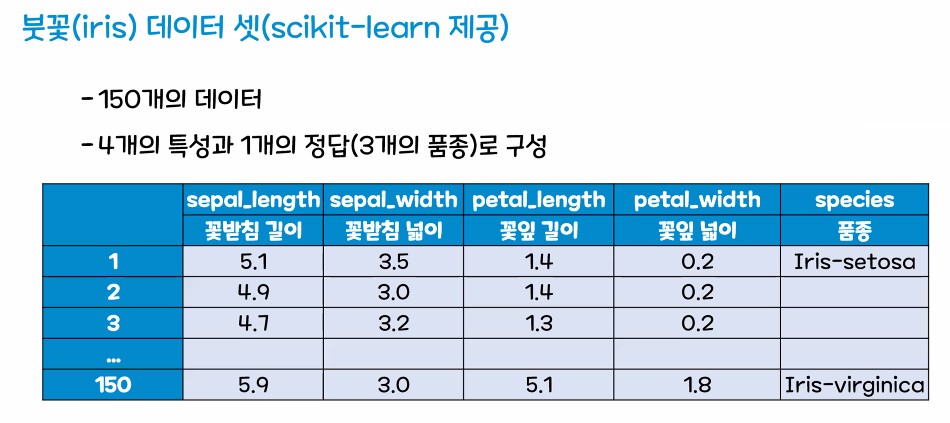
1. 공의 특성에 대해 학습


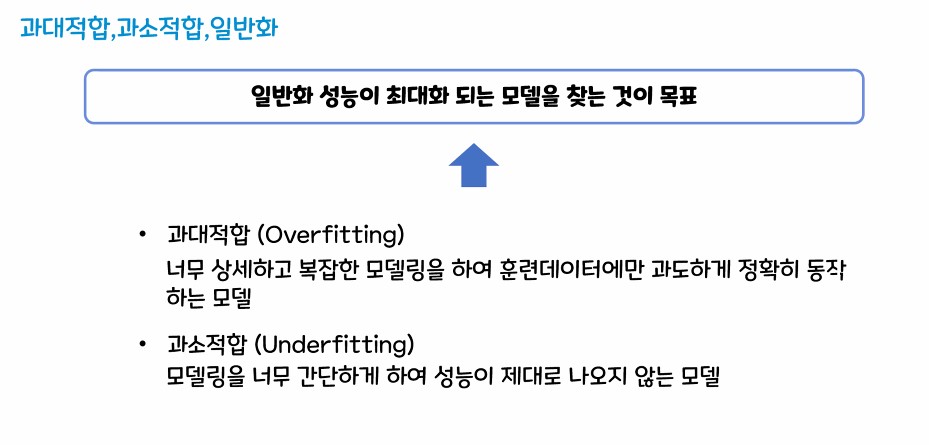
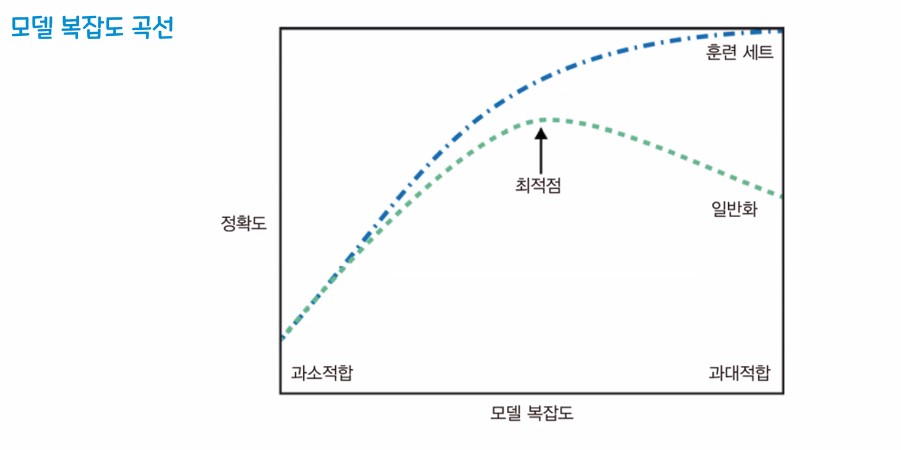
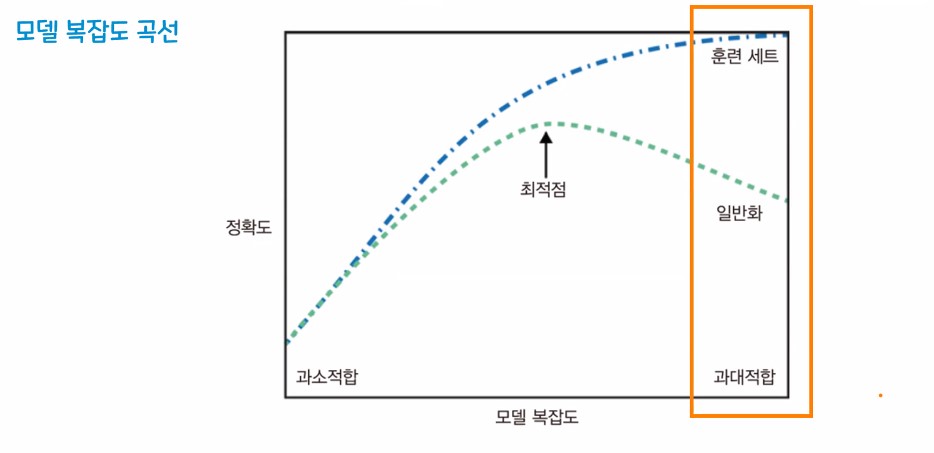
2. 과대적합, 과소적합, 일반화
-
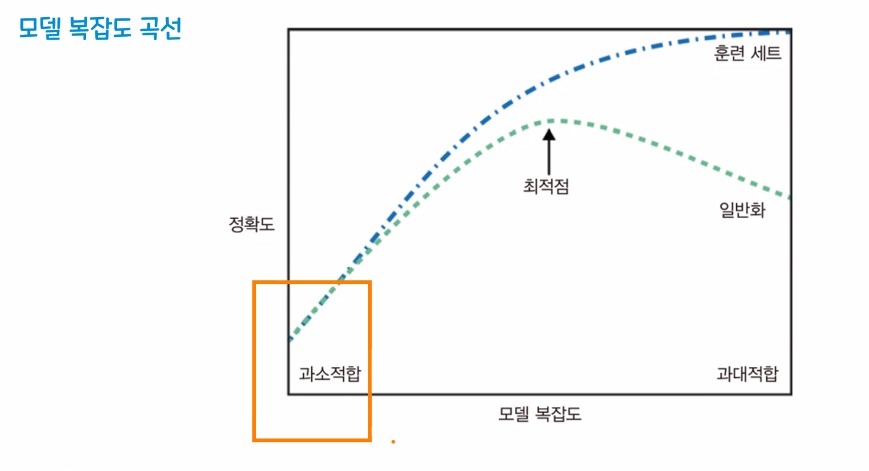
