Blog Rank 바로가기
깃허브 주소 : https://github.com/applleeee/Blog-Rank
계기
- 처음 코딩을 시작하게 된 계기였던 블로그 순위 검색 기능을 다시 만들어보기로 했다.
- 퇴사 후 잘 쓰이지 않았던 기능이었으나, 최근 해당 기능을 쓰기 편하게 다시 만들어달라는 요청이 있어 이전의 부족했던 부분들을 보완해 웹사이트로 만들 계획이다.
- 이전엔 python으로 만들었으나 이번에 nodejs로 바꿔서 만들 계획이다.
- 이전에 거의 해보지 않았던 프런트 부분까지 할 생각이라 그 부분에서 조금 어려움이 예상되고, 구현 방법에 있어서도 기존의 매 요청마다 크롤링하는 방식을 유지할 수 있을지 의문이다(네이버 api 등 대체 방안 모색).
기획
핵심 기능
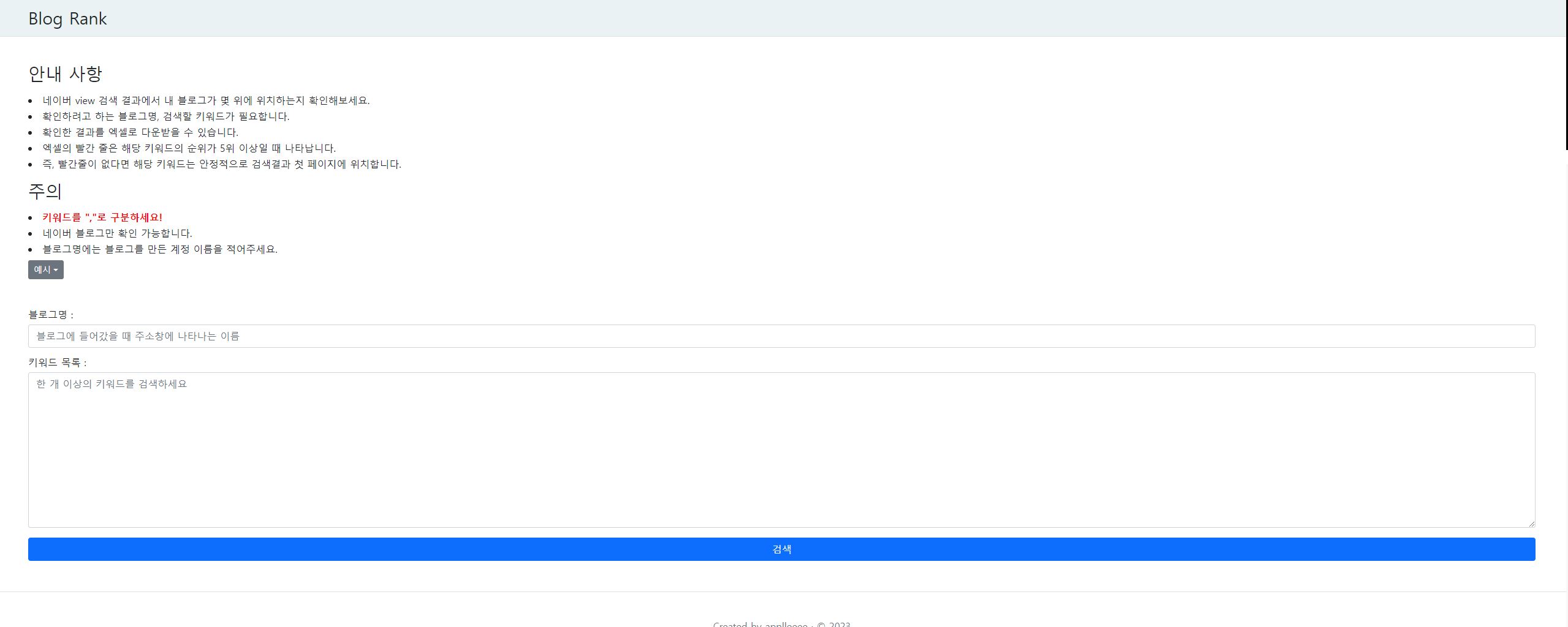
- 유저가 확인하고자 하는 블로그명, 검색할 키워드(다중 검색 가능), 두 가지를 입력하면 해당 블로그가 입력한 키워드 검색 결과에서 몇 번째로 나타나는지와 나타난다면 어떤 글이 나타나는지에 대한 정보를 화면에 표시
- 화면에 표시할 때, 만약 api에서 페이지 정보를 알 수 있다면 첫 페이지에 뜨는 경우와 나머지 경우를 색깔 등으로 구분. 그렇지 않다면 임의의 숫자(ex 5)를 정해 글의 순위가 그 숫자보다 큰 경우와 작은 경우를 구분.
