0. 머신러닝 이란?

0.1. 머신러닝의 등장
rule based expert system의 문제점.
-
if, else 로 나뉜 조건별 선택
-
포함되지 않은 조건은 처리 불가.
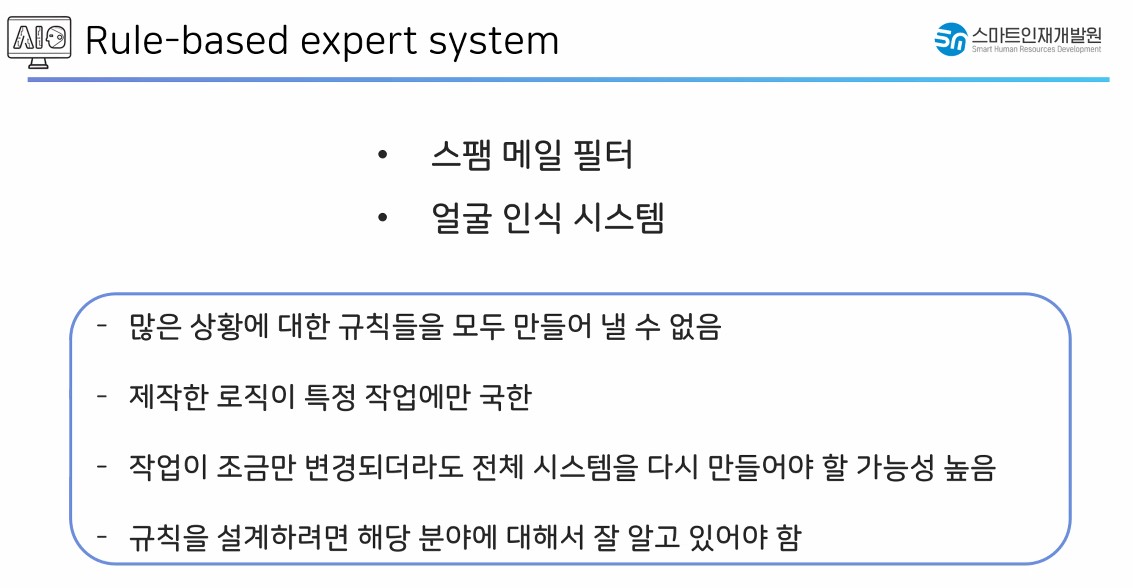
-
머신러닝으로 해답을 찾음.

