
Let's git it 바로가기
1월 초, 부트캠프를 수료하고 동기들과 팀을 이뤄 프로젝트를 진행하기로 했다.
1월 11일. 프로젝트 기간을 한달 반 정도로 잡고 각자 주제를 생각해보기로 했다.
이때 한달 반 뒤에 프로젝트를 완성해 배포한 이후에도 최소한 일정 기간 동안은 유지보수하는 서비스를 만들어보자는 생각에는 모두 동의를 했기에 그게 기획을 하는데 유일한 전제였다.
프로젝트 진행
기획
나는 처음에 특별히 만들고 싶었던 것이 있진 않았다.
그래서 바로 어떤 주제를 선택하기보다 주어진 상황에서 팀 프로젝트를 진행할 때 유리한 것과 불리한 것에 대해 생각을 해 보았다.
이런저런 생각을 해보다가 이전 프로젝트들에서 힘들었던 점이 생각이 났다. 사실 기술적인 문제들은 당장 모르고 있는 것들이더라도 어떻게든 해결할 수 있었고, 그 과정 자체가 공부이니 크게 문제가 되지 않았다. 그러나 필요한 "데이터"를 수집하고 넣는 과정은 별로 재밌는 경험은 아니었다.
이전에 진행했던 프로젝트들(나이키, 제주항공, 한국어 학습 앱)에서는 모두 서비스에 들어갈 데이터가 필요했다. 판매할 상품, 항공편, 한국어 공부 자료 등. 프로젝트를 진행할 때에는 물론 소수의 가짜 데이터들을 만들어 활용했지만, 만약 위의 프로젝트들을 실제로 배포하고 사람들로 하여금 사용하게 하려면 적절한 데이터가 필요할 것이다. 어쩌면 개발한 서비스보다 "데이터" 자체가 훨씬 중요할 수도 있다.
또한 나이키와 제주항공과 같이 서비스를 위해 오프라인의 무언가가 필요한 경우도 제외해야 했다.
따라서 이번 프로젝트에서는 실제 배포가 목적이기에 가짜 데이터를 넣을 수 없었고, 그 말은 우리가 직접 의미있는 데이터를 만들던지, 아니면 다른 사람의 데이터를 활용하던지, 아니면 데이터가 필요 없는 서비스를 만들어야 했다. 또한 온라인 상에서 끝나는 서비스여야 했다.
이렇게 선택 기준이 생겼다.
