Spring
1.Error:java: error: release version 5 not supported 해결 방법 (IntelliJ, Maven)

스프링 ORM 강의를 들으면서 프로젝트 작동 중 발생했던 문제:Intellij의 Preferences -> Build, Execution, Deployment -> Compilter -> Java Compiler 에서 프로젝트 모듈의 타겟 버전을 확인해보니Java 모듈
2.HHH000206: hibernate.properties not found 오류 해결기

JPA를 공부하던 중 만나게 된 HHH000206: hibernate.properties not found 문구는 처음 맞이하였기 때문에 기록을 남겨보았습니다. JDK 11Hibernate 5.4.13 FinalH2 2.1.212JDK 8Hibernate 5.6.4.
3.nested exception is org.hibernate.AnnotationException: Use of @OneToMany or @ManyToMany targeting an unmapped class:
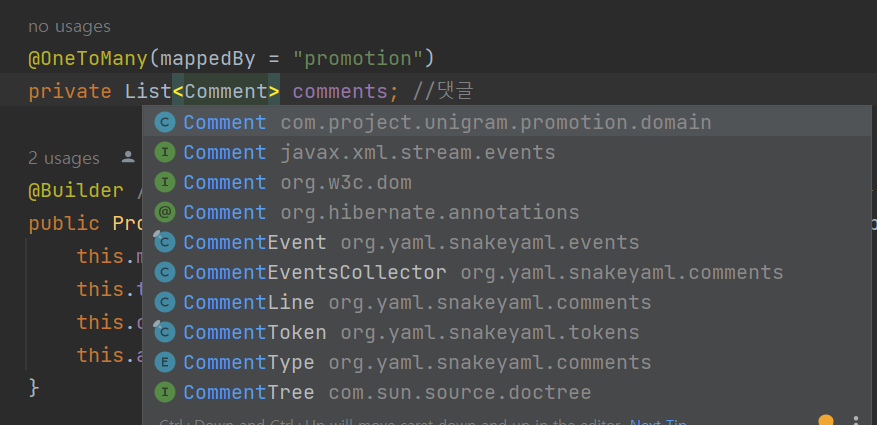
구글링을 해보니 애노테이션들을 확인해서 고쳐주어야 한다는 내용이었습니다. 당시 Comment 엔티티 클래스를 생성해서 만드는 중이어서 매핑 관계를 설정하고 있었는데 실행이 안되니 막막했는데 바로 찾았습니다Comment라는 같은 이름의 인터페이스로 임포트하니 계속해서
4.개발에서 자주 사용되는 Lombok 어노테이션 - 생성자
Lombok에서는 생성자를 자동으로 생성해주는 어노테이션을 사용할 수 있습니다. @NoArgsConstructor 은 파라미터 없는 기본 생성자를 생성합니다.@AllArgsConstructor 은 모든 필드 값을 파라미터로 받는 생성자를 생성합니다.@RequiredAr
5.[Spring] 트러블 슈팅 - FOREIGN KEY 삭제 관련
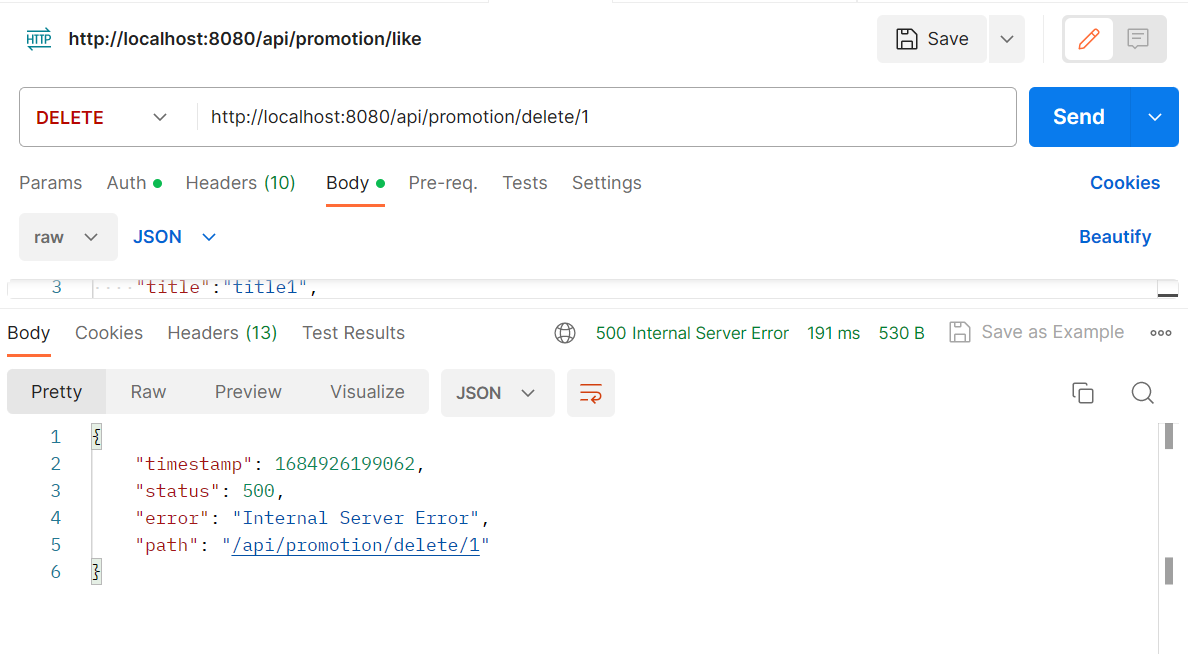
Promotion 엔티티와 Likes 엔티티는 1대 N의 관계를 가지며 단방향의 관계를 가지도록 설계하였습니다. 특히 DB에서 PROMOTION 테이블이 삭제되면 마찬가지로 LIKES 테이블 정보도 삭제되어야 합니다. 따라서, @OnDelete(action = OnDe
6.[스프링] MVC - 웹 애플리케이션의 이해
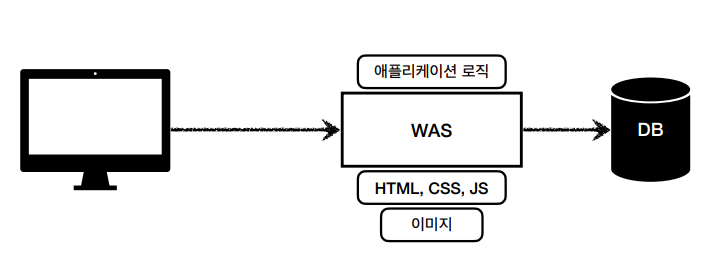
다음은 모두 HTTP 기반으로 동작합니다.http 프로토콜로 주고 받을 수 있는 것을 웹 서버라고 하며 http 기반으로 동작합니다사용자에 따라서 다른 화면들을 보여줄 수 있습니다동적 html, http api(rest api) 등을 제공할 수 있습니다서블릿, jsp,
7.[자바 JPA 표준] 영속성 컨텍스트 - JPA 소개