0.2. 머신러닝 학습방법
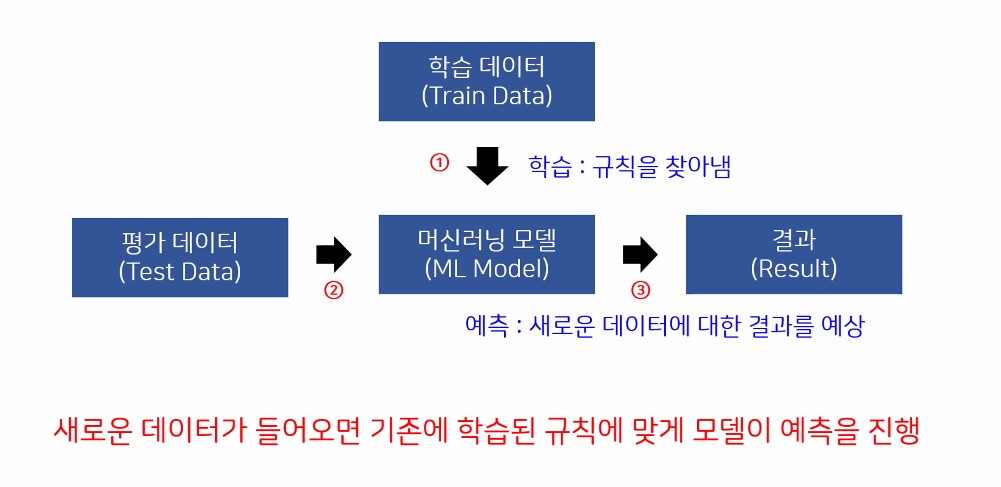
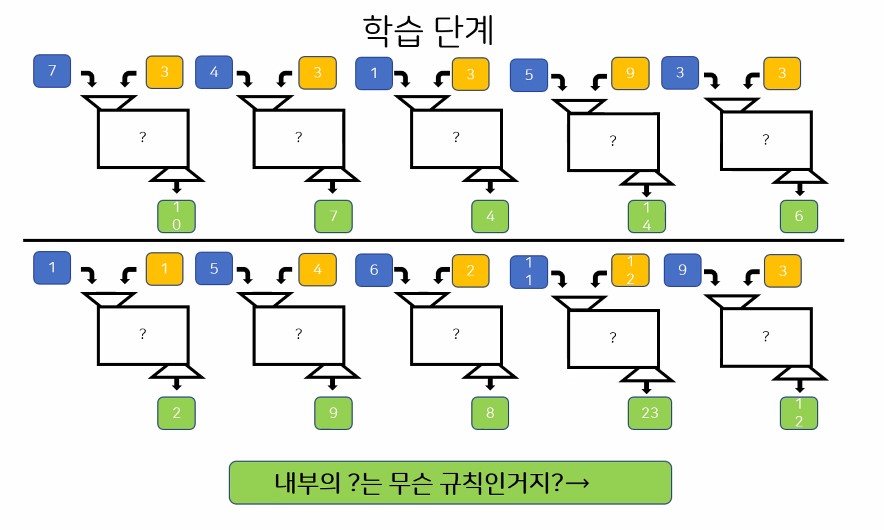
- 반복적인 규칙을 찾아서 학습함
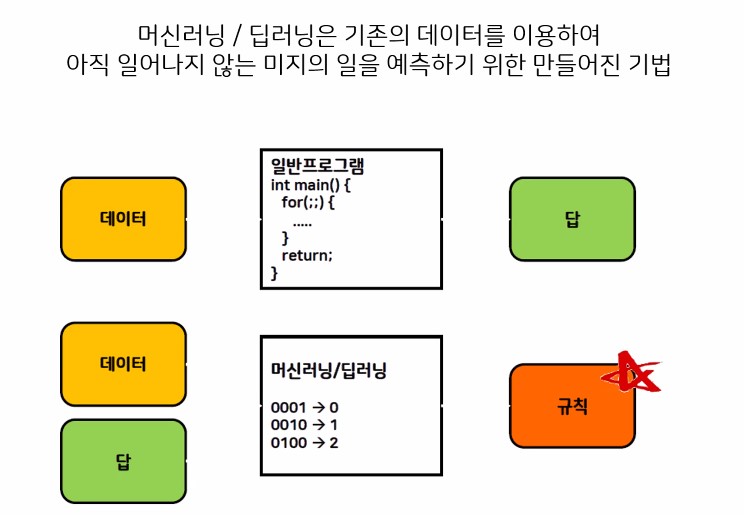
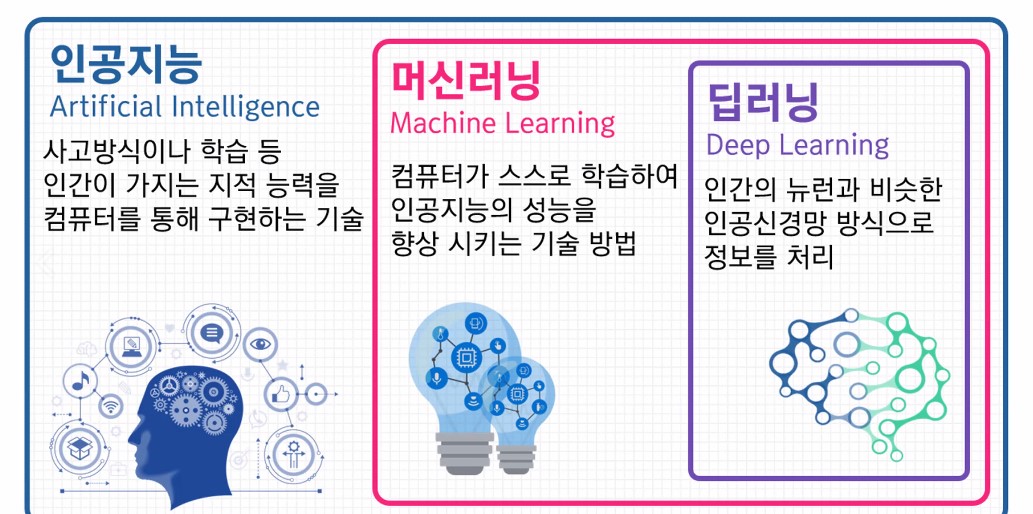
1. 머신 러닝과 딥러닝
- 영상보기
9분만에 이해하는 인공지능 총 정리!
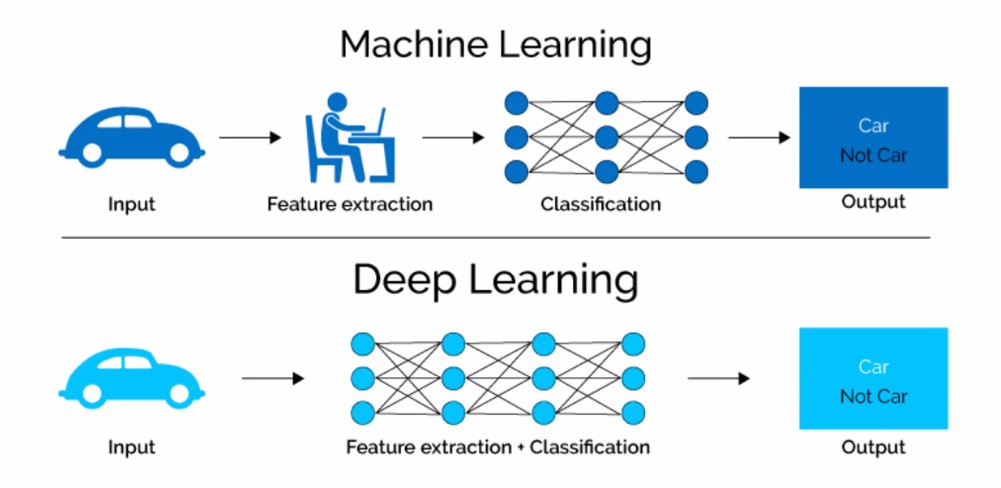
- 머신러닝 :
- 많은 데이터로 규칙을 찾아내 예측 기능
- 컴퓨터가 스스로 학습하여 인공지능의 성능을 향상시키는 기술방법

