함수(Function)
하나의 큰 프로그램에서 반복적으로 사용되는 부분들을 분리하여 작성해 놓은 작은 서브 프로그램
호출하며 값을 전달하면 결과를 리턴하는 방식으로 사용
문자 처리 함수
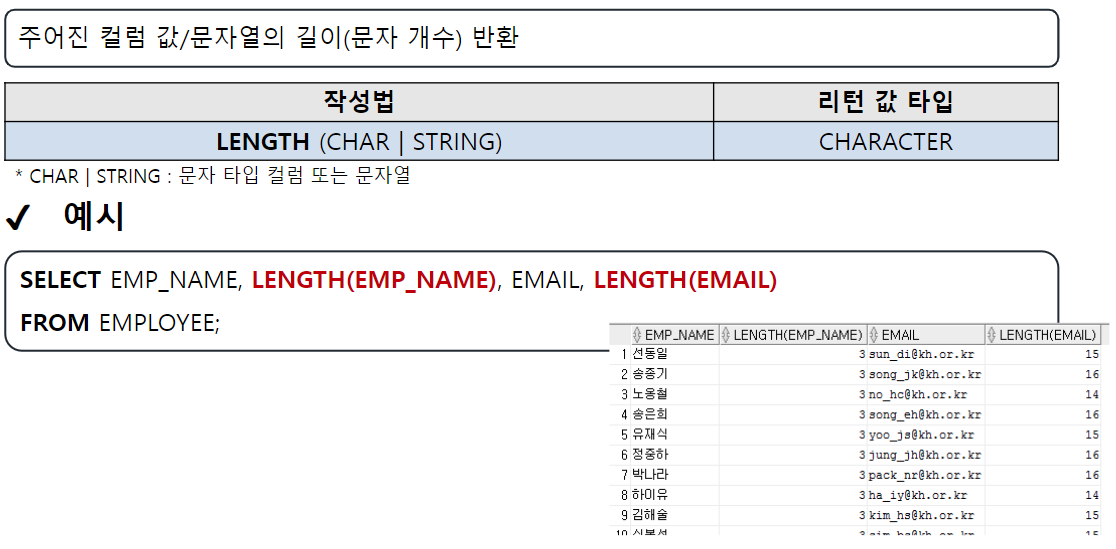
LENGTH
INSTR

LTRIM/RTRIM

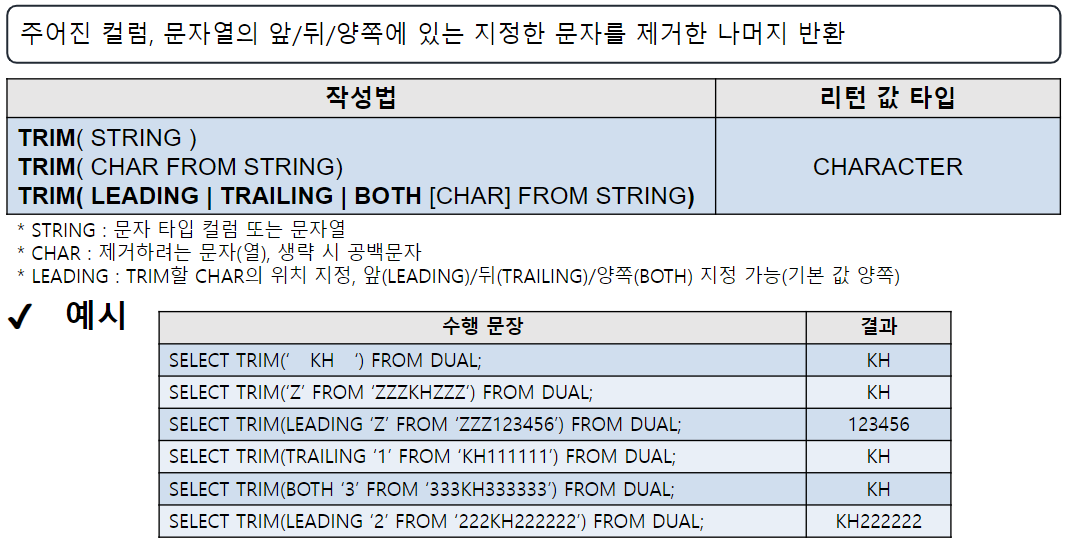
TRIM
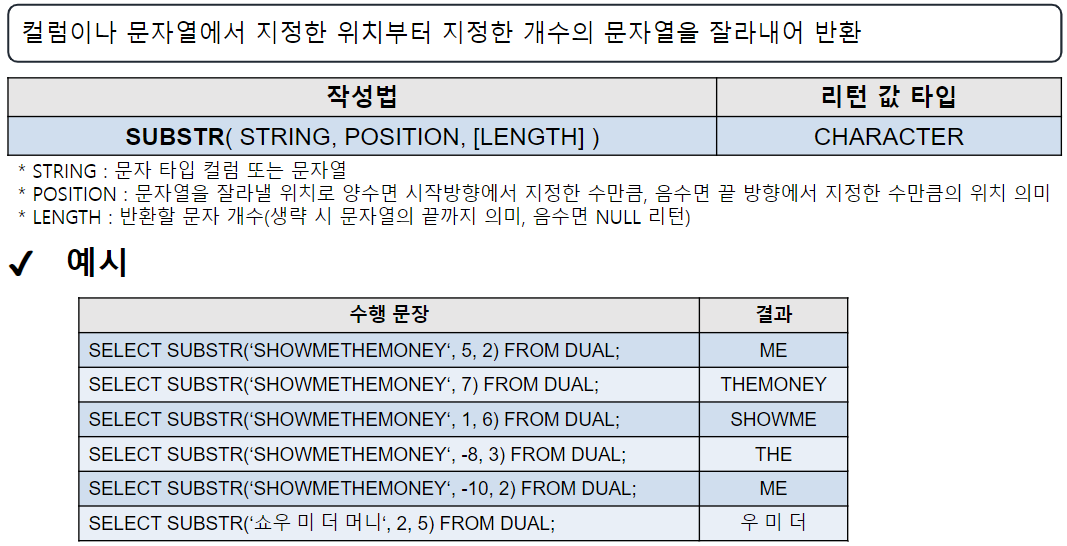
SUBSTR
숫자 처리 함수
ABS
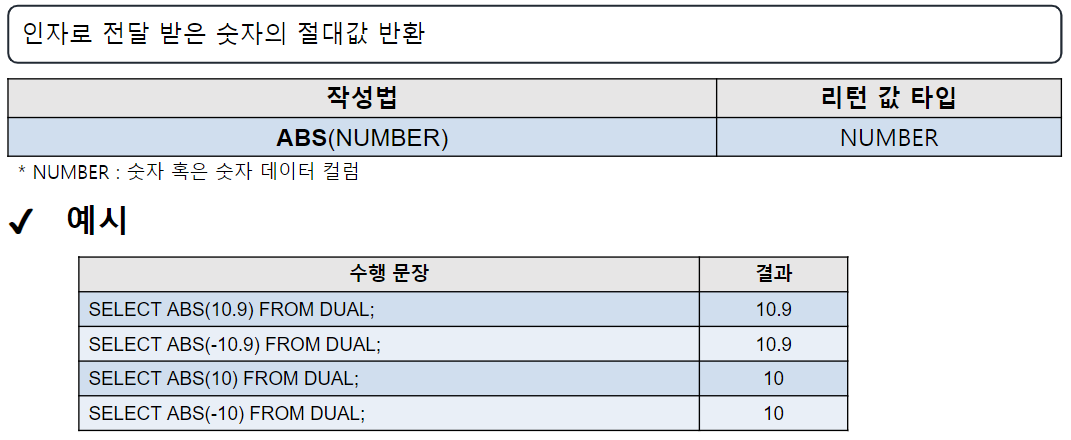
ROUND
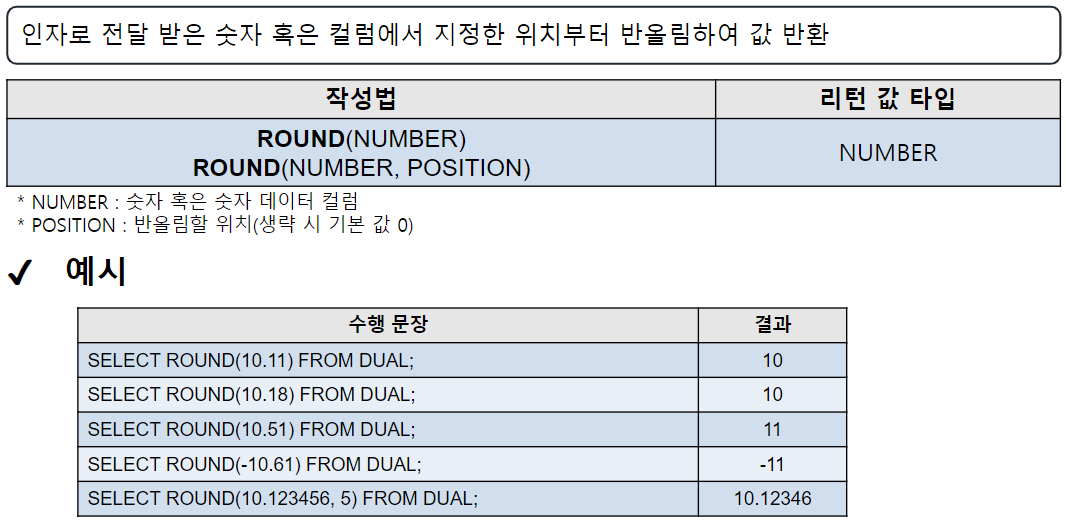
TRUNC
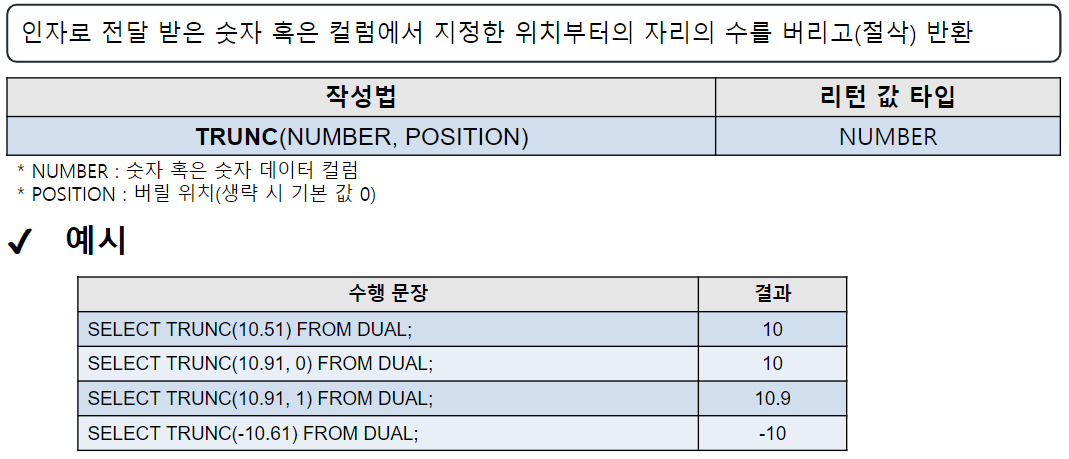
CEIL
날짜 처리 함수
SYSDATE

MONTHS_BETWEEN
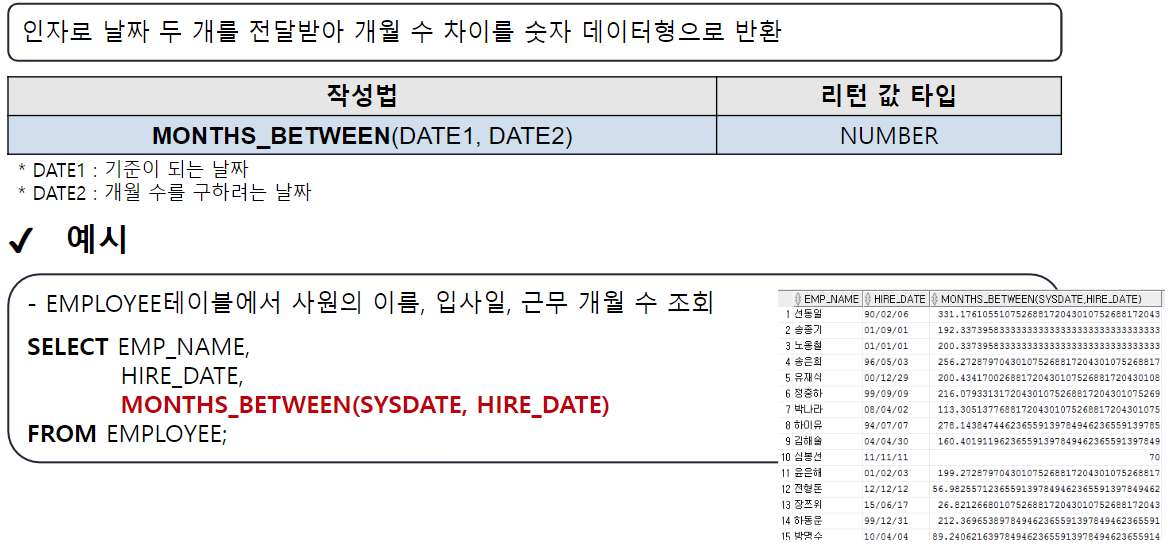
ADD_MONTHS
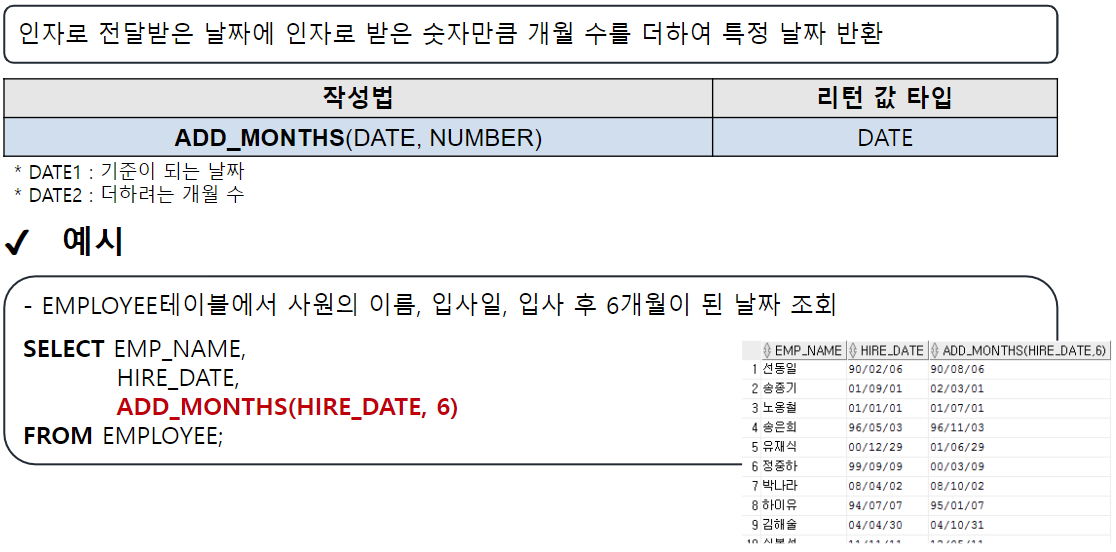
EXTRACT
형 변환 함수
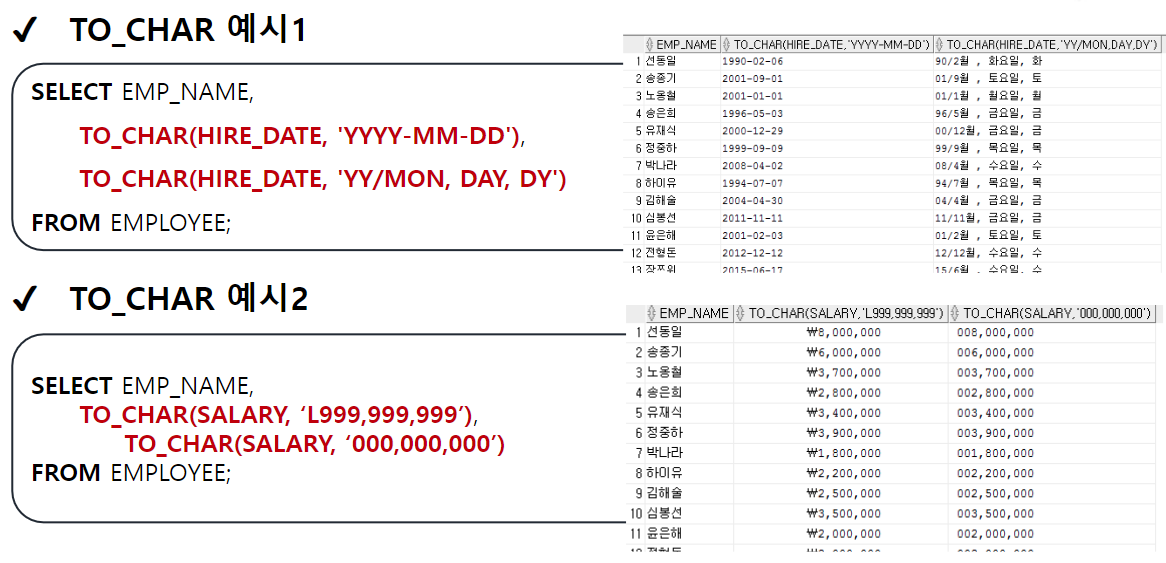
TO_CHAR
날짜 혹은 숫자형 데이터를 문자형 데이터로 변환하여 반환
TO_DATE
숫자 혹은 문자형 데이터를 날짜형 데이터로 변환하여 반환

TO_NUMBER
날짜 혹은 문자형 데이터를 숫자형 데이터로 변환하여 반환

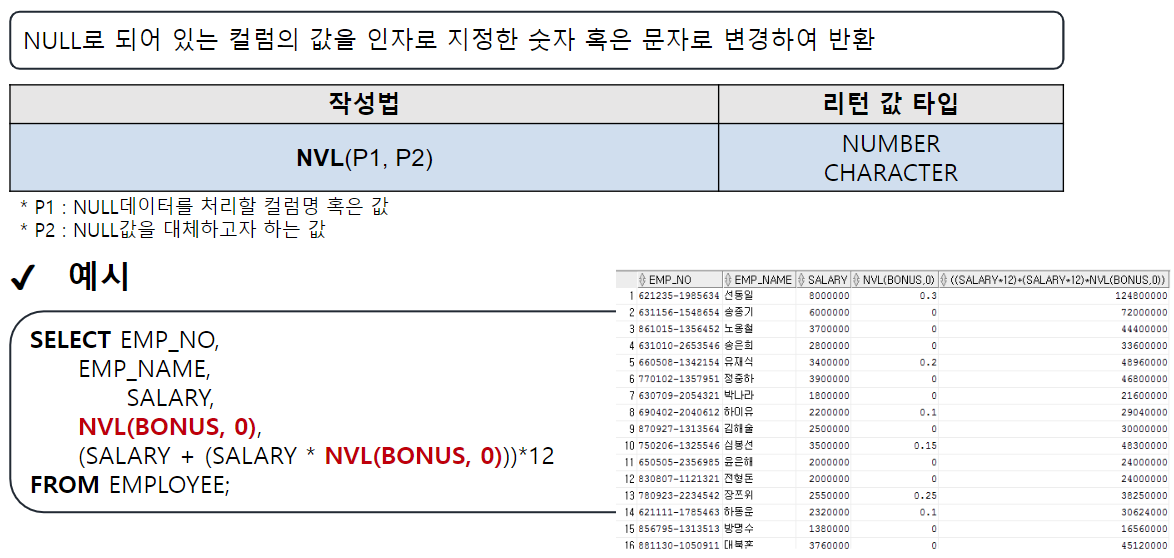
NULL 처리 함수
NVL
선택 함수
DECODE
CASE
그룹 함수
SUM
해당 컬럼 값들의 총합 반환

AVG
해당 컬럼 값들의 평균 반환

MAX/MIN
그룹의 최대값과 최소값 반환

COUNT
테이블 조건을 만족하는 행의 개수 반환

FUNCTION