ORMObject-relational-mapping이다. 매핑이란 중간에서 무언가를 해준다는 의미ORM 프레임워크가 중간에서 다른 부분을 매핑해준다는 것으로, 패러다임 일치를 도와준다.JPA자바 애플리케이션과 JDBC API 사이에 위치, 동작한다.동작 종류저장'회원
8.[자바 JPA 표준] 영속성 컨텍스 프로젝트 생성
데이터베이스 방언JPA는 특정 데이터 베이스에 종속적이지 않다. 각 db마다 sql 문법 및 함수가 조금씩 다른데, 이러한 특정 db 만의 고유한 기능을 방언이라고 한다.\-dialect 라는 db를 persistance.xml에 등록해놓으면, h2 db를 사용한다고
9.[자바 JPA 표준] 영속성 컨텍스 - 영속성 컨텍스트 속성
엔티티 매니저 팩토리와 엔티티 매니저엔티티 메니저 팩토리에서 고객의 요청이 오면 EntityManager를 각각 생성하고, 엔티티 매니저가 db 커넥션을 사용하게 된다.영속성 컨텍스트(JPA를 이해하는데 가장 중요 용어)'엔티티를 영구 저장하는 환경'이라는 뜻을 가진다
10.[스프링 JPA] - 데이터베이스 기본 키 매핑과 전략
@Entity : JPA가 관리하는 클래스이다. JPA를 사용해서 테이블과 매핑할 클래스는 @Entity가 필수이다.주의 : 기본 생성자 필수(파라미터가 없는 public/protected 생성자) 애플리케이션 실행시점에 DDL을 자동으로 생성되도록 할 수 있다. 필
11.[스프링 JPA ] - 연관관계 매핑의 기초
목표 : 객체의 참조와 테이블의 외래키(나와 연관된 테이블을 찾는다.)가 어떻게 매핑되는 지를 탐구연관관계의 주인 : 객체 양방향 연관관계를 관리하는 주체예제) 회원과 팀이 있고, 회원은 하나의 팀에만 소속될 수 있으며, 회원과 팀은 다대일 관계객체의 참조와 db 외
12.[스프링 JPA] - N+1 문제
JPA를 사용함에 따라 여러 번의 SELECT문이 여러 개가 나갈 수 있다는 문제점이러한 현상을 N+1 문제라고 한다.왜 이러한 문제가 발생하는지실무에서 어떤 식으로 해결을 하는지연관관계인 엔티티 조회를 할 경우 조회된 데이터 갯수(N)만큼 조회쿼리가 추가로 발생해 데
13.[스프링 JPA] 다양한 연관관계
다중성단방향, 양방향연관관계의 주인다대일, 일대다, 일대일, 다대다가 있다. 테이블 외래키 하나로 양쪽 조인이 가능하며 두 테이블이 연관관계를 맺는다. 테이블에서는 방향이라는 개념이 없다.객체 참조용 필드가 있는 쪽으로만 참조가능, 한쪽만 참조하면 단방향, 서로 참조하
14.[스프링 JPA] - 상속관계 매핑
상속관계 매핑@MappedSuperclass객체에는 상속관계가 있으나, 관계형 데이터베이스는 상속관계가 없다. 슈퍼타입 서브타입 관계라는 모델링 기법이 객체 상속과 유사하다.슈퍼타입 서브타입 논리모델 -> 물리모델로 구현하는 방법@Inheritance(strategy=
15.[스프링 JPA] - 복합키 구성
