
스케일링을 하는 이유
모델의 성능을 높이기 위해 스케일링을 진행한다.
알고리즘 중 거리를 계산하는 알고리즘은 거리가 클수록 영향을 많이 받는다.
그러나 거리가 크다는 것(범위가 크다는 것)이 꼭 중요한 변수를 의미하지는 않는다.
따라서 스케일링을 통해 범위를 일치시켜준다.
- ex) 나이와 연봉 변수
- 보통 나이는 0~100 사이, 연봉은 1000만 단위
스케일링 작업을 진행하면 모든 feature에 대해서 featrue 각각을 기준으로 스케일링이 진행된다.
만약 특정 변수에 대해서만 진행하고 싶다면, 해당 변수만 따로 스케일링을 진행하고 다른 변수들과 데이터프레임으로 합치는 작업을 진행해줘야한다.
스케일링 종류에는 표준화와 정규화가 있다.
스케일링 작업은 둘 중 하나만 수행한다.
cf) ★가변수화가 선행되어야한다.
스케일링의 종류
표준화(Standardiztion)
표준화는 분포의 범위가 다양할 때, 분포를 비교하기 위한(특히 정규분포) 방법이다.
표준화를 거치면 z-score가 된다.
모든 분포가 평균은 0, 표준편차는 1이 되므로 분포에 대한 비교가 가능해진다.
cf) : 뮤라고 읽으며, 제로평균을 의미한다.
Standard Scaler
- 필요한 라이브러리 불러오기
from sklearn.preprocessing import StandardScaler- 선언, 학습 후 적용
scaler = StandardScaler() # 스케일러 호출
x_train_s = scaler.fit_transform(x_train) # 학습 후 적용- validation 셋에 적용
x_val_s = scaler.transform(x_val) # 적용- 또는 아래 방법으로도 가능하다.
# 다른 방법
scaler.fit(X_train)
x_train_s = scaler.transform(X_train)
x_val_s = scaler.transform(x_val)- cf) 결과 확인을 위한 df 작업
# 결과 확인을 위한 df 작업
df_s = pd.DataFrame(x_train_s, columns=x_train.columns)
df_s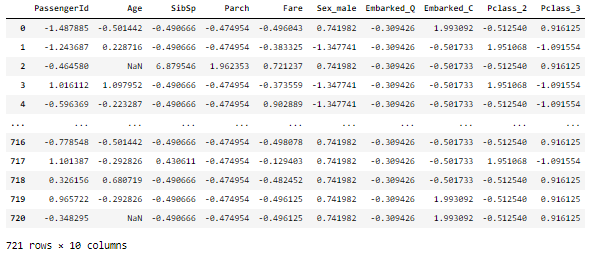
Z-score
sklearn 라이브러리가 아닌 scipy클래스의 stats함수를 import한다!
- 필요한 함수 불러오기
from scipy import stats- z-score 적용
x_train_zs = stats.zscore(x_train)- validation 셋에 적용
x_val_zs = stats.zscore(x_val)- cf) 결과 확인을 위한 df 작업
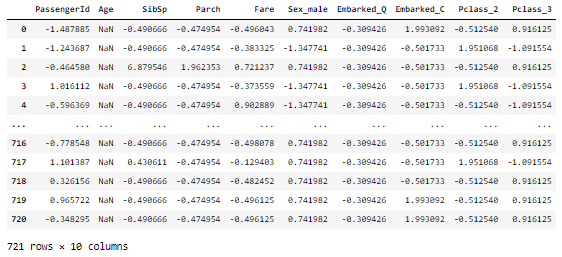
df_zs = pd.DataFrame(x_train_zs, columns=x_train.columns)
df_zs결과를 보면 다른 스케일링 작업과 다르게 NaN이 있는 변수에 대해서는 z-score를 구할 수 없음을 알 수 있다.
정규화(normalization)
모든 feature(변수)를 [0,1] 사이 값으로 변환하는 방식이다.
이상치 제거가 선행되어야한다.
이상치가 존재할 경우, 성능이 저하된다.
-
-
cf) 정규화를 보통 0 ~ 1로 하는 것이 일반적이나 -1 ~ 1로도 할 수 있다.
그러나모델링 전처리 시에는 0 ~ 1로만 고려하면 된다.
(x - x.min()) / (x.max() - x.min())
x_s = (x_train - x_train.min()) / (x_train.max() - x_train.min())
x_s
MinMax Scaler
sklearn에서 제공하는 MinMaxScaler를 통한 정규화
cf) https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html
- 필요한 라이브러리 불러오기
from sklearn.preprocessing import MinMaxScaler- 선언, 학습 후 적용
scaler = MinMaxScaler() # 스케일러 호출
x_train_s = scaler.fit_transform(x_train) # 학습 후 적용- validation 셋에 적용
x_val_s = scaler.transform(x_val) # 적용- cf) 수식 사용했을 때랑 결과 비교하기
# 결과 확인을 위한 df 작업
df_s = pd.DataFrame(x_train_s, columns=x_train.columns)
df_s수식을 이용했을 때랑 결과가 같음을 확인할 수 있다.

표준화와 정규화의 차이점
표준화는 이상치와 상관없이 분포를 그대로 유지해준다.
반면에 정규화는 값의 범위를 0~1로 맞춰야하기 때문에 이상치에 따라서 분포가 좀 더 압축된다.
따라서 이상치가 큰 경우 표준화가 적절하다.
반대의 경우, 대체로 정규화를 사용한다.
- cf) 스케일링에 따른 타이타닉의 Fare 변수에 대한 분포
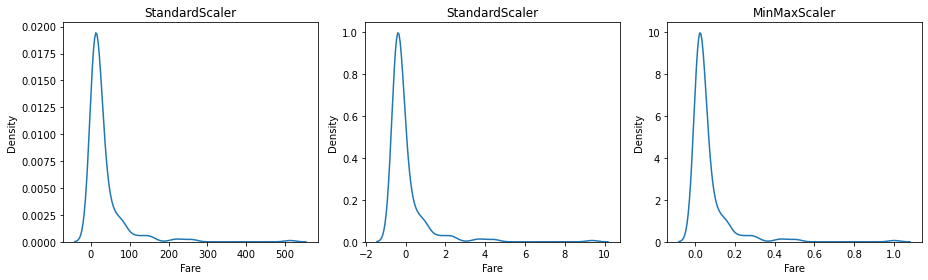
어떤 방법을 사용하여 스케일링 했냐에 따라 x축 범위가 달라짐을 확인할 수 있다.
사용된 데이터 출처: https://www.kaggle.com/c/titanic
스케일링이 필요한 알고리즘
KNN, SVM 등 거리를 이용한 알고리즘
