KNNImputer
KNNImputer는 sklearn의 패키지 중 하나로, 결측치를 채우는 방법으로 실무에서도 많이 쓰인다는 방법이다.
앞서 소개했던 df.fillna(), df.interpolate 또는 SimpleImputer와 다르게 마땅히 결측치를 채울 방법이 떠오르지 않을 때 사용한다.
cf) https://velog.io/@songjeongwoo/%EA%B2%B0%EC%B8%A1%EC%B9%98-%EC%A1%B0%EC%B9%98-aq300kcu
KNNImputer는 가변수화가 반드시 선행되어야한다.
KNNImputer는 KNN 알고리즘을 사용하여 결측치를 채우는 방식이다.
즉, 가까운 이웃의 수를 정하고 그 이웃들을 이용하여 결측치를 채우는 방식이다.
따라서 KNN 알고리즘은 거리가 중요하다.
코드 사용법
데이터를 불러와서 x와 y분리, train, val 셋 분리, 가변수화 등 모두 되어있다고 가정한다.
사용된 데이터 출처: https://www.kaggle.com/c/titanic
라이브러리 불러오기
from sklearn.impute import KNNImputercf) https://scikit-learn.org/stable/modules/generated/sklearn.impute.KNNImputer.html
KNNImputer 선언
# n_neighbors=5(디폴트 값)
imputer = KNNImputer(n_neighbors=3)imputer를 선언할 때 n_neighbors 하이퍼파라미터를 이용해 몇 개의 이웃을 사용할 지 지정한다.
cf) n_neighbors=5가 디폴트 값이다.
사용 후 확인을 위한 코드
cols = x_train.columnsKNNImputer를 거치면 데이터가 np array가 되기때문에 확인을 위해선 pd.DataFrame()을 사용해야한다.
이때 사용할 x_train의 column명들을 cols 변수에 담아둔다.
x_train.info()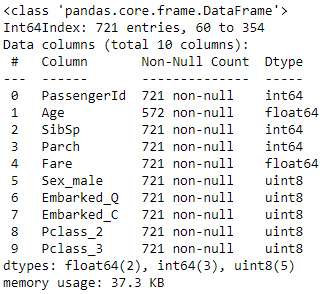
사용(학습 후 적용)
x_train = imputer.fit_transform(x_train)
x_val = imputer.transform(x_val)df로 변환 후 info()를 통한 확인
x_train = pd.DataFrame(x_train, columns=cols)
x_train.tail(2)
x_train.info()