클라이언트
데이터베이스 접속
mysql -uroot -p
password : <password>- -uroot : root라는 user로 접속
password :가 나오면 사용자 비밀번호 입력
데이터베이스 선택
show databases;
use sample- 데이터베이스 목록을 확인하고
sample이라는 데이터베이스 선택 show는 SQL 명령이 아닌 mysql 클라이언트 프로그램의 고유 명령
클라이언트 종료
exit- mysql 클라이언트 종료
개념
SELECT * FROM sample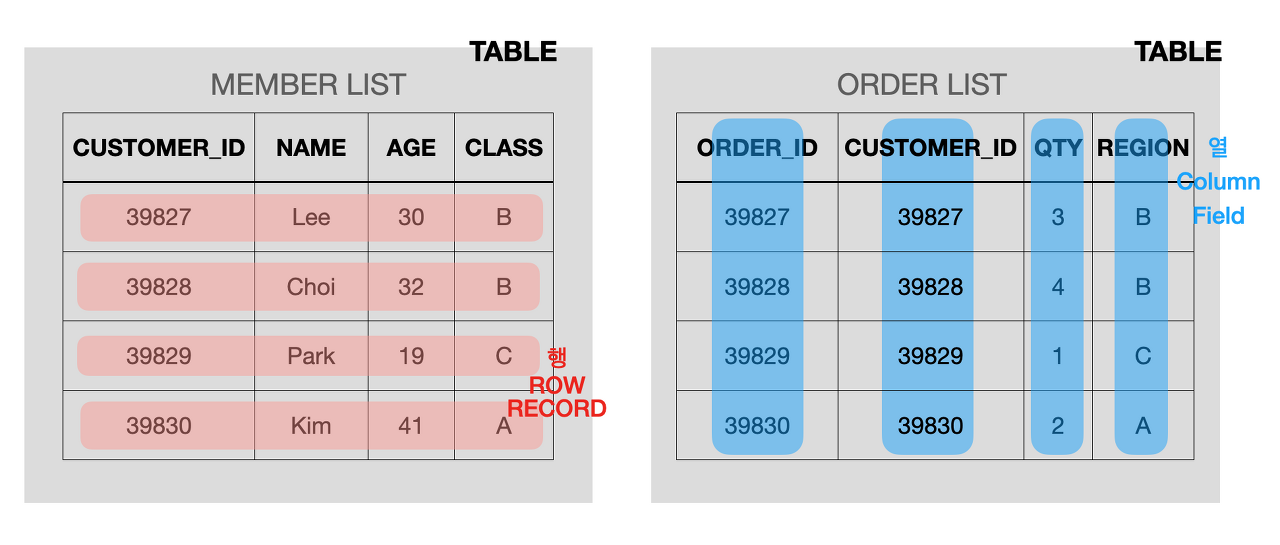
- SELECT 명령을 실행하면 표 형식의 데이터가 출력
- 데이터는
행(래코드)과열(컬럼/필드)로 구성
테이블 구조 참조
DESC 테이블명;- 테이블에 어떤 열이 정의되어 있는지 알 수 있다.
- SQL 명령이 아니다.
명령
SELECT
// no 열 값이 2인 행 검색
SELECT * FROM sample21 WHERE no = 2;
// no 열 값이 2가 아닌 행 검색
SELECT * FROM sample21 WHERE no <> 2;
// birthday가 NULL인 행만 검색
SELECT * FROM sample21 WHERE birthday IS NULL;조건
SELECT * FROM sample24 WHERE (a=1 OR a=2) AND (b=1 OR b=2);- AND는 OR보다 높은 우선순위를 가진다.
- 일반적으로 OR 조건식은 괄호로 묶어 지정한다.
