TorchVision Object Detection Finetuning Tutorial
- Finetuning(미세조정): 기존에 학습되어져 있는 모델을 기반으로 아키텍쳐를 새로운 목적(나의 이미지 데이터에 맞게)변형하고 이미 학습된 모델 Weights로 부터 학습을 업데이트하는 방법
→ 정교한 파라미터 튜닝으로 기존에 학습이 된 레이어에 내 데이터를 추가로 학습시켜 파라미터를 업데이트
Defining the Dataset
-
pycocotools: 이미지 인식 및 객체 감지 작업을 위한 도구 모음
[ 주요기능 ]
1) 주석 파일을 읽고 객체 인스턴스에 대한 정보를 추출하는 기능
이를 통해 객체 감지, 객체 분할 및 객체 인식 작업에 필요한 데이터를 사용할 수 있다.
2) COCO 형식의 결과 파일을 생성하는 기능
이를 통해 모델의 출력 결과를 COCO 형식으로 저장하고, 이를 평가 및 시각화하는 데 사용할 수 있다.
→ COCO(Common Objects in Context) 데이터셋과 관련된 작업을 수행하는 데 도움이 된다. (* COCO: 데이터셋은 객체 인식, 객체 검출 및 객체 분할과 같은 컴퓨터 비전 작업에 널리 사용되는 대규모 데이터셋으로 실제 이미지에서 다양한 객체 카테고리의 인스턴스를 주석으로 제공한다.) -
labels 에 대한 참고사항
1) 클래스 0 을 배경으로 취급
ex) 고양이 와 강아지 의 오직 2개의 클래스만 분류한다고 가정하면, (0 이 아닌) 1 이 고양이 를, 2 가 강아지 를 나타내도록 정의
2) 학습 중에 가로 세로 비율 그룹화를 사용하려는 경우 get_height_and_width 메소드를 구현하기를 추천
→ 이 메소드가 구현되지 않은 경우에는 모든 데이터셋은 getitem 를 통해 메모리에 이미지가 로드되며 사용자 정의 메소드를 제공하는 것보다 느릴 수 있기 때문
Defining your model