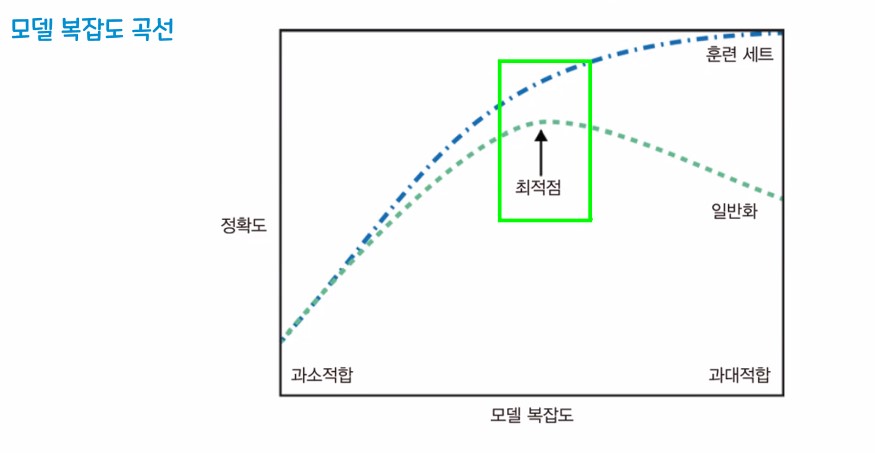
과대적합 - 훈련 데이터 셋은 성능이 잘 나오지만, 평가 데이터는 성능이 잘 안나오는 경우(과도하게 학습)
-
과소적합 - 훈련 데이터/ 평가 데이터 모두 성능이 잘 안나오는 경우
(학습이 제대로 이루어지지 않은 경우) -
일반화 - 훈련셋에서 적정 수준의 성능이 나오고 새로운 평가셋을 사용했을때 훈련셋과 비슷한 성능이 나오는 것을 기대할 수 있는 상태
