
0. Quick Start
데이터 로드 및 처리 함수
- torch.utils.data.Dataset
- 데이터 셋을 나타내는 추상화된 기본 클래스 → 상속하여 커스텀 데이터 셋을 만들 수 있음
- 반드시 __len__ 함수와 __getitem__ 함수를 구현해야함
- Image Datasets, Text Datasets, Audio Datasets이 있음. - torch.utils.data.DataLoader
- 데이터 셋을 받아 미니배치로 분할하고 병렬로 데이터를 로드하기 위한 기능 제공 → 모델에 데이터를 효율적으로 제공할 수 있다.
- 배치 크기, 데이터 순서 섞기 여부, 병렬 로딩에 사용되는 프로세스 수 와 같은 매개변수 설정 가능
transform vs. target_transform
- transform: 데이터 셋의 샘플에 적용할 변환을 정의하는 함수나 변환 객체
ex. 매개변수에 지정한 변환은 데이터 셋의 각 샘플에 적용되어 데이터를 변형시킨다. - target_transform: 데이터 셍의 타깃(라벨 등)에 적용할 변환을 정의하는 함수나 변환 객체
ex. 클래스 라벨을 원-핫 벳터로 변환하는 작업을 수행할 수 있다.
MPS
- MPS 장치는 Metal 프로그래밍 프레임워크를 사용해서 GPU에서 고성능 훈련을 가능하게 한다.
→ cuda와 비슷한 역할을 하나 내 노트북인 맥북 m1에서는 사용 가능하긴하나 잘 되지 않음.
MPS BACKEND 공식문서 링크
1. Tensors
Datatype of tensor
- 'torch.float32' 또는 'torch.float': 32비트 부동 소수점
- 'torch.float64' 또는 'torch.double': 64비트 부동 소수점
- 'torch.float16' 또는 'torch.half': 16비트 부동 소수점
- torch.bool: 부울리언 타입
- torch.int8: 8비트(1바이트) 정수(-128 ~ 127)
- torch.uint8: 8비트(1바이트) 부호 없는 정수(0 ~ 255)
→ 이미지 처리 등에서 픽셀 값이 0부터 255 사이인 경우에 사용 - torch.int16: 16비트(2바이트) 정수(-32768 ~ 32767)
- torch.int32: 32비트(4바이트) 정수(-2147483648 ~ 2147483647)
- torch.int64: 64비트(8바이트) 정수(-9223372036854775808 ~ 9223372036854775807)
- torch.bfloat: 16비트 부동소수점 타입인 BFloat16
Operations on Tensors
- 기본적으로 텐서는 CPU에 할당된다. GPU 연산을 하기 위해서는 GPU로 옮겨줘야한다.
- torch.cat: 텐서결합 torch.cat을 사용하여 주어진 차원을 따라 텐서 시퀀스를 연결할 수 있다.
- In-place operation: 계산 결과를 피연산자에 저장하는 작업.

- tensor을 바꾸면 tensor를 numpy array로 바꾼 값도 같이 바뀐다.

Creating Tensors
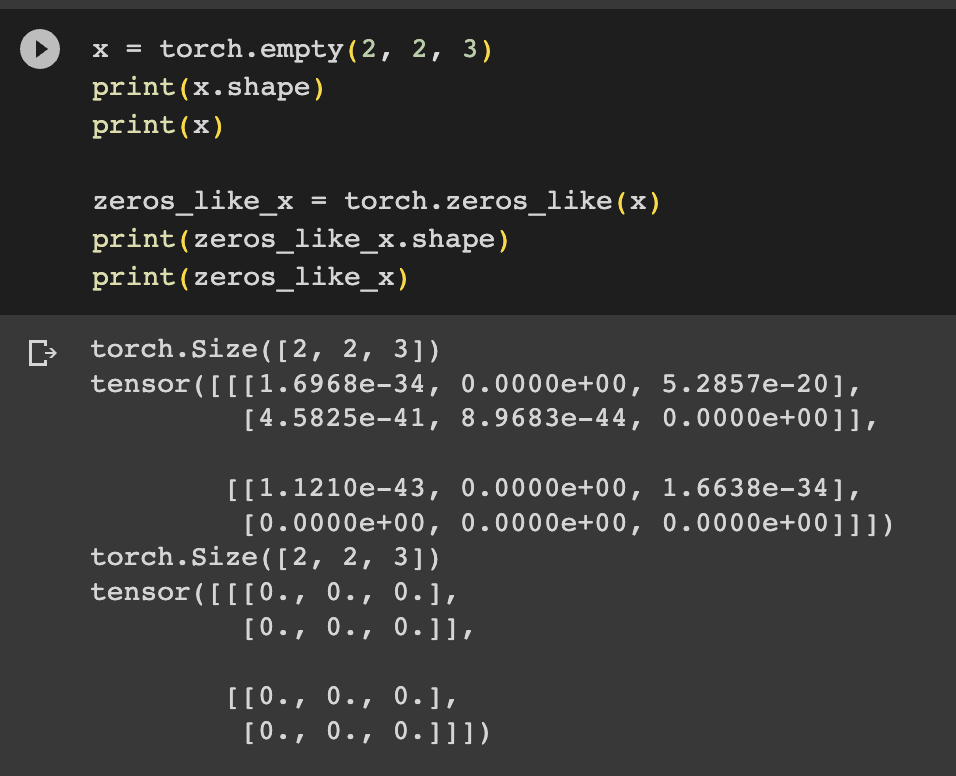
- torch.empty(): 원하는 값 만큼 행렬 초기화
→ 텐서를 출력하면 무작위로 보이는 값을 보게 되는데, 이는 torch.empty()가 텐서를 위한 메모리를 할당하지만 어떤 값으로도 초기화하지 않기 때문에 할당 시점에 메모리에 있던 모든 것이 표시된다.
