 더 깊게 네트워크와 서버를 이해할 수 있는 시간이었다. 프록시 70점 맞은거 소심하게 자랑하면서 회고해보겠다.
웹 서버
http 요청부터 응답까지 한땀한땀
이전까지의 나는 스프링과 플라스크를 이용해서 편하게 웹서버를 구현할 수 있었다. 이때는 내가 요청과 응답을 하나하나 적지 않아도 프레임워크들이 내가 인자로 넣은 것들을 알아서 http request 요청으로 바꿔서 보내줬고 응답도 알아서 처리해줬다. 하지만 퓨어 웹서버를 만들면서는 내가 이런 부분까지 다 처리해줘야 했다.
void serve_static(int fd, char *filename, int filesize, int isHEAD) {
int srcfd;
char *srcp, filetype[MAXLINE], buf[MAXBUF];
get_filetype(filename, filetype);
sprintf(buf, "HTTP/1.0 200 OK\r\n");
sprintf(buf, "%sServer: Tiny Web Server\r\n", buf);
sprintf(buf, "%sConnection: close\r\n", buf);
sprintf(buf, "%sContent-length: %d\r\n", buf, filesize);
sprintf(buf, "%sContent-type: %s\r\n\r\n", buf, filetype);
Rio_writen(fd, buf, strlen(buf));
이렇게 말이다. 문자열 하나하나 이렇게 관리하는 게 쉬운 건 아니다. 왜 프레임워크가 나왔는지 뼈저리게 느끼는 시간이었다. ㅎ_ㅎ
HTTP Response Splitting 공격
나는 이때까지 시험을 위한 공부를 많이 했다. 그때 http 요청과 응답은 헤더와 바디로 나뉘고 헤더와 바디를 구분할때는 캐리지리턴과 개행문자를 이용한다. 여기서 CRLF 취약점, http 응답 분할 공격이 일어날 수 있다고 무지성 외웠었다.
근데 이번에 직접 응답을 만들어보니까 위 내용들을 내가 체감하고 이해할 수 있게 됐다.
sprintf(content, "QUERY_STRING=%s", buf);
sprintf(content, "Welcome to add.com: ");
sprintf(content, "%sTHE Internet addition portal.\r\n<p>", content);
sprintf(content, "%sThe answer is: %d + %d = %d\r\n<p>",
content, n1, n2, n1 + n2);
sprintf(content, "%sThanks for visiting!\r\n", content);
printf("Connection: close\r\n");
printf("Content-length: %d\r\n", (int)strlen(content));
printf("Content-type: text/html\r\n\r\n");
printf("%s", content);
fflush(stdout);
exit(0);adder.c 의 일부다. 이 코드를 크게 두부분으로 나누면 윗부분은 content 버퍼에 응답을 쓰는것이고 밑부분은 응답을 printf()로 다른 소켓에 적어주고 있다. (표준출력을 소켓으로 바꿨음)
난 이 코드를 처음봤을 때 이해가 안됐던 부분이 printf()로 다 찍었는데 왜
printf("s", content);
여기만 웹페이지에 출력이 될까? 이게 궁금했다. "Connection : close" 여기 밑에도 다 출력을 시켰는데 위에부분은 안나온다.