※ 우리의 최종 목표
- 일반화가 가장 잘 되면서 성능이 나올 것을 기대할 수 있는 상태
 |
 |
 |
 |

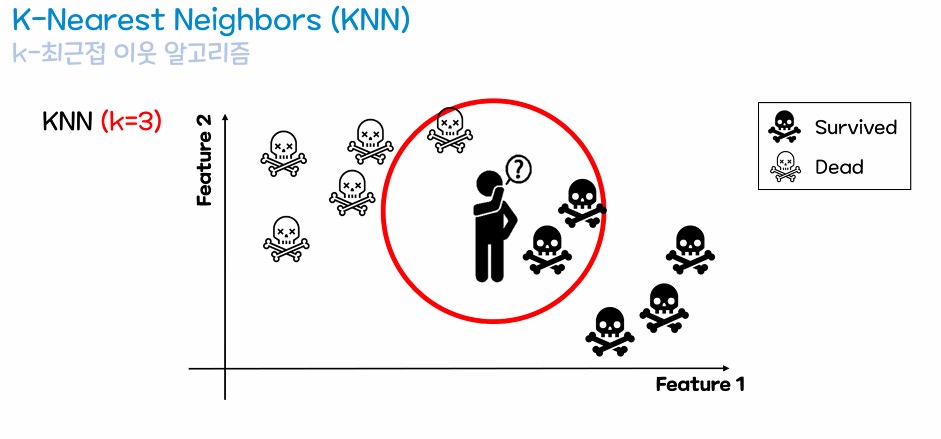
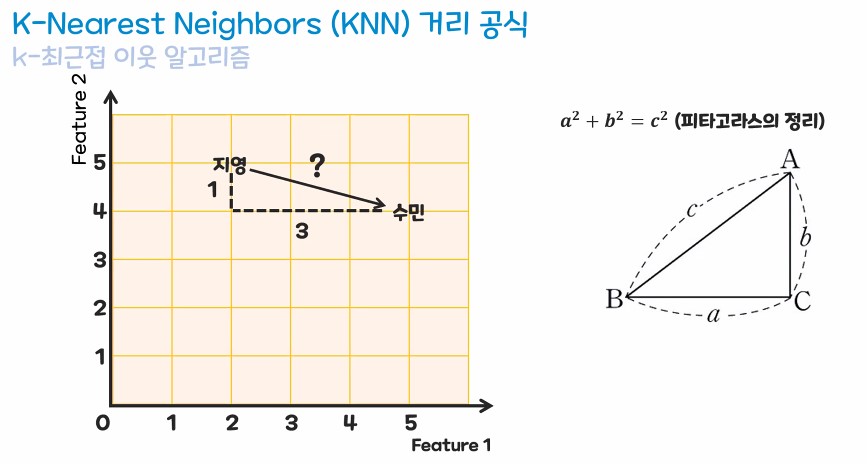
3. 최근접 이웃 알고리즘(KNN)
- 4글자로 표현하면 => 유유상종
- 띠리띠리 뭉쳐 다닌다.