-- 함수 : 컬럼의 값을 읽어서 연산한 결과를 반환
-- 단일 행 함수 : N개의 값을 읽어서 N개의 결과를 반환
-- 그룹 함수 : N개의 값을 읽어서 1개의 결과를 반환(합계, 평균, 최대, 최소)
-- 함수는 SELECT문의
-- SELECT절, WHERE절, ORDER BY절, GROUP BY절, HAVING 절 사용 가능
---------------------------- 단일 행 함수 -----------------------------
-- LENGTH(컬럼명 | 문자열) : 길이 반환
SELECT EMAIL, LENGTH(EMAIL)
FROM EMPLOYEE;
------------------------------------
-- INSTR(컬럼명 | 문자열, '찾을 문자열' [, 찾기 시작할 위치 [, 순번] ] )
-- 지정한 위치부터 지정한 순번째로 검색되는 문자의 위치를 반환
-- 문자열을 앞에서부터 검색하여 첫번째 B위치 조회
-- AABAACAABBAA
SELECT INSTR('AABAACAABBAA', 'B') FROM DUAL; -- 3
-- 문자열을 5번째 문자 부터 검색하여 첫번째 B위치 조회
SELECT INSTR('AABAACAABBAA', 'B', 5) FROM DUAL; -- 9
-- 문자열을 5번째 문자 부터 검색하여 두번째 B위치 조회
SELECT INSTR('AABAACAABBAA', 'B', 5, 2) FROM DUAL; -- 10
-- EMPLOYEE 테이블에서 사원명, 이메일, 이메일 중 '@' 위치 조회
SELECT EMP_NAME, EMAIL, INSTR(EMAIL, '@')
FROM EMPLOYEE;
---------------------------------------------------------------------