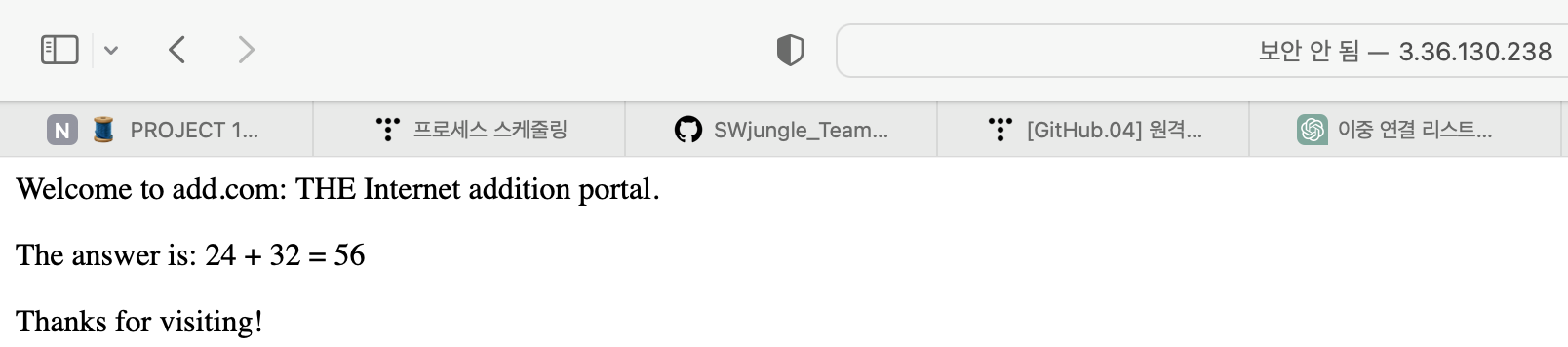
이렇게 나오는 이유는 당연히
printf("Connection: close\r\n");
printf("Content-length: %d\r\n", (int)strlen(content));
printf("Content-type: text/html\r\n\r\n"); 이건 해더부분이기 때문에 요청을 받은쪽에서 헤더로 인식을 했기 때문에 출력을 안한 거다. 받은쪽에서 헤더를 구분할 수 있었던 것은 마지막 Content-Type을 적는부분에 \r\n\r\n 을 적었기 때문이다. 이때 쫌 유레카였다. ㅎ_ㅎ
아무튼 결론은 이런식으로 헤더와 바디를 구분하기 때문에 만약 request 인자에서 캐리지리턴이나 라인피드가 있고 그걸 검증하지 않으면 request 요청하면서 응답메시지를 분할할 수 있다. 중간에 공격자가 이걸 분할하고 두번째 응답을 조작하는 것이 HTTP Response Splitting 공격이다.
소켓과 파일 디스크립터 with C
운영체제는 자기 나름대로 파일을 관리하기 위한 시스템을 가지고 있다. 그것이 파일시스템. 파일 입출력 과정에서 필요한 건 FD이다. 파일간 입출력 통로를 만들어 주는 것이다. FD에는 입출력 정보가 적혀있는 듯하다. 디테일하게 말하면 fd에 어떤 주소값이 적혀있고 그 주소에 가면 (File Table) 어떤애를 어디서부터 읽고쓸지 적혀있는 것 같다.
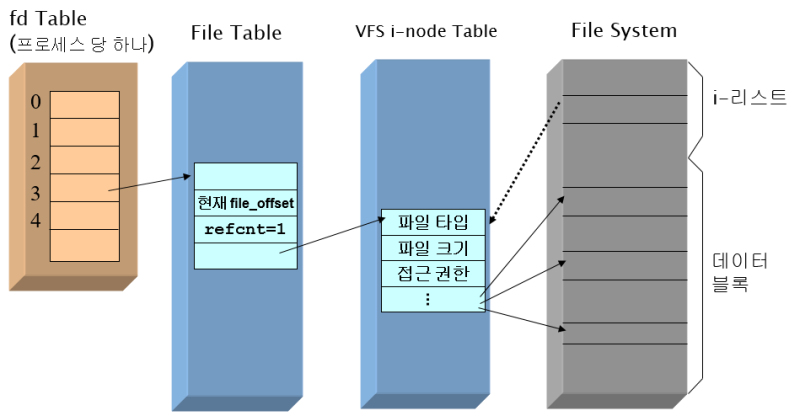
소켓도 결국 입출력 통로가 필요하다. 프로그램에서 소켓을 열때 fd를 할당받아놓으면 앞으로 그 통로를 통해서 입출력이 이루어진다고 생각할 수 있다.
listenfd = Open_listenfd(argv[1]);
이렇게 소켓을 열면 파일디스크립터를 할당받는다.
소켓은 결국 OSI 7계층에서 4계층 아래부터를 추상화한 개념이라고 보면 된다. 소켓을 쓰면 그 아래 개념을 알 필요없이 데이터를 주고받을 수 있다. 데이터를 효율적으로 전달하기 위해서 각자마다 규약을 가지고 주고받다가 버클리대학교에서 BSD소켓을 만들고 공짜로 소스를 풀어서 지금 이 방식이 세계를 통합한 것으로 보인다.
