
이 DB만 알다가..
Data
관찰 결과로 나타난 정량적 혹은 정성적인 실제 값
정보
데이터를 기반으로 의미를 부여한 것

Database
한 조직에 필요한 정보를 여러 응용 시스템에서 공용할 수 있도록
논리적으로 연관된 데이터를 모으고 중복되는 데이터를 최소화하여
구조적으로 통합/저장해놓은 것
- 공용 데이터(Shared Data) : 공동으로 사용되는 데이터
- 통합 데이터(Integrated Data) : 중복 최소화로 중복으로 인한 데이터 불일치 현상 제거
- 저장 데이터(Stored Data) : 컴퓨터 저장장치에 저장된 데이터
- 운영 데이터(Operational Data) : 조직의 목적을 위해 사용되는 데이터
특징
- 실시간 접근성(real time accessibility) : 사용자가 데이터 요청 시 실시간으로 결과 서비스
- 계속적인 변화(continuos change) : 데이터 값은 시간에 따라 항상 바뀜
- 동시 공유(concurrent sharing) : 서로 다른 업무 또는 여러 사용자에게 동시 공유됨
- 내용에 따른 참조(reference by content) : 데이터의 물리적 위치가 아닌 데이터 값에 따라 참조
DBMS
데이터베이스에서 데이터 추출, 조작, 정의, 제어 등을 할 수 있게 해주는 데이터베이스 전용 관리 프로그램

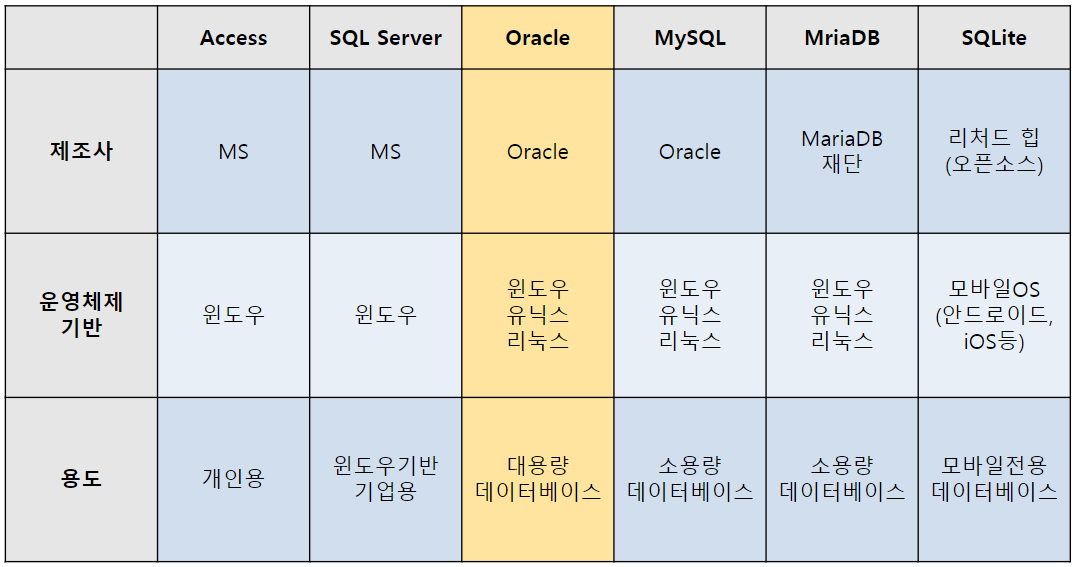
DBMS 종류와 특징
DBMS 사용 이점
-
데이터 독립화
데이터와 응용 프로그램을 분리시킴으로써 상호 영향 정도를 줄일 수 있음 -
데이터 중복 최소화, 데이터 무결성 보장
중복되는 데이터를 최소화 시키면 데이터 무결성이 손상될 가능성이 줄어듦
중복되는 데이터를 최소화 시키면 필요한 저장공간의 낭비를 줄일 수 있음 -
데이터 보안 향상
응용프로그램은 DBMS를 통해 DBMS가 허용하는 데이터에만 접근 가능
권한에 맞게 데이터 접근을 제한하거나 데이터를 암호화시켜 저장 가능 -
관리 편의성 향상
다양한 방법으로 데이터 백업 가능
장애 발생 시 데이터 복구 가능
Database 유형
관계형 데이터베이스
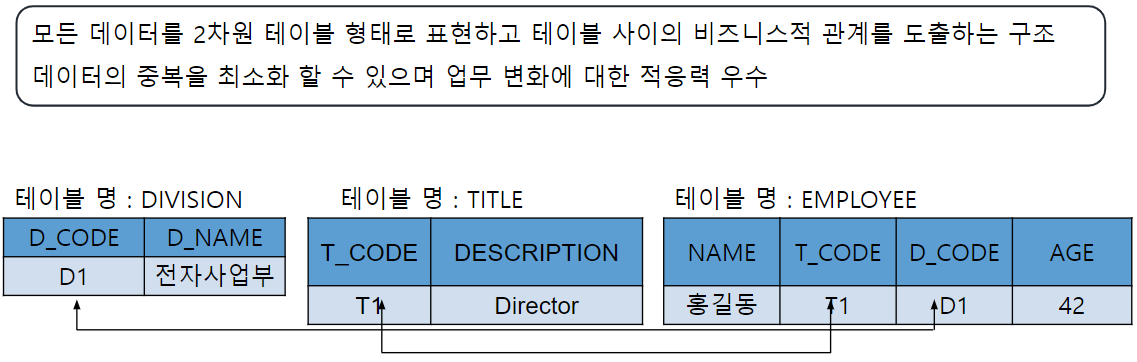
객체-관계형 데이터베이스
-
사용자 정의 타입 지원
사용자가 임의로 정한 데이터 유형으로 기본형을 넘어 다양한 형태의 데이터를 다룰 수 있음 -
참조(reference)타입 지원
