
1. bmi 데이터 학습해보기
- 쥬피터 실행
- 03.머신러닝 새폴더 생성
- 카톡에서 데이터 다운
- 머신러닝 폴더에 data 폴더 생성
- data 폴더내 3에서 다운 받은 파일 넣기
- ex01 bmi 데이터 학습해보기 이름으로 파이선 파일 생성
1.1. 사분위수 :
-
min, 25%, 50%, 75%, max
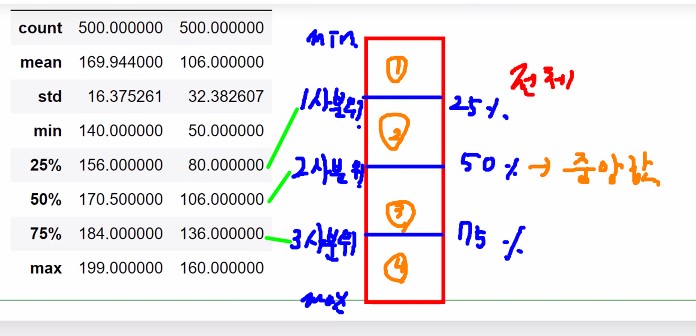
-
사분위수 기준으로 잡아줌
-
IQR = (Q1 ~ Q3) 범위
- 1사분위 Q1
- 2사분위 메디안 Q2
- 3사분위 Q3
- 최소 이상치 기준
- Q1 - IQR * 1.5
- 최대 이상치 기준
- Q3 + IQR * 1.5
-
결측치와 이상치는 대체 값으로 채워주거나 변경하고 상황에 따라 삭제하는 경우도 있다.
1.2. 머신러닝 적용해보기
- 머신러닝 구조
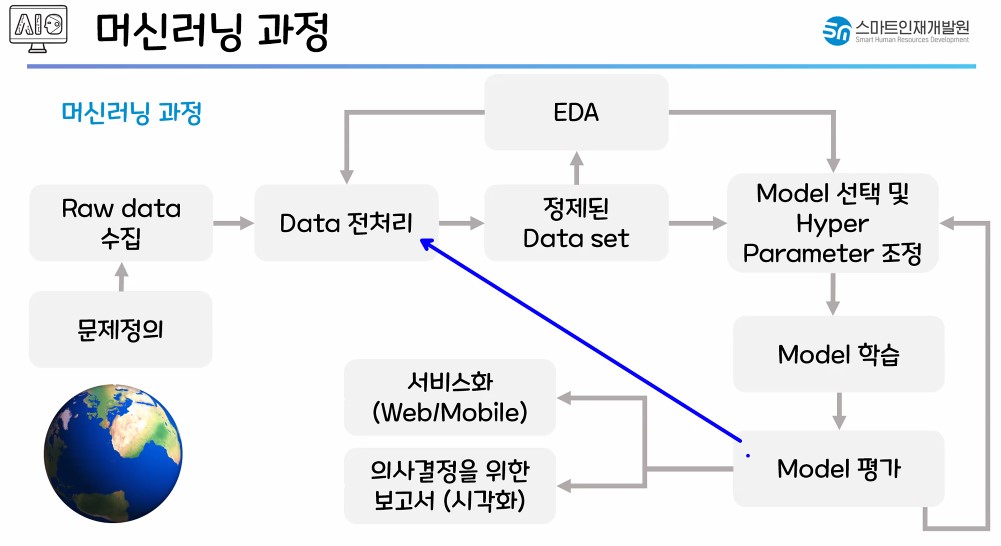
라이브러리 정리
- Scikit-learn : 파이선에서 쉽게 사용할 수 있는 머신러닝 프레임워크
1) 문제 정의
- 500명의 키와 몸무게, 비만도 라벨을 이용해서 비만을 판단하는 모델을 만들어보자.
- 머신러닝의 전반적인 과정을 이해해보자.
