1. 함수
(클라우드 교육과정 시험에는 안 나옴.)
1.1. SELECT의 함수
- SELECT 절에서 사용하는 자료형 관련 함수 이외에 시험에 자주 등장하는 순위함수에 대해서 알아보자!
- RANK
- DENCE_RANK
- ROW_NUMBER
1.1.1. 순위 함수 ( RANK , DENCE_RANK , ROW_NUMBER )
- SELECT 절에서 사용하는 함수의 한 종류로, 순위를 나타내는 함수! 개념은 쉽지만 굉장히 중요한 함수
--아래 테이블 정보 등록하기!
CREATE TABLE MEM_TB(
MEM_ID VARCHAR2(10),
MEM_NM VARCHAR2(20),
SCORE NUMBER);
INSERT INTO MEM_TB(MEM_ID, MEM_NM, SCORE) VALUES('A1', '치수', 80);
INSERT INTO MEM_TB(MEM_ID, MEM_NM, SCORE) VALUES('B2', '백호', 85);
INSERT INTO MEM_TB(MEM_ID, MEM_NM, SCORE) VALUES('C3', '대만', 75);
INSERT INTO MEM_TB(MEM_ID, MEM_NM, SCORE) VALUES('D4', '태웅', 85);
INSERT INTO MEM_TB(MEM_ID, MEM_NM, SCORE) VALUES('E5', '태섭', 95);
SELECT *
FROM MEM_TB;
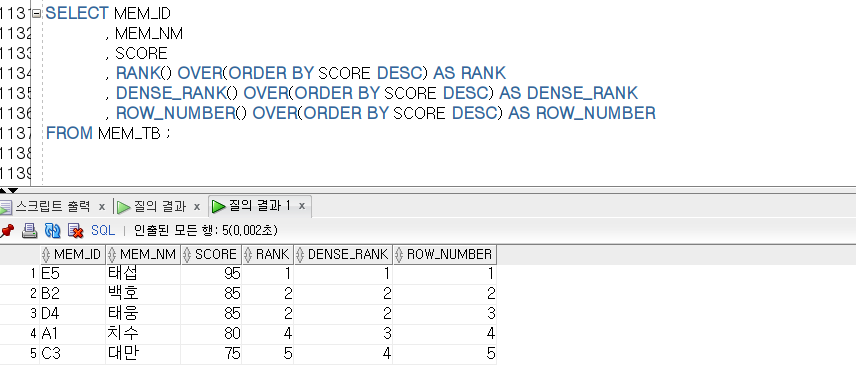
위 이미지에서 SCORE에 따라 순위가 다음과 같은 차이로 표기되었다.
-
RANK : 순위가 중복되면 다음 순위로 넘어 표기됨.
(2등이 2명임으로 3등이 제외되고 4등이 표기) -
DENSE_RANK : 순위 중복 관계없이 모두 표기됨.
-
ROW_NUMBER : 순위 중복 없이 표기함.
1.2. 집합 연산자 ( UNION , UNION ALL , INTERSECT , MINUS , CROSS JOIN )

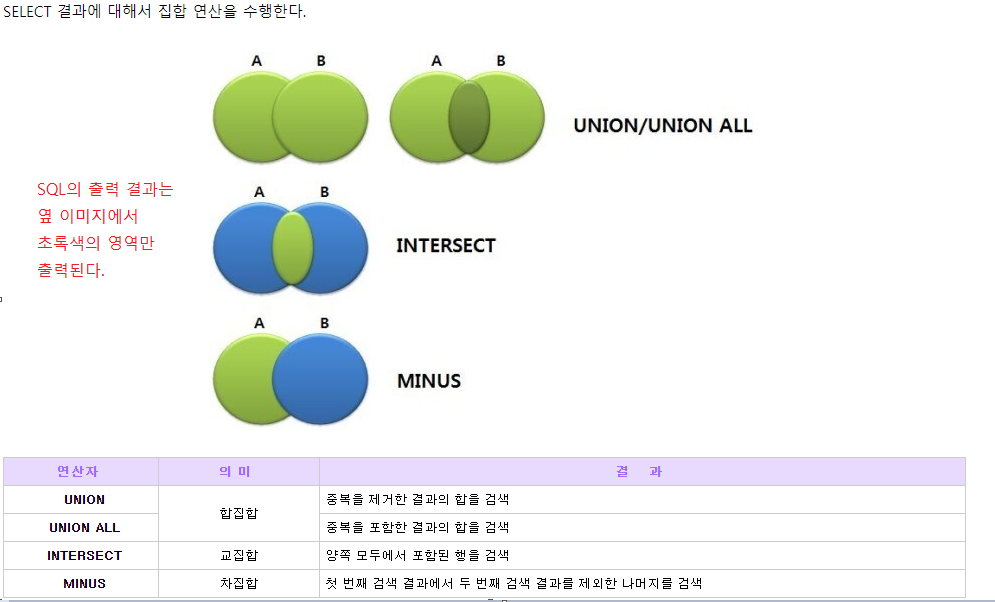
테이블과 테이블 간의 출력 결과를 연산하는 연산자
- UNION : 합집합 ( 중복 제거 (튜플단위) : DEFAULT DISTINCT )
- UNION ALL : 합집합 (중복 허용)
- INTERSECT : 교집합
- MINUS : 차집합
- CROSS JOIN : 곱집합 → CARTESIAN PRODUCT