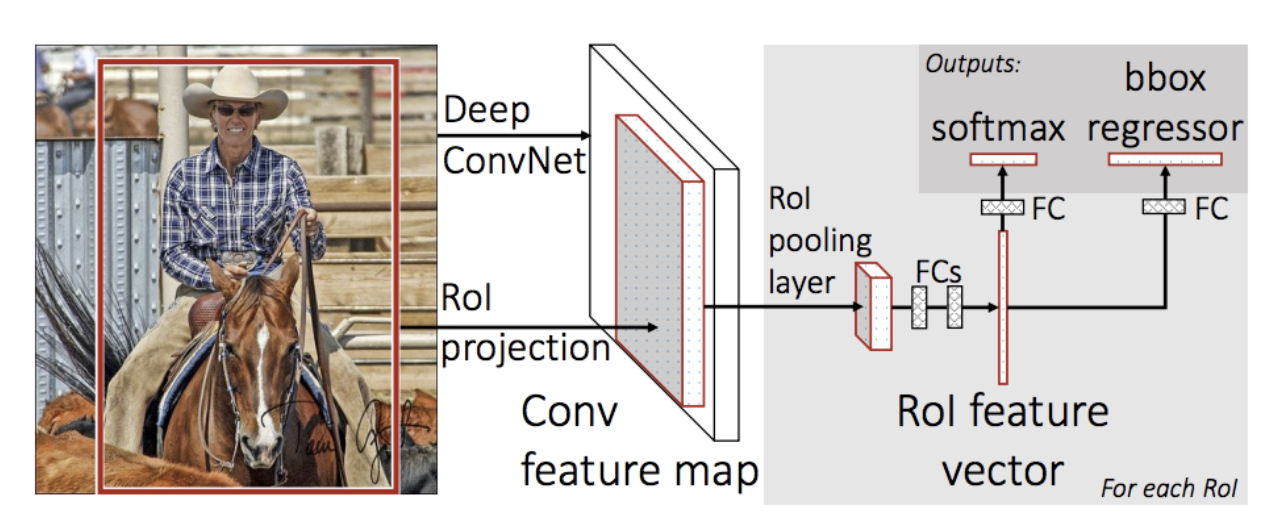
- Fast R-CNN: 이전 R-CNN의 한계점을 극복하고자 나온 모델
→ 가장 핵심적인 아이디어는 RoI Pooling (* RoI는 Region of Interest(관심 영역)의 약자로, 객체 감지 및 인식 작업에서 주목할 가치가 있는 영역)
-
R-CNN의 한계점
1) RoI (Region of Interest) 마다 CNN연산을 함으로써 속도저하
2) multi-stage pipelines으로써 모델을 한번에 학습시키지 못함
→ RoI pooling, CNN 특징 추출부터 classification, bounding box regression까지 하나의 모델에서 학습을 통해 극복 -
RoI Pooling: Fast R-CNN에서 적용된 1개의 피라미드 SPP로 고정된 크기의 feature vector를 만드는 과정
R-CNN에서 CNN output이 FC layer의 input으로 들어가야했기 때문에 CNN input을 동일 size로 맞춰줘야 했기때문에 원래 이미지에서 추출한 RoI를 crop, warp을 통해 동일 size로 조정하였다.
→ 그러나 실제로 "FC layer의 input이 고정인거지 CNN input은 고정이 아니다" 따라서 CNN에는 입력 이미지 크기, 비율 관계없이 input으로 들어갈 수 있고 FC layer의 input으로 들어갈때만 size를 맞춰주기만 하면된다. -
Spatial Pyramid Pooling(SPP):
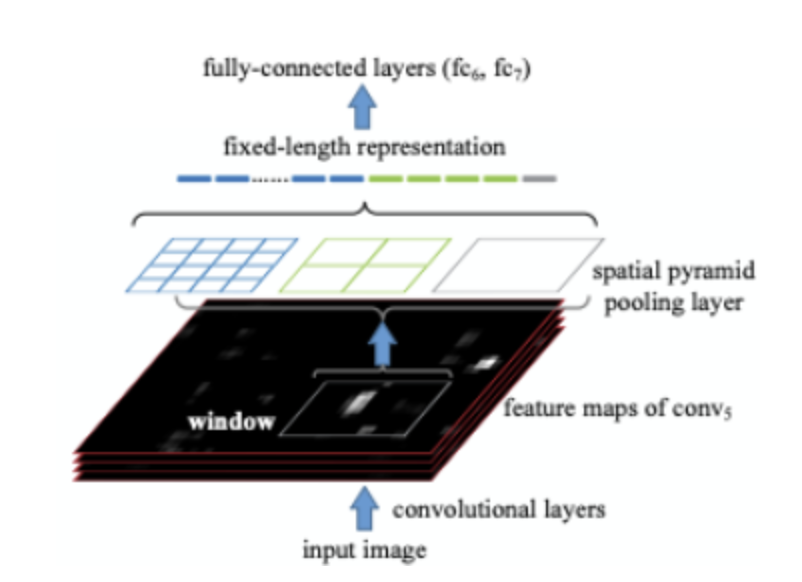
4x4, 2x2, 1x1 세 가지 피라미드가 존재하고, max pooling을 적용하여 각 피라미드 크기에 맞게 max값을 뽑아낸다. 각 피라미드 별로 뽑아낸 max값들을 쭉 이어붙여 고정된 크기 vector를 만들고 이게 FC layer의 input으로 들어간다.