# 필요한 라이브러리 불러오기
import pandas as pd
import matplotlib.pyplot as plt
# 모델불러오기
from sklearn.neighbors import KNeighborsClassifier2) 데이터 수집
- 배포된 bmi_500.csv 파일 이용하기
# 데이터 로드
data = pd.read_csv("./data/bmi_500.csv", index_col = 'Label')
data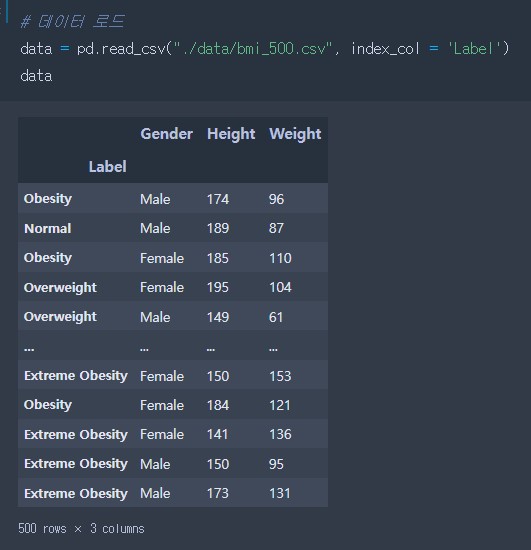
# 데이터 정보 확인하기
# 전체 행, 컬럼 정보(이름), 결측치 여부, 데이터 타입
data.info()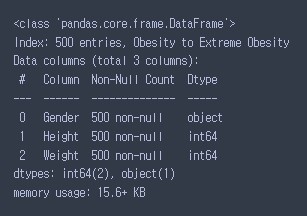
3. 데이터 전처리
- 학습용 데이터 : 전처리가 완료된 데이터
- 이미 정리가 된 데이터이기 깨문에 별도로 진행하지 않음 : Pass
4.EDA (탐색적 데이터 분석)
- 기술통계 확인
- 간단한 시각화를 통한 데이터 분포 현황 확인
# 기슬 통계획인 :
# 수치형 데이터와 범주형 데이터가 섞인 경우 수치형 데이터만 출력
data.describe()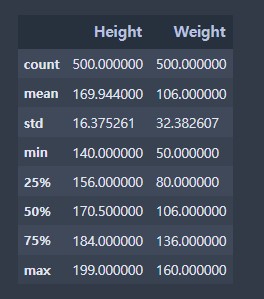
# Label의 유니크 값 확인
# 현재 라벨의 위치는 어디일까요? - index에 위치
data.index.unique()
# 'Obesity' : 비만
# 'Normal' : 보통
# 'Overweight' : 과체중
# 'Extreme Obesity' : 고도비만
# 'Weak' : 저체중
# 'Extremely Weak' : 심각한 저체중Index(['Obesity', 'Normal', 'Overweight', 'Extreme Obesity', 'Weak', 'Extremely Weak'], dtype='object', name='Label')
# 각 Label 별 갯수 알아보기
data.index.value_counts()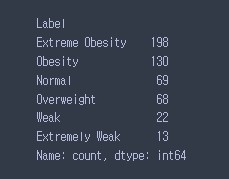
# 위에 그래프를 그려주는 함수 정의
def draw_bmi(label, color) :
d = data.loc[label]
plt.scatter(d['Height'], d['Weight'], c=color, label=label)
# 'Obesity', 'Normal', 'Overweight', 'Extreme Obesity', 'Weak', 'Extremely Weak'
# 위에서 만든 함수를 이용해서 그래프를 만들어 보자
draw_bmi('Obesity', 'orange')
draw_bmi('Normal', 'blue')
draw_bmi('Overweight', 'cyan')
draw_bmi('Extreme Obesity', 'red')
draw_bmi('Weak', 'green')
draw_bmi('Extremely Weak', 'yellow')