위의 경우 중 이번에 선택할 수 있는 것은 온라인 서비스이면서 다른 사람의 데이터를 활용하는 것, 혹은 데이터가 필요없는 경우이다.
두 가지 중 하나에 해당하는 주제에 대해 생각하다보니 데이터가 아예 필요없는 경우는 7명의 인원이 개발하기에 너무 할 일이 없거나, 너무 기술적으로 무리인 경우밖에 생각나지 않았다.
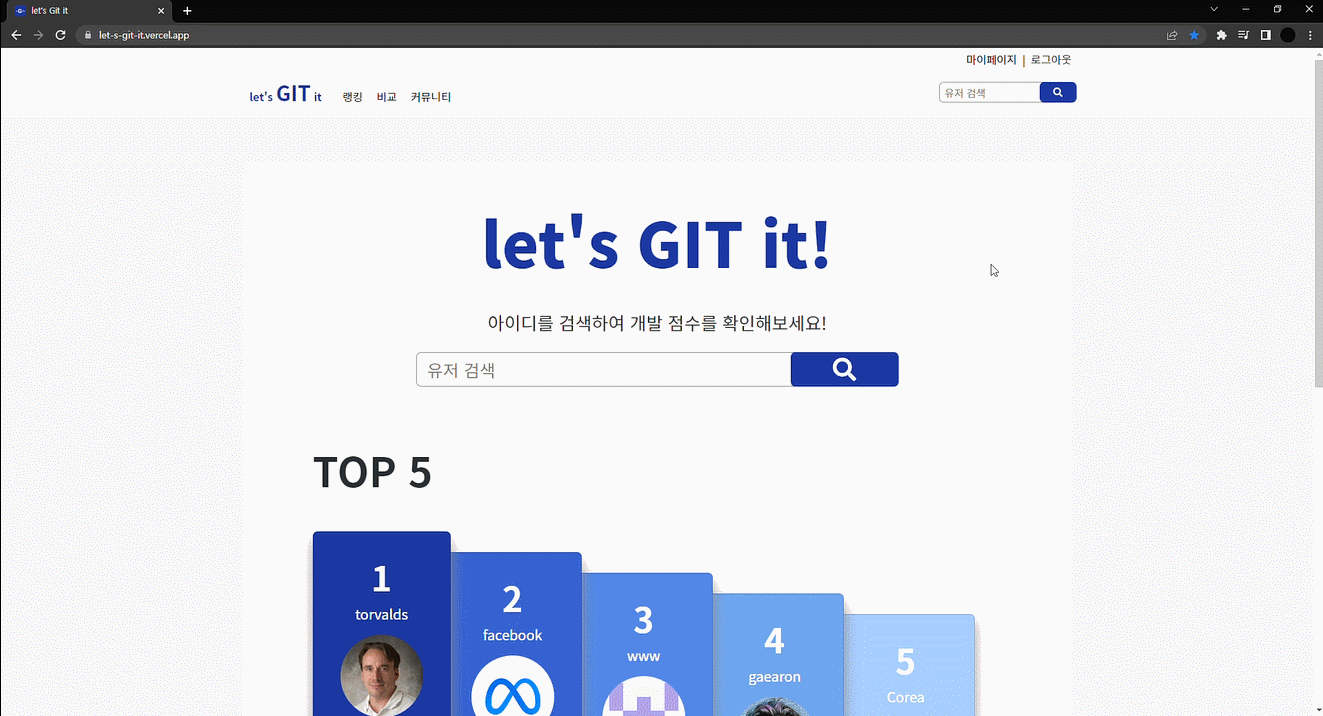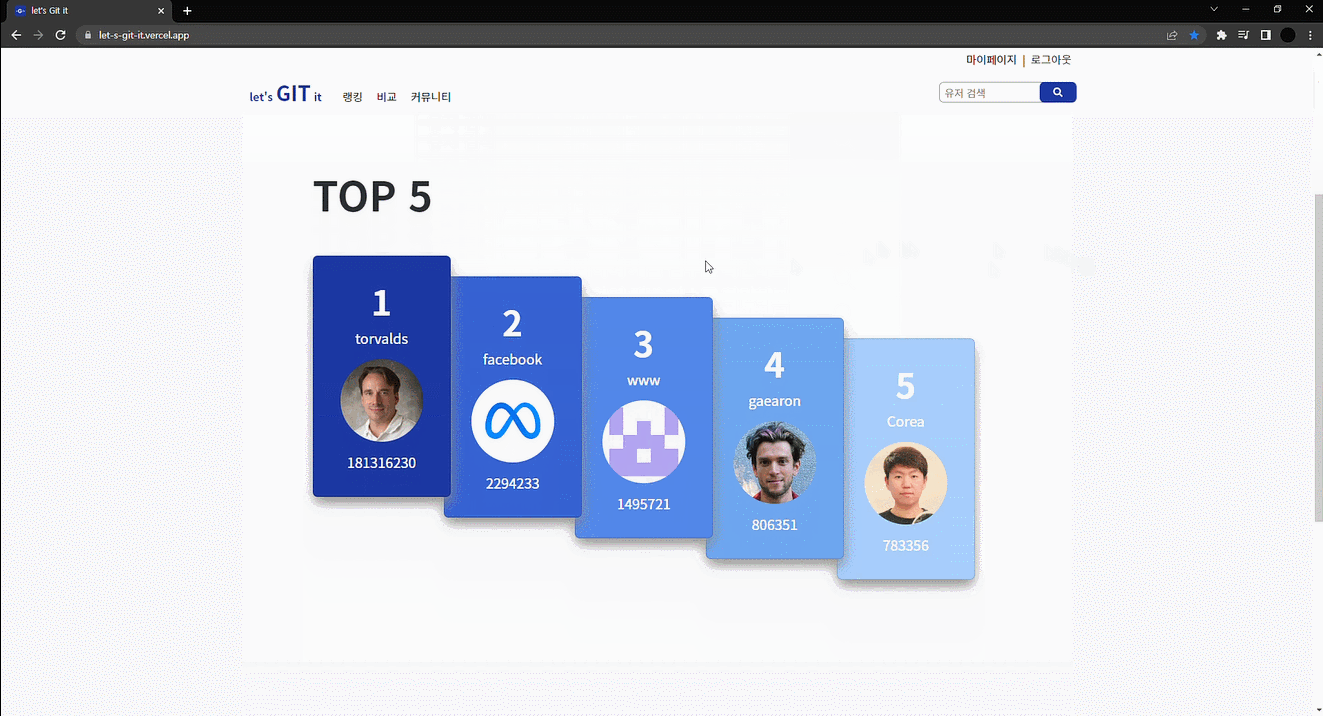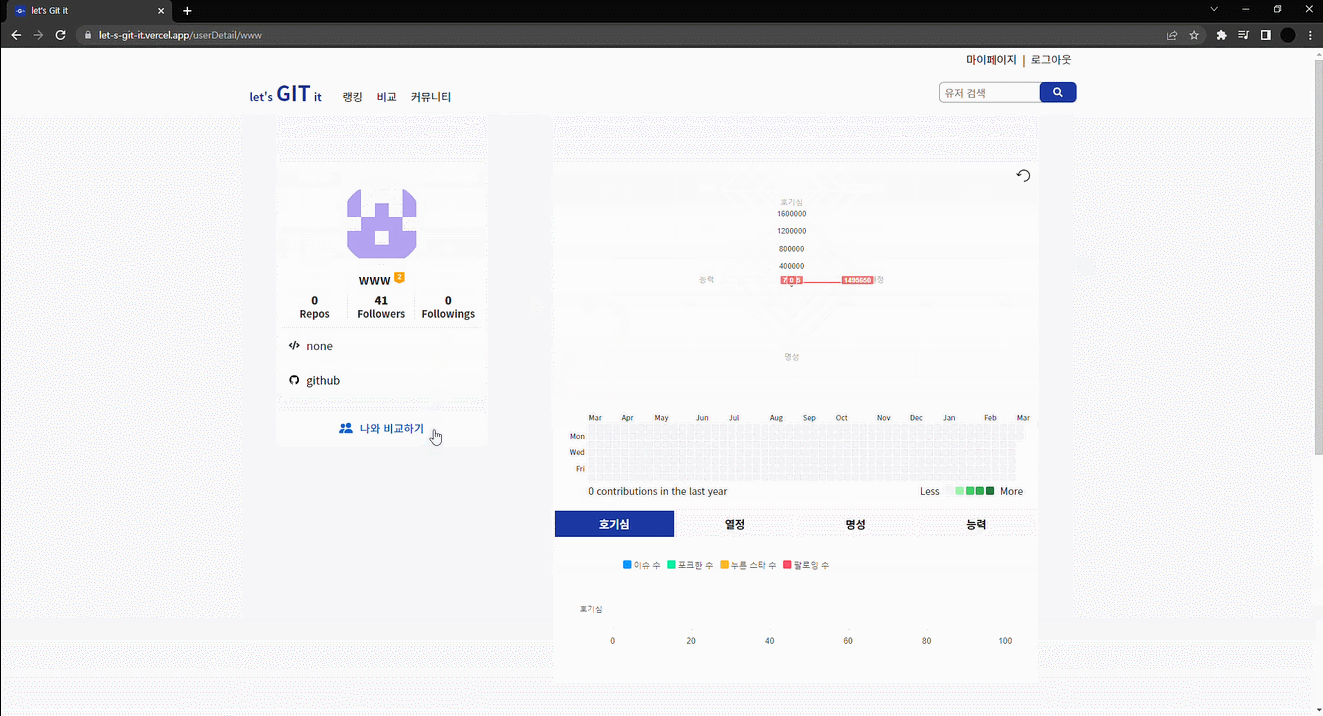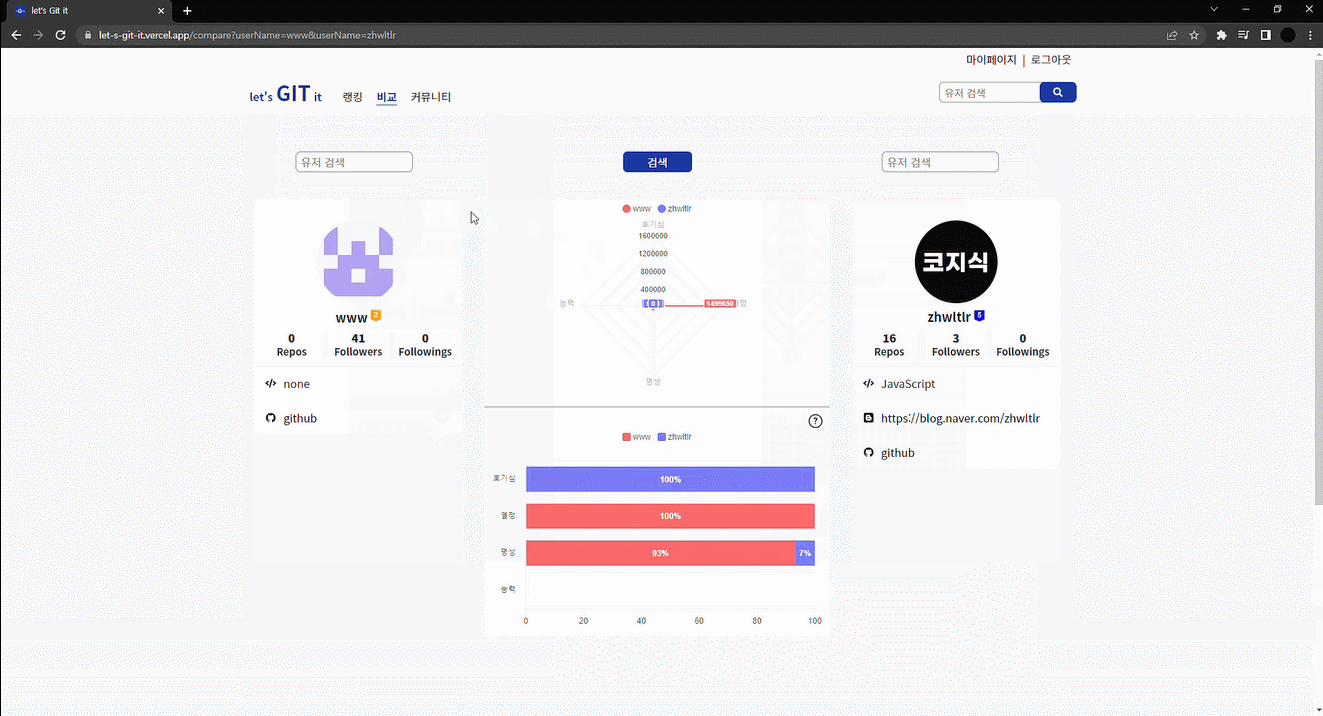
결국 다른 사람의 데이터를 활용하는 것이 남았는데, 평소 한 번이라도 사용해봤던 사이트들을 돌아다니다가 op.gg라는 게임 전적 검색 사이트가 떠올랐다. 그때 대부분의 개발자가 사용하는 깃허브를 이용해 순위를 매긴다면 재밌지 않을까? 하는 생각을 했고, 거기에 더해 각자의 계정에 대해 분석까지 해준다면 꽤 흥미로운 서비스가 될 것 같았다.
깃허브 api를 활용한다면 데이터 문제도 해결되고, 오프라인과 관계없는 서비스였다. 그리고 만약 작업량이 부족하다면 추가적인 기능을 붙이기에도 용이하다고 생각했다. 거의 모든 사용자는 개발자일테니, 관련 커뮤니티를 만들거나 한다면 작업량 문제는 없을거라 생각했다.
그렇게 이후 진행한 아이디어 회의에서 위의 서비스가 선택되었다. 그 외에 자전거 주차장 서비스, 관광 안내, 초단기 알바 등등 여러 아이디어가 나왔지만 모두 실제 서비스를 하는데 무리가 있다고 판단되어 위 깃허브 서비스가 선택되었고, 이어서 PM을 맡게 되었다.. (선택 과정에서 조금 고집을 부린 느낌이 있는데 끝까지 열심히 참여해주신 팀원 분들 감사합니다 ㅎ)
기술 선정
1월 18일. 세부적인 기획 등이 정해지고 프런트, 백에서 각각 사용할 기술에 대해서 정해야 했다.
