
Pandas란?
- 머신러닝과 딥러닝 분야의 데이터 분석 필수 라이브러리이다.
- 파이썬 언어로 데이터 분석을 쉽게 할 수 있는 데이터 구조와 기능을 제공한다.
- Pandas 기능으로 데이터 분석 과정 중 하나인 데이터 전터리를 쉽게 할 수 있다.
Pandas의 자료구조:
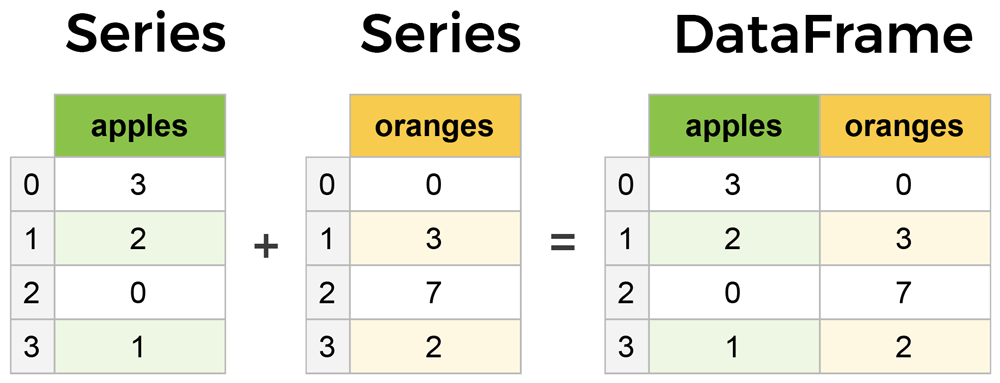
- Series: 1차원 Array 형태, 즉 하나의 열을 가진다.
- DataFrame: 2차원 Array 형태, 즉 1개 이상의 열을 가진다. Series를 여러 개 합친 것이 DataFrame이다.
Pandas 라이브러리
설치
!pip install pandas==1.5.3pandas는 pd라는 별칭으로 사용한다.
import pandas as pdSeries
- 인덱스 index와 값 value로 구성된다.
- 키 key와 값 value로 구성되는 딕셔너리와 형태가 유사하다.
- DataFrame에 대한 정보, 일부 데이터 또는 집계 결과가 시리즈 형태를 갖는 경우가 많다.
Series 생성
List로 Series 생성
series변수명 = pd.Series(list변수명)
List에서 series를 생성하고, 따로 index를 입력하지 않으면 자동으로 0부터 주어진다.
values = [200, 300, 400, 500]
series_1 = pd.Series(values)
print(series_1) # output is 0 200
# 1 300
# 2 400
# 3 500
# dtype: int64Dictionary로 Series 생성
series변수명 = pd.Series(dictionary변수명)
Dictionary로 series를 생성하면, dictionary의 key가 series의 index가 되고, dictionary의 value가 series의 value가 된다.
dict_stock = {'2019-02-15': 92300,
'2019-02-16': 94300,
'2019-02-17': 92100,
'2019-02-18': 92400,
'2019-02-19': 92600}
# Series 생성
stock_series = pd.Series(dict_stock)
print(stock_series)
# output is
# 2019-02-15 92300
# 2019-02-16 94300
# 2019-02-17 92100
# 2019-02-18 92400
# 2019-02-19 92600
# dtype: int64Series 확인 & 조작
index 조회
series변수명.index
# 딕셔너리 만들기
dict_stock = {'2019-02-15': 92300,
'2019-02-16': 94300,
'2019-02-17': 92100,
'2019-02-18': 92400,
'2019-02-19': 92600}
# 시리즈 만들기
stock = pd.Series(dict_stock)
# index 조회
stock.index
# output is Index(['2019-02-15', '2019-02-16', '2019-02-17', '2019-02-18', '2019-02-19'], dtype='object')index 변경
series변수명.index = 새로운 index list
Series의 index 속성을 새로운 list로 변경/치환할 수 있다.
단, series의 row개수와 새로운 list의 길이가 동일해야 한다.
new_index = ['2020-02-15', '2020-02-16', '2020-02-17', '2020-02-18', '2020-02-19']
# index 변경
stock.index = new_index
print(stock.index)
# output is Index(['2020-02-15', '2020-02-16', '2020-02-17', '2020-02-18', '2020-02-19'], dtype='object')index 초기화
series변수명.reset_index(drop = , inplace = )
index 초기화는 기존 index를 버리고, 0부터 순차적으로 증가하는 정수 index가 할당된다.