1.3. GROUP BY 그룹함수
조금 더 고차원 적인 그룹별 집계를 하기 위한 함수
- GROUPING SETS : 인수들에 대한 개별 집계 출력
- ROLLUP : 명시한 컬럼의 그룹별 결과와 총 데이터의 집계 출력
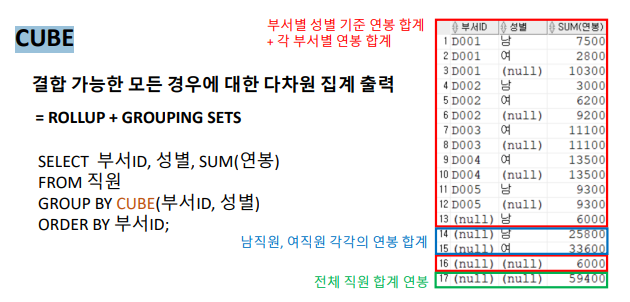
- CUBE : 결합 가능한 모든 경우에 대한 다차원 집계 출력
→ 각 부서별 남, 여 직원의 연봉 값을 통해 알아보자! (성별 수정)
1.3.1. GROUPING SETS
- 인수들에 대한 개별 집계 출력
(예시) 출력 값 비교해보기 ( SQL문 및 출력결과 아래 이미지 참조 )
--부서ID의 남, 여 합계를 모두 보여줌.
SELECT 부서ID, 성별, SUM(연봉)
FROM 직원
GROUP BY 부서ID, 성별
ORDER BY 부서ID ;--부서ID 별 합계와 성별 합계 를 모두 보여줌.
SELECT 부서ID, 성별, SUM(연봉)
FROM 직원
GROUP BY GROUPING SETS(부서ID, 성별)
ORDER BY 부서ID ;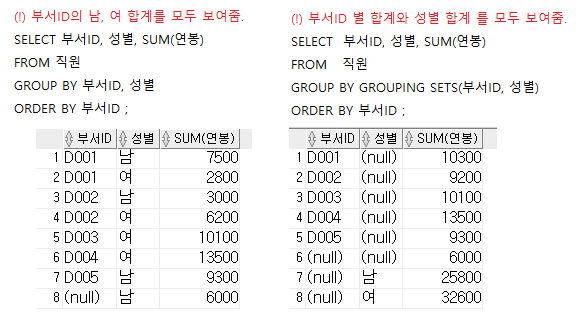
1.3.2. ROLLUP
명시한 컬럼의 그룹별 결과와 총 데이터의 집계 출력