프런트는 React에 타입스크립트를 적용해 개발하기로 결정했다. 백은 nodejs에서 타입스크립트를 사용하는 것까진 정했지만, 어떤 프레임워크를 사용할 것인가에 대한 고민이 조금 있었다. 기존에 사용한 express를 계속해서 사용할 것인지, 아니면 nestjs를 사용해 볼 것인지.
사실 그동안 프로젝트를 할 때마다 계속 새로운 기술을 도입했었다. 처음엔 당연히 express와 mysql을 처음 실전에 사용해 보았고, 두번째엔 테스트 코드(jest)를 처음 작성해 보았다. 세번째에서는 TypeScipt, Redis를 처음 적용해 보았다.
결국 백엔드 3명 모두 NestJs 사용에 동의를 하고 이번 프로젝트에 사용해 보기로 했다. 또한 db는 그대로 mysql을 활용하지만 그동안 raw query를 썼던 것에 반해 이번엔 TypeORM을 사용해 보기로 했다. 기획 과정에서 커뮤니티 기능이 추가되어 게시글 등 정적 파일들은 aws s3에 저장하기로 했다.(배포, ci/cd 관련 기술들은 이후 배포 단계에서 결정했다.)
- Front : React, TypeScript, SCSS, vercel
- Back : NestJs, Mysql, TypeORM, aws(ec2, s3, rds, route53, cloudfront, certificate manager), docker, github action
공부 & 구현 방법 고민
위의 기술 선정까지 마친 후, 본격적으로 개발을 시작하기 앞서 어떤 방식으로 깃허브에서 데이터를 가져올지 깃허브 api에 대한 분석이 필요했고, NestJs에 대해서도 처음부터 공부를 해야 했다.
가장 먼저 유저의 순위를 매기기 위해 각자 점수를 줘야 했는데 이 점수를 우리가 얻을 수 있는 깃허브의 각 지표들을 수치화한 것의 총합으로 정했다. 또한 이 지표들을 "호기심", "열정", "명성", "능력" 4가지 카테고리로 구분했고, 각각의 카테고리에 가중치를 주어 총점을 산출했다.
이때 각각의 지표들을 얻기 위해 필요한 api를 알아보기 위해 깃허브 api 공식 문서를 처음부터 끝까지 읽어 봤다. 가져와야 하는 지표의 개수가 13~14개 정도 되었기 때문에 최대한 적은 api 호출을 통해 모두 가져오는 방법을 찾기 위해서였다.(깃허브 토큰을 이용하면 api를 1시간에 5000회 호출할 수 있었다)
어느 정도 어떤 api를 활용해야 할지 감을 잡은 후 nestjs 공부로 넘어갔다. 그런데 하다보니 nestjs 자체보다 그것과 db를 typeorm을 이용해서 연결하는데 애를 먹었다. 찾은 자료들마다 사용하는 전략이 달라 원하는 방법을 찾는데 오래 걸렸던 것 같다.
이 과정에서 entity 작성법, 모듈과 의존성 주입에 대해 공부했다.
프로젝트 구조
그리고 각자 맡을 역할을 정했다. 전체 일을 3가지로 나눠서 사다리타기로 정했다. 나는 커뮤니티의 댓글을 제외한 모든 부분을 맡았다.
먼저 src 폴더 구조는 아래와 같다. 각 기능마다 모듈을 분리했고, controller, service, repository로 구분했다. 또 필요한 경우엔 각 폴더에 dto, pipe, guard 등을 커스텀해서 사용했고 공통으로 쓰이는 것들은 utiles 폴더에 분리해 만들었다.