plt.legend() # 범례 출력
plt.show()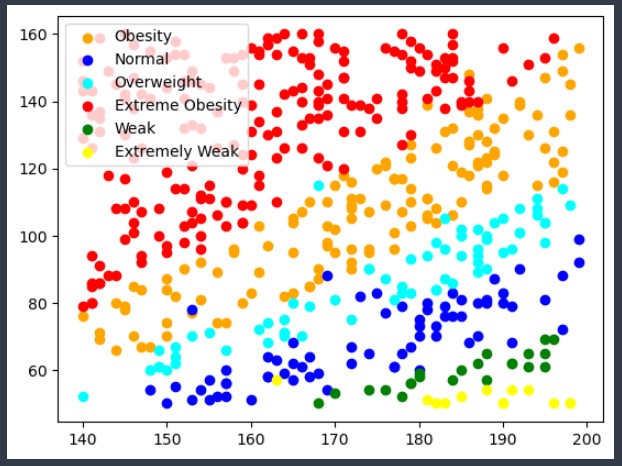
5. 모델 선택 및 하이퍼파라미터 조정
- 뒤에서 배울 KNN 모델 사용해보기
모델불러오기
from sklearn.neighbors import KNeighborsClassifier
# 위쪽에서 모델 import는 실행했다!
# 모델을 사용하기 편하도록 모델 객체를 생성해주자.
# 소괄호의 의미 : 데이터가 들어갈 공간 및 하이퍼 파라미터 조절 부분
knn_bmi = KNeighborsClassifier()
# 데이터 분할
# 현재 데이터의 형태 -> 모든 데이터가 섞여 있는 구조
# 1차 분할(문제/정답 분할)
X = data.iloc[:,1:3]
y = data.index
# 2차분할(훈련/평가 분할)
X_train = X.iloc[350]
y_train = y[ : 350]
X_test = X.iloc[350 : ]
y_test = y[350 : ]
# 위의 과정을 한번에 처리하자
# 훈련용 데이터 셋
X_train = data.iloc[ : 350, 1 : 3]
y_train = data.index[ : 350]
# 평가용 데이터 셋
X_test = data.iloc[350 : , 1 : 3]
y_test = data.index[350 : ]
# 데이터 분할 확인
# 데이터의 형태가 바뀌거나, 삭제, 추가 등 변환되는 부분이 있다면 무조건 체크를 하고 넘어갈 것 !
# 데이터 변경에 있어서 데이터 오염 문제가 있기 때문에 주기적인 확인 필요
X_train.shape, X_test.shape, y_train.shape, y_test.shape ((350, 2), (150, 2), (350,), (150,))
- 모델 학습
# 모델 학습 - 무슨 데이터 셋을 넣어줘야 컴퓨터가 학습을 할까 ? : train 셋트를 넣어주자
# fit(훈련용 문제 데이터, 훈련용 정답 데이터)
knn_bmi.fit(X_train, y_train)
- 예측 값 얻어보기 (rs)
# 학습된 모델을 이용해서 예측값을 얻어내보자 - 무슨 데이터가 들어가야할까?
# predict(평가용 문제 데이터)
# 예측은 학습한 패턴을 가지고 새로운 값을 찾아내는 작업 - 정답을 넣으면 안된다.
rs = knn_bmi.predict(X_test)
rs

# 모델 성능 평가
# from sklearn.metrics : 평가지표 모음집
# accuracy_score : 정확도 평가지표
from sklearn.metrics import accuracy_score
accuracy_score(y_test, rs)0.9066666666666666
# 하이퍼 파라미터 변경
knn_bmi2 = KNeighborsClassifier(n_neighbors=3)
# 모델 학습
knn_bmi2.fit(X_train, y_train)
# 모델 예측
rs = knn_bmi2.predict(X_test)
rs
# rs에 뽑힌 데이터 키와 몸무게를 기준으로 알아서 기준을 연산 후 인덱스의 패턴으로 작성한 내용이다.
# 컴퓨터가 패턴을 찾아서 결과 도출 -> 원래 정답과 비교 !
# 정답률 90% 정도..!
# accuracy_score(y_test, rs) 와 다른 방법으로 평가 해보기
knn_bmi2.score(X_test, y_test)0.9
번외편..
- 자신의 키와 몸무게를 넣어서 비만도를 측정해보자
# 번외 - 자신의 키와 몸무게를 넣어서 비만도를 측정해보자
knn_bmi.predict([[183, 85]])C:\Users\smhrd4\anaconda3\Lib\site-packages\sklearn\base.py:464: UserWarning: X does not have valid feature names, but KNeighborsClassifier was fitted with feature names
warnings.warn(array(['Overweight'], dtype=object)
=> 'Overweight' 과체중이다..

제가 한 번 해보겠습니다.