→ 2천개의 region proposal마다 해야했던 2천번의 CNN연산이 1번으로 줄었다. -
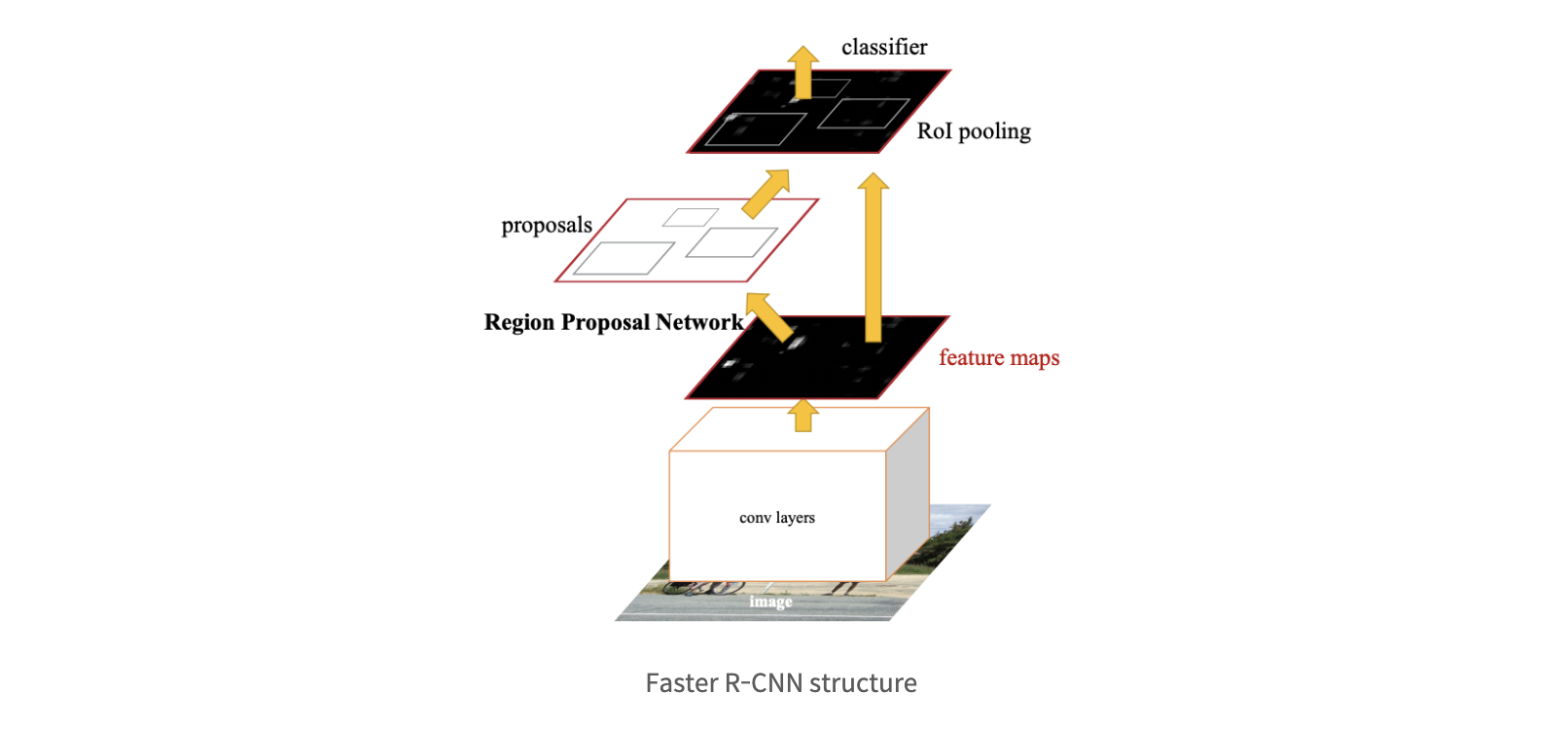
Faster R-CNN:기존 Fast RCNN 구조를 그대로 계승하면서 selective search를 제거하고 RPN(Region Proposal Network)을 통해서 RoI를 계산
→ GPU를 통한 RoI 계산이 가능, RoI 계산도 학습시켜 정확도를 높일 수 있음
Transfer Learning for Computer Vision Tutorial
- Transfer learning(전이학습): 어떤 목적을 이루기 위해 학습된 모델을 다른 작업에 이용하는 것 → 학습이 빠르게 수행될 수 있다. + 작은 데이터셋에 대해 학습할 때 오버피팅을 예방할 수 있다.