객체들로 이루어진 객체 테이블의 경우 하나의 레코드가 다른 레코드를 참조할 수 있는 것 -
중첩 테이블 지원
테이블을 구성하는 로우(row)자체가 또 다른 테이블로 구성되는 테이블을 지원하며
조금 더 복잡하고 복합적인 정보 표현 가능 -
대단위 객체의 저장 및 추출 가능
이미지, 오디오, 비디오 등 저장하기 위한 대단위 객체(LOB) 지원 -
객체간의 상속관계 지원
오라클의 경우 OBJECT타입을 지원함으로써 상속 기능을 구현하고 있음
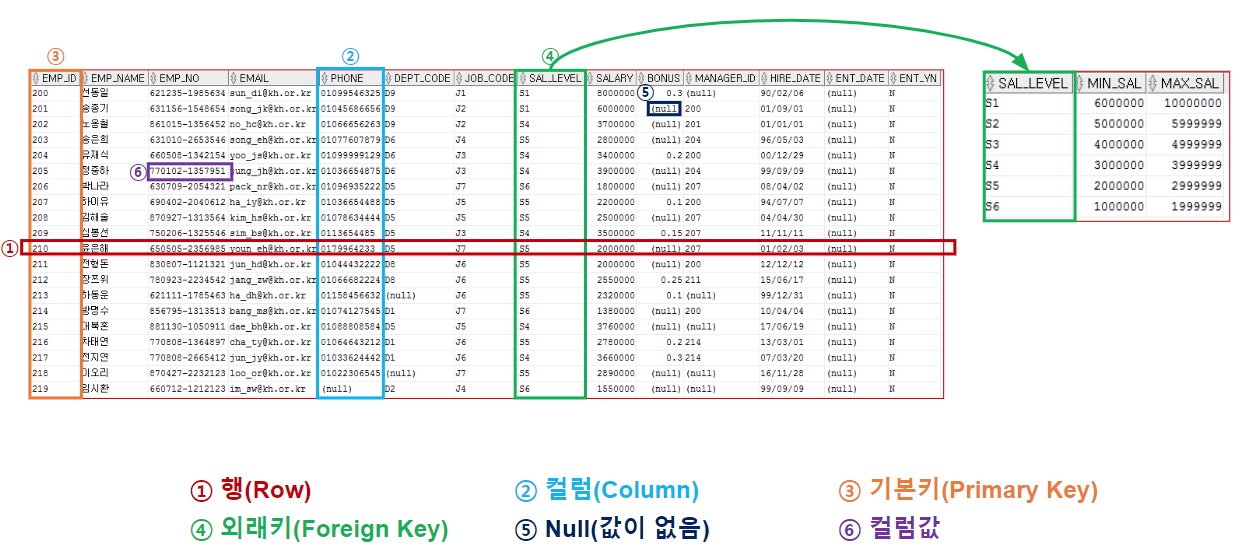
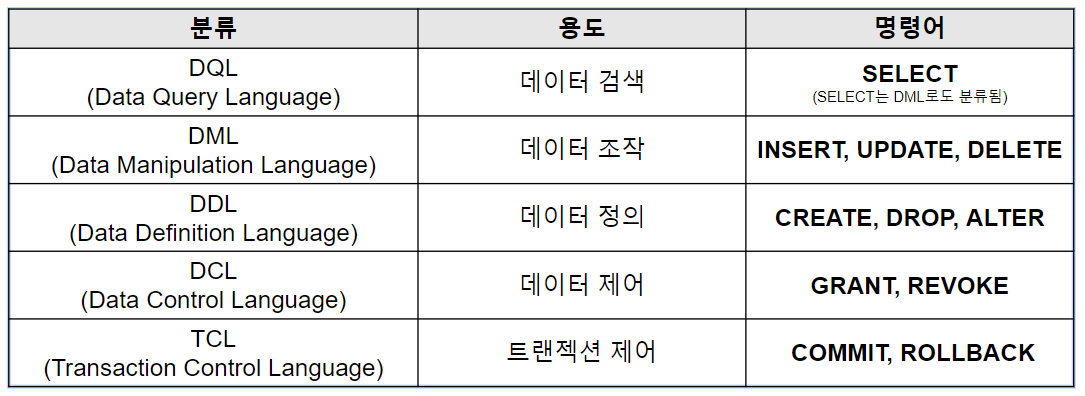
DML(SELECT)
주요 용어
SQL(Structured Query Language)
관계형 데이터베이스에서 데이터를 조회하거나 조작하기 위해 사용하는 표준 검색 언어
원하는 데이터를 찾는 방법이나 절차를 기술하는 것이 아닌 조건을 기술하여 작성
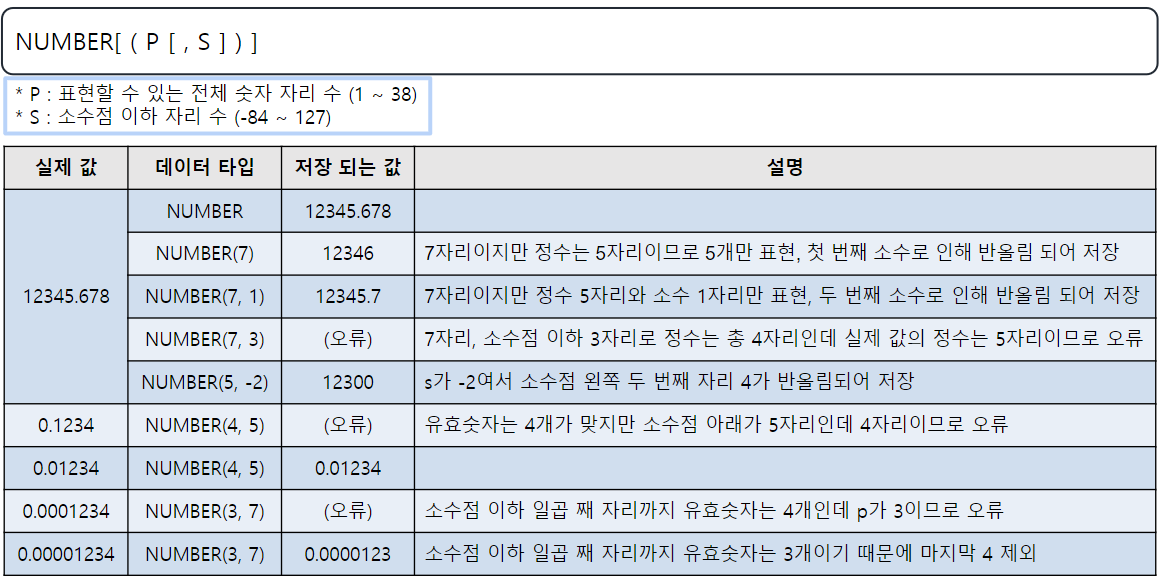
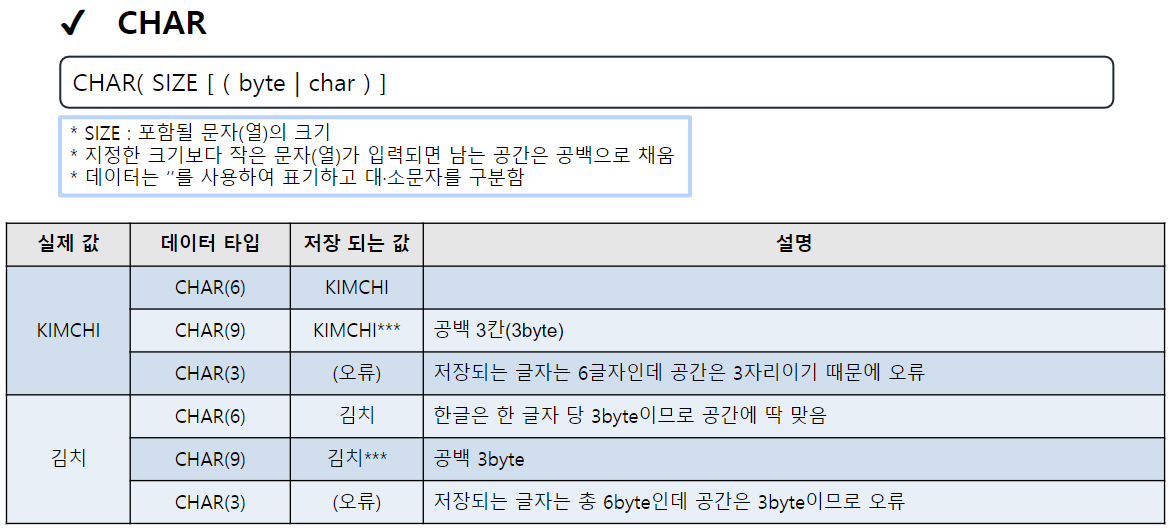
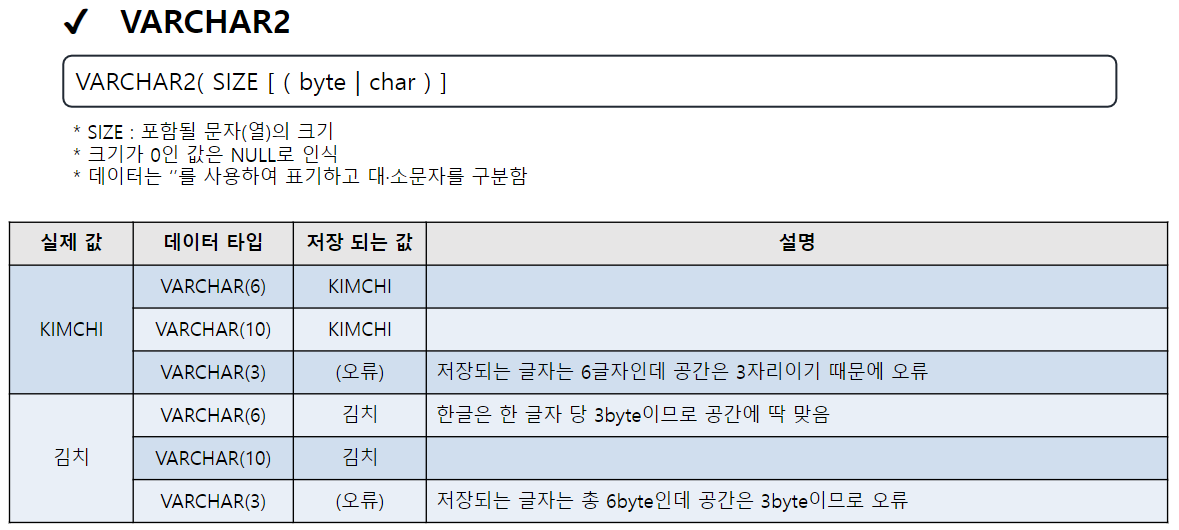
주요 데이터 타입