-- SUBSTR('문자열' | 컬럼명, 잘라내기 시작할 위치 [, 잘라낼 길이])
-- 컬럼이나 문자열에서 지정한 위치부터 지정된 길이만큼 문자열을 잘라내서 반환
--> 잘라낼 길이 생략 시 끝까지 잘라냄
-- EMPLOYEE 테이블에서 사원명, 이메일 중 아이디만 조회
-- sun_di@KH.or.kr --> sun_di
SELECT EMP_NAME, SUBSTR ( EMAIL, 1, INSTR(EMAIL, '@') -1 ) 아이디
FROM EMPLOYEE;
---------------------------------------------------------------------
-- TRIM ( [[옵션] '문자열' | 컬럼명 FROM ] '문자열' | 컬럼명 )
-- 주어진 컬럼이나 문자열의 앞, 뒤, 양쪽에 있는 지정된 문자를 제거
--> 양쪽 공백 제거에 많이 사용한다.
-- 옵션 : LEADING(앞쪽), TRAILING(뒤쪽), BOTH(양쪽)
SELECT TRIM(' H E L L O ')
FROM DUAL; -- 양쪽 공백 제거
SELECT TRIM(BOTH '#' FROM '####안녕#####')
FROM DUAL;
---------------------------------------------------------------------
/* 숫자 관련 함수 */
-- ABS(숫자 | 컬럼명) : 절대값
SELECT ABS(10), ABS(-10) FROM DUAL; -- 둘 다 10
SELECT '절대값 같음' FROM DUAL
WHERE ABS(10) = ABS(-10); -- WHERE 절 함수 작성 가능
-- MOD(숫자 | 컬럼명, 숫자 | 컬럼명) : 나머지 값 반환
-- EMPLOYEE 테이블에서 사원의 월급을 100만으로 나눴을 때 나머지 조회