지켜야 할 사항- 공통Serializable을 implementsequal, hashCode 메서드 구현(lombok 활용 가능): @EqualsAndHashCode(onlyExplicitlyIncluded = true) - 클래스에 작성@EqualsAndHashCod
16.[스프링 JPA] - 프록시와 로딩
프록시즉시로딩과 지연로딩지연로딩 활용영속성 전이 :CASCADE고아 객체실전예제em.find() vs em.getReference()를 비교해보면,em.find() : 데이터베이스를 통해 실제 엔티티 객체를 조회, sql 쿼리문이 나간다.em.getReference()
17.[스프링 JPA] - 값 타입
기본값 타입임베디드 타입(복합 값 타입)값 타입과 불변 객체값 타입의 비교값 타입 컬렉션실전 예제 - 6. 값 타입 매핑크게 엔티티타입과 값 타입으로 나뉜다.1) 엔티티 타입@Entity로 정의하는 객체데이터가 변해도 식별자로 지속해서 추적 가능예) 회원 엔티티의 키나
18.[스프링 JPA] - JPQL/네이티브 SQL/QueryDSL 등
JPQLJPA CriteriaQueryDSL네이티브 SQL가장 단순한 조회 방법JPA를 사용하면 엔티티 객체를 중심으로 개발검색을 할 때도 테이블이 아닌 엔티티 객체를 대상으로 검색SQL과 문법 유사, SELECT, FROM, WHERE, GROUP BY, HAVING
19.[스프링 JPA] - JPQL 기본 및 심
경로 표현식이란? .(점)을 찍어 객체 그래프를 탐색하는 것경로 표현식 용어정리상태 필드(state field): 단순히 값을 저장하기 위한 필드(ex: m.username)연관 필드(association field): 연관관계를 위한 필드단일 값 연관 필드: @Man
20.[스프링 JPA] - 조인
01 Fetch Join, Join의 차이점 및 일반조인으로 n+1문제를 해결하지 못하는 이유02 JPQL과 영속성 컨텍스트 자세히 알기03 Spring Jpa에서 더티 체킹이란?1 일반 Join Fetch Join과 달리 연관 Entity에 Join을 걸어도 오직 J
21.[Spring 잘 사용하기] @Transactional에 대하여
스프링에서는 트랜잭션 처리를 위하여 선언적 트랜잭션을 사용한다고 한다.선언적 트랜잭션은 1) 설정 파일 2) 어노테이션 이 2가지 방식으로 트랜잭션에 관하여 정의할 수 있다. 선언적 트랜잭션의 1) 사용방법 및 2) 동작원리와 3) 주의할 점에 대하여 살펴보면 다음과
22.[스프링] 웹 개발과 활용1,2 편
외래키가 있는 곳을 연관관계의 주인으로 정한다. 연관관계의 주인은 단순히 외래키를 누가 관리하냐의 문제일 뿐이다. 실무에서는 조회할 일이 많으므로 Getter를 모두 열어두는 것이 편리하다. Getter는 아무리 호출해도 호출하는 것만으로 어떠한 일이 발생하지 않기 때
23.[스프링과 JPA활용 2편] 요약 정리1