- 주변의 이웃 값을 보고 새로운 데이터의 값을 예측하는 알고리즘
- 주변의 가까운 이웃을 보기 때문에 거리라는 기준으로 이웃을 판단
- 유클리디언 거리 공식을 사용한다.
- n_neighbores : 주변의 이웃 데이터를 몇개나 볼 것인가? (기본값은 5)
- info 함수 - 데이터의 프레임의 기본 정보를 요약정리 해주는 함수
- describe 함수 - 기술통계 확인 함수
- 기술 통계 - 데이터가 가지고 있는 통계정보들을 서술
- 갯수, 평균, 표준 편차, 최소 / 최대값, 사분위수




4. KNN 실습 - 붓꽃 분류하기
1. 목표설정
- KNN 모델을 이용해서 붓쏯의 품종을 분류해보자
- KNN 모델의 사용법을 익혀보자
- 하이퍼 파라미터 조정을 해보자
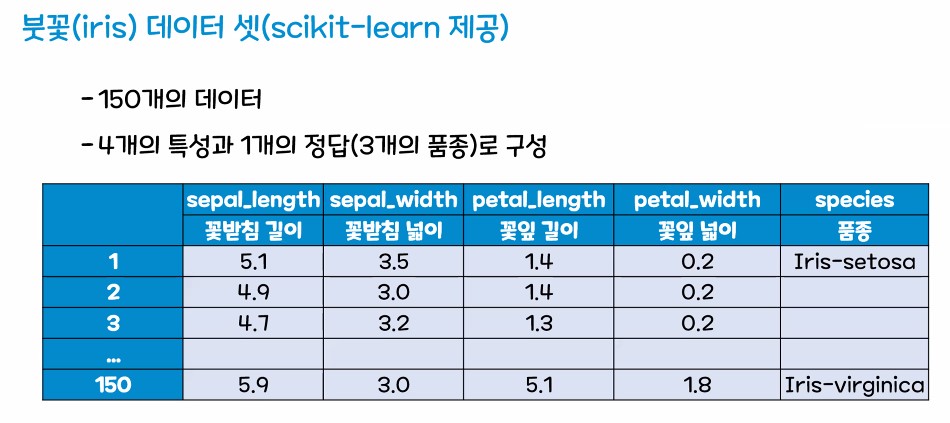
2. 데이터 확보
- 데이터를 어떻게 확보해야 할까?
- 사이킷 런 에서 제공하는 데이터를 사용하자 !
3. 실습해보기
3.1. 목표설정
- KNN 모델을 이용해서 붓쏯의 품종을 분류해보자
- KNN 모델의 사용법을 익혀보자
- 하이퍼 파라미터 조정을 해보자
- 사이컷 런에서 데이터를 가져와보자!
# 필요한 라이브러리 불러오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 데이터 셋 확보
# from sklearn.datasets : 사이킷런에서 제공하는 데이터 세트 모음집
from sklearn.datasets import load_iris # 붓꽃 품종 데이터
# 데이터 객체 생성하기
iris = load_iris()3.2. 데이터 확보
- 데이터를 어떻게 확보해야 할까?
- 사이킷 런 에서 제공하는 데이터를 사용하자 !
#iris 값 확인 해보기 !
iris -
iris의 데이터 중...