Tensor Shapes
- torch.*_like(x): 주어진 텐서(x)와 동일한 크기(shape)와 데이터 타입(dtype)을 가지는 새로운 텐서를 생성하는 함수 (*함수로 생성)
2. Datasets and DataLoaders
import os
import pandas as pd
from torchvision.io import read_image
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
# Dataset 개체를 인스턴스화할 때 한 번 실행 / 이미지, 주석 파일 및 두 변환을 모두 포함하는 디렉터리를 초기화
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
# 데이터 세트의 샘플 수를 반환
return len(self.img_labels)
def __getitem__(self, idx):
# 지정된 인덱스의 데이터 세트에서 샘플을 로드하고 반환
'''
인덱스를 기반으로 디스크에서 이미지의 위치를 식별하고 이를 사용하여 텐서로 변환하고
read_image의 csv 데이터에서 해당 레이블을 검색하고
self.img_label의 변환 함수를 호출하고(해당하는 경우에) 텐서 이미지와 해당 레이블을 반환
'''
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label3. Transforms
ToTensor()
-
torchvision.transforms 모듈에서 제공되는 변환(transform) 중 하나
→ 이미지나 PIL 이미지 객체를 Pytorch 텐서로 변환하는 역할을 함 -
FashionMNIST의 PIL 이미지 객체를 one-hot encoded tensors로 변경
import torch from torchvision import datasets from torchvision.transforms import ToTensor, Lambda ds = datasets.FashionMNIST( root="data", train=True, download=True, transform=ToTensor(), target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=1)) )
Lambda Transforms
- 임의의 함수를 정의하고, 해당 함수를 데이터에 적용하여 변환할 수 있다.
→ 이를 통해 데이터에 대한 사용자 지정 전처리 또는 변환 작업을 수행할 수 있다.
target_transform = Lambda(lambda y: torch.zeros(
10, dtype=torch.float).scatter_(dim=0, index=torch.tensor(y), value=1))
'''
정수를 원핫 인코딩된 텐서로 바꾸는 함수를 정의
데이터 셋 label의 개수인 크기 10짜리 zero tensor을 만들고 scatter_을 호출하여 정답 y에 해당하는 인덱스에 value=1을 할당
'''4. Build Model
- 신경망은 데이터에 대한 연산을 수행하는 계층(layer)과 모듈(module)로 구성되어 있다. → Pytorch에서는 torch.nn이 제공한다.
- Pytorch의 모든 모듈은 nn.Module의 하위 클래스이다.