기존 index를 버릴지, 보존할지 여부는 parameter에 정의할 수 있다.
drop = True: 기존의 index를 버린다drop = False: 기존의 index를 보존한다inplace = True: 기존 series에 업데이트 한다inplace = False: display만하고 기존 series에 업데이트 안 한다
대개, 초기화(reset)와 버리기(drop) 등의 method에 inplace method가 있는 경우가 많고, inplace method는 대부분 update 여부를 결정하는 parameter다.
stock.reset_index(drop = True, inplace = True)데이터 타입 확인
series변수명.dtype
print(stock.dtype) # output is dtype('int64')데이터 타입 변경
series변수명.astype("변경 데이터타입")
# stock 시리즈의 데이터타입을 int로 변경
stock = stock.astype("int")모양 확인
series변수명.shape
series는 1차원 배열의 형태이므로, shape 확인 시 row의 개수 확인 가능
dict_stock = {'2019-02-15': 92300.0,
'2019-02-16': 94300.5,
'2019-02-17': 92100.0}
stock = pd.Series(dict_stock)
# 모양 확인
stock.shape # output is (3,)미리보기
series변수명.head() : 상위 5개행 미리보기
series변수명.tail() : 하위 5개행 미리보기
전체 data를 확인하기에 데이터 사이즈가 너무 클 경우, 일부분을 미리 확인할 수 있다. 함수 안에 정수값을 넣으면 5개행이 아닌 원하는 행개수만큼 미리보기 할 수 있다.
# 상위 7개행 미리보기
stock.head(7)
# 하위 4개행 미리보기
stock.tail(4)기초 통계 확인
series변수명.describe()
데이터를 다룰 떄는 기초 통계에 대한 정보가 매우 중요하다. 평균, 표준편차, 4분위값, 개수 등을 통계에서 확인 할 수 있다.
dates = ['2019-02-15', '2019-02-16','2019-02-17','2019-02-18','2019-02-19']
# series 생성
stock = pd.Series([92300, 94300, 92100, 92400, 92600], index=dates)
# 통계 확인
stock.describe()Data Handling
Data 조회
indexing
series변수명[index명]series변수명.loc[index명]: index명으로 조회하는 loc 방법series변수명.iloc[index번호]: index번호로 조회하는 iloc 방법
dates = ['2019-02-15', '2019-02-16','2019-02-17','2019-02-18','2019-02-19', '2019-02-20', '2019-02-21','2019-02-22','2019-02-23','2019-02-24']
stock = pd.Series([92300, 94300, 92100, 92400, 92600, 92300, 94300, 92100, 92400, 92600], index=dates)
# indexing
stock['2019-02-21'] # output is 94300
# loc indexing
stock.loc['2019-02-21'] # output is 94300
# iloc indexing
stock.iloc[6] # output is 94300slicing
series변수명[시작index명:끝index명]series변수명.loc[시작index명:끝index명]: index명으로 조회하는 loc 방법series변수명.iloc[시작index번호:끝index번호]: index번호로 조회하는 iloc 방법
- list의 slicing과 달리, 끝index명 자리의 value를 생략하지 않고 전부 가져온다.
- slicing을 하면 반환되는 데이터 타입은 다시 series이다.
# slicing
stock['2019-02-21': '2019-02-23'] # output is 2019-02-21 94300
# 2019-02-22 92100
# 2019-02-23 92400
# dtype: int64
# loc slicing
stock.loc['2019-02-21': '2019-02-23'] # output is 2019-02-21 94300
# 2019-02-22 92100
# 2019-02-23 92400
# dtype: int64
# iloc slicing
stock.iloc[6:9] # output is 2019-02-21 94300
# 2019-02-22 92100
# 2019-02-23 92400
# dtype: int64조건에 따라 추출
series변수명.loc[조건식]
- loc method를 사용하여, 조건에 맞는 row만 추출한다.
- 조건식에는 and(&)와 or(|) 연산자를 넣을 수 있다.
- 각 조건식을 연산자로 연결해줄 때는 괄호를 사용하여 연결한다.
stock.loc[stock > 92500]
# and 연산자
stock.loc[(stock > 92300) & (stock < 92600)]
# or 연산자
stock.loc[(stock < 92300) | (stock > 92500)]Data 추가
series변수명[새로운 index명] = 새로운 값
Data 수정
series변수명[기존index명] = 새로운 값
series변수명.loc[기존index명] = 새로운 값
series변수명.iloc[기존index번호] = 새로운 값
Data 삭제
del series변수명[기존index명]
# 추가
stock['2019-02-25'] = 90000
# 수정
stock['2019-02-24'] = 92000
# 삭제
del stock['2019-02-25']