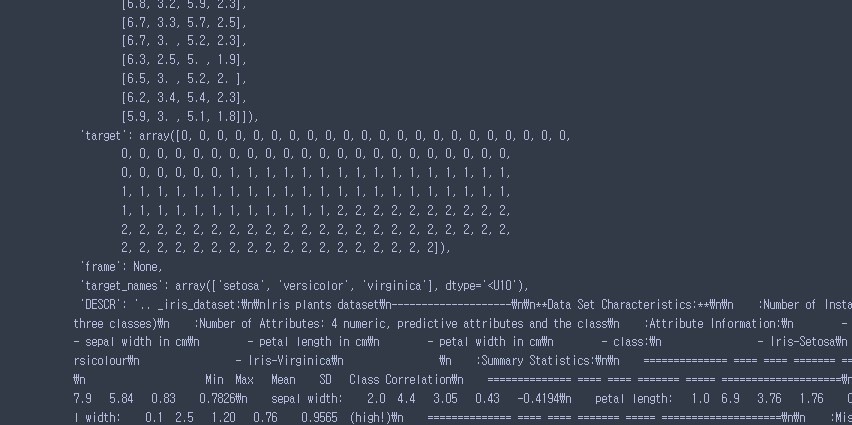
-
iris 타입을 확인해보자 !
type(iris)
# bunch : '다발' 이라는 뜻을 가짐
# 같은 데이터들을 모아주고 있다. 데이터 다발 및
# 중괄호()를 사용해서 딕셔너리와 유사한 구조
# 현재 iris 데이터는 붓꽃에 관한 데이터만 묶어놓은 상태 (붓꽃 다발)sklearn.utils._bunch.Bunch
# 하나로 뭉쳐진 딕셔너리 형태의 데이터를 나누기 위한 기준을 확인하자 !
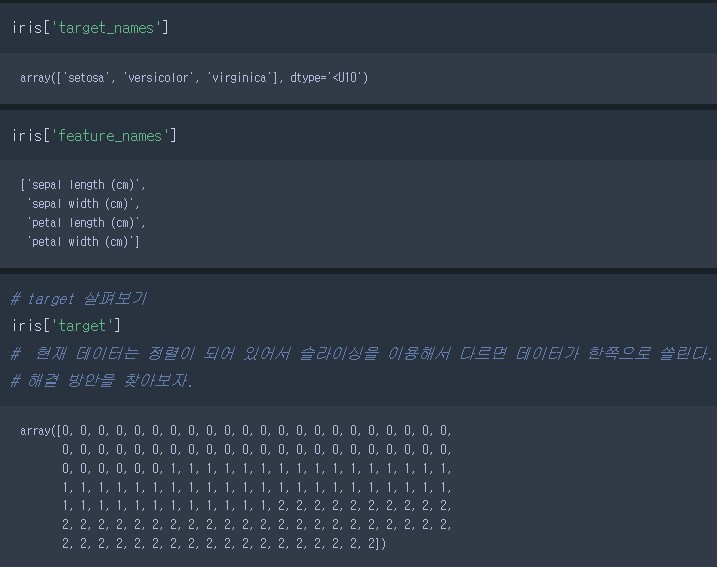
iris.keys()dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
- iris 데이터의 종류
- 'data' : 꽃의 정보(문제 데이터) - 필수 데이터
- 'target' : 꽃의 품종(정답 데이터) - 필수 데이터 (0:setosa, 1:verginica, 2:versicolor)