- 딥러닝 :
- 신경망을 통해서 무수한 계산이 가능
- 인간의 뉴런과 비슷한 인공신경망 방식으로 정보를 처리하는 기술
1.1. 차이점
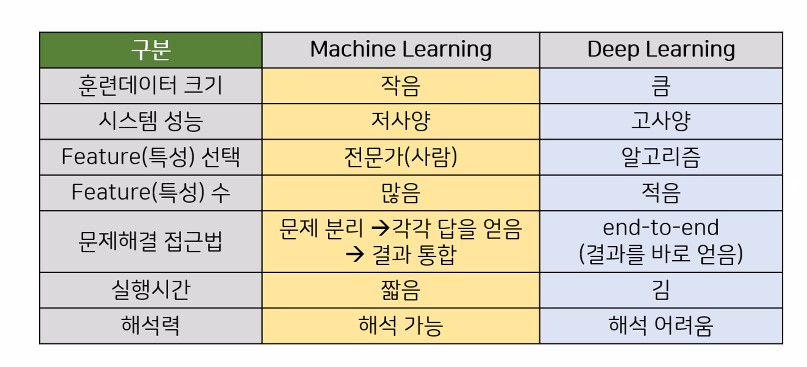
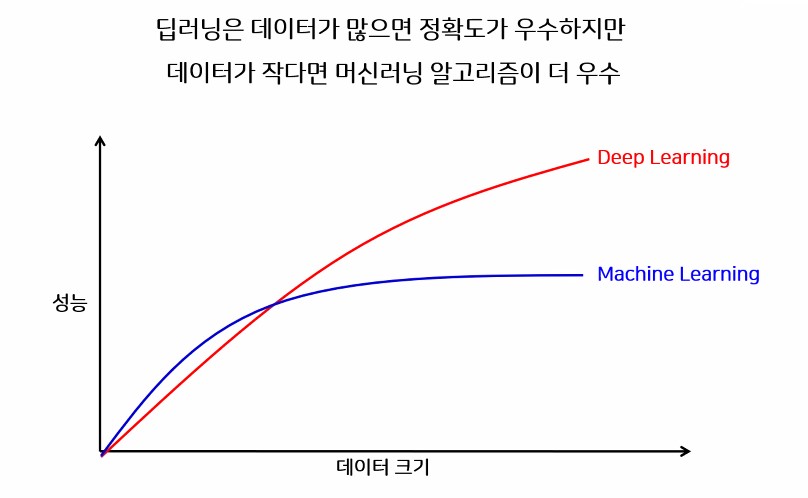
2. 분류모델