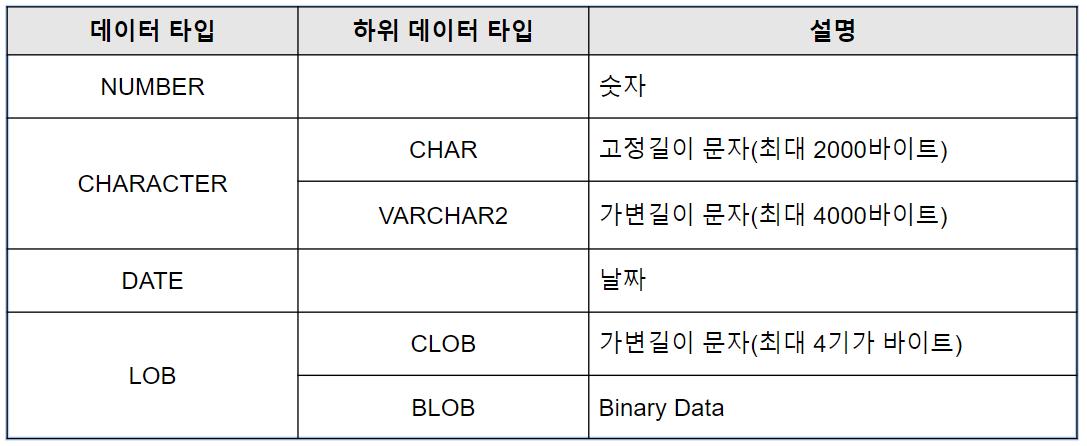
NUMBER
CHARACTER
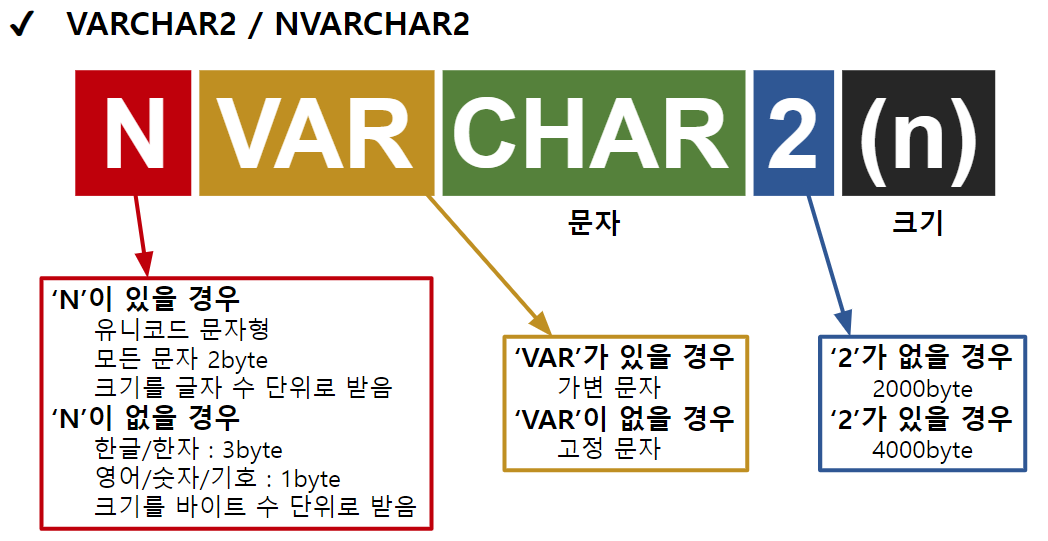
DATE
SELECT
데이터를 조회한 결과를 Result Set이라고 하는데 SELECT구문에 의해 조회된 행들의 집합을 의미.
Result Set은 0개 이상의 행이 포함될 수 있고 Result Set은 특정한 기준에 의해 정렬 가능.
한 테이블의 특정 컬럼, 특정 행, 특정 행/컬럼 또는 여러 테이블의 특정 행/컬럼 조회 가능
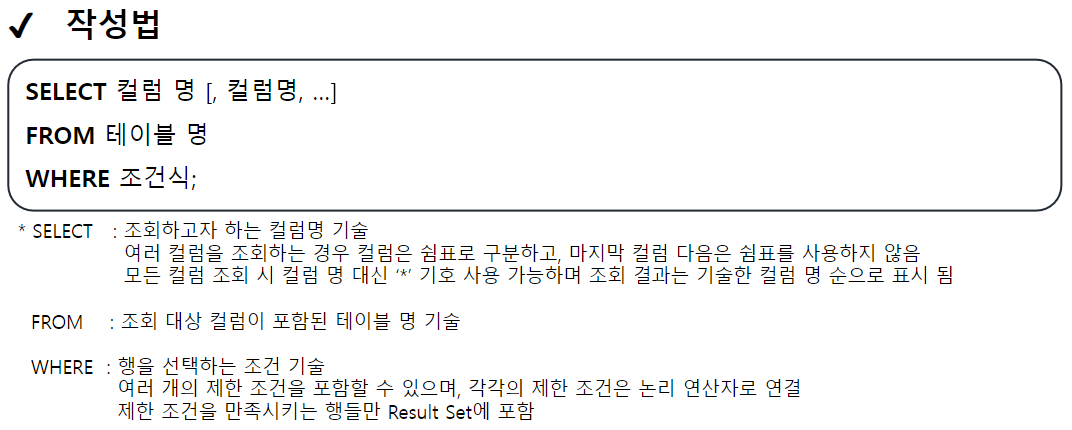


컬럼 값 산술 연산
컬럼 별칭

리터럴

DISTINCT

WHERE절

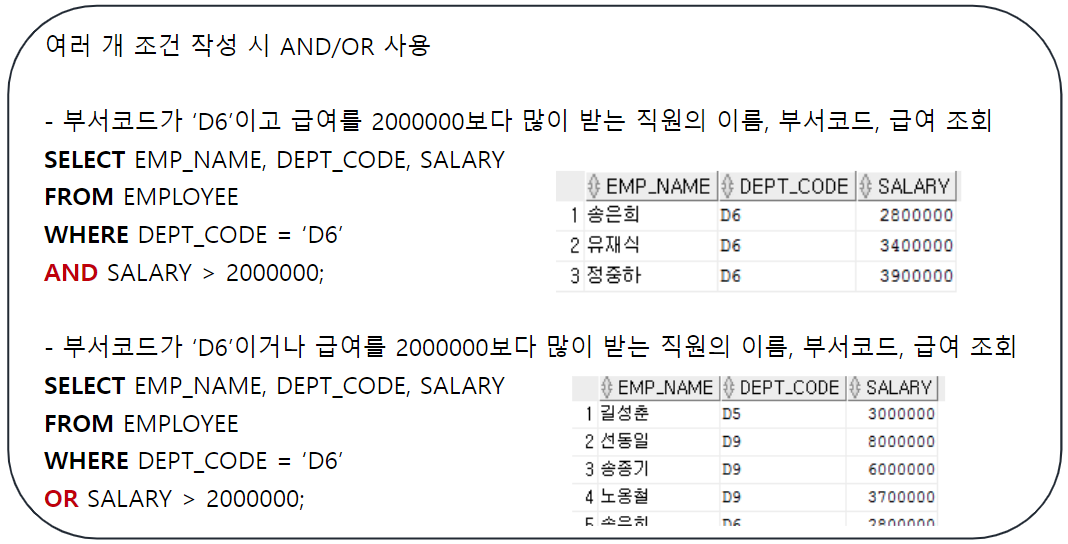
연결 연산자
‘||’를 사용하여 여러 컬럼을 하나의 컬럼인 것처럼 연결하거나 컬럼과 리터럴을 연결함

논리 연산자
여러 개의 제한 조건 결과를 하나의 논리 결과로 만들어줌
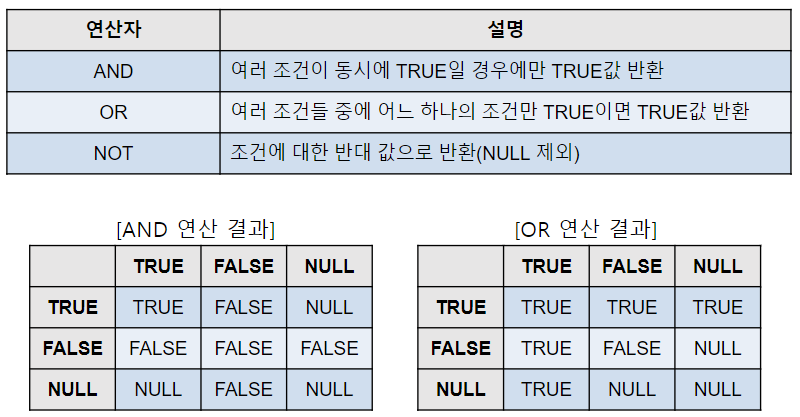
비교 연산자
표현식 사이의 관계를 비교하기 위해 사용하고 비교 결과는 논리 결과(TRUE/FALSE/NULL) 중 하나가 됨