패턴 매칭
% : 임의의 문자열을 의미하는 메타문자
_ : 임의의 문자 하나를 의미하는 메타문자
// SQL로 시작하는 문자열을 포함한 행 검색
SELECT * FROM sample25 WHERE text LIKE 'SQL%';
// SQL을 포함한 문자열을 포함한 행 검색
SELECT * FROM sample25 WHERE text LIKE '%SQL%';
// %을 포함한 문자열을 포함한 행 검색
SELECT * FROM sample25 WHERE text LIKE '%\%%';
// _을 포함한 문자열을 포함한 행 검색
SELECT * FROM sample25 WHERE text LIKE '%\_%';- 문자열 상수
'는''로 2개 연속해서 기술하는 것으로 이스케이프 처리 It's->It''s'하나만 문자열 데이터인 경우는''''
정렬
// age열의 값을 오름차순으로 정렬
SELECT * FROM sample31 ORDER BY age;
// age열의 값을 내림차순으로 정렬
SELECT * FROM sample31 ORDER BY age DESC;ORDER BY는 테이블에 영향을 주지 않는다.
SELECT * FROM sample31 order by a ASC, b DESC;- a열 ASC로, b열 DESC로 정렬하기
- 기본값이 ASC이지만 데이터베이스 제품에 따라 기본값을 변경할 수도 있으므로 정렬방법은 생략하지 말고 지정
NULL 값의 정렬순서
- NULL에 대한 대소비교 방법은 표준 SQL에도 규정되어 있지 않아 데이터베이스 제품에 따라 기준이 다르다.
- NULL값을 가지는 행은 가장 먼저 표시되거나 가장 나중에 표시된다.
MySQL의 경우는 NULL값을 가장 작은 값으로 취급해 ASC에서는 가장 먼저, DESC에서는 가장 나중에 표시한다.
LIMIT
// sample33에 LIMIT 3으로 상위 3건만 검색
SELECT * FROM sample33 LIMIT 3;
//sample33을 내림차순으로 정렬 후 LIMIT 3으로 상위 3건만 검색
SELECT * FROM sample33 ORDER BY no DESC LIMIT 3;- LIMIT는 표준 SQL이 아니기 때문에 MySQL, PostgreSQL 이외의 데이터베이스에서는 사용할 수 없다.
SELECT TOP 3 * FROM sample33;- SQL Server에서는
TOP뒤에 최대 행수를 지정하면 된다.
SELECT * FROM sample33 WHERE ROWNUM <= 3;- Oracle에서는
ROWNUM이라는 열을 사용해 WHERE 구로 조건을 지정하여 행을 제한할 수 있다. ROWNUM으로 행을 제한할 때는 WHERE 구로 지정하므로 정렬하기 전에 처리되어 LIMIT로 행을 제한한 경우와 결과값이 다르다.
// 4번째 행부터 획득
SELECT * FROM sample33 LIMIT 3 OFFSET 3;수치연산
// price * quantity를 계산한 열에 amount라는 별명 붙이기
SELECT *, price * quantity AS amout FROM sample34;- 별명을 한글로 지정하는 경우에는
더블쿼트(MySQL에서는 백쿼트)로 둘러싸서 지정한다. - 이름은 숫자로 시작할 수 없다.
// WHERE 구에서 금액을 계산하고 2,000원 이상인 행 검색하기
SELECT *, price * quantity AS amount FROM sample34
WHERE price * quantity >= 2000;- WHERE 뒤의 조건을
amount >= 2000;으로 수정하면 에러가 발생한다. - 일반적으로 데이터베이스 서버 내부에서
WHERE 구 -> SELECT 구의 순서로 처리된다. WHERE 구로 행이 조건에 일치하는지 아닌지를 먼저 조사한 후에 SELECT 구에 지정된 열을 선택해 결과로 반환한다. 별명은 SELECT 구문을 내부 처리할 때 비로소 붙여지기 때문에 WHERE 구에서 사용한 별칭은 아직 내부적으로 지정되지 않은 상태가 되어 에러가 발생한다.
NULL 값의 연산
- NULL로 연산하면 결과는 NULL이 된다.