API 패키지를 생성API를 작성하는 곳과 화면을 렌더링하고 화면관련된 일을 하는 곳은 분리되어야 한다.MemberApiController 생성어노테이션 설정api 관련 컨트롤러는 @Controller와 @ResponseBody, @RequiredArgsConstruc
24.[스프링과 JPA활용 2편] 요약 정리2
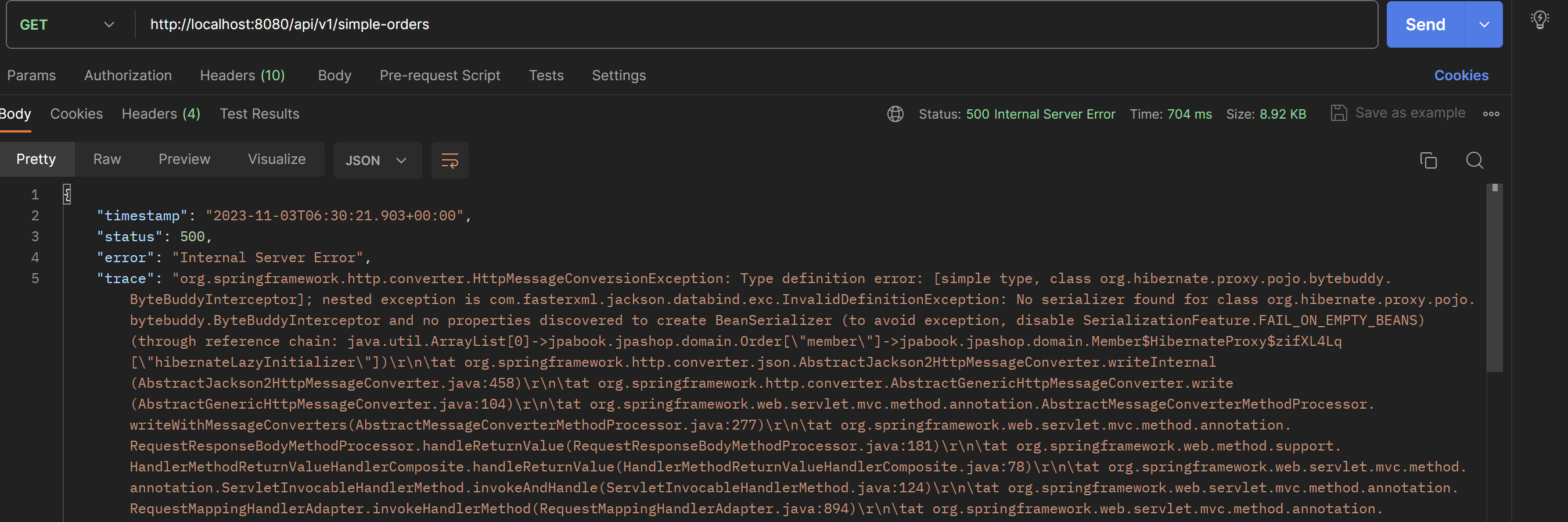
주문, 배송정보, 회원을 조회하는 API를 만들어 볼 것이다. 지연로딩으로 발생하는 성능문제를 단계적으로 해결해본다.참고::지금부터 설명하는 내용은 정말 중요하며, JPA를 실무에서 사용하려면 100%이해해야한다. 현재 Order에 대한 리스트만 출력하려고 했는데, O
25.[스프링과 JPA활용 2편] 요약 정리3
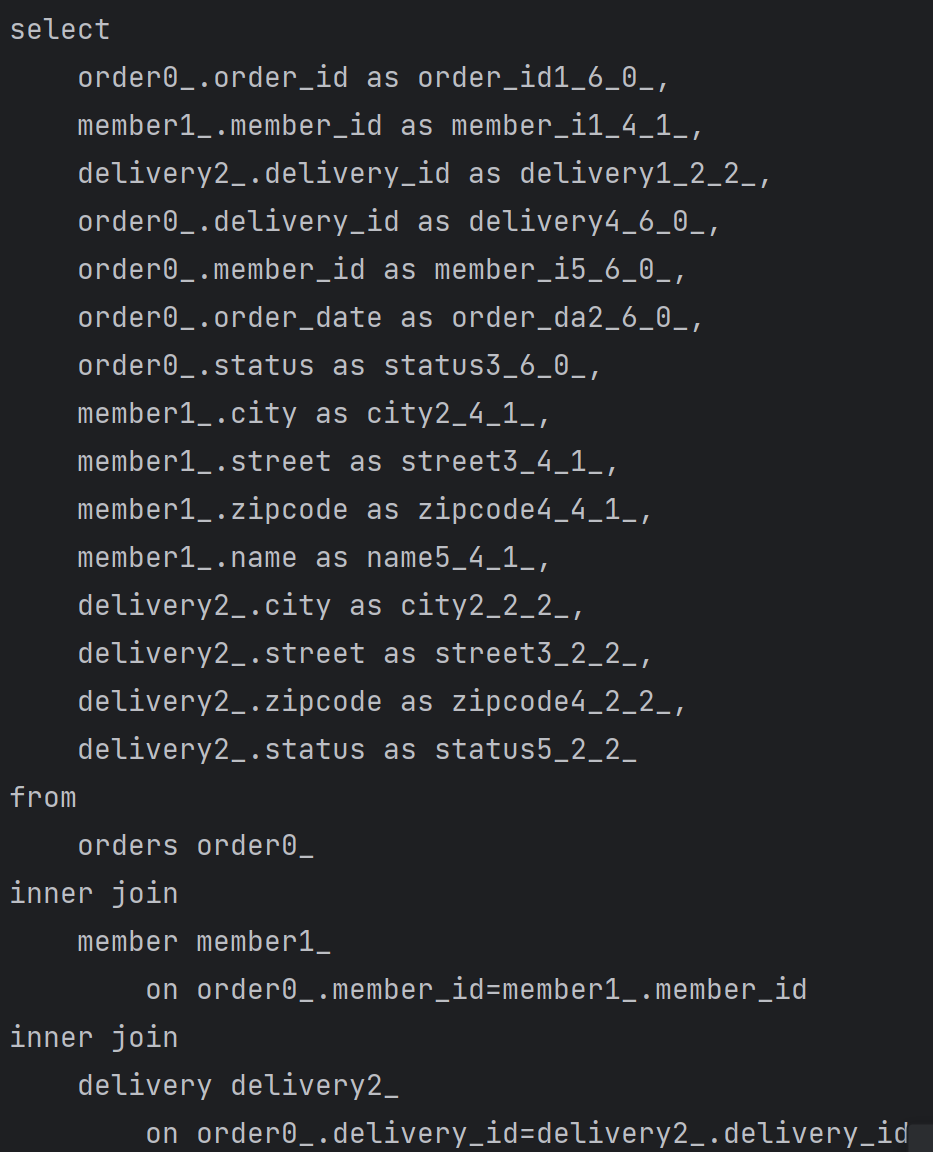
api controllerrepository엔티티를 페치조인하여 쿼리 1번으로 조회하게 되고 이미 이렇게 select로 모두 조회하므로 지연로딩으로 인한 추가적인 쿼리문이 발생하지 않게 된다.사진에서 보다시피 모든 필드를 조회해오기 때문에 아주 약간의 성능문제가 발생할
26.[스프링과 JPA활용 2편] 요약 정리4
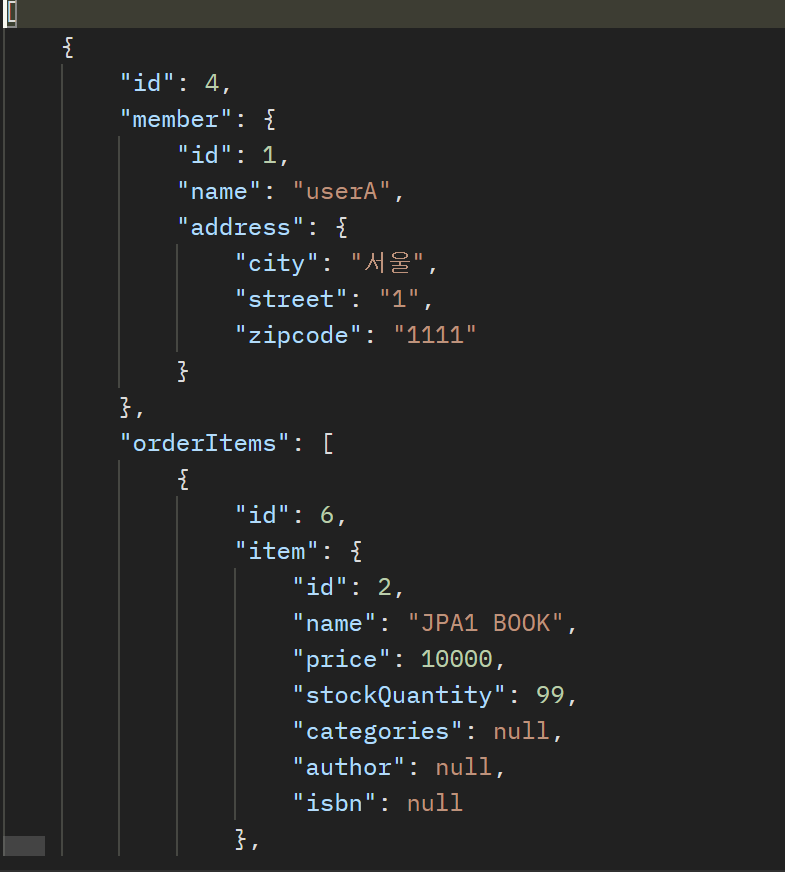
일대다 조회가 되면, 조인할때 데이터 뻥튀기가 되어버린다.ToOne인 경우는 모두 fetch join을 하거나 inner join을 하면 최적화가 가능했었다@XToOne 조회 최적화 확인하러 가기컬렉션 조회인 경우는 다쪽에 데이터가 많아져서 최적화가 힘들다. 따라서 컬
27.[스프링과 JPA활용 2편] 요약 정리5
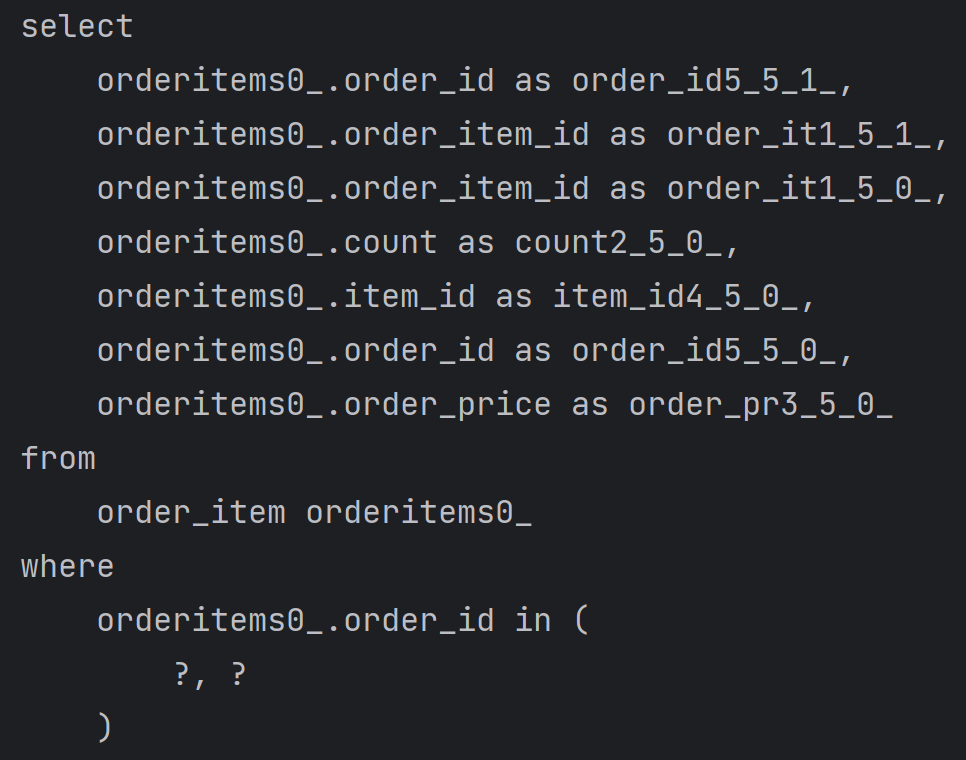
컬렉션을 페치조인하면 페이징이 불가능하다.컬렉션을 페치조인시 일대다 조인이 발생하여 데이터 뻥튀기가 발생하며 예측할 수 없이 쿼리가 증가하게 되는걸 경험할 수 있다. 일대다에서 일(1) 기준으로 페이징을 하는 것을 목적으로 하지만, 데이터는 다(N)기준으로 row가 생
28.[스프링과 JPA활용 2편] 요약 정리6
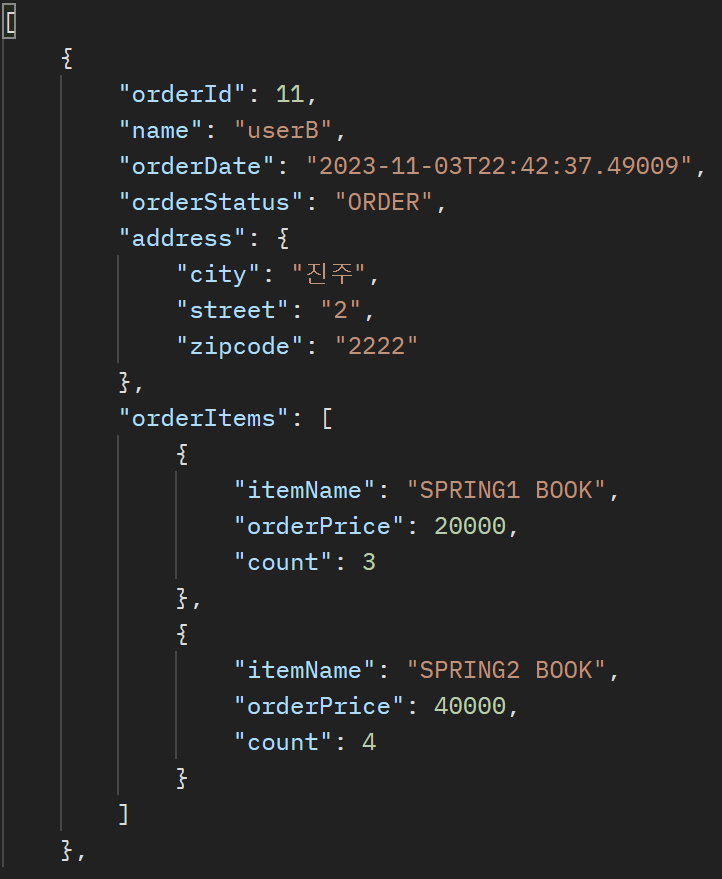
주문 조회 V4: JPA에서 DTO 직접 조회 api controller query repository OrderItemQueryDto OrderQueryDto 위 코드의 V4의 문제는 Query 루트 1번이 실행이 되고 추가적으로 컬렉션을 도는 코드로 인해
29.[스프링과 JPA활용 2편] API 개발 中 컬렉션 조회 정리
컬렉션 조회의 종류에는 엔티티로 조회하는 경우와 DTO로 직접 조회하는 경우로 나뉜다.이전까지 작성했던 블로그 글을 살펴보면엔티티를 조회해서 그대로 반환(V1)엔티티를 조회해서 DTO로 변환(V2)페치조인으로 쿼리수 최적화(V3)컬렉션 페이징과 한계 돌파(V3.1) \
30.[스프링과 JPA활용 2편] 실무 필수 최적화(OSIV)