1.3.3. CUBE
결합 가능한 모든 경우에 대한 다차원 집계 출력
= ROLLUP + GROUPING SETS
-- 실습 예제 전 SQL쿼리문 적용하기!
DROP TABLE 수강생정보 CASCADE CONSTRAINTS;
DROP TABLE 성적표 CASCADE CONSTRAINTS;
CREATE TABLE 수강생정보 (
학생ID VARCHAR2(9) PRIMARY KEY ,
학생이름 VARCHAR2(50) NOT NULL ,
소속반 VARCHAR2(5)
);
CREATE TABLE 성적표 (
학생ID VARCHAR2(9) ,
과목 VARCHAR2(30) ,
성적 NUMBER ,
CONSTRAINT PK_성적표 PRIMARY KEY(학생ID , 과목) ,
CONSTRAINT FK_성적표_REF_수강생 FOREIGN KEY(학생ID) REFERENCES 수강생정보(학생ID)
) ;
INSERT INTO 수강생정보 VALUES ('S0001' , '김현철' , 'A') ;
INSERT INTO 수강생정보 VALUES ('S0002' , '문현중' , 'A') ;
INSERT INTO 수강생정보 VALUES ('S0003' , '강문치' , 'B') ;
INSERT INTO 수강생정보 VALUES ('S0004' , '박나선' , 'B') ;
INSERT INTO 수강생정보 VALUES ('S0005' , '신태강' , 'B') ;
INSERT INTO 수강생정보 VALUES ('S0006' , '물고기' , 'C') ;
INSERT INTO 수강생정보 VALUES ('S0007' , '자라니' , 'C') ;
INSERT INTO 수강생정보 VALUES ('S0008' , '공팔두' , 'C') ;
INSERT INTO 수강생정보 VALUES ('S0009' , '최팔현' , 'C') ;
INSERT INTO 성적표 VALUES('S0001' ,'국어' , 90);
INSERT INTO 성적표 VALUES('S0001' ,'수학' , 85);
INSERT INTO 성적표 VALUES('S0001' ,'영어' , 100);
INSERT INTO 성적표 VALUES('S0002' ,'국어' , 100);
INSERT INTO 성적표 VALUES('S0002' ,'수학' , 100);
INSERT INTO 성적표 VALUES('S0002' ,'영어' , 20);
INSERT INTO 성적표 VALUES('S0003' ,'국어' , 100);
INSERT INTO 성적표 VALUES('S0003' ,'수학' , 100);
INSERT INTO 성적표 VALUES('S0003' ,'영어' , 20);
INSERT INTO 성적표 VALUES('S0004' ,'국어' , 85);
INSERT INTO 성적표 VALUES('S0004' ,'수학' , 40);
INSERT INTO 성적표 VALUES('S0004' ,'영어' , 60);
INSERT INTO 성적표 VALUES('S0005' ,'국어' , 100);
INSERT INTO 성적표 VALUES('S0005' ,'수학' , 100);
INSERT INTO 성적표 VALUES('S0005' ,'영어' , 100);
INSERT INTO 성적표 VALUES ( 'S0006' , '국어' , NULL ) ;
INSERT INTO 성적표 VALUES ( 'S0006' , '수학' , NULL ) ;
INSERT INTO 성적표 VALUES ( 'S0006' , '영어' , NULL ) ; - GROUPING SETS, ROLLUP, CUBE 실습예제
/*
성적표 테이블은 학생ID, 과목, 성적 컬럼으로 구성된 테이블이다.
그룹함수 3가지를 사용하여 성적 합계에 대한 결과를 미리 예측하고
실제 답과 비교해 보자
*/
SELECT 학생ID, 과목, SUM(성적)
FROM 성적표
GROUP BY GROUPING SETS(학생ID, 과목)
ORDER BY 학생ID;
SELECT 학생ID, 과목, SUM(성적)
FROM 성적표
GROUP BY ROLLUP(학생ID, 과목)
ORDER BY 학생ID;
SELECT 학생ID, 과목, SUM(성적)
FROM 성적표
GROUP BY CUBE(학생ID, 과목)
ORDER BY 학생ID;1.4. 절차형 SQL
SQL을 절차적으로 프로그래밍하여 사용하는 기술


1.4.1. 위 절차형 sql의 종류와 특징에 대한 이론정보.
프로시저, 사용자 정의함수, 트리거 로 구분됨
위 3가지도 엄연히 함수다. (예시) f(x) = y
x 값에 무엇을 넣느냐에 따라 달라짐.
프로시저, 사용자 정의함수 = 일련의 sql을 절차적으로 처리할 수 있도록 정의하였음
프로시저 => 리턴 값이 없음
사용자 정의함수 => 리턴 값이 있음 (y값이 보여짐)
트리거 = 삽입, 삭제, 갱신 이벤트 발생시 관련 작업이 자동적으로 수행 (사용자가 직접 실행 안됨)
트리거는 에러 발생시 에러 출력 문구등이 트리거를 사용한 것임.
절차형 sql의 예시
트리거 => 리턴 값이 없음

제가 한 번 해보겠습니다.