// ORDER BY구에서 별명을 사용해 정렬하기
SELECT *, price * quantity AS amount FROM sample34 ORDER BY amount DESC;- ORDER BY는 서버에서 내부적으로 가장 나중에 처리되기 때문에 별명을 사용할 수 있다.
// amount를 반올림
SELECT amount, ROUND(amount) FROM sample341;
// amount를 소수점 둘째 자리에서 반올림
SELECT amount, ROUND(amount, 1) FROM sample341;- 두 번째 인수로 반올림할 자릿수 지정
- -1을 지정하면 1단위, -2를 지정하면 10단위를 반올림
문자열 연산
SELECT CONCAT(quantity, unit) FROM smaple35;- 그 외
SUBSTRING,TRIM
CHARACTER_LENGTH 함수
-
CHARACTER_LENGTH: 문자열의 길이를 계산해 돌려주는 함수,CHAR_LENGTH로 줄여서 사용 -
OCTET_LENGTH: 문자열의 길이를 바이트 단위로 계산해 돌려주는 함수 -
문자 하나의 데이터가 몇 바이트의 저장공간을 필요로 하는지
인코드 방식에 따라 결정된다. VARCHAR 형의 길이는 문자세트에 따라 길이가 문자 수로 간주되기도 하니 주의할 필요가 있다. -
알파벳의 경우는 반각문자, 한글은 전각문자라고 할 수 있다. 반각 문자는 전각문자 폭의 절반밖에 안 되며 저장용량 또한 저너각문자 쪽이 더 크다. 반각의 알파벳이나 숫자, 기호는
ASCII 문자라고 부른다. -
한글의 경우
EUC-KR,UTF-8등의 인코드 방식을 주로 사용한다. 인코드 방식은 데이터베이스나 테이블을 정의할 때 변경할 수 있는데 RDBMS에서는 이를문자세트라고 부른다. -
CHAR_LENGTH함수를 사용하는 경우, 한글이든 ASCII 문자든 문자 수로 계산되기 때문에 문제가 없다. -
OCTET_LENGTH함수의 경우 문자 수가 아닌 바이트 단위로 길이를 계산하므로 주의할 필요가 있다.
문자열 조작 함수로 문자 단위가 아닌 바이트 단위로 지정할 경우에는 문자세트에 주의할 필요가 있다. 날짜 연산
// 날짜를 연산해 시스템 날짜의 1일 후를 검색
SELECT CURRENT_DATE + INTERVAL 1 DAY;
// 날짜시간형 데이터 간에 뺄셈
SELECT DATEDIFF('2014-02-28', '2014-01-01');CASE
// CASE로 NULL 값을 0으로 변환하기
SELECT a, CASE WHEN a IS NULL THEN 0 ELSE a END "a(null=0)" FROM sample37;
// 위와 동일한 명령
// NULL이 아닌 값에 대해서는 첫번째 인수, NULL이면 두번째 인수로 출력
SELECT a, COALESCE(a, 0) FROM sample37;// 검색 CASE로 성별 코드를 남자, 여자로 변환하기
SELECT a AS "코드",
CASE
WHEN a=1 THEN '남자'
WHEN a=2 THEN '여자'
ELSE '미지정'
END AS "성별" FROM sample37;
// 단순 CASE로 성별 코드를 남자, 여자로 변환하기
// CASE 뒤에는 대상을 적는다
// WHEN 뒤에는 값만 적는다
SELECT a AS "코드",
CASE a
WHEN 1 THEN '남자'
WHEN 2 THEN '여자'
ELSE '미지정'
END AS "성별" FROM sample37;ELSE 생략
- ELSE를 생략하면
ELSE NULL이 되는 것에 주의해야 한다.ELSE는 생략하지 않는 편이 낫다.
WHEN에 NULL 지정
// 단순 CASE 문으로는 NULL 값을 비교할 수 없다.