일반적으로 스프링 어플리케이션을 동작시키면 로그 중에 이런 warn으로 나오는 open-in-view와 관련된 경고메세지가 뜬다. WARN 17736 --- \[ restartedMain] JpaBaseConfiguration$JpaWebConfiguration
31.[스프링 데이터 JPA] 중요 요약본

이 어노테이션을 활용하게 되면 같은 트랜잭션 안에 있는 동작들에 대해서 엔티티의 동일성을 보장하게 된다. 따라서 테스트 클래스에서 테스트를 진행할 경우에도 find로 엔티티를 찾아와서 assertJ를 활용해 isEqualTo로 동일한지 확인을 하면 true로 동일하다는
32.[스프링 데이터 JPA] 중요 요약본 2

이 어노테이션 없이 추상 메서드를 작성하게 된다면 레포지토리의 일반적인 getResultList() 나 getSingleResult()로 인식해버리며 오류가 발생하게 된다. 순수 JPA 레포지토리로 벌크연산(수정)을 작성한 것을 spring data jpa로 바꾸는 과
33.[스프링부트 3.x + Querydsl 설정 세팅]

스프링부트 2버전과 3버전은 Querydsl 설정하는 방법이 다르다. 이중에서 이젠 스프링부트 3버전만 제작하는게 가능해졌으므로 스프링부트 3버전의 Querydsl 설정법만 작성해보았다. 이렇게 //주석처리된 부분 아랫내용들을 프로젝트 build.gradle에 붙여
34.[JPA] 올바른 JPA Entity와 @Builder 사용법

위 블로그에서는 해결방법을 다양하게 제시해준다. 의미있는 메서드로 생성한다.의도가 분명하지 않고 객체를 언제든지 변경할 수 있는 상태가 되므로 객체의 안전성이 보장받기 힘들다. 특히 @Setter 사용시 어디에서 언제 누구에 의해 변경되었는지 추적하기 어렵다. 따라서
35.[스프링 데이터 JPA] 페이징과 정렬

org.springframework.data.domain 패키지를 기준으로 스프링 Data JPA의 페이징과 정렬을 사용할 수 있다.페이징과 정렬 파라미터 Sort : 정렬 기능Pageable : 페이징 기능(내부에 Sort포함)특별한 반환 타입Page : 추가 cou
36.[스프링 데이터 JPA] Web확장된 페이징과 정렬 사용

스프링 Data JPA에서 제공하는 페이징과 정렬은 검색 리스트를 조회하는데에도 사용할 수 있다. 이렇게 API를 작성할때 Pageable을 파라미터로 받을 수 있다. 저번 포스트에서도 작성을 했었지만 Pageable은 인터페이스고 실제로는 PageRequest객체를
37.[스프링] form-data 형태로 이미지 + json API 구현 과정

파일 + json을 함께 스프링에서 함께 구현하는 방법 개요파일 + json을 이용해 form-data로 post 요청을 했음에도 성공하지 않는 경우\-> default value must not be null 과 같은 DTO @Valid가 작동했던 문제 해결@Requ
38.Spring boot에 caffeine cache 적용기

내가 프로젝트에서 진행하고 있는 내용은 토론 게시판 조회 api와 메인페이지상에서 추천 프로그램 api 가 포함되어있다. 이중에서 수정은 적지만 조회가 빈번하게 일어나는 서비스에 대해 캐싱을 적용해 성능을 최적화할 수 있다고 알게 되서 내 코드에도 적용해보려고 한다.
39.nGrinder를 이용해 스프링 어플리케이션 성능 측정기록 여정

성능 테스트 도구의 종류 Gatling 스칼라를 통해 테스트 스크립트를 생성하는 부하테스트 도구이며, 비동기식 아키텍쳐로 가상 사용자를 스레드가 아닌 메세지로 생성해 수천명의 동시 사용자를 재현할 수 있는 장점이 있다. 그러나, 분산 테스트를 지원하지 않아서 다수의
40.delete 쿼리가 발생하지 않을때