SELECT EMP_NAME, SALARY, MOD(SALARY, 1000000)
FROM EMPLOYEE;
-- EMPLOYEE 테이블에서 사번이 짝수인 사원의 사번, 이름 조회
SELECT EMP_ID, EMP_NAME
FROM EMPLOYEE
WHERE MOD(EMP_ID, 2) = 0;
-- EMPLOYEE 테이블에서 사번이 홀수인 사원의 사번, 이름 조회
SELECT EMP_ID, EMP_NAME
FROM EMPLOYEE
WHERE MOD(EMP_ID, 2) != 0;
-- ROUND( 숫자 | 컬럼명 [, 소수점 위치] ) : 반올림
SELECT ROUND(123.456) FROM DUAL; -- 123, 소수점 첫 번째 자리에서 반올림
-- = SELECT ROUND(123.456, 0) FROM DUAL;
SELECT ROUND(123.456, 1) FROM DUAL; -- 123.5, 소수점 두 번째 자리에서 반올림
-- CEIL(숫자 | 컬럼명) : 올림
-- FLOOR(숫자 | 컬럼명) : 내림
--> 둘 다 소수점 첫 번째 자리에서 올림/내림 처리
SELECT CEIL(123.456) FROM DUAL; -- 124
SELECT FLOOR(123.456) FROM DUAL; -- 123
SELECT CEIL(123.1), FLOOR(123.9) FROM DUAL; -- 124, 123
-- TRUNC(숫자 | 컬럼명 [,위치]) : 특정 위치 아래를 버림(첨삭)
SELECT TRUNC(123.456) FROM DUAL; -- 123
SELECT TRUNC(123.456, 2) FROM DUAL; -- 123.45
SELECT TRUNC(123.456, -1) FROM DUAL; -- 120
/* 내림, 버림 차이점 */
SELECT FLOOR(-123.5), TRUNC(-123.5) FROM DUAL; -- -124, -123