- 표시한 결과를 엑셀로 다운 가능
구현 방법 예상
기존의 크롤링 방식에서 네이버 api를 활용하는 방법으로 전환 예정
→ 크롤링에 비해 안정성, 속도 면에서 좋을 것이라고 생각. 만약 api에서 필요한 정보를 가져오지 못하는 경우 크롤링으로 복귀.
→ 검색 결과를 가져오긴 하나 블로그, 카페로 분리되어 결과가 나와 실제 결과(view)를 반영하지 못함. 또한 각각의 api 결과도 검색 순위와 일치하지 않음.
→ 정확도를 위해 크롤링/스크래핑 방식을 선택해야 할 듯.
- cheerio vs puppeteer
nodejs 환경에서 크롤링 관련된 라이브러리를 찾으니 위의 두가지가 주로 나왔다.
둘의 차이를 보니 cheerio는 스크래핑, puppeteer는 크롤링을 하는 라이브러리였다.
스크래핑은 정적 페이지를 가져오는데 그치고, 크롤링은 브라우저를 직접 실행해 동적인 페이지 정보까지 가져올 수 있었다. 그에 따라 성능 면에선 스크래핑이 우수하다.cheerio의 작동 방식을 보니 특정 url을 입력해 해당 페이지의 정보만을 가져온다. 그러니까 특정 키워드를 검색했을 때의 url을 입력해야 한다.
puppeteer의 경우에는 기존의 python에서 사용했던 라이브러리와 동작 방식이 같다.(selenium)브라우저를 직접 실행해 검색창에 키워드를 입력하는 동작까지 구현할 수 있다.기능상 문제가 없다면 더 가벼운 cheerio를 사용하는 것이 좋은 선택인 것 같다.
cheerio를 사용할 때 중요한 것은 네이버에 특정 키워드를 검색할 때마다 키워드를 제외한 url의 형태가 바뀌지 않아야 한다는 것이다. 직접 몇가지 검색어를 쳐봤을 때, 키워드 부분을 제외하더라도 조금씩 형태가 바뀌었다.
ex1)
https://search.naver.com/search.naver?where=view&sm=tab_jum&query=국어
ex2)https://search.naver.com/search.naver?sm=tab_hty.top&where=view&query=국어학원&oquery=국어&tqi=itsNysp0YiRssi3PY%2F4ssssssph-025101&mode=normal첫번째로 검색했을 땐 위의 예시처럼, 그 이후엔 아래 예시처럼 url의 형태가 나타났다. 그러나 아래 예시에서 위 예시처럼 where와 query만을 남기고 모두 지웠을 때 같은 결과가 나타났다. 따라서 url의 형태를 특정지을 수 있고, cheerio를 사용할 수 있다고 생각했다.
-> cheerio 사용 결정
개발
처음 프로젝트를 세팅할 때 프런트와 백을 나눠 각 폴더마다 환경 설정을 했다. 백은 지난 번 Let's git it 프로젝트에서 썼었던 nestjs를 활용하고 프런트에선 그냥 바닐라js를 쓰기로 했다. 만들 페이지나 기능이 간단하고 빠르게 배포하는게 목표였기 때문에 원래 알고 있던 것을 최대한 활용하기로 했기 때문이다.