Define the Class
-
신경망 모델을 nn.Module의 하위 클래스로 정의하고, __init__에서 신경망 계층을 초기화한다. nn.Module을 상속받은 모든 클래스는 forward 메소드에 입력 데이터에 대한 연산들을 구현한다.
class NeuralNetwork(nn.Module): def __init__(self): super().__init__() self.flatten = nn.Flatten() self.linear_relu_stack = nn.Sequential( nn.Linear(28*28, 512), nn.ReLU(), nn.Linear(512, 512), nn.ReLU(), nn.Linear(512, 10), ) def forward(self, x): # 입력데이터의 일부는 백그라운드 연산들과 함께 모델의 forward를 실행한다. → model.forward() 직접 호출 x x = self.flatten(x) logits = self.linear_relu_stack(x) return logits
Model Layers
- nn.Flatten: 차원 텐서를 1차원으로 평탄화(flatten)하는 역할을 한다. → 주로 신경망 모델의 첫번째 레이어로 사용됨
nn.Flatten 공식문서 - nn.Linear: 선형 변환(linear transformation)을 수행하는 레이어를 구성하는 역할을 한다. → 입력 텐서와 가중치(weight) 행렬 간의 선형 연산을 수행하고, 선택적으로 편향(bias)을 더하는 작업을 수행한다.
nn.Linear 공식문서 - nn.ReLU: ReLU(Rectified Linear Unit) 활성화 함수를 구현한 레이어
nn.ReLU 공식문서 - nn.Sequential: 여러 개의 nn.Module을 순차적으로 연결하여 신경망 모델을 구성하는 데 사용 → 간단한 순차적 모델을 빠르게 구성할 수 있다.
nn.Sequential 공식문서 - nn.Softmax: Softmax 함수(다중 클래스 분류 문제에서 확률값을 계산하기 위해 주로 사용되는 활성화 함수)를 구현한 레이어
- Softmax 함수: 입력 벡터의 각 요소를 0과 1 사이의 값으로 변환하여 전체 합이 1이 되도록 정규화
→ 주로 다중 클래스 분류 문제에서 모델의 출력을 확률 분포로 표현하기 위해 사용
nn.Softmax 공식문서
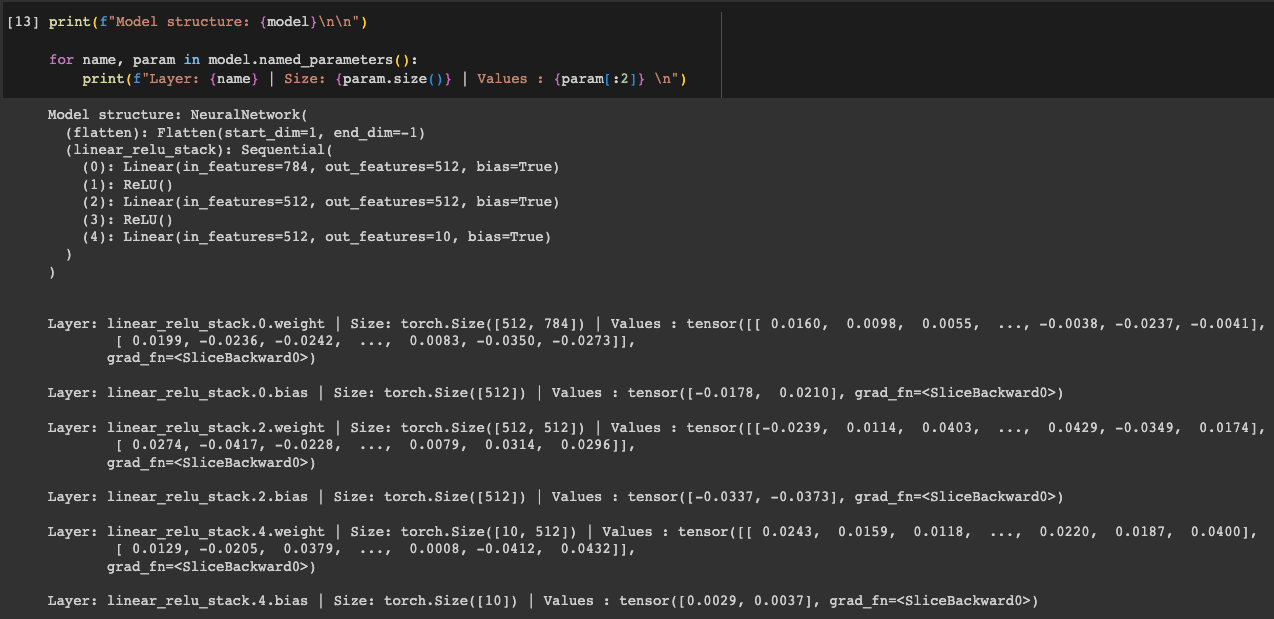
Model Parameters
- 신경망 내부의 많은 계층들은 매개변수화(parameterize)된다.