Pre-training / Finetuning
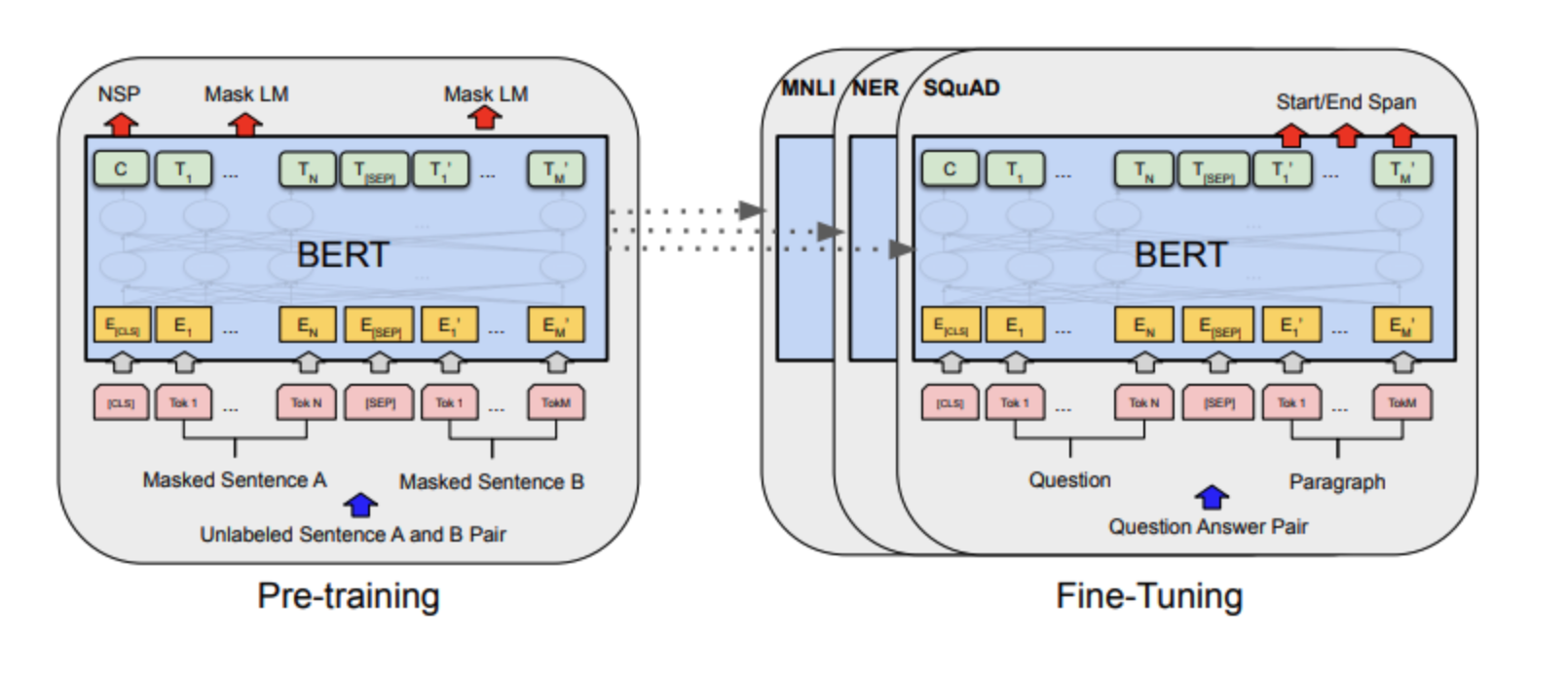
- pre-training: 이전에 학습한 모델의 가중치를 다른 모델에 학습시키는 것
이때, 사전 학습한 가중치를 활용해 학습하고자 하는 본 문제를 하위 문제(downstream task) 라 한다. - fine-tuning: 사전 학습한 모든 가중치와 더불어 downstream task를 위한 최소한의 가중치를 추가해서 모델을 추가로 학습(미세 조정)
Adversarial Example Generation
Threat Model
-
다양한 범주의 적대적 공격이 있는데 보통 가장 중요한 목표는 입력 데이터 최소한의 작은 변화를 추가하여 이것이 의도적으로 잘못 분류되게 하는 것이다.
