
1. 단일행/다중행 연산자
- WHERE 절에서 서브쿼리 결과를 받을때
- 단일행을 받을 수 있는 연산자 (= , =< , != , > 등등..)
- 다중행을 받을 수 있는 연산자 (IN , ANY , ALL , EXISTS 등등..)

- 서브쿼리 실행 결과가 2개 이상의 행을 출력했으므로 IN이 정답!
→ 다중행(2개 이상의 행) 연산!
- 단일행을 받을 수 있는 연산자 : = , >= , < . != 등
→ 비교 연산자는 이미 많이 경험해 봤으므로
- 다중행을 받을 수 있는 연산자 : IN , ANY , ALL , EXISTS , NOT EXISTS 등
→ 우리가 살펴봐야 할 것은 다중 연산자
1.1. 다중행 연산자 < IN >
- 입력된 다중행 중에서 일치하는 값들을 모두 출력

1.2. 다중행 연산자 < ANY >
- 입력된 다중 행 중에서 하나라도 일치하면 출력 (OR로 묶음)

1.3. 다중행 연산자 < ALL >
- 입력된 다중 행 중에서 값이 모두 일치해야 출력 (AND로 묶음)

- 중첩쿼리 실습문제 ( 이전 교육내용 : 중첩쿼리 링크 )
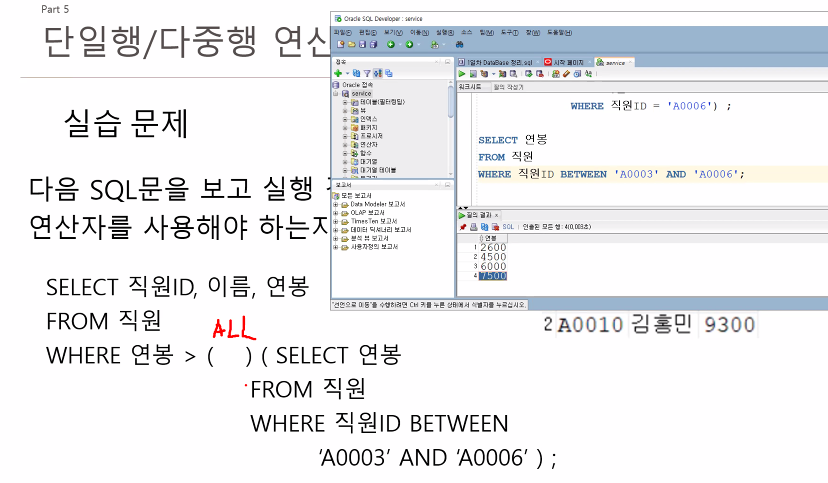
--직원 테이블에서 직원ID가 ‘A0006’인 사람과 같은 연봉을 받는
--직원들의 이름과 연봉을 출력하세요. (단, 중첩서브쿼리와 IN을 사용)
SELECT 이름, 연봉
FROM 직원
WHERE 연봉 IN ( SELECT 연봉
FROM 직원
WHERE 직원ID = 'A0006' );
--IN을 사용하는 이유는 서브쿼리의 결과가
--하나인지 여러개인지 알수 없음으로 IN 다중행연산자를 사용함.정보처리기사에서 나온 SQL 문제 중..
1.4. 다중행 연산자 < EXISTS >
참고 URL : 링크
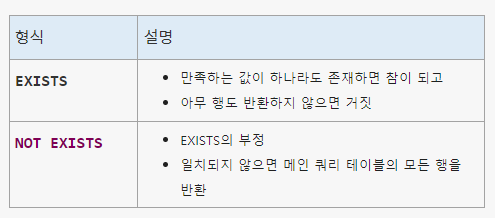
- 입력된 다중 행 중에서 일치하는 행의 존재 여부를 확인
→ 존재하면 TRUE 반환 서브쿼리를 꼭 사용해야 하는 연산자 - 실무에서 정말 많이 사용하는 다중행 연산자
- EXISTS는 상관 서브쿼리에서만 사용 ( 상관 서브쿼리 다시보기 )
- WHERE 뒤에 특정 컬럼을 입력하지 않고 바로 EXISTS 를 입력하여 연산 ( =? )
- 조건에 일치하는 대상을 찾는 순간, 작업을 멈추고 다음 작업 수행 ( 효과적 )
- 상관서브쿼리와 비슷하게 메인쿼리의 컬럼을 참조
--(예시)
--직원연락처에 연락처 데이터값이 있는 직원들만 출력된 값.
SELECT 직원ID, 이름
FROM 직원 A
WHERE EXISTS ( SELECT 1
FROM 직원연락처
WHERE 직원ID = A.직원ID );
-- 여기서 1 은 참(true)의 개념을 가짐(기능적의미가 없음)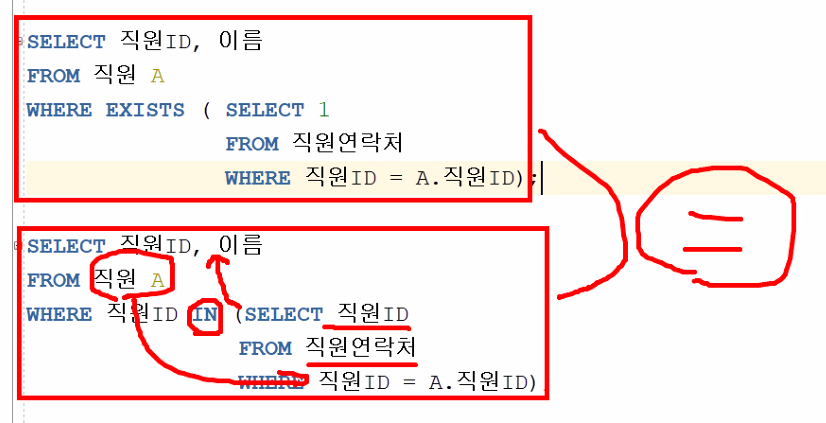
둘의 결과는 같지만 연산(구동) 순서는 다르다.
1.4.1. EXIST 와 IN의 차이점
- IN은 일치하는 모든 것을 출력하기 위해 테이블의 모든 튜플에 접근
→ 출력한 내용을 눈으로 확인해야 할 때 사용 - EXISTS는 일치하는 튜플이 있는 순간 해당 작업 중지
→ 해당 내용이 존재 하는지 확인되기만 하면 테이블의 다른 정보를
보여주고 싶을 때 ( 속도 및 성능 우위 )
- IN
A 테이블 10개 데이터 , B 테이블 13개 데이터
- A의 1번이 B의 데이터 13번까지 모두 조건 비교
- A의 1~ 10까지 B의 데이터 13건 비교하여 총 130번 작업 수행함
- EXISTS
A 테이블 10개 데이터 , B 테이블 13개 데이터
- A의 1번이 B의 데이터가 조건에 맞으면 13번 돌려보지 않고 다음 A의 2번이동
- 반복
- IN에 비해 총 조회수가 현저히 적음(성능면에서 우수함)
(로그인때 자주사용함)
1.5. 다중행 연산자 < NOT EXISTS >
- 입력된 다중 행 중에서 일치하는 행의 존재 여부를 확인
→ 존재하면 FALSE 반환 조건과 일치하지 않는 내용에 대해 TRUE 출력

제가 한 번 해보겠습니다.