#' target_names' : 정답의 실제 이름 - 선택 데이터 - 'feature_names' : 특성 이름 - 선택 데이터
- 'DESCR' : Readme(설명서) - 선택 데이터이지만 한번씩은 꼭 체크할 것
- 'data', 'target', 'target_names', 'DESCR', 'feature_names'
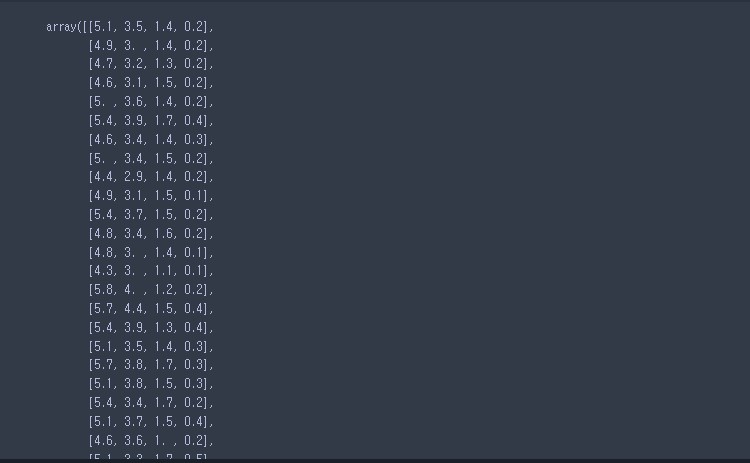
- 데이터 하나씩 확인 해보기
# data 살펴보기
iris['data'] # 2차원의 넘파이 배열 / 실수형
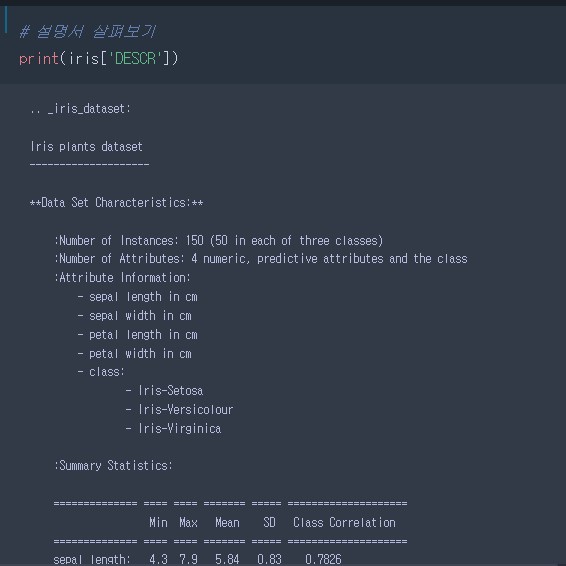
- 데이터 확인 후 문제점 정리
- 문제 데이터의 가독성이 떨어진다.
- 정답 데이터가 정렬이 되어 있어 슬라이싱으로 데이터 분할 불가
# 1. 문제 데이터 + 가독성 올려주기
iris_df = pd.DataFrame(iris['data'], columns = iris['feature_names'])