-
공격자가 가지고 있는 정보에 대한 가정
1. 화이트 박스: 공격자가 모델에 대해 아키텍처, 입력, 출력, 가중치를 포함한 모든 것을 알고 있고 접근 가능하다고 가정
2. 블랙 박스: 공격자가 모델의 입력과 출력에 대해서만 접근 가능하고 모델의 가중치와 아키텍처에 관한 내용은 모른다고 가정
-
Fast Gradient Sign Attack: 화이트 박스 공격
→ 변화도를 활용하여 신경망을 공격: 조그만 변화로 판다를 긴팔원숭이로 인식

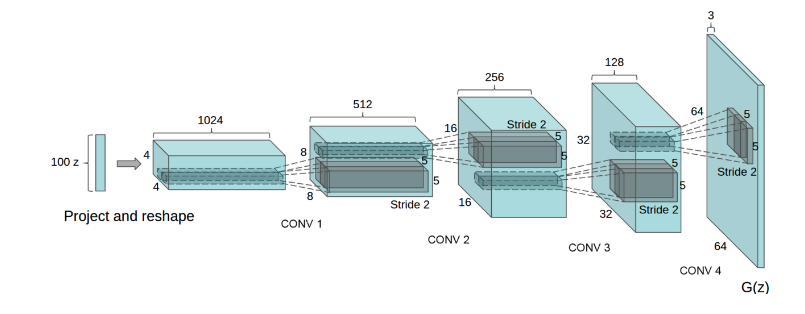
DCGAN Tutorial
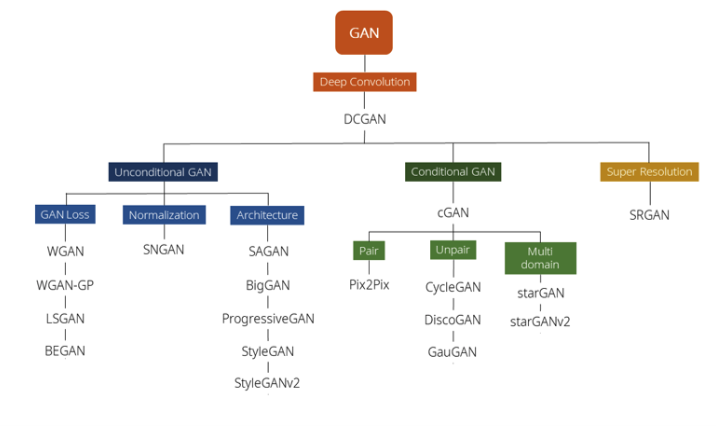
GAN: Generative Adversarial Network
→ Generative model의 한 종류로써 데이터를 생성하는 generator와 데이터를 구별하는 discriminator가 경쟁하는 과정을 통해서 데이터를 학습한다.