동적 파라미터 처리
CGI
이번 서버는 사용자가 보낸 파라미터를 CGI 방식으로 처리했다. CGI는 서버에 동적 데이터(사용자가 입력한 데이터 등)가 들어왔을 때 처리하는 방식 중 하나이다. 동적인 데이터가 들어오면 새로운 프로세스를 만들어 그 데이터를 처리하는 미리 만들어놓은 파일을 실행한다. 중간에 새로운 프로그램을 실행하게 만들어버리면 공격자가 임의로 다른 프로그램을 연결시켜 사용자의 입력을 탈취할 수도 있듯이 보안에 취약하다. 그래서 요즘은 CGI를 잘 안쓰고 자바의 서블릿을 많이 이용한다.
vs 서블릿
자바 스프링 공부할 때 HttpServletRequest 얘 참 많이 봤는데 얘가 동작 파라미터를 처리하기 위해 존재한다는 걸 이제 알게되었다.
cgi 코드를 보면
int main(void) {
char *buf, *p;
char arg1[MAXLINE], arg2[MAXLINE], content[MAXLINE];
int n1=0, n2=0;
if ((buf = getenv("QUERY_STRING")) != NULL) {
p = strchr(buf, '&');
*p = '\0';
strcpy(arg1, buf);
strcpy(arg2, p+1);
n1 = atoi(arg1);
n2 = atoi(arg2);
}
sprintf(content, "QUERY_STRING=%s", buf);
sprintf(content, "Welcome to add.com: ");
sprintf(content, "%sTHE Internet addition portal.\r\n<p>", content);
sprintf(content, "%sThe answer is: %d + %d = %d\r\n<p>",
content, n1, n2, n1 + n2);
sprintf(content, "%sThanks for visiting!\r\n", content);
printf("Connection: close\r\n");
printf("Content-length: %d\r\n", (int)strlen(content));