CASE
WHEN a=1 THEN '남자'
WHEN a=2 THEN '여자'
WHEN a IS NULL THEN '데이터 없음'
ELSE '미지정'
ENDDECODE
- NULL 값을 변환할 때는 표준 SQL로 규정되어 있는
COALESCE함수를 사용한다.
INSERT
INSERT INTO sample41 VALUES(1, 'ABC', '2014-01-25');
INSERT INTO sample41(a, no) VALUES('XYZ', 2);
INSERT INTO sample411(no, d) VALUES(2, DEFAULT);DELETE
DELETE FROM sample41 WHERE no=3;UPDATE
UPDATE sample41 SET b='2014-09-09' WHERE no=2;SET 구의 실행 순서
UPDATE sample41 SET no=no+1, a=no; - 1
UPDATE sample41 SET a=no, no=no+1; - 2MySQL에서는 1, 2번이 서로 다른 결과값이 나오지만Oracle에서는 어느 명령을 실행해도 결과는 같다.MySQL에서는 SET 구에 기술된 순서로 갱신 처리가 일어난다.Oracle에서는 항상 갱신 이전의 값을 기준으로 갱신하기 때문에 SET 구에 기술한 식의 순서가 처리에 영향을 주지 않는다.
집계
SELECT COUNT(*) FROM sample51;
SELECT COUNT(no), COUNT(name) FROM sample51;
SELECT DISTINCT name FROM sample51;
SELECT COUNT(ALL name), COUNT(DISTINCT name) FROM sample51;
// NULL을 0으로 계싼해서 평균값 계산
SELECT AVG(CASE WHEN quantity IS NULL THEN 0 ELSE quantity END) AS avgnull0 FROM sample51;DISTINCT는 예약어로 열명이 아니다. 중복된 데이터를 제외한 결과를 클라이언트로 반환한다.
그룹화
SELECT name, COUNT(name), SUM(quantity) FROM sample51 GROUP BY name;- 집계함수와 같이 사용해야 의미가 있다.
SELECT name, COUNT(name) FROM sample51 GROUP BY name HAVING COUNT(name) = 1;- 집계함수를 사용할 경우 HAVING 구로 검색조건을 지정한다.
- WHERE구가 ORDER BY 구문보다 처리 순서가 앞서기때문에 HAVING을 사용해야 한다.
- HAVING 구가 SELECT 구보다도 먼저 처리되므로 별명을 사용할 수 없지만 MySQL에서는 제품 특성상 사용 가능하다. Oracle에서는 사용 불가.
// no, quantity는 GROUP BY에서 지정되지 않았으므로
// SELECT구에서 지정할 수 없어서 에러가 발생한다.
SELECT no, name, quantity FROM sample51 GROUP BY name;
SELECT MIN(no), name, SUM(quantity) FROM sample51 GROUP BY name;- GROUP BY에 지정한 열 이외의 열은 집계함수를 사용하지 않은 채 SELECT 구에 기술해서는 안된다.
서브쿼리
// 괄호로 서브쿼리를 지정
DELETE FROM sample54 WHERE a = (SELECT MIN(a) FROM sample54);- MySQL에서는 동일한 테이블을 서브쿼리에서 사용할 수 없기 때문에 위의 쿼리는 사용할 수 없다.
스칼라 값
// 하나의 행, 하나의 열을 반환하는 패턴
SELECT MIN(a) FROM sample54;- SELECT 명령이 하나의 값만 반환하는 것을 '스칼라 값을 반환한다'고 한다.