프론트엔드분께서 대댓글 delete 요청이 안되는 것 같다고 의견을 주셨다. postman으로 확인해보니 삭제요청은 잘 되었다고 메세지가 뜨는데, 쿼리를 살펴보니 delete 쿼리는 나타나지 않았던 것이다.대댓글은 삭제하려는 Community, 부모 Reply가 테이블
41.좋아요 기능 데이터 정합성 맞추기

좋아요 동시요청해보면 200개의 쓰레드를 두 개의 서버에서 동시에 요청했으나 400개가 아닌 303개로 좋아요 수가 찍혔다. 이를 통해 트랜잭션 보장이 되지 않고있다는 결과를 알 수 있었다. 1. DB 락을 이용해서 맞춰보기
42.[자바 ORM표준 JPA 프로그래밍-기본편] JPA 소개
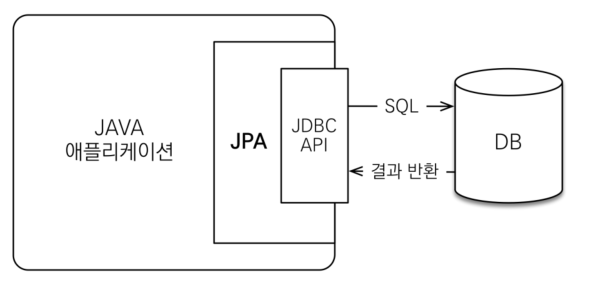
우선 애플리케이션은 객체지향적이고 데이터베이스는 관계형 DB를 사용한다는 점에서 차이가 있다. 하지만 지금 시대는 객체를 관계형DB에서 관리한다는 점이 특징이다.여기서 발생하는 문제점은 SQL 중심적으로 개발한다는 점이다. CRUD와 같은 무한 반복, 지루한 코드를 작
43.[자바 ORM표준 JPA 프로그래밍-기본편] 영속성 관리- 내부동작 방식