단 비교하는 두 컬럼 값/표현식은 서로 동일한 데이터 타입이어야 함
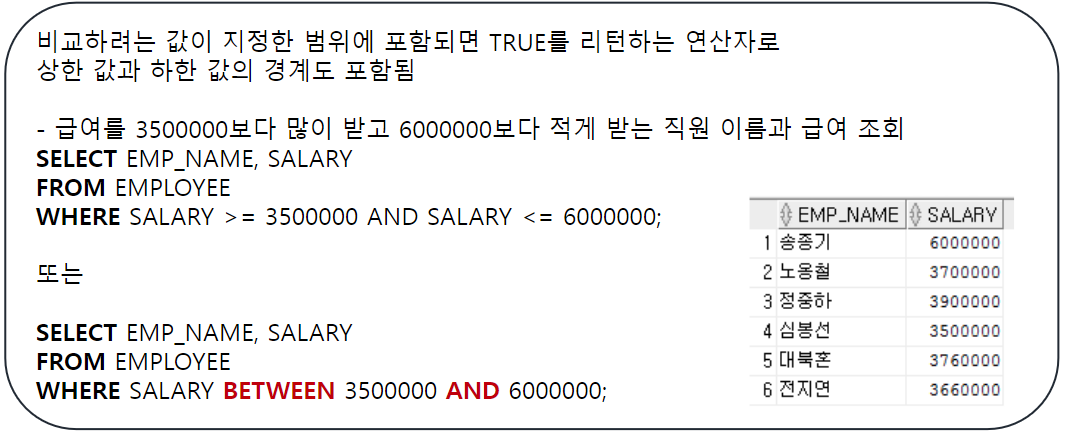
BETWEEN AND
LIKE
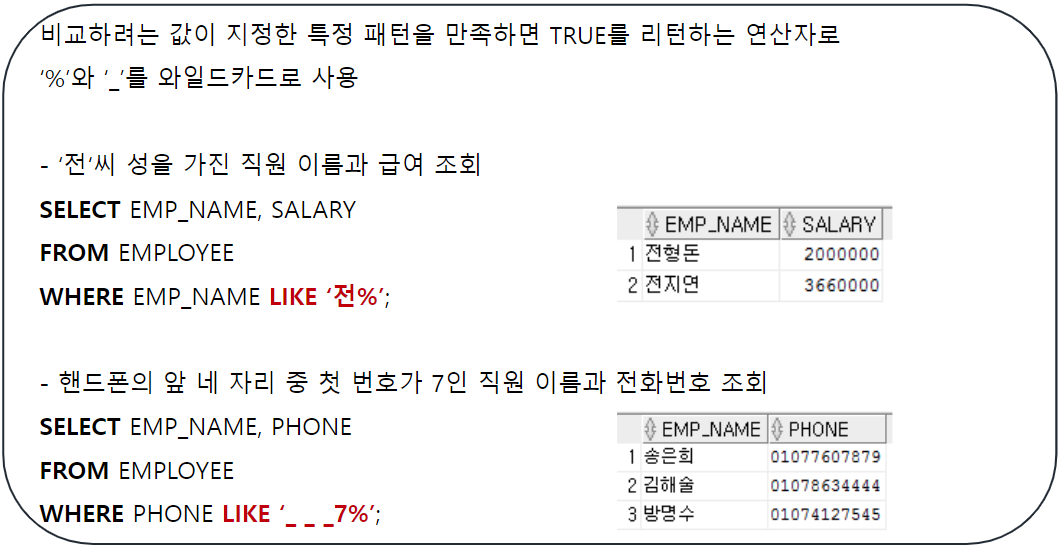

NOT LIKE

IS NULL과 IS NOT NULL

IN

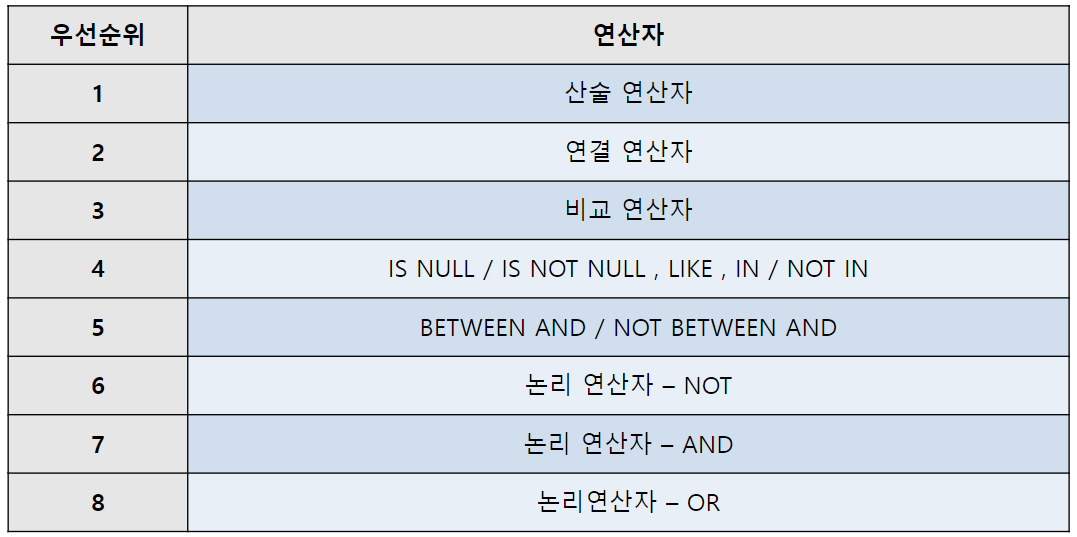
연산자 우선순위
계정 생성
-- 새로운 사용자 계정 생성 (sys 계정으로 진행)
ALTER SESSION SET "_ORACLE_SCRIPT" = TRUE;
CREATE USER workbook IDENTIFIED BY workbook;
--사용자 계정 권한 부여 설정
GRANT RESOURCE, CONNECT TO workbook;
--객체가 생성될 수 있는 공간 할당량 지정
ALTER USER workbook DEFAULT TABLESPACE SYSTEM QUOTA UNLIMITED ON SYSTEM;SELECT
/* SELECT (DML 또는 DQL) : 조회
*
* - 데이터를 조회(SELECT)하면 조건에 맞는 행들이 조회됨.