iris_df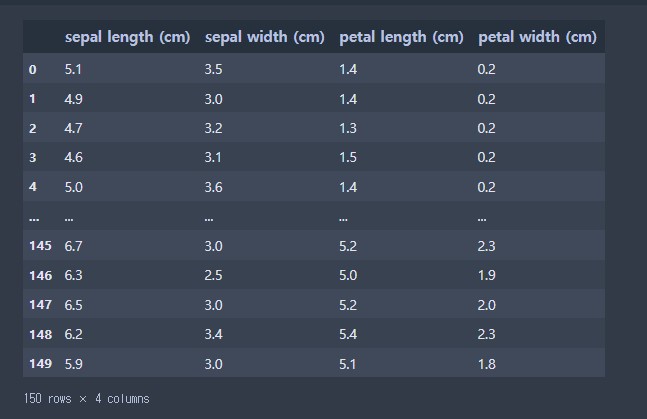
- 정답 데이터를 랜덤으로 섞어주자
- 현제 파일 데이터는 오름차순으로 되어 있어 데이터 인덱스를 변경해주자
# 2. 정답 데이터를 섞어서 분할을 해주자
# 데이터 분할 도구 import
from sklearn.model_selection import train_test_split
# train_test_split( 문제 데이터 ,
# 정답 데이터 ,
# test_size = 평가 데이터 셋의 비율 ,
# random_state = 데이터를 어떤 랜덤시드로 섞어줄 것인가?)
X_train, X_test, y_train, y_test = train_test_split( iris_df,
iris['target'],
test_size =0.3,
random_state = 65)
# 값이 제대로 적용되어 있는지 확인
X_train.shape, X_test.shape, y_train.shape, y_test.shape- 총 150 데이터에서
- X_train : 105개, 4분류
- X_test : 45개
- y_train : 105개
- y_test : 45개
((105, 4), (45, 4), (105,), (45,)) # 알맞게 데이터가 들어가 있음
# np.bincount(data) : pandas의 pd.value_count()와 똑같은 기능(넘파이 배열)
np.bincount(y_train)array([34, 36, 35], dtype=int64)
3.3. 데이터 전처리
- 데이터확인 후 전처리 작업하기
iris_df.info()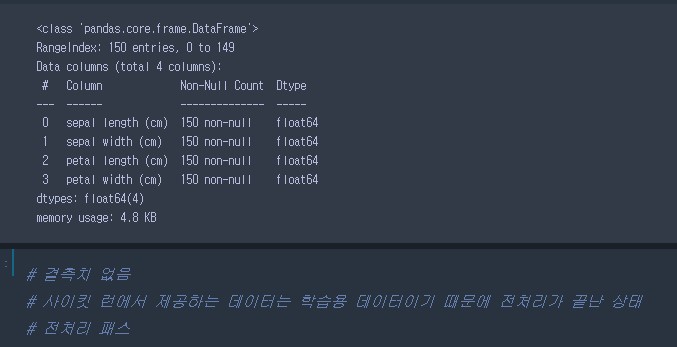
3.4.EDA(탐색적 데이터 분석)
- 산점도 행렬을 그려서 데이터 분포를 파악하자!
# 산점도 행렬 : scatter_matrix : 한번의 변수들 간의 관계를 확인하기 편한 기능
pd.plotting.scatter_matrix( iris_df,
figsize=(10,10),
c = iris['target'],
alpha = 0.9)