2.1. 지도 학습
모델에게 문제 데이터와 정답 데이터를 함께주고 이를 이용해서 새로운 패턴을 학습한 후 정답이 없는 데이터에서 결과 값을 예측하는 학습방법
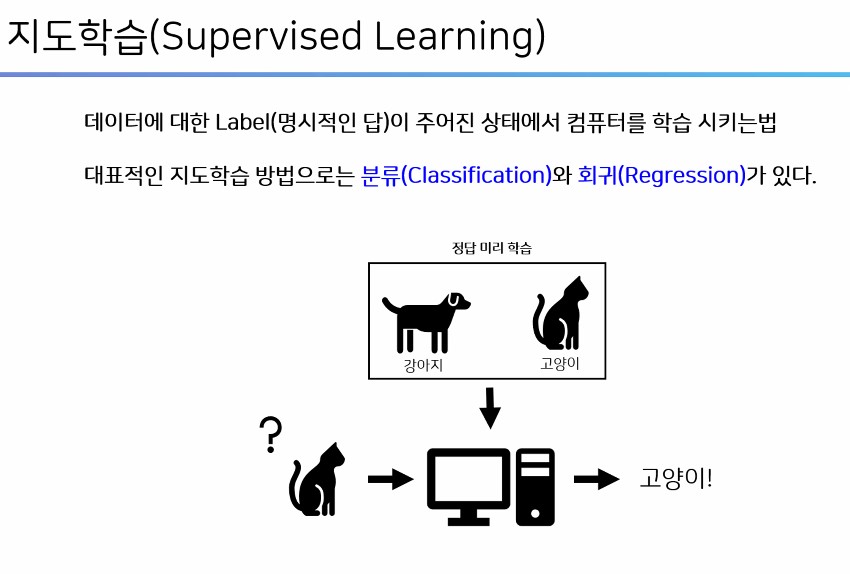
2.1.1. 분류 : 미리 정해진 카테고리 중 하나를 예측하는 것
- 미리정의된 여러 클래스 레이블 중 하나를 예측하는 것
- 속성 값을 입력, 클래스 값을 출력으로 하는 모델
- 붓꽃(iris)의 세 품종 중 하나로 분류, 암 분류 등
- 이진 분류(둘 중 하나로 고르는 것), 다중 분류(여러개(세개이상 중에 하나를 고르는 것) 등이 있다.
2.1.2. 회귀 : 연속된 수치값을 예측하는 방법
(딥러닝에서 깊게 배울 예정)
- 연속적인 숫자를 예측하는 것.
- 속성 값을 입력, 연속 적인 실수 값을 출력으로 하는 모델
- 어떤 사람의 교육수준, 나이, 주거지를 바탕으로 연간 소득 예측 등.
- 예측 값의 미묘한 차이가 크게 중요하지 않음
2.2. 비지도 학습
모델에게 학습 데이터만 제공해서 패턴을 찾고 유사한 데이터를 묶어주거나 새로운 인사이트를 찾는 방법
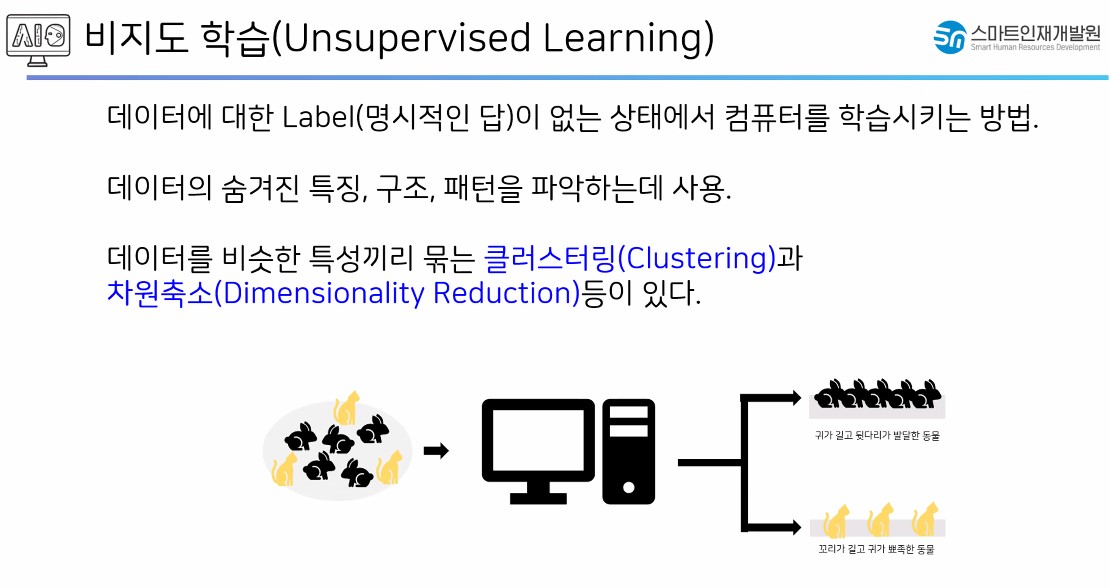
2.2.1. 군집 분석
- 데이터가 가지고 있는 유사성을 판단해서 그룹핑해주는 작업
- 비슷한 것끼리 묶어준다.