→ 학습 중에 최적화되는 가중치와 편향과 연관지어진다. - nn.Module 을 상속하면 모델 객체 내부의 모든 필드들이 자동으로 추적(track)되며, 모델의 parameters() 및 named_parameters() 메소드로 모든 매개변수에 접근할 수 있다.
5. Automatic Differentiation with torch.autograd
- 신경망을 학습할 때 가장 자주 사용되는 알고리즘은 back propagation(역전파)이다. 이 알고리즘에서, 매개변수(모델 가중치)는 주어진 매개변수에 대한 손실 함수의 변화도(gradient)에 따라 조정된다.
→ 이러한 변화도를 계산하기 위해 PyTorch에는 torch.autograd라고 불리는 자동 미분 엔진이 내장되어 있다.
Tensors, Functions and Computational graph
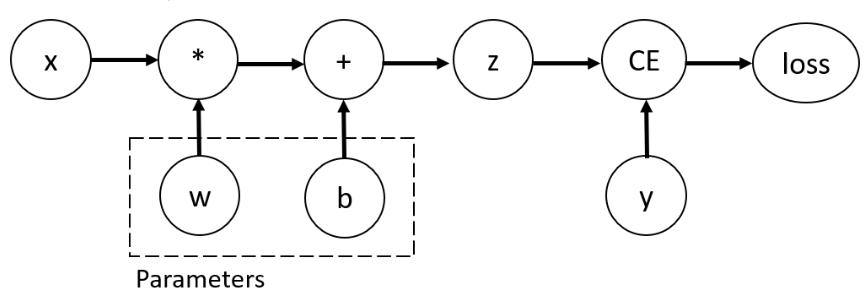
- 이 신경망에서 w와 b는 최적화를 해야 하는 매개변수이다. 따라서 이러한 변수들에 대한 손실 함수의 변화도를 계산할 수 있어야 하고 이를 위해 해당 텐서에 requires_grad 속성을 설정한다.
Computing Gradients
- 매개변수의 가중치를 최적화하려면 매개변수에 대한 손실함수의 도함수를 계산해야한다. 이러한 값을 계산하기 위해 loss를 w와 b로 나눈 값이 필요하다.
(성능 상의 이유로 주어진 그래프에서의 backward를 사용한 변화도 계산은 한 번만 수행할 수 있다. 만약 동일한 그래프에서 여러번의 backward 호출이 필요하면 backward 호출 시에 retrain_graph=True를 전달해야 한다.)
Disabling Gradient Tracking
- torch.no_grad()를 통해 연산 추적을 멈춘다. (혹은 detach() 사용)
→ 이러한 추적을 멈춰야 하는 이유
1. 신경망의 일부 매개변수를 고정된 매개변수(frozen parameter)로 표시하기 위해
2. 연산 속도 향상
More on Computational Graphs
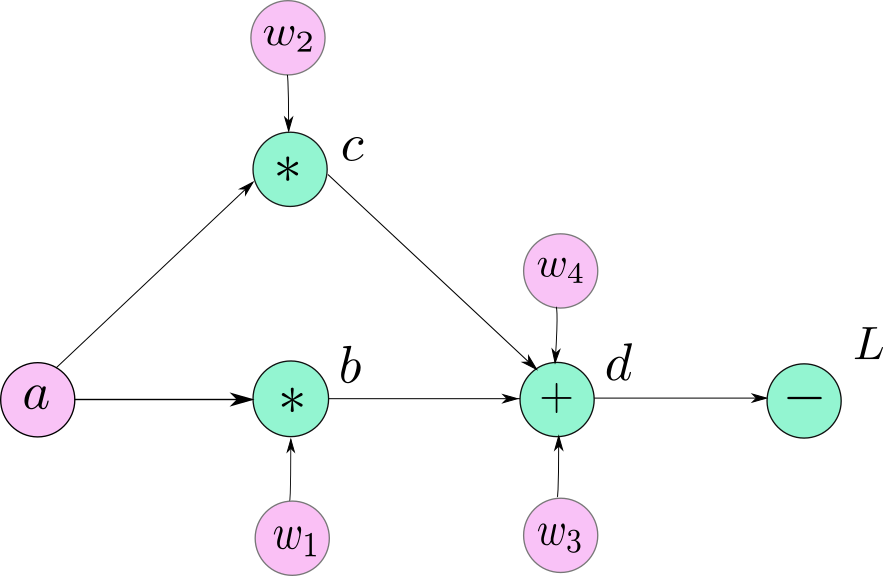
- autograd를 사용한 모든 데이터와 연산은 기록을 Function 객체로 구성된 방향성 비순환 그래프(DAG; Directed Acyclic Graph)에 저장한다.