plt.show()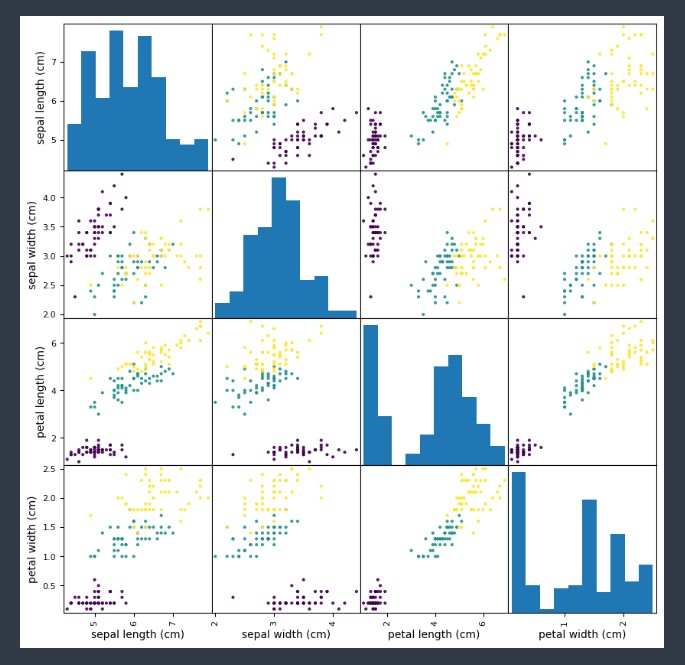
3.5. 모델링
- KNN 모델 사용
# 모델 import
# sklearn.neighbors : 이웃 알고리즘 모음집
# KNN 모델은 분류 기능 / 회귀 가능 - 모델을 구분
# TMI.
# Classifier - 분류 모델
# Regression - 회귀 모델
from sklearn.neighbors import KNeighborsClassifier
# 모델 객체 생성(하이퍼 파라미터 (기본) )
knn_model = KNeighborsClassifier()
# 모델 학습 - fit()
knn_model.fit(X_train, y_train)
# 모델 예측 - predkct(평가용 문제 데이터)
rs = knn_model.predict(X_test)
print(f"테스트 셋 전체를 이용한 예측 결과 값 : \n{rs}")
print(f"\n예상되는 품종은 ? : \n{iris['target_names'][rs]}")테스트 셋 전체를 이용한 예측 결과 값 :
[2 2 0 1 0 2 0 0 2 1 0 1 2 0 0 0 1 1 2 2 2 2 2 2 0 2 0 2 1 0 1 2 0 1 1 1 2
0 2 2 0 0 1 1 0]예상되는 품종은 ? :
['virginica' 'virginica' 'setosa' 'versicolor' 'setosa' 'virginica'
'setosa' 'setosa' 'virginica' 'versicolor' 'setosa' 'versicolor'
'virginica' 'setosa' 'setosa' 'setosa' 'versicolor' 'versicolor'
'virginica' 'virginica' 'virginica' 'virginica' 'virginica' 'virginica'
'setosa' 'virginica' 'setosa' 'virginica' 'versicolor' 'setosa'
'versicolor' 'virginica' 'setosa' 'versicolor' 'versicolor' 'versicolor'
'virginica' 'setosa' 'virginica' 'virginica' 'setosa' 'setosa'
'versicolor' 'versicolor' 'setosa']
# 모델 성능평가 import
from sklearn.metrics import accuracy_score
# 모델 평가
accuracy_score(y_test, rs)0.9111111111111111
3.6. 하이퍼 파라미터 조정
- KNN 모델의 대표적인 하이퍼 파라미터는 n_neighbors
- n_neighbors를 이용해서 이웃 값을 조정 해보자
# 모델 객체 생성
knn_model2 = KNeighborsClassifier(n_neighbors=i)
# 모델 학습(하이퍼 파라미터 - 임의의 값으로 넣어보기)
knn_model2.fit(X_train, y_train)
rs = knn_model2.predict(X_test)
# 모델 평가(score) - 하이퍼 파라미터 : 4 설정
accuracy_score(y_test, rs)0.9777777777777777
- 경고창 무시하는 기능
# 경고창 무시
import warnings
warnings.filterwarnings('ignore')- 이웃의 갯수를 바꿔주는 반복문을 이용해서 하이퍼 파라미터별 성능을 살펴보자
# 정확도를 담아줄 리스트드 만들어주기
train_list = []
test_list = []
# 1에서 100개까지의 값을 세팅한 반복문을 만들어주자
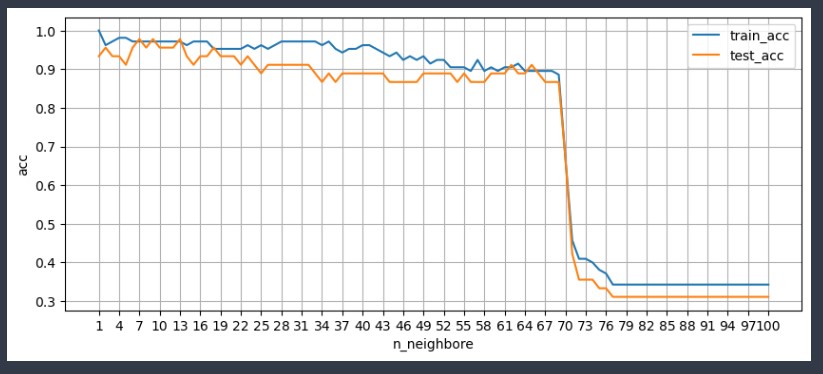
for i in range(1, 101) :
# 모델 생성
knn_clf = KNeighborsClassifier(n_neighbors= i )
# 모델 학습
knn_clf.fit(X_train, y_train)
# 훈련세트 정확도 저장
train_score = knn_clf.score(X_train.values, y_train)
train_list.append(train_score)
# 평가셋트 정확도 저장
test_score = knn_clf.score(X_test.values, y_test)
test_list.append(test_score)
# 하이퍼 파라미터를 살펴볼 그래프를 그려주자
plt.figure(figsize=(10,4))
plt.plot(range(1,101), train_list, label='train_acc')
plt.plot(range(1,101), test_list, label='test_acc')
plt.grid()
plt.legend() # 범례
plt.xticks(range(1, 101, 3)) # 눈금값
plt.ylabel('acc')
plt.xlabel('n_neighbore')
plt.show()