---------------------------------------------------------------------
/* 날짜(DATE) 관련 함수 */
-- SYSDATE : 시스템에 현재 시간 (년, 월, 일, 시, 분, 초)을 반환
SELECT SYSDATE FROM DUAL;
-- SYSTIMESTAMP : SYSDATE + MS 단위 추가
SELECT SYSTIMESTAMP FROM DUAL;
-- TIMESTAMP : 특정 시간을 나타내거나 기록하기 위한 문자열
-- MONTHS_BETWEEN(날짜, 날짜) : 두 날짜의 개월 수 차이 반환
SELECT ABS( ROUND(MONTHS_BETWEEN(SYSDATE, '2023-12-22'), 3) ) "수강 기간(개월)"
FROM DUAL; -- 4.568
-- EMPLOYEE 테이블에서
-- 사원의 이름, 입사일, 근무한 개월 수, 근무 년차 조회
SELECT EMP_NAME, HIRE_DATE,
CEIL ( MONTHS_BETWEEN(SYSDATE, HIRE_DATE) ) "근무한 개월 수",
CEIL ( MONTHS_BETWEEN(SYSDATE, HIRE_DATE) / 12 ) || '년차' "근무 년차"
FROM EMPLOYEE;
/* || : 연결 연산자 (문자열 이어쓰기) */
-- ADD_MONTHS(날짜, 숫자) : 날짜에 숫자만큼의 개월 수를 더함. (음수도 가능)
SELECT ADD_MONTHS(SYSDATE, 4) FROM DUAL;
SELECT ADD_MONTHS(SYSDATE, -1) FROM DUAL;
-- LAST_DAY(날짜) : 해당 달의 마지막 날짜를 구함
SELECT LAST_DAY(SYSDATE) FROM DUAL;
SELECT LAST_DAY('2020-02-01') FROM DUAL;