→ 잎(leave)은 입력 텐서이고, 뿌리(root)는 결과 텐서이다. (아래의 예시에서 a, w1, w2, w3, w4는 잎, L이 뿌리)
6. Optimization Loop
- 모델을 학습하는 과정
1. 모델은 출력을 추측
2. 추측과 정답 사이의 오류(손실(loss))를 계산
3. 매개변수에 대한 오류의 도함수(derivative)를 수집한 뒤
4. 경사하강법을 사용하여 이 파라미터들을 최적화(optimize)
→ 이 과정을 반복한다.
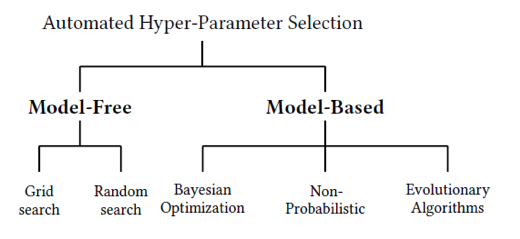
Hyperparameters
- 모델 최적화 과정을 제어할 수 있는 조절 가능한 매개변수 (모델 학습전에 미리 조정)
→ 에폭(epoch) 수, 배치 크기(batch size), 학습률(learning rate) 정의 등 - 하이퍼파라미터 튜닝: 모델을 최적화하기위해 하이퍼파라미터를 조정하는 과정
Manual Search, Grid Search, Random Search, Bayesian Optimization 등 여러가지 방법이 있음.
Optimizer
- 각 학습 단계에서 모델의 오류를 줄이기 위해 모델 매개변수를 조정하는 과정
-
SGD: Gradient Descent와 수식은 동일하나 업데이트 방식이 다르다.
- 매 batch마다 cost function으로 계산하여 업데이트하는 방식
→ 속도가 느린 GD를 개선하기 위해서 만들었다
단점: 학습 방향이 너무 급격하게 변한다. / 하나의 parameter(learning rate)에 너무 의존적이다.
- 매 batch마다 cost function으로 계산하여 업데이트하는 방식
-
Momentum Optimizer
-
SGD에서 발생하는 문제점을 해결하기 위해 개발된 기술
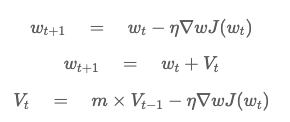
-
이전에 사용했던 미분값을 추가로 더해줌으로써 이전 step에서 미분값이 컸다면 큰값을 업데이트해주며, 미분값이 작다면 작은값을 업데이트
→ 이전에 사용했던 미분값을 사용하여 미분값을 업데이트하여, 함수의 기울기가 급격하게 변한다 하더라도 이전에 계산해놓은 값으로 인해, local minimum에 빠질 확률이 줄어든다.
-
-
Root Mean Square Propagation Optimizer
- 학습데이터의 양이 많고 적절한 성능까지 많은 학습을 요한다면 오히려 마지막은 학습이 진행되지 않을 수 있다는 단점을 보완하기 위하여 고안됨.
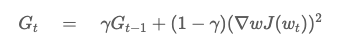
- learning rate term에서 기존의 미분텀과 업데이트될 미분텀의 영향을 분산하며 과거의 정보는 다소 적게 반영하여 최신의 정보는 강하게 반영하여 현재의 상황을 보면서 학습하는 방식
- 학습데이터의 양이 많고 적절한 성능까지 많은 학습을 요한다면 오히려 마지막은 학습이 진행되지 않을 수 있다는 단점을 보완하기 위하여 고안됨.
-
Adam = Adaptive Momentum Optimizer
- Momentum 과 Root Mean Square Propagation의 혼합 모델
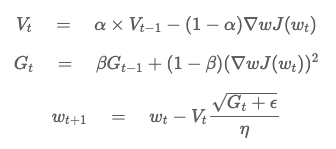
- momentum(V), learning rate(G) term을 각각 계산해서, learning rate를 step마다 계산하며 동시에 momentum값을 구하여 parameter를 update한다.
- Momentum 과 Root Mean Square Propagation의 혼합 모델

Master's Student @ KU👩🏻🎓