├── app.module.ts
├── auth
│ ├── auth.controller.spec.ts
│ ├── auth.controller.ts
│ ├── auth.module.ts
│ ├── auth.repository.spec.ts
│ ├── auth.repository.ts
│ ├── auth.service.spec.ts
│ ├── auth.service.ts
│ ├── constants.ts
│ ├── dto
│ │ └── auth.dto.ts
│ └── jwt.strategy.ts
├── community
│ ├── community.controller.spec.ts
│ ├── community.controller.ts
│ ├── community.module.ts
│ ├── community.repository.spec.ts
│ ├── community.repository.ts
│ ├── community.service.spec.ts
│ ├── community.service.ts
│ ├── dto
│ │ ├── Post.dto.ts
│ │ └── comment.dto.ts
│ ├── guard
│ │ └── optionalGuard.ts
│ └── pipe
│ └── getPostList.pipe.ts
├── entities
│ ├── Career.ts
│ ├── Comment.ts
│ ├── CommentLike.ts
│ ├── Field.ts
│ ├── MainCategory.ts
│ ├── Post.ts
│ ├── PostLike.ts
│ ├── RankerProfile.ts
│ ├── Ranking.ts
│ ├── SubCategory.ts
│ ├── Tier.ts
│ └── User.ts
├── main.ts
├── rank
│ ├── dto
│ │ ├── rankerProfile.dto.ts
│ │ └── ranking.dto.ts
│ ├── rank.controller.spec.ts
│ ├── rank.controller.ts
│ ├── rank.module.ts
│ ├── rank.service.spec.ts
│ ├── rank.service.ts
│ ├── rankerProfile.repository.spec.ts
│ ├── rankerProfile.repository.ts
│ ├── ranking.repository.spec.ts
│ ├── ranking.repository.ts
│ ├── tier.repository.spec.ts
│ └── tier.repository.ts
├── schedule
│ ├── schedule.module.ts
│ └── schedule.service.ts
├── user
│ ├── dto
│ │ └── mypage.dto.ts
│ ├── user.controller.spec.ts
│ ├── user.controller.ts
│ ├── user.module.ts
│ ├── user.repository.spec.ts
│ ├── user.repository.ts
│ ├── user.service.spec.ts
│ └── user.service.ts
└── utiles
├── aws.ts
├── boolean-transformer.ts
└── http-exception.filter.ts
그리고 ERD는 아래와 같다.

기능 구현
내가 구현한 기능(api)는 다음과 같다.
- 카테고리 리스트 조회
- 글 생성
- 글 이미지 s3 업로드
- 글 이미지 s3 삭제
- 글 수정
- 글 삭제
- 글 상세페이지 조회
- 글 목록 조회
- 글 좋아요 생성/삭제
- 글 검색
-
카테고리 리스트 조회(1)는 단순히 db에 저장된 카테고리 종류를 get하는 api이다.
-
글 생성(2)은 유저가 글을 작성하고 게시 버튼을 눌렀을 때 호출된다.
글을 작성하고 저장하는 전체 과정을 보면,
- 유저가 글 입력
- 유저가 이미지 업로드 시 글 이미지 s3 업로드(3) api 호출 -> aws sdk 이용해 s3에 저장 -> 프런트에 s3 객체 url 리턴 -> 유저에게 이미지 표시
- 유저가 이미지 삭제 시 글 이미지 s3 삭제(4) api 호출 -> aws sdk 이용해 s3에서 이미지 삭제
- 유저가 글 저장 시 글 생성(2) api 호출 -> 글 전체를 html 형식으로 받음 -> 이미지 역시 html 안에 객체 url 형태로 존재 -> aws sdk 이용해 s3에 저장 -> 저장된 s3 주소를 db에 저장
- 글 수정은 프런트에서 유저가 기존에 작성한 글 상세페이지 조회(6) api 호출 -> 본문 내용 리턴 -> 수정한 글 저장 시 글 수정(5) api 호출
- 글 목록 조회(7)는 정렬 방식(최신순/인기순)(전체기간, 연, 달, 주, 일)에 따라 글 목록 정렬해 리턴
고정 글 존재할 시 고정글은 일반 글과 분리해 리턴
- 글 검색(10)은 제목/작성자/제목+작성자로 검색 가능
- 글 좋아요(9) api 호출 시 유저가 좋아요를 처음 누른 경우 좋아요 생성, 이미 누른 상태에서 다시 누르면 좋아요 삭제
배포
최종 목표는 ci/cd까지였지만 프런트의 개발 속도와 편의를 위해 기능적으로 완성된 서버를 먼저 ec2에 띄우기로 했다.
처음에 ec2에 접속해서 github 레포지토리를 clone해 실행시켰더니 메모리 부족 에러가 생겨 실행되지 않았다.(ec2는 프리티어 적용되는 t2.micro를 사용했다. 메모리는 1GB)
위 문제의 해결 방법으로 로컬에서 빌드한 dist 폴더를 바로 ec2에 복사했다. 이후 실행하니 잘 작동되었다.