데이터 수집 방법
일단 서버 쪽에서 네이버 api에 대해 테스트를 해봤다. 아래는 네이버 공식 문서의 예시이다. 바로가기
// 네이버 검색 API 예제 - 블로그 검색
var express = require('express');
var app = express();
var client_id = 'YOUR_CLIENT_ID';
var client_secret = 'YOUR_CLIENT_SECRET';
app.get('/search/blog', function (req, res) {
var api_url = 'https://openapi.naver.com/v1/search/blog?query=' + encodeURI(req.query.query); // JSON 결과
// var api_url = 'https://openapi.naver.com/v1/search/blog.xml?query=' + encodeURI(req.query.query); // XML 결과
var request = require('request');
var options = {
url: api_url,
headers: {'X-Naver-Client-Id':client_id, 'X-Naver-Client-Secret': client_secret}
};
request.get(options, function (error, response, body) {
if (!error && response.statusCode == 200) {
res.writeHead(200, {'Content-Type': 'text/json;charset=utf-8'});
res.end(body);
} else {
res.status(response.statusCode).end();
console.log('error = ' + response.statusCode);
}
});
});
app.listen(3000, function () {
console.log('http://127.0.0.1:3000/search/blog?query=검색어 app listening on port 3000!');
});해당 api를 테스트해본 결과 목표한 기능을 구현하는데 무리가 있다고 판단했다. 내 목표는 실제로 네이버의 view 탭에서 특정 블로그가 몇 번째에 위치하는지 확인하는 것이다. 그리고 view는 블로그+카페로 구성되어있다.
그런데 위 api는 주석에 있듯이 view 검색이 아니라 블로그 검색이다. 문서를 보면 카페 검색은 따로 존재한다. 따라서 위 api의 응답을 확인해 봤을 때 특정 키워드를 검색했을 때 나오는 결과에서 블로그의 결과만이 나오기 때문에 실제 순위를 제대로 파악할 수가 없다. 게다가 카페를 제외한 블로그도 그 순위가 정확하지 않았다.
ex)
실제 검색 결과 :
1 - 블로그1
2 - 블로그2
3 - 카페1
4 - 블로그3블로그3의 순위를 확인하고 싶다고 할 때 위 api를 이용하면 카페를 포함하지 않기 때문에 3위로 나올 수 있다.
-> 위에서 말한 cheerio 이용
프로젝트 구조 변경
그렇게 cheerio를 이용해 검색 결과를 가져오는 api를 만들었다. 그런데 만들고보니 백엔드 서버를 굳이 분리해야 하나라는 생각이 들었다. 일단 지금은 db를 쓸 일도 없고 특별히 중요한 정보가 포함되지도 않았기 때문에 배포의 편의성을 위해 프런트 코드에 포함시키기로 했다.
BootStrap 적용
최대한 간단하게 페이지를 만들려고 했지만 최소한의 스타일을 주어야 하기에 깜깜한 내 미적 감각을 믿기보단 유명한 라이브러리를 쓰기로 했다.
Web Pack 설정
사실 여기서부터 시간이 지체되기 시작했다. 기능 구현을 위한 코드는 사실 몇시간 내로 끝났지만 개발 환경 설정, 배포 설정 등 해본 적 없거나 해본 지 오래된 익숙하지 않은 것들에 계속 막혔다. 일단 수십 번의 삽질 끝에 babel-loader, HtmlPlugin, MiniCssExtractPlugin, file-loader 등을 이용해 설정을 완료했다.
cors
기존 nestjs에서 cors설정을 간편하게 해결하고 외부 페이지에 접근할 수 있었던 것에 비해, 프런트 쪽으로 코드를 합친 후 cors 설정에 문제가 생겼다.
// 요청 코드
await axios({
url: `/search.naver?where=view&query=${encodeURIComponent(ele)}&mode=normal`,
method: "GET",
})-> 웹팩 서버에서 프록시 설정을 할 수 있다고 한다.
devServer: {
proxy: {
"/search.naver": {
target: "https://search.naver.com",
changeOrigin: true,
},
},
},아래는 최종 결과이다. 아래 배포와도 관련되어 있다.