printf("Content-type: text/html\r\n\r\n");
printf("%s", content);
fflush(stdout);
exit(0);
}결국 문자열 파싱해서 데이터 받아오고 적절한 처리를 한 다음 응답 메소드를 보내는 것인데 서블릿도 결국 비슷한 걸 하는 애인 것 같다. 다만 그 방식이 서블릿은 was와 servlet 컨테이너를 이용해 멀티스레드로 구현되어 있는 그런 차이..?
결과물
기능에만 집중한, css는 1도 넣지 않은 웹서버 디자인이 특징이다.
프록시 서버
프록시 서버는 클라이언트의 요청을 대신 서버로 보내주는 중간 서버다. 파이어폭스 브라우저를 설정하면 프록시 서버를 설정할 수 있다. 이걸 직접 설정해보면 조금 느낌이 올 것이다.
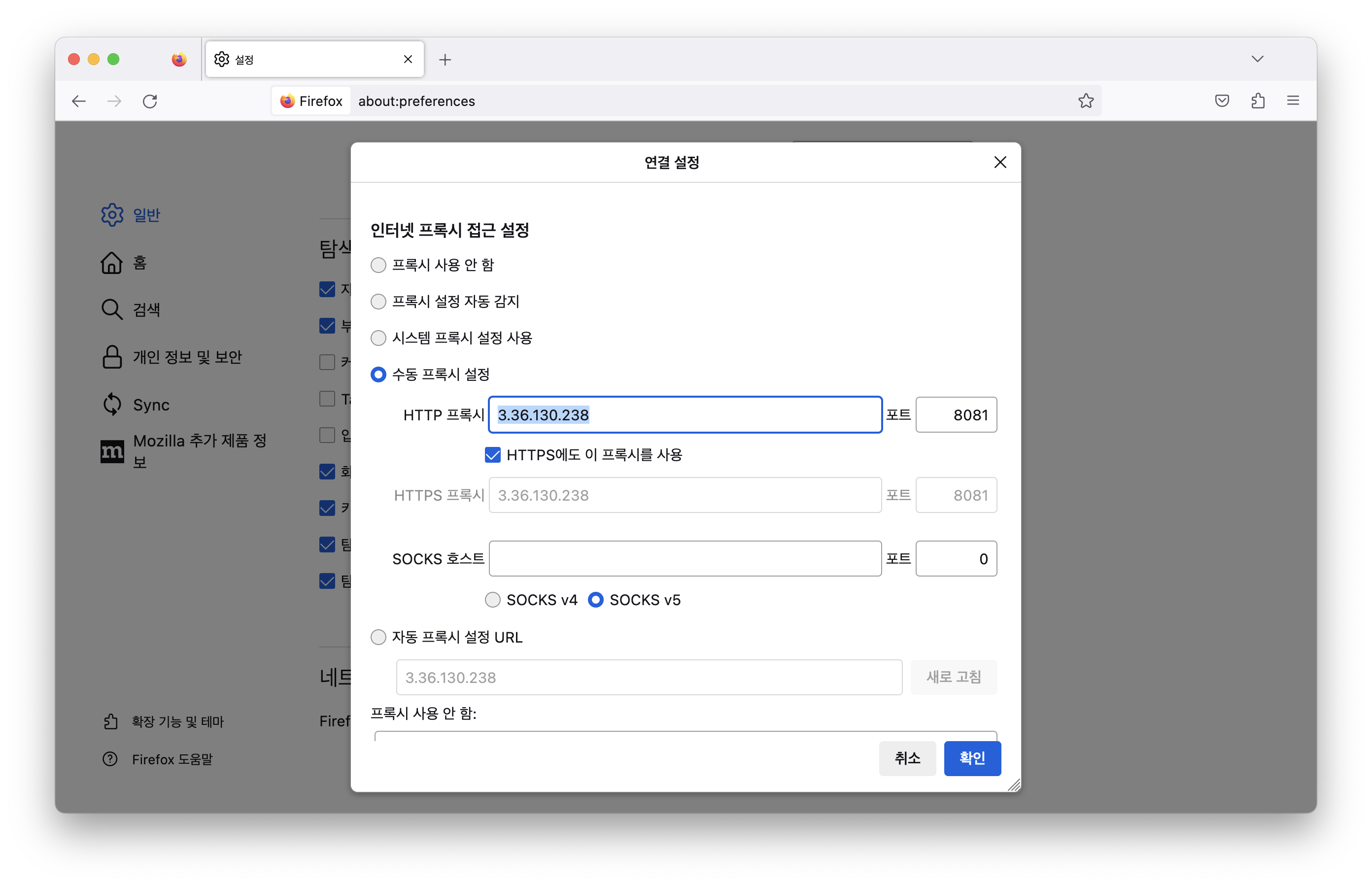
이렇게 설정을 하면 앞으로 내가 저 브라우저를 통해 어떤 사이트에 접속하면 저 서버로 요청이 간다. 저 네트워크의 8081번 포트엔 당연히 요청을 처리할 수 있는 프로그램이 실행되어 있어야 한다. 우리는 그 서버를 구현할 것이다. 근데 사실 테스트할 땐 이렇게 브라우저로 한건 아니고 curl 명령어를 통해 테스트했다.
curl -i -x 프록시주소:포트 접속할서버주소:포트이렇게 명령을 날려주고 적절한 응답이 오면 성공이다.
-x는 프록시 서버 설정하는 거고
-i는 응답의 헤더까지 출력하는 거다. 설정안하면 바디만 온다
프록시 서버는 왜 쓸까?
서버에 클라이언트 개개인이 누군지 숨기고 싶을 때 쓰는 것 같다. 그 반대로 어떤 클라가 특정 사이트에 접속못하게 하는 것도 비슷한 것 같다. 컴퓨터실에서 게임사이트에 못들어가는 것 마냥. 또 자주쓰는 무거운 데이터들을 캐싱할 수도 있다.
vs 리버스 프록시
그냥 프록시가 클라를 위해서 존재한다면 리버스는 서버를 위해 존재한다. 로드밸런싱할 때 좋은 것 같다. 요새는 msa라고 하면서 한 서비스에 여러 서버가 존재하는데 서버들이 어떻게 연결되어있는지 어디에서 어떤걸 처리하는지를 숨기고 싶을때 좋을 것 같다. 리버스 프록시가 서비스의 DMZ 부분이 되는 것 같다.