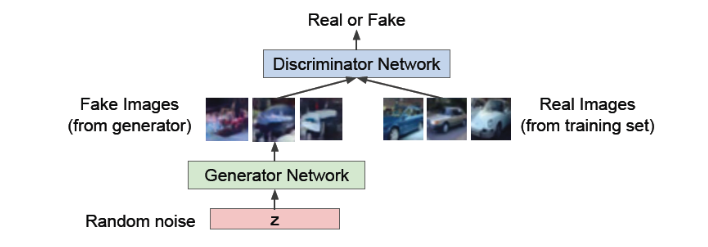
- motivation: Generator는 최대한 실제처럼 보이는 데이터를 생성함으로써 discriminator를 속이려고 시도하고, 이에 반해 discriminator는 실제 데이터와 만들어진 가짜 데이터를 구별하려고 노력한다.
→ 이렇게 서로 경쟁하면서 학습을 함으로써, generator는 점점 더 실제와 같은 데이터를 생성하게 되고, discriminator는 점점 더 실제와 가짜 데이터를 잘 구별할 수 있게 될 것이다. 결론적으로 generator가 실제 데이터와 굉장히 비슷한 데이터를 생성하는 generative model로서의 역할을 할 수 있게 된다.
DCGAN: Deep Convolution GAN
→ GAN에서는 Fully-connected layer 구조였던 네트워크들을 Convolutional layer 구조로 전부 치환
-
모델의 구조
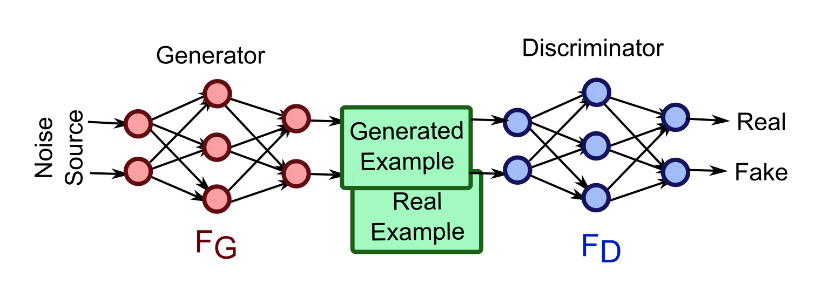
-
discriminator: convolution 계층, batch norm 계층, 그리고 LeakyReLU 활성함수가 사용
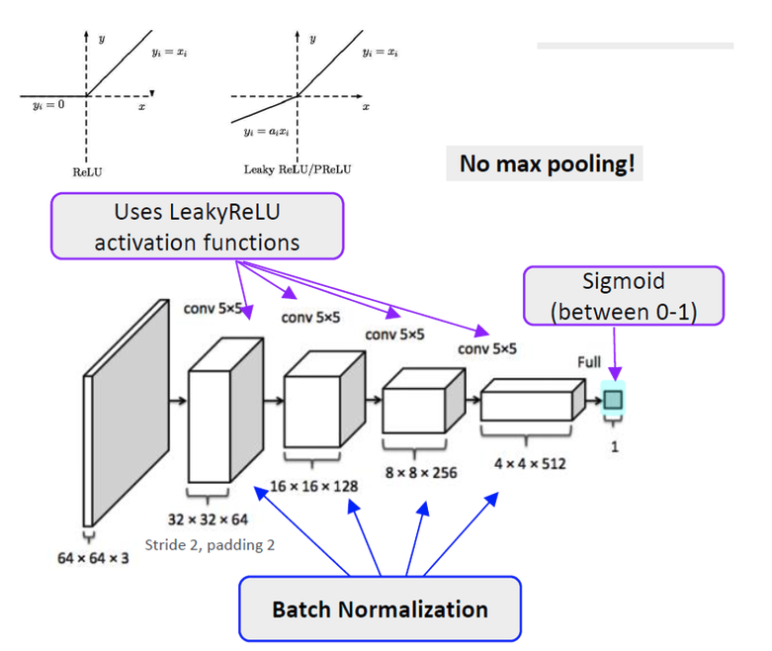
-
generator: convolutional-transpose 계층, 배치 정규화(batch norm) 계층, 그리고 ReLU 활성함수가 사용