RDS는 로컬의 db를 덤프떠서 그대로 적용해 별 문제 없이 ec2와 잘 연결되었다.
테스트
이후 테스트코드 작성에 들어갔다. jest로 유닛테스트를 진행했다. controller, service, repository의 모든 함수에 대해 테스트 코드를 작성하는 것을 목표로 했지만 뒤의 배포 일정에 맞추기 위해 일단 70% 정도 완성하고 배포 관련 작업으로 넘어갔다. 추후 보완할 예정이다.
테스트는 독립성을 확보하기 위해 각 레이어에 해당하지 않는 함수들은 모두 모킹해 진행했고, AAA 패턴을 적용했다.
HTTPS
프런트는 vercel을 이용해 배포했다. 프런트에서 https 설정을 적용했더니 서버와의 통신에서 에러가 나기 시작했다.(기존에 http 통신)
..서버도 적용했다.
자세한 과정은 이전 글을 참고
CI / CD
마지막 단계이다. Docker와 GitHub Action을 사용했다. 백엔드 3명이서 각자 해보고 적절한 방법을 선택해 적용하기로 했다.
일단 똑같은 코드에 대한 똑같은 테스트 코드가 누구의 로컬에선 잘 통과되지만 누구의 로컬에선 통과되지 않는 것을 보고 도커의 필요성에 대해 확실히 느꼈다.
개발 과정에서 main - develop - feature1 / feature2 이런 식으로 브랜치를 운영했다.
목표는 develop에서 main 브랜치로 pr을 요청했을 때 test를 진행하고 모두 통과하면 docker 이미지를 빌드하고 ec2에 배포한 뒤 서버를 실행시키는 것이었다.
나는 test를 진행하고 통과하면 docker 이미지 빌드, 이후 깃허브 container registry에 이미지를 저장한 후 ec2에 ssh로 접속해 docker 이미지를 다운 받아 서버를 실행시켰다. 이때 환경변수를 ec2에 .env 파일을 올려 도커 이미지를 실행할 때 해당 파일을 참조하도록 했다.
이후 3명의 방법을 모두 종합해 하나를 선택했는데, 내 방식에서 .env를 ec2에 직접 올리는 것이 위험할 수 있다고 생각해 환경변수를 모두 깃허브 시크릿에 등록한 뒤 yml파일에서 서버를 실행시킬때 환경변수를 넣어주는 방식을 선택했다. 또한 깃허브 컨테이너 대신 도커 허브를 이용했다.
이후 완성된 서비스를 여기저기 홍보하고 피드백을 받고 있다. 조금 뒤에 있을 회의에서 피드백에 대한 처리와 앞으로의 계획 등을 정할 듯 싶다.
-> (3/23 추가) 완성한 이후 여러 유저들의 피드백을 받고 해결해야할 문제들 목록을 만들어 일주일에 한 번 회의를 거쳐 각자 지난 주에 한 것, 이번 주에 할 것 등을 공유하고 있다.
또 개발 서버를 추가해 배포 전 테스트할 수 있는 환경을 만들어 안정성을 높였다. (기존의 방식, 즉 develop에서 main branch로 pr을 올렸을 때 개발 서버로 배포가 진행되고, 본 서버로의 배포는 수동으로 액션을 실행해야 하도록 수정했다. )
결론
처음에 목표했던 대로 유저가 실제로 사용하고 피드백할 만한 서비스를 배포했다는 것에 만족을 느낀다. 그리고 이후에도 부족한 부분들을 보완할 것 같아서 더 목표에 가깝게 온 것 같다.
처음 생각했던 것보다 개발 기간이 길어졌는데, 역시 새로운 기술들에 대한 학습과 처음 해보는 작업들(ci/cd)에서 시간이 많이 소요되었다.
또, 프런트와 통신을 할 때 각자 코드를 완성한 상태에서 직접 만나 기능을 테스트했는데, 만약 ci/cd와 docker를 먼저 적용하고 배포한 상태에서 프로젝트를 진행했다면 훨씬 진행 속도가 빨라졌을 것이다. 이후에는 이미 환경을 구축한 상태이니 유지보수가 쉬울 것으로 기대된다.