2.2.2. 차원 축소 (분석)
- 데이터가 가지고 있는 복잡한 차원을 낮춰주면서 새로운 인사이트를 찾아내는 작업

2.3. 강화 학습
- 주로 보게될 학습 방법
- 인간의 행동 심리학을 본따서 만든 학습 방법
- 보상 대신 로직으로 처리함. (옮고 그름을 판단 > 가산치, 감산치 부여)

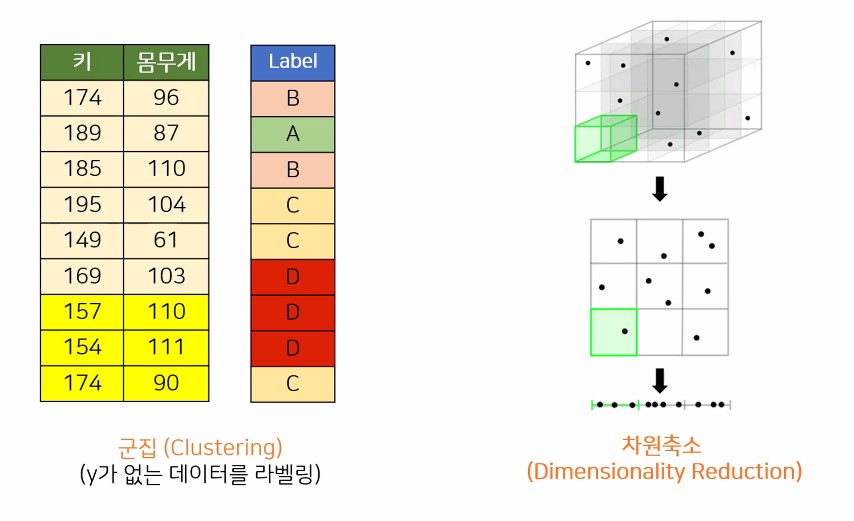
2.4. 비지도 학습의 종류
-
군집 : 키와 몸무게로 등급을 나눠줌
-
차원축소 : 3차원에서 2차원에서 1차원으로 나눠줌
-
비지도 학습으로 처리할 수 있는 일