* 이 때, 조회된 행들의 집합을 "RESULT SET" (조회 결과의 집합) 이라고 한다.
*
* - RESULT SET은 0개 이상의 행을 포함할 수 있다.
* 왜 0개? 조건에 맞는 행이 없을 수도 있어서.
*
*/
-- [작성법]
-- SELECT 컬럼명 FROM 테이블명;
--> 어떤 테이블의 특정 컬럼을 조회하겠다.
SELECT * FROM EMPLOYEE;
-- '*' : all, 모든, 전부
--> EMPLOYEE테이블의 모든 컬럼을 조회하겠다.
-- 사번, 직원이름, 휴대전화번호 조회
SELECT EMP_ID, EMP_NAME, PHONE FROM EMPLOYEE;
--------------------------------------------------------------------------
-- <컬럼 값 산술 연산>
-- 컬럼 값 : 테이블 내 한 칸 ( == 한 셀) 에 작성된 값 (DATA)
-- EMPLOYEE 테이블에서 모든 사원의 사번, 이름, 급여, 연봉 조회
SELECT EMP_ID, EMP_NAME, SALARY, SALARY * 12 FROM EMPLOYEE;
SELECT EMP_NAME + 10 FROM EMPLOYEE;
-- ORA-01722 : 수치가 부적합합니다.
-- 산술연산은 숫자(NEMBER 타입)만 가능하다!
SELECT EMP_ID + 10 FROM EMPLOYEE;
-- 숫자형은 산술연산이 되기도 한다.
SELECT '같음'
FROM DUAL
WHERE 1 = '1';
--------------------------------------------------------------------------
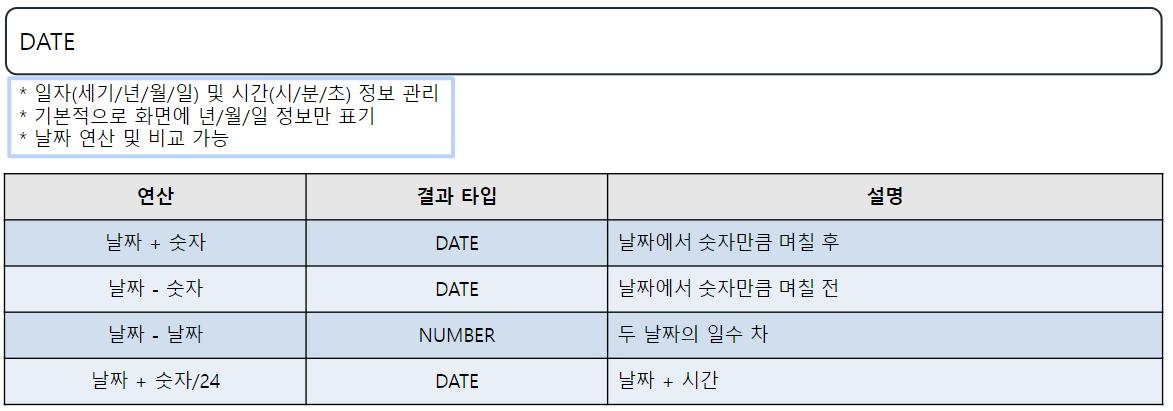
-- 날짜(DATE) 타입 조회
-- EMPLOYEE 테이블에서 이름, 입사일, 오늘 날짜 조회
SELECT EMP_NAME, HIRE_DATE, SYSDATE FROM EMPLOYEE;
-- 2023-08-03 12:05:31.000
-- SYSDATE : 시스템상의 현재 시간(날짜) 를 나타내는 상수
SELECT SYSDATE FROM DUAL;
-- DUAL(DUmy tAbLe) 테이블 : 가짜 테이블(임시 조회용 테이블)
-- 날짜 + 산술연산 ( + , - )
SELECT SYSDATE - 1, SYSDATE, SYSDATE +1
FROM DUAL;
-- 날짜에 +/- 연산 시 일 단위로 계산이 진행됨
--------------------------------------------------------------------------
-- <컬럼 별칭 지정>
/* 컬럼명 AS 별칭 : 별칭 띄어쓰기 x, 특수문자 x, 문자만 o
*
* 컬럼명 AS "별칭" : 별칭 띄어쓰기 o, 특수문자 o, 문자 o
*
* AS 생략 가능
*
*/
SELECT SYSDATE - 1 "하루 전", SYSDATE AS 현재시간, SYSDATE +1 내일
FROM DUAL;
--------------------------------------------------------------------------
-- JAVA 리터럴 : 값 자체를 의미