동시성
동시성이 필요한 이유
동시성을 구현하지 않을 경우 서버는 한번에 하나의 클라이언트만 연결할 수 있다. 만약 한 클라이언트가 연결을 맺고 아무것도 보내지 않고 가만히 있는다면 서버는 계속 read()에서 블로킹 되고 아무것도 하지못한다. 새로운 클라가 연결요청을 하더라도 앞의 클라 연결이 종료될 때 까지 대기해야 한다.
동시성을 구현하면 서버가 다른 클라와 연결을 맺는 것과 그 연결된 이후의 동작을 분리해서 동시에 처리할 수 있다. 그러면 서버에 여러요청이 한번에 들어와도 클라이언트가 대기하지 않아도 된다.
구현 방법
동시성을 구현하는 방법에는 프로세스 생성, I/O 다중화, 스레드가 있다.
다중화는 많은 i/o(fd?)를 미리 다 열어놓고 그곳을 계속 감시하고 있는다. 감시하는 곳에 요청이 들어오면 메인이 그걸 이벤트 기반으로 비동기적으로 확인하고 처리해주는 방식인데, 효율이나 메모리, 데이터 관리하기에는 좋지만 구현하기 어렵다.
클라가 연결된 이후의 처리를 새로운 프로세스에 넘기면 프로세스 방식이고 스레드로 만들면 스레드 방식이다.
코드
스레드를 위한 코드는 책에 다 나와있었다.
while (1)
{
clientlen = sizeof(clientaddr);
connfdp = malloc(sizeof(int));
*connfdp = Accept(listenfd, (SA *)&clientaddr, &clientlen);
Getnameinfo((SA *)&clientaddr, clientlen, hostname, MAXLINE, port, MAXLINE, 0);
printf("커넥션 연결 : %d\n", *connfdp);
printf("Accepted connection from (%s, %s)\n", hostname, port);
Pthread_create(&tid, NULL, thread, connfdp);
}doit()을 스레드로 뺀다.
void *thread(void *vargp)
{
int connfd = *((int *)vargp);
Pthread_detach(pthread_self());
Free(vargp);
doit(connfd);
Close(connfd);
return NULL;
}캐싱
사실 내가 구현한건 짭캐시이다. 그냥 테스트 코드만 잘 돌아가고 캐시데이터가 너무 많아졌을때 삭제하는 거나 쓴 캐시데이터를 리스트의 맨 앞에 넣는 이런것들은 빠져있다.
그래도 조금 설명해보자면
typedef struct cache_t
{
char request[MAXLINE];
int response_size;
char response[MAX_OBJECT_SIZE];
struct cache_t *prev, *next;
} cache_t;이런식으로 구조체를 만들고 한번의 요청응답이 올 때마다 캐시에 기록한다. 다음에 어떤 요청이 올때 캐시리스트에 그 요청 기록이 있으면 그냥 바로 캐시서버에서 저장된 값을 바로 보내준다.
cache_t *res = find_cache(buf);
if (res)
{
printf("캐시된 경우!!!\n");
Rio_writen(fd, res->response, res->response_size);
return;
}서버의 응답을 받고 클라이언트에 그 응답을 다시 돌려줄 때 버퍼를 이용해서 중간에 기록했다가 그 버퍼에 내용을 클라이언트와 연결된 파일 디스크립터에 써줬는데 서버에서 온 응답 사이즈를 알아내는 게 어려웠던 부분이었다.
int res_size;
Rio_readinitb(&response_rio, clientfd);
res_size = Rio_readnb(&response_rio, response_buf, MAX_CACHE_SIZE);
response_buf[res_size] = '\0';
Rio_writen(fd, response_buf, res_size);
Close(clientfd);동호에몽이 알려준 방법이다.
일단 버퍼를 겁나 크게 하고 Rio_reandnb를 하면 리턴으로 사이즈가 나온다. 그럼 size를 그대로 써도 되고 그 버퍼의 인덱스 사이즈 부분을 \0으로 바꿔서 버퍼를 그대로 써도 된다. 딱 그만큼만 읽어진다.
끝
회고는 여기까지.. 아무튼 재밌는 한주였다. 복습하면서 겸사겸사 이거 쓰는건데 반나절이 지났다. 빨리 우선순위 스케줄링 구현해야하러 가봐야겠다.