// SELECT 구에서 서브쿼리
SELECT
(SELECT COUNT(*) FROM sample51) AS sq1,
(SELECT COUNT(*) FROM sample54) AS sq2;
// SET 구에서 서브쿼리
UPDATE sample54 SET a = (SELECT MAX(a) FROM sample54);
// FROM 구에서 서브쿼리
SELECT * FROM (SELECT * FROM sample54) sq;
// Oracle에서 LIMIT 구의 대체 명령
SELECT * FROM (
SELECT * FROM sample54 ORDER BY a DESC
) sq
WHERE ROWNUM <= 2;
// INSERT, VALUES 구에서 서브쿼리
INSERT INTO sample541 VALUES (
(SELECT COUNT(*) FROM sample51),
(SELECT COUNT(*) FROM sample54)
);
// INSERT, SELECT 결과를 INSERT
INSERT INTO sample541 SELECT 1,2;
// 테이블의 행 복사
INSERT INTO sample542 SELECT * FROM sample543;상관 서브쿼리
- 부모 명령과 자식인 서브쿼리가 특정 관계를 맺는 것을
상관 서브쿼리라고 부른다. - 상관 서브쿼리는 단독 쿼리로 실행할 수 없다.
// EXITS를 사용해 '있음'으로 갱신
UPDATE sample551 SET a = '있음' WHERE
EXISTS (SELECT * FROM sample552 WHERE no2 = no);
// NOT EXITS를 사용해 '없음'으로 갱신
UPDATE sample551 SET a = '없음' WHERE
NOT EXISTS (SELECT * FROM sample552 WHERE no2 = no);
// 열에 테이블명 붙이기
UPDATE sample551 SET a = '있음' WHERE
EXISTS (SELECT * FROM sample552 WHERE sample552.no2 = sample551.no);
// IN의 오른쪽을 서브쿼리로 지정
SELECT * FROM sample551 WHERE no IN
(SELECT no2 FROM sample552);- IN에서는 집합 안에 NULL 값이 있어도 무시하지는 않는다. 하지만 NULL = NULL을 계산할 수 없기 때문에 NULL을 비교하기 위해서는 IS NULL을 사용해야 한다.
- NOT IN의 경우, 집합 안에 NULL 값이 있으면 설령 왼쪽 값이 집합 안에 포함되어 있지 않아도 참을 반환하지는 않는다. 그 결과는 '불명(UNKNWON)'이 된다.
WITH, WITH RECURSIVE
- WITH 구문은 메모리 상에 가상의 테이블을 저장할 때 사용된다.
WITH
WITH CTE AS (
SELECT 0 AS NUM
UNION ALL
SELECT 0 FROM SOME_TABLE # SOME_TABLE의 행 수만큼 반복된다.
)WITH RECURSIVE
// 0에서 10의 값을 갖는 테이블
WITH RECURSIVE CTE AS(
SELECT 0 AS NUM # 초기값 설정
UNION ALL
SELECT NUM+1 FROM CTE
WEHRE NUM < 10 # 반복을 멈추는 조건
)- WITH RECURSIVE 구문은 가상 테이블을 생성하면서 가상 테이블 자신의 값을 참조하여 값을 결정할 때 사용된다.
테이블 작성, 삭제, 변경
// 테이블 생성
CREATE TABLE [Table Name]
// 테이블 삭제
DROP TABLE [Table Name]
// 테이블 모든 행 빠르게 삭제
TRUNCATE TABLE [Table Name]- DELETE 명령은 행 단위로 여러가지 내부처리가 일어나므로 삭제할 행이 많으면 처리속도가 상당히 늦어진다. 이런 경우
TRUNCATE TABLE명령을 사용하면 모든 행을 빠르게 삭제할 수 있다.
// 열 추가
ALTER TABLE sample62 ADD newcol INTEGER;- NOT NULL 제약을 붙인 열을 추가하고 싶다면 먼저 NOT NULL로 제약을 건 뒤에 NULL 이외의 값으로 기본값을 지정할 필요가 있다.
// 열 속성 변경
ALTER TABLE sample62 MODIFY newcol VARCHAR(20);
// 열 이름 변경
ALTER TABLE sample62 CHANGE newcol c VARCHAR(20);
// 열 삭제
ALTER TABLE sample62 DROP c;제약
테이블 작성시 제약 정의
CREATE TABLE sample632 (
no INTEGER NOT NULL,
sub_no INTEGER NOT NULL,
name VARCHAR(30),
CONSTRAINT pkey_sample PRIMARY KEY (no, sub_no)
);- 테이블에 제약을 설정해서 저장될 데이터를 제한할 수 있다.