3. 머신러닝 과정(외우기)
-
머신러닝 7대 과정 (무조건 외우기 시험)

-
- 문제 정의

- 문제 정의
-
- 데이터 수집

- 데이터 수집
-
- 데이터 전처리(80%의 노력이 들어감..)

- 데이터 전처리(80%의 노력이 들어감..)
- 탐색적 데이터 분석

- 탐색적 데이터 분석
-
- 모델 선택, Hyper Parameter 조정

- 모델 선택, Hyper Parameter 조정
-
- 학습
데이터 셋트의 구조
-
모든 데이터가 하나로 합쳐져 있는 경우
(문제/정답/훈련/평가) -> 짬뽕
문제와 정답으로 나눈 후 훈련과 평가셋으로 2차 분할 -
데이터가 문제와 정답으로 나눠져 있는 경우
훈련과 평가셋으로 분할 -
훈련과 평가셋으로 나눠져 있는 경우
문제와 정답으로 분할
- 머신러닝 지도학습에서 데이터를 사용하느 셋트는 4가지로 셋트를 가지고 있음.
- 해당 내용 습득해두기 (주로 사용될 용어)
train - 훈련용 데이터
test - 평가용 데이터
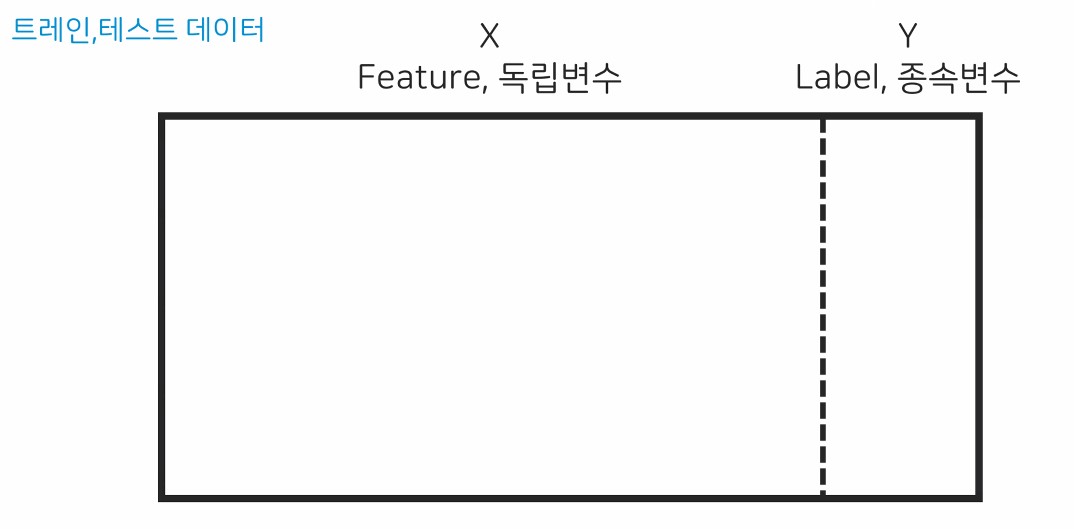
X - 특성변수, 문제 데이터, 독립변수
y - 종족변수, 정답 데이터X_train : 학습용(훈련용) 문제 데이터
X_text : 평가용 문제 데이터
y_train : 학습용(훈련용) 정답 데이터
y_text : 평가용 정답 데이터

- 평가
- 평가

제가 한 번 해보겠습니다.