JPA에서 가장 중요한 두 가지는 바로 설계-객체와 관계형 데이터베이스 매핑과 실제 동작-영속성 컨텍스트다. 엔티티 매니저 팩토리와 엔티티 매니저의 관계를 알아보자. 엔티티 매니저 팩토리에서는 새 고객의 요청이 올때마다 엔티티 매니저를 생성해서 트랜잭션 시작~요청 완료
44.[자바 ORM표준 JPA 프로그래밍-기본편] 엔티티 매핑
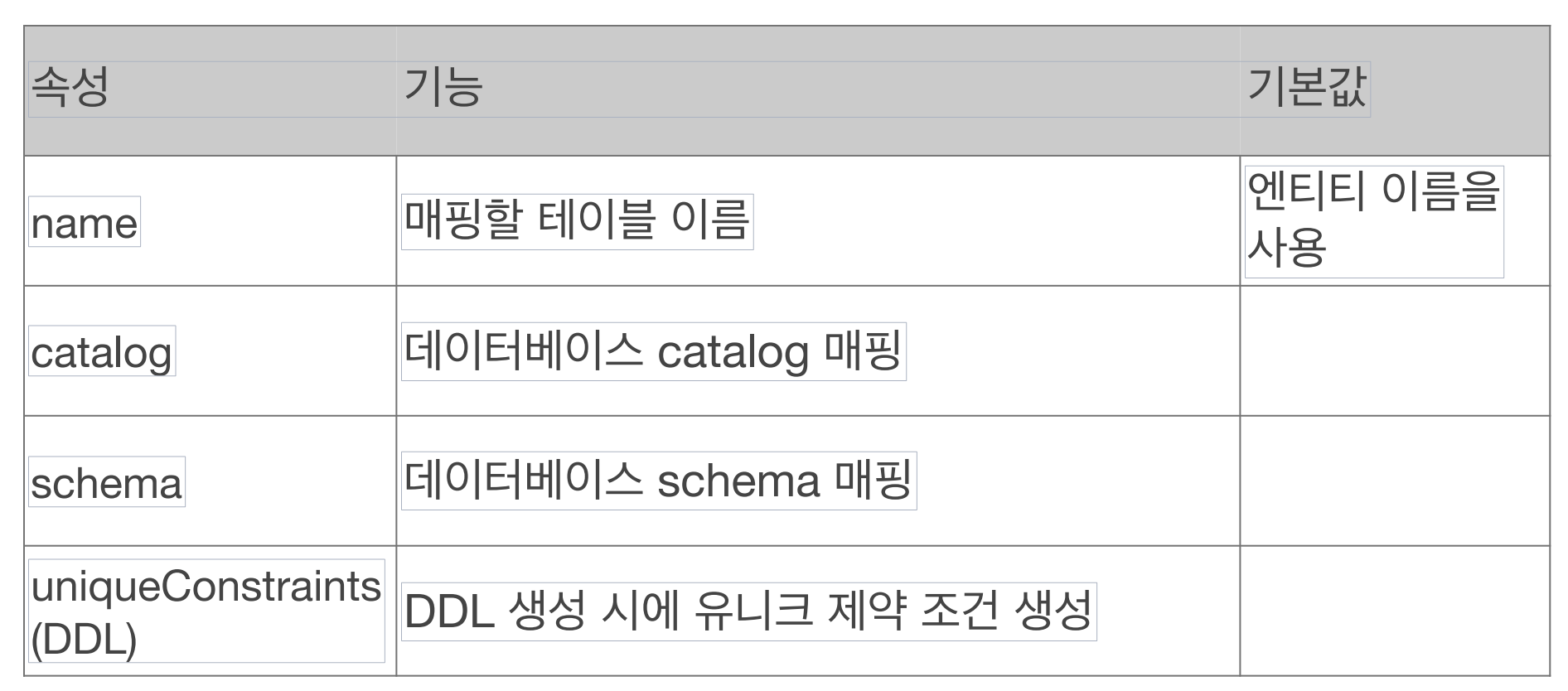
객체와 테이블 매핑시 @Entity로 JPA에서 관리할 엔티티를 class단에 선언해주고 @Table을 통해 실제 매핑하게 될 테이블명과 연결시켜줄 수 있다. 필드와 컬럼 매핑에는 @Column이 사용되는데 실제 매핑하게 될 테이블의 해당 컬럼명을 작성해주면 된다. 기
45.[자바 ORM표준 JPA 프로그래밍-기본편] 연관관계 매핑 기초
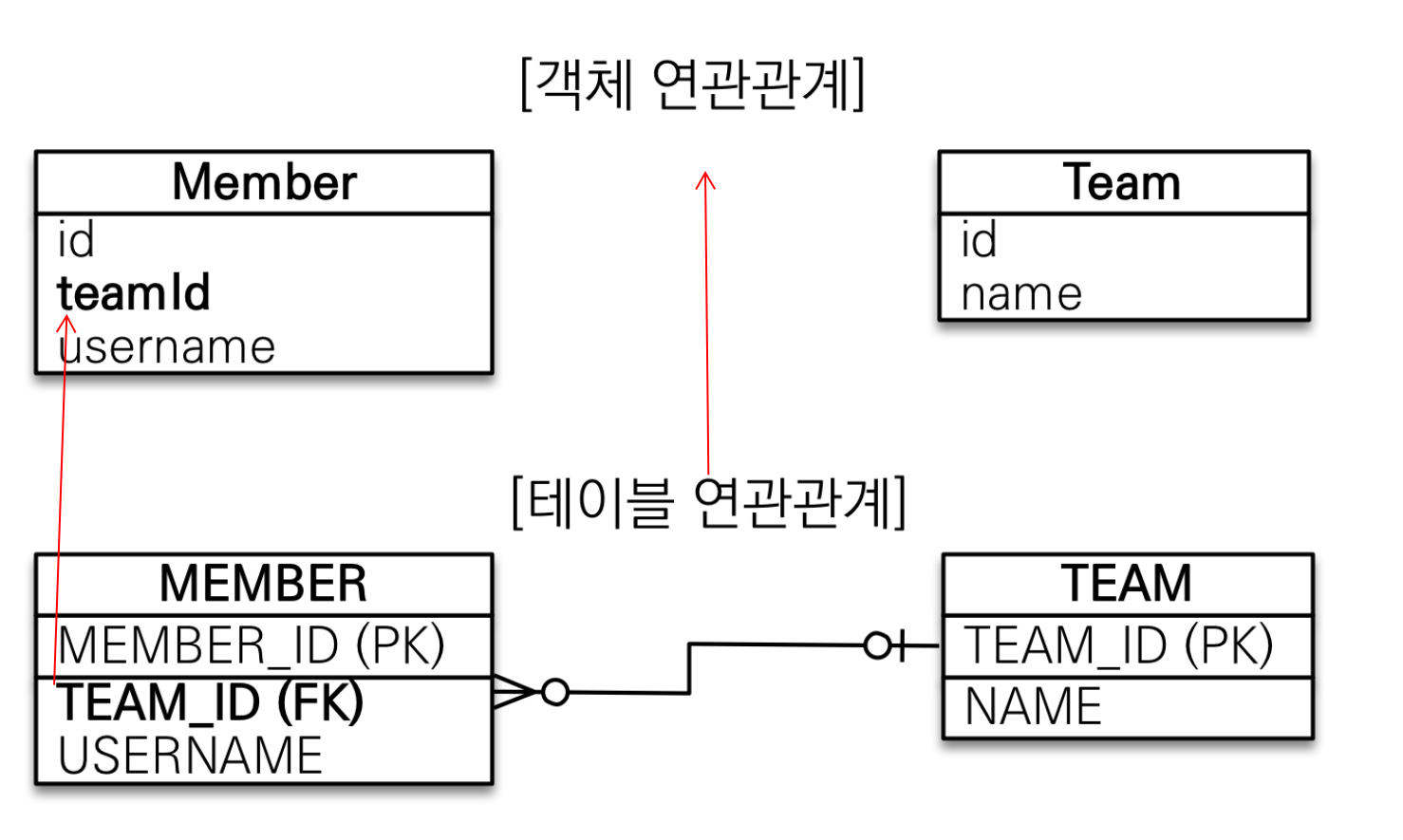
연관관계 매핑에 있어서 중요한 점은 1\. 객체의 참조와 테이블의 외래키를 매핑해야 한다는 점2\. 연관관계의 주인이 필요하다는 점(객체의 양방향 연관관계 설계시 관리주인을 설정해야한다)객체를 모델링한 테이블에 맞춰서 모델링한다고 생각해보자. 그러면 테이블의 외래키(F
46.[자바 ORM표준 JPA 프로그래밍-기본편] 다양한 연관관계 매핑
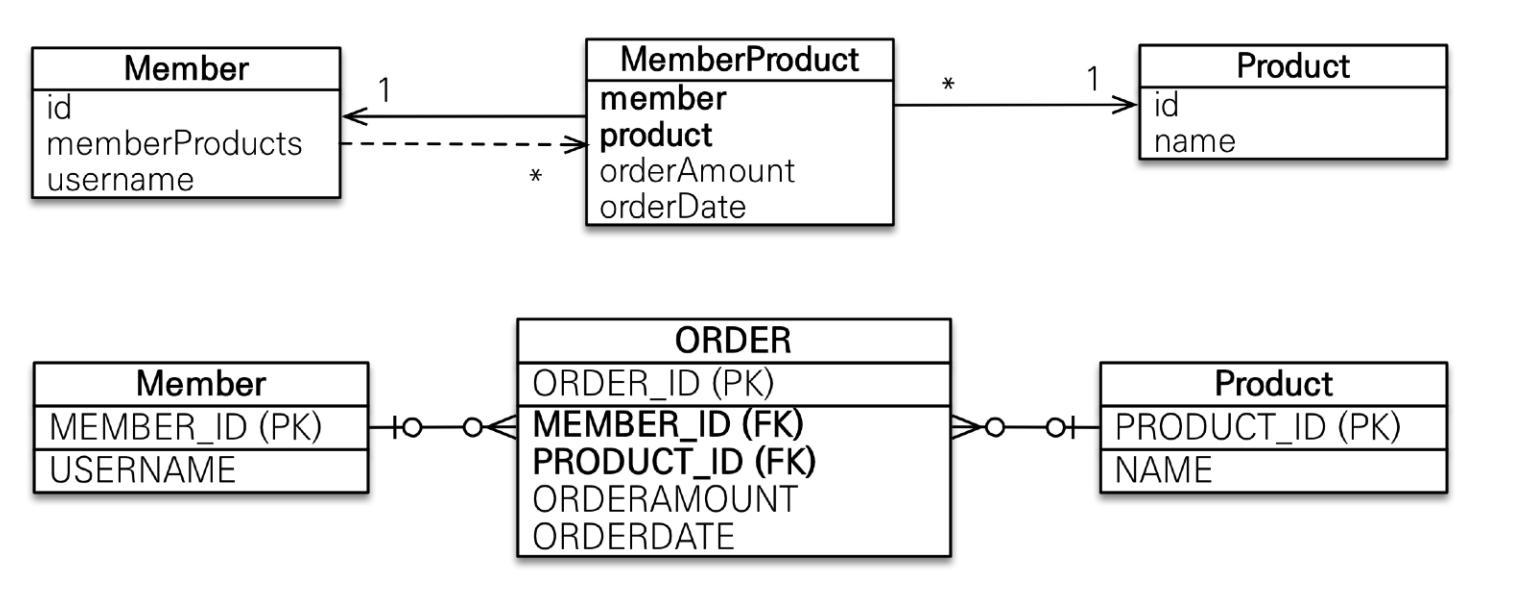
연관관계 매핑시 고려해야할 3가지는 다중성, 단방향-양방향, 연관관계의 주인이다.JPA에서 나온 어노테이션은 모두 데이터베이스와 매핑하기 위해서 나온 것이라고 믿으면 된다. 아래 3가지만 주로 사용한다.🔎 다대일 @ManyToOne🔎 일대다 @OneToMany🔎
47.[자바 ORM표준 JPA 프로그래밍-기본편] 고급매핑
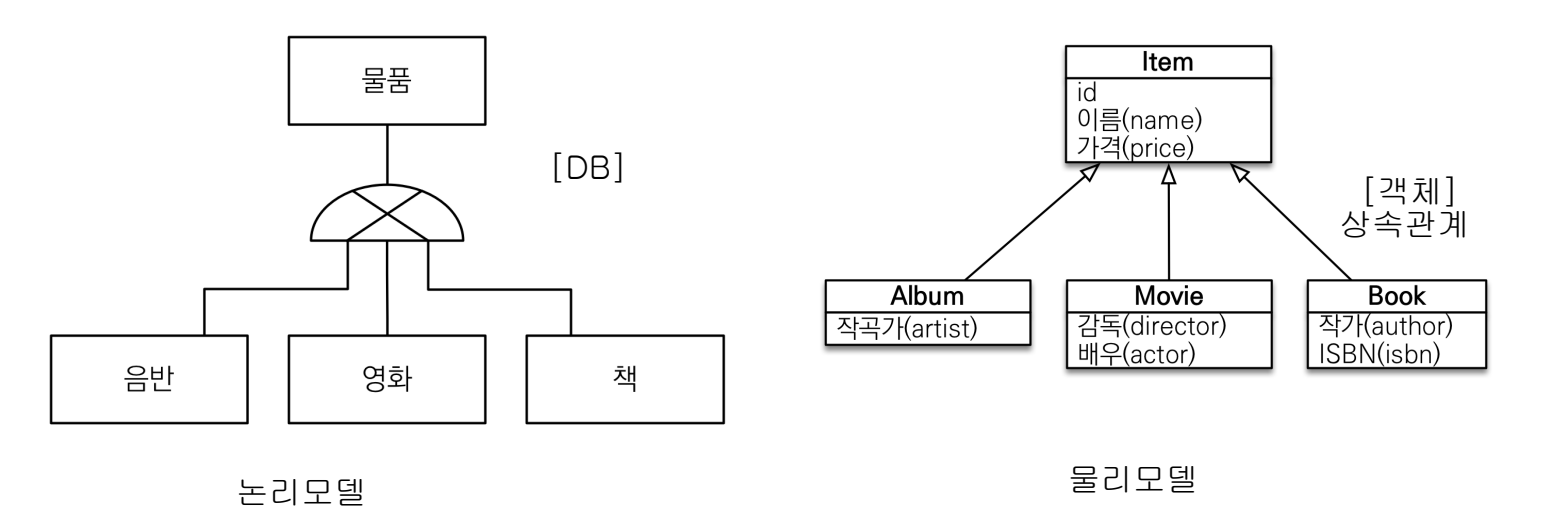