-- DB 리터럴 : 임의로 지정한 값을 기존 테이블에 존재하는 값처럼 사용하는 것
--> (필수) DB의 리터럴 표기법은 '' 홑따옴표
SELECT EMP_NAME, SALARY, '원 입니다' FROM EMPLOYEE
--------------------------------------------------------------------------
-- DISTINCT : 조회 시 컬럼에 포함된 중복 값을 한 번만 표기
-- (주의사항)
-- 1) DISTINCT는 SELECT문에 딱 한 번만 작성 가능
-- 2) DISTINCT는 SELECT문 가장 앞에 작성되어야 함
SELECT DISTINCT DEPT_CODE, JOB_CODE FROM EMPLOYEE;
--------------------------------------------------------------------------
-- 3. SELECT 절 : SELECT 컬럼명
-- 1. FROM 절 : FROM 테이블명
-- 2. WHERE 절 : WHERE 컬럼명 연산자 값;
-- 4. ORDER BY 컬럼명 | 별칭 | 컬럼 순서 [ASC | DESC] [NULLS FIRST | LAST]
-- EMPLOYEE 테이블에서 급여가 3백만원 초과인 사원의
-- 사번, 이름, 급여, 부서코드를 조회
SELECT EMP_ID, EMP_NAME, SALARY, DEPT_CODE
FROM EMPLOYEE
WHERE SALARY > 3000000;
-- 비교 연산자 : >, <, >=, <=, = (같다), !=, <> (같지 않다)
-- 대입 연산자 : :=
-- EMPLOYEE 테이블에서 부서코드가 'D9'인 사원의
-- 사번, 이름, 부서코드, 직급코드를 조회
SELECT EMP_ID, EMP_NAME, DEPT_CODE, JOB_CODE
FROM EMPLOYEE
WHERE DEPT_CODE = 'D9';
--------------------------------------------------------------------------
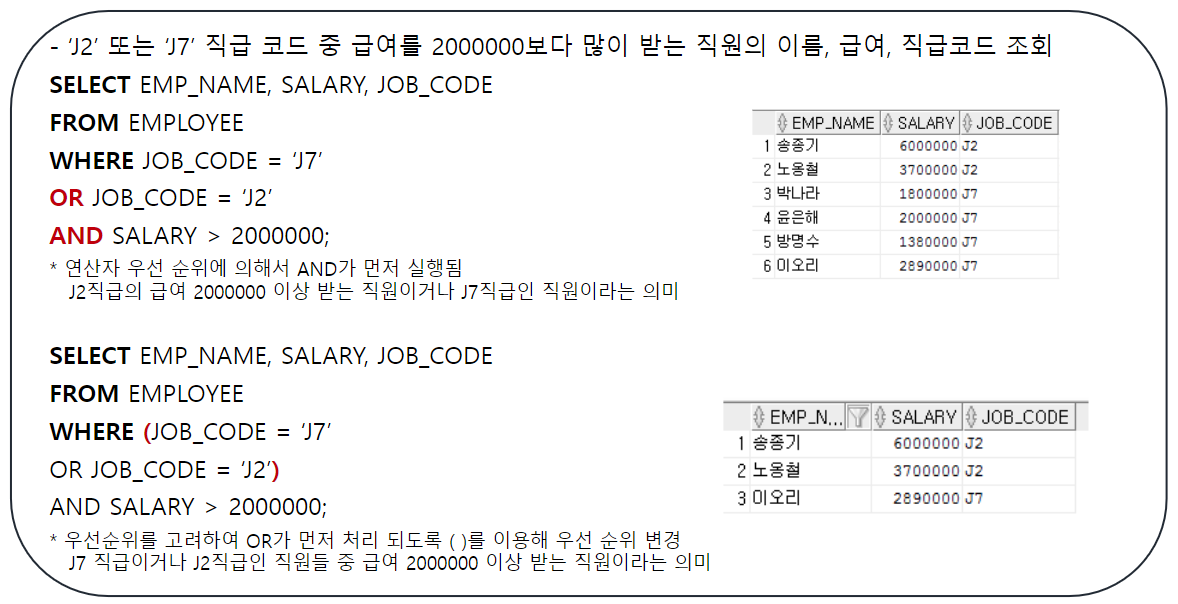
-- 논리 연산자 (AND, OR)
-- EMPLOYEE 테이블에서 급여가 300만 미만 또는 500만 이상인 사원의
-- 사번, 이름, 급여, 전화번호 조회
SELECT EMP_ID, EMP_NAME, SALARY, PHONE
FROM EMPLOYEE
WHERE SALARY < 3000000 OR SALARY >= 5000000;
-- EMPLOYEE 테이블에서 급여가 300만 이상, 500만 미만인 사원의
-- 사번, 이름, 급여, 전화번호 조회
SELECT EMP_ID, EMP_NAME, SALARY, PHONE
FROM EMPLOYEE
WHERE SALARY >= 3000000 AND SALARY < 5000000;
-- BETWEEN A AND B : A 이상 B 이하
-- 300만 이상, 600만 이하
SELECT EMP_ID, EMP_NAME, SALARY, PHONE
FROM EMPLOYEE
WHERE SALARY BETWEEN 3000000 AND 6000000;
-- NOT 연산자 사용 가능!