- a, b열처럼 열에 대해 정의하는 제약을
열 제약이라고 한다. - 한 개의 제약으로 복수의 열에 제약을 설명하는 경우를
테이블 제약이라고 한다. CONSTRAINT키워드로 제약에 이름을 지정할 수 있다.
기존 테이블에 제약 추가
// 열 제약 추가
ALTER TABLE sample631 MODIFY c VARCHAR (30) NOT NULL;
// 테이블 제약 추가
ALTER TABLE sample631 ADD CONSTRAINT pkey_sample631 PRIMARY KEY(a);제약 삭제
// c열의 NOT NULL 제약 없애기
ALTER TABLE sample631 MODIFY c VARCHAR (30);
// pkey_sample631 제약 삭제하기
ALTER TABLE sample631 DROP CONSTRAINT pkey_sample631;
// 기본키는 제약명을 지정하지 않고도 삭제할 수 있다.
ALTER TABLE sample631 DROP PRIMARY KEY;인덱스
// sample62 테이블의 no 열에 isample65라는 인덱스를 지정
CREATE INDEX ismample65 ON sample62(no);
// 인덱스 삭제
DROP INDEX ismample65 ON sample62;
// 실제로 인덱스를 사용해 검색하는지를 확인
EXPLAIN SELECT * FROM sample62 WHERE a = 'a';EXPLAIN은 표준 SQL에는 존재하지 않는 데이터베이스 제품 의존형 명령이다.- 실제로 실행되지는 않고 어떤 상태로 실행되는지를 설명해준다.
possible_keys는 사용될 수 있는 인덱스를 의미하고key는 사용된 인덱스를 의미한다.
뷰
// 열을 지정해 뷰 작성
CREATE VIEW sample_view_672(n, v, v2) AS SELECT no, a, a*2 FROM sample54;
// 뷰 삭제
DROP VIEW sample_view_67;머티리얼라이즈드 뷰(Materialized View)
- 뷰의 근원이 되는 테이블에 보관하는 데이터양이 많은 경우, 집계처리를 할 때도 뷰가 사용된다면 처리속도가 많이 떨어질 수밖에 없다. 이같은 상황을 회피하기 위해 사용하는 것이
머티리얼라이즈드 뷰이다. - 머티리얼라이즈드 뷰는 처음 참조되었을 때 데이터를 저장하고 이후 다시 참조할 때 이전에 저장해 두었던 데이터를 그대로 사용한다. 다만 뷰에 지정된 테이블의 데이터가 변경된 경우에는 SELECT 명령을 재실행하여 데이터를 다시 저장한다.
MySQL에서는 머티리얼라이즈드 뷰를 사용할 수 없고 Oracle과 DB2에서만 사용 가능한 데이터베이스 객체이다.
함수 테이블
- 뷰를 구성하는 SELECT 명령은 단독으로도 실행될 수 있어야 하기 때문에
상관 서브쿼리를 사용할 수 없다. - 이런 약점은
함수 테이블을 사용하여 회피할 수 있다.
복수의 테이블
집합연산
SELECT * FROM sample71_a UNION SELECT * FROM sample71_b;
SELECT a AS c FROM sample71_a UNION SELECT b AS c FROM sample71_b ORDER BY c;- ORDER BY 구에 지정하는 열은 별명을 붙여 이름을 일치시킨다.
// 종북제거 x
SELECT * FROM sample71_a UNION ALL SELECT * FROM sample71_b;- 중복값이 없는 경우에는 UNION ALL을 사용하는 편이 좋은 성능을 보여준다.