-- EXTRACT : 년, 월, 일 정보를 추출하여 리턴
-- EXTRACT(YEAR FROM 날짜) : 년도만 추출
-- EXTRACT(MONTH FROM 날짜) : 월만 추출
-- EXTRACT(DAY FROM 날짜) : 일만 추출
-- EMPLOYEE 테이블에서
-- 각 사원의 이름, (입사 년도, 월, 일) 조회
SELECT EMP_NAME,
EXTRACT(YEAR FROM HIRE_DATE) || '년 ' ||
EXTRACT(MONTH FROM HIRE_DATE) || '월 ' ||
EXTRACT(DAY FROM HIRE_DATE) || '일' AS 입사일
FROM EMPLOYEE;
---------------------------------------------------------------------
/* 형변환 함수 */
-- 문자열(CHAR), 숫자(NUMBER), 날짜(DATE) 끼리 형변환 가능
/* 문자열로 변환 */
-- TO_CHAR(날짜, [포맷]) : 날짜형 데이터를 문자형 데이터로 변경
-- TO_CHAR(숫자, [포맷]) : 숫자형 데이터를 문자형 데이터로 변경
-- <숫자 변환 시 포맷 패턴>
-- 9 : 숫자 한칸을 의미, 여러개 작성 시 오른쪽 정렬
-- 0 : 숫자 한칸을 의미, 여러개 작성 시 오른쪽 정렬 + 빈칸 0 추가
-- L : 현재 DB에 설정된 나라의 화폐 기호
SELECT TO_CHAR(1234, '99999') FROM DUAL; -- ' 1234'
SELECT TO_CHAR(1234, '00000') FROM DUAL; -- '01234'
SELECT TO_CHAR(1234) FROM DUAL; -- '1234'
SELECT TO_CHAR(1000000, '9,999,999') || '원' FROM DUAL;