SELECT EMP_ID, EMP_NAME, SALARY, PHONE
FROM EMPLOYEE
WHERE SALARY NOT BETWEEN 3000000 AND 6000000;
-- 날짜 (DATE) 에 BETWEEN 이용하기
-- EMPLOYEE 테이블에서 입사일이 1990-0101~1999-12-31 사이인 직원의
-- 이름, 입사일 조회
SELECT EMP_NAME, HIRE_DATE
FROM EMPLOYEE
WHERE HIRE_DATE BETWEEN '1990-0101' AND '1999-12-31';
--------------------------------------------------------------------------
-- LIKE : ~처럼, ~같이
-- 비교하려는 값이 특정한 패턴을 만족 시키면 조회하는 연산자
-- [작성법]
-- WHERE 컬럼명 LIKE '패턴이 적용된 값'
-- LIKE의 패턴을 마타내는 문자(와일드 카드)
--> '%' : 포함
--> '_' : 글자수
-- '%' 예시
-- 'A%' : A로 시작하는 문자열
-- '%A' : A로 끝나는 문자열
-- '%A%' : A를 포함하는 문자열
-- '_' 예시
-- 'A_' : A로 시작하는 두 글자 문자열
-- '____A' : A로 끝나는 다섯 글자 문자열
-- '__A__' : 세 번째 문자가 A인 다섯 글자 문자열
-- '_____' : 다섯 글자 문자열
-- EMPLOYEE 테이블에서 성이 '전'씨인 사원의 사번, 이름 조회
SELECT EMP_ID, EMP_NAME
FROM EMPLOYEE
WHERE EMP_NAME LIKE '전%';
-- EMPLOYEE 테이블에서 전화번호가 010으로 시작하지 않는 사원
-- 사번, 이름, 전화번호 조회
SELECT EMP_ID, EMP_NAME, PHONE
FROM EMPLOYEE
WHERE PHONE NOT LIKE '010%';
-- EMPLOYEE 테이블에서 EMAIL의 _앞에 글자가 세 글자인 사원만 조회
-- 이름, EMAIL 조회
SELECT EMP_NAME, EMAIL
FROM EMPLOYEE
WHERE EMAIL LIKE '____%';
-- ESCAPE
-- ESCAPE 문자 뒤에 작성된 _ 는 일반 문자로 탈출한다는 뜻
-- #, ^
SELECT EMP_NAME, EMAIL
FROM EMPLOYEE
WHERE EMAIL LIKE '___#_%' ESCAPE '#';
--------------------------------------------------------------------------
-- 연습문제 !!!
-- EMPLOYEE 테이블에서
-- 이메일 '_'앞이 4글자 이면서
-- 부서코드가 'D9' 또는 'D6' 이고 -> AND가 OR 보다 우선순위가 높다, () 사용 가능
-- 입사일이 1990-0101 ~ 2000-12-31 이고
-- 급여가 270만원 이상인 사원의
-- 사번, 이름, 이메일, 부서코드, 입사일, 급여 조회
SELECT EMP_ID, EMP_NAME, EMAIL, DEPT_CODE, HIRE_DATE, SALARY
FROM EMPLOYEE
WHERE HIRE_DATE BETWEEN '1990-01-01' AND '2000-12-31'
AND SALARY >= 2700000
AND EMAIL LIKE '____#_%' ESCAPE '#'
AND (DEPT_CODE = 'D9' OR DEPT_CODE = 'D6');
-- 연산자 우선순위
/*
* 1. 산술 연산자 (+ - * /)
* 2. 연결 연산자 ( || )
* 3. 비교 연산자 ( > < <= >= = != <> )
* 4. IS NULL / IS NOT NULL, LIKE, IN / NOT IN
* 5. BETWEEN AND / NOT BETWEEN AND
* 6. NOT (논리 연산자)
* 7. AND
* 8. OR
*
*/
--------------------------------------------------------------------------
/* IN 연산자
*
* 비교하려는 값과 목록에 작성된 값 중
* 일치하는 것이 있으면 조회하는 연산자
*
* [작성법]
* WHERE 컬럼명 IN(값1, 값2, 값3....)
*
* WHERE 컬럼명 = '값1'
* OR 컬럼명 = '값2'
* OR 컬럼명 = '값3';
*
*/
-- EMPLOYEE 테이블에서
-- 부서코드가 D1, D6, D9 인 사원의
-- 사번, 이름, 부서코드 조회
SELECT EMP_ID, EMP_NAME, DEPT_CODE
FROM EMPLOYEE
WHERE DEPT_CODE IN('D1', 'D6', 'D9');
-- NOT IN
SELECT EMP_ID, EMP_NAME, DEPT_CODE
FROM EMPLOYEE
WHERE DEPT_CODE NOT IN('D1', 'D6', 'D9') -- 12명
OR DEPT_CODE IS NULL; -- 부서코드 없는 사람 포함 14명
-- IS NULL
-- IS NOT NULL
--------------------------------------------------------------------------
/* NULL 처리 연산자
*
* JAVA 에서 NULL : 참조하는 객체가 없음을 의미하는 값
* DB 에서 NULL : 컬럼에 값이 없음을 의미하는 값
*
* 1) IS NULL : NULL인 경우 조회
* 2) IS NOT NULL : NULL이 아닌 경우 조회
*
*/
-- EMPLOYEE 테이블에서 보너스가 있는 사원의 이름, 보너스 조회
SELECT EMP_NAME, BONUS
FROM EMPLOYEE
WHERE BONUS IS NOT NULL; -- 9행
-- EMPLOYEE 테이블에서 보너스가 없는 사원의 이름, 보너스 조회
SELECT EMP_NAME, BONUS
FROM EMPLOYEE
WHERE BONUS IS NULL; -- 14행
--------------------------------------------------------------------------
/* ORDER BY 절
*
* - SELECT문의 조회 결과(RESULT SET)를 정렬할 때 사용하는 구문
*
* ** SELECT문 해석 시 가장 마지막에 해석된다!!!
*
* 3. SELECT 절
* 1. FROM 절
* 2. WHERE 절
* 4. ORDER BY 컬럼명 | 별칭 | 컬럼순서
*
*/
-- EMPLOYEE 테이블 급여 오름 차순으로
-- 사번, 이름, 급여 조회
SELECT EMP_ID, EMP_NAME, SALARY
FROM EMPLOYEE
ORDER BY SALARY; -- ASC가 기본값 [ASC(오름차순) | DESC(내림차순)]
-- 급여 200만 이상인 사원의
-- 사번, 이름, 급여 조회
-- 단, 급여는 내림 차순으로 조회
SELECT EMP_ID, EMP_NAME, SALARY
FROM EMPLOYEE
WHERE SALARY >= 2000000
ORDER BY 3 DESC; -- 3은 3번째 칼럼(SALARY)
-- 입사일 순서대로 이름, 입사일 조회 (별칭 사용)
SELECT EMP_NAME 이름, HIRE_DATE 입사일
FROM EMPLOYEE
ORDER BY 입사일;
/* 정렬 중첩 : 대분류 정렬 후 소분류 정렬 */
-- 부서코드 오름차순 정렬 후 급여 내림차순 정렬
SELECT EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
ORDER BY DEPT_CODE, SALARY DESC;