테이블 결합
교차결합
SELECT * FROM sample72_x, sample72_y;- 두 개의 테이블을 곱집합으로 계산
내부결합
SELECT 상품.상품명, 재고수.재고수
FROM 상품 INNER JOIN 재고수
ON 상품.상품코드 = 재고수.상품코드
WHERE 상품.상품분류 = '식료품';
SELECT S.상품명, M.메이커명
FROM 상품2 S INNER JOIN 메이커 M
ON S.메이커코드 = M.메이커코드;자기결합
SELECT S1.상품명, S2.상품명
FROM 상품 S1 INNER JOIN 상품 S2
ON S1.상품코드 = S2.상품코드;- 자기결합에서는 결합의 좌우가 같은 테이블이 되기 때문에 이를 구별하기 위해서 반드시 별명을 붙여야 한다.
- 자기 자신의 기본키를 참조하는 열을 자기 자신이 가지는 데이터 구조로 되어 있을 경우에 자주 사용된다.
외부결합
SELECT 상품3.상품명, 재고수.재고수
FROM 상품3 LEFT JOIN 재고수
ON 상품3.상품코드 = 재고수.상품코드
WHERE 상품3.상품분류 = '식료품';- 외부결합은 결합하는 테이블 중에 어느 쪽을 기준으로 할지 결정할 수 있다.
- 결합의 왼쪽이 기준이 된다.
- 오른쪽을 기준으로 하려면
RIGHT JOIN을 사용하면 된다.
관계형 모델
릴레이션(Relation)
- 관계형 모델의 릴레이션은 SQL에서 말하는 테이블이다.
속성: SQL의 열. 속성 이름과 형 이름으로 구성된다.튜플: SQL의 행관계대수: 릴레이션에 대한 연산이 집합의 대한 연산에 대응된다는 이론
데이터베이스 설계
논리명과 물리명
- 실제 데이터베이스에서 사용할
물리명과 설계상에서 사용하는논리명을 분리하기도 한다. - VARCHAR 형으로 지정할 수 있는 크기를 넘어가는 경우에는 LOB(Large Object) 형을 사용한다. LOB 형은 큰 데이터를 다루는 자료형이지만 인덱스를 지정할 수 없다는 단점이 있다.
정규화
정규화
- 테이블을 올바른 형태로 변경하고 분할하는 것
제1정규형
- 테이블에는 하나의 셀에 하나의 값만 저장되도록 한다.
- 반복되는 데이터를 가로(열 방향)가 아닌 세로(행 방향)로 늘리는 것이 제1정규화의 제1단계이다.
- 중복을 제거하는 테이블의 분할도 제1 정규화에 포함된다. 동일한 값을 가지는 행이 여러 개 존재하지 않도록 정리한다.
- 테이블을 분할하고 기본키를 지정한다.
제2정규형
- 기본키에 의해 특정되는 열과 그렇지 않은 열로 나누는 것으로 정규화가 이루어진다.
제3정규형
- 이전과 마찬가지로 중복하는 부분을 찾아내어 테이블을 분할한다.
- 제2정규화의 경우에는 기본키에 중복이 없는지 조사하지만 제3정규화에서는 기본키 이외의 부분에서 중복이 없는지를 조사한다.
정규화의 목적
- 정규화로 데이터 구조를 개선하는 것은
하나의 데이터가 한 곳에 저장되도록 하기 위함이다.
트랜잭션
- 몇 단계로 처리를 나누어 SQL 명령을 실행하는 경우에 사용한다.
- 데이터를 추가하다가 에러가 발생하면 트랜잭션을
롤백해서 종료할 수 있다. 롤백하면 트랜잭션 내에서 행해진 모든 변경사항을 없었던 것으로 할 수 있다. - 아무런 에러가 발생하지 않는다면 변경사항을 적용하고 트랜잭션을 종료하는데, 이때
커밋을 사용하너다. - 트랜잭션을 사용해서 데이터를 추가할 때는
자동커밋을 꺼야 한다.

jjlabsio