관계형 데이터베이스는 상속관계라는 말이 없고 대신에 슈퍼타입-서브타입이라는 관계라는 내용이 있다. 객체는 상속관계가 있는데, 그럼 테이블과 어떻게 매핑되어야 할까? 상속관계가 없기때문에 매핑하는 다양한 방법이 있다.슈퍼타입-서브타입인 테이블을 실제 물리모델 객체로 구현
48.[자바 ORM표준 JPA 프로그래밍-기본편] 프록시와 연관관계 관리
프록시 기초 em.find와 em.getReference()의 차이가 뭘까? em.find()는 엔티티 조회에 쓰이며, 1차 캐시에서 필요한 엔티티를 찾고 없다면 DB까지 가서 엔티티를 가지고 와 1차 캐시에 넣어둔다. em.getReference()도 조회에 쓰이지
49.[자바 ORM표준 JPA 프로그래밍-기본편] 값 타입
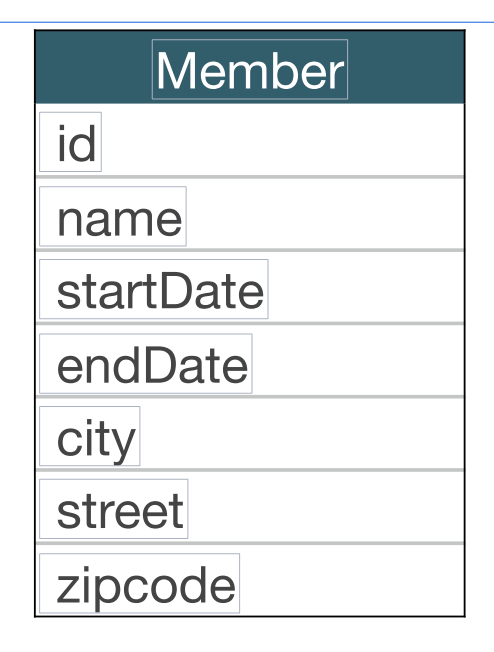
@Entity 어노테이션을 붙이는 객체로, 데이터가 변해도 id값처럼 식별자로 지속해서 추적이 가능하다. 예를들어, 회원의 키나 나이가 변경해도 색별자인 id=100은 변하지 않는 것처럼 id값으로 지속적인 객체 값 확인이 가능하다. int, Integer, Strin
50.[자바 ORM표준 JPA 프로그래밍-기본편] 객체지향 쿼리 언어(1/2)

JPA는 다양한 쿼리방법을 지원한다. JPQL, JPA Criteria, QueryDSL, 네이티브 SQL, JDBC API 직접 사용 및 Mybatis, SpringJdbcTemplate을 함께 사용하기도 한다. 여기서 Criteria와 QueryDSL은 자바코드로
51.[자바 ORM표준 JPA 프로그래밍-기본편] 객체지향 쿼리 언어(2/2)

JPQL - 경로 표현식 점을 찍어서 객체 그래프를 탐색하는 것을 경로표현식이라고 한다. 3가지 유형이 있다. (1) 상태 필드 : 인스턴스 변수를 탐색하는 것 (2) 단일 값 연관경로 : 다대일 관계에서 연관된 일쪽 엔티티로 탐색하는 것, 대상이 엔티티 selec