SELECT TO_CHAR(1000000, 'L9,999,999') FROM DUAL; -- '\1,000,000'
-- < 날짜 변환 시 포맷 패턴 >
-- YYYY : 년도 / YY : 년도 (짧게)
-- MM : 월
-- DD : 일
-- AM 또는 PM : 오전/오후 표시
-- HH : 시간 // HH24 : 24시간 표기법
-- MI : 분 / SS : 초
-- DAY : 요일(전체) / DY : 요일(요일명만 표시)
-- 2023/08/04 10:06:45 금요일
SELECT TO_CHAR(SYSDATE, 'YYYY/MM/DD HH24:MI:SS DAY') FROM DUAL;
-- 08/04 (금)
SELECT TO_CHAR(SYSDATE, 'MM/DD (DY)') FROM DUAL;
-- 2023년 08월 04일 (금)
SELECT TO_CHAR(SYSDATE, 'YYYY"년" MM"월" DD"일" (DY)') FROM DUAL;
--SQL Error [1821] [22008] : ORA-01821: 날짜 형식이 부적합합니다
-- 년, 월, 일이 날짜를 나타내는 패턴으로 인식이 안되서 오류 발생
--> "" 쌍따옴표를 이용해서 단순한 문자로 인식시키면 해결됨
---------------------------------------------------------------------
/* 날짜로 변환 TO_DATE */
-- TO_DATE(문자형 데이터, [포맷]) : 문자형 데이터를 날짜로 변경
-- TO_DATE(숫자형 데이터, [포맷]) : 숫자형 데이터를 날짜로 변경
--> 지정된 포맷으로 날짜를 인식함
SELECT TO_DATE('2022-09-02') FROM DUAL; -- DATE 타입 변환
SELECT TO_DATE(20230804) FROM DUAL;