//webpack.config.js
const path = require("path");
const HtmlPlugin = require("html-webpack-plugin");
const MiniCssExtractPlugin = require("mini-css-extract-plugin");
module.exports = {
devServer: {
proxy: {
"/search.naver": {
target: "https://search.naver.com",
changeOrigin: true,
},
},
},
entry: { index: "./js/index.js", scrap: "./js/scrap.js", getData: "./api/getData.js" },
output: {
path: path.resolve(__dirname, "docs"),
filename: "js/[name].[contenthash:8].js",
clean: true,
publicPath: "/",
},
module: {
rules: [
{
test: /api\/getData\.js$/,
use: {
loader: "file-loader",
options: {
name: "js/[name].[ext]",
publicPath: "/",
outputPath: "/",
},
},
},
{
test: /\.js$/,
exclude: [path.resolve(__dirname, "api")],
use: {
loader: "babel-loader",
options: {
presets: ["@babel/preset-env"],
},
},
},
{
test: /\.css$/,
use: [MiniCssExtractPlugin.loader, "css-loader"],
},
{
test: /\.(png|jpe?g|gif|svg|webp)$/i,
use: [{ loader: "file-loader", options: { name: "[name].[ext]", publicPath: "images/", outputPath: "images/" } }],
},
],
},
devtool: "source-map",
plugins: [
new HtmlPlugin({
template: "./index.html",
chunks: ["index", "scrap", "getData"],
}),
new MiniCssExtractPlugin({
linkType: false,
filename: "css/[name].[contenthash:8].css",
}),
],
};이후 package.json에 "dev": "webpack-dev-server --open --progress --hot"를 추가해 웹팩 서버를 이용해 개발했다.
배포
이전 Let's git it 프로젝트에서 프런트를 vercel로 간편하게 배포하고 ci/cd까지 해결되는 것을 보고 이번 프로젝트에 적용해보기로 했다.

위와 같이 설정하고 배포를 시도했지만

아무리 기다려도 위의 building과정에서 넘어가지 않았다. 그렇다고 에러도 뜨지 않았다.
여기서 vercel을 포기하고 github page를 사용해 배포를 시도했다. 배포는 됐지만 프록시 기능이 없기 때문에 cors 에러가 났다.
다시 vercel로 돌아와 아예 빌드를 로컬에서 하고 그 폴더를 루트 디렉토리로 설정하다가 처음에 빌드가 되지 않았던 이유를 발견했다.
package.json에 "build": "webpack -w" 이렇게 w 옵션이 붙어있었다...
w 옵션을 삭제하고 다시 시도하니 빌드 후 배포까지 성공했다.
이후 프록시 기능을 사용하기 위해 vercel에서 제공하는 serverless funtion에 대해 알아보고 적용했다. api 폴더에 있는 함수를 vercel에서 인식해 프록시 서버에서 실행한다고 한다. 그래서 외부와 통신하는 부분만 해당 폴더의 새 파일에 분리했다.
이번엔 axios 에러가 난다..
vercel의 에러 로그를 보면 axios 패키지를 찾을 수 없다고 한다. 분명 npm i로 필요한 패키지들을 모두 설치했고 다른 기능들은 잘 동작하는데..
Cannot find module '/var/task/node_modules/axios/dist/node/axios.cjs'
Did you forget to add it to "dependencies" inpackage.json?
RequestId: 86237dd0-a2ab-4ae7-9e7f-cbd2ed099de7 Error: Runtime exited with error: exit status 1
Runtime.ExitError
다른 파일들에선 외부 패키지들을 잘 불러왔기 때문에 serverless funtion에서 외부 패키지를 불러오지 못하는 것 같았다. 그래서 원래 axios를 사용했던 코드를 다음과 같이 fetch로 바꿨다.
// serverless funtion
export default async function getData(request, response) {
try {
const res = await fetch(request.body.url);
const data = await res.text();
response.send(data).status(200);
} catch (error) {
console.error(error);
response.status(error.response?.status || 500).end(error.message);
}
}-> 잘 작동한다.. 관련 질문을 여기 남겼다.
결론
프로젝트를 할 때마다 기능 구현을 위한 코드를 작성하는데 쓰는 시간에 비해 개발 환경 설정, 배포 관련 설정을 하는데 훨씬 많은 시간을 쏟는 것 같다. 이전엔 해봤던 구조, 방법으로 새 프로젝트를 한 적이 거의 없었기 때문이다. 그래서 매 번 막막하지만 이 작업들을 하면서 확실히 보는 눈이 넓어지고 공부가 되는 느낌은 있다.
이번엔 리액트 등 프런트 프레임워크의 편의성 및 필요성, 웹팩 설정 방법, 프록시에 대한 개념을 알 수 있었다.