SELECT TO_DATE('230804 101835', 'YYMMDD HH24MISS') FROM DUAL;
-- SQL Error [1861] [22008]: ORA-01861: 리터럴이 형식 문자열과 일치하지 않음
--> 패턴을 적용해서 작성된 문자열의 각 문자가 어떤 날짜 형식인지 인지 시킴
-- EMPLOYEE 테이블에서 각 직원이 태어난 생년월일 조회
SELECT EMP_NAME,
TO_CHAR( TO_DATE( SUBSTR ( EMP_NO, 1, INSTR (EMP_NO, '-') -1 ) , 'RRMMDD' ),
'YYYY"년" MM"월" DD"일"' ) AS 생년월일
FROM EMPLOYEE;
-- Y 패턴 : 현재 세기(21세기 == 20XX년 == 2000년대)
-- R 패턴 : 1900년대
-- 1세기 기준으로 절반(50년) 이상인 경우는 이전 세기 (1900년대)
-- 절반(50년) 미만인 경우는 현재 세기 (2000년대)
SELECT TO_DATE('500505', 'YYMMDD') FROM DUAL;
SELECT TO_DATE('490505', 'RRMMDD') FROM DUAL; -- 2049
SELECT TO_DATE('500505', 'RRMMDD') FROM DUAL; -- 1950
---------------------------------------------------------------------
/* 숫자 형변환 */
-- TO_NUMBER(문자데이터, [포맷]) : 문자형 데이터를 숫자로 변경
SELECT '1,000,000' + 500000 FROM DUAL;
--SQL Error [1722] [42000]: ORA-01722: 수치가 부적합합니다
SELECT TO_NUMBER('1,000,000', '9,999,999') + 500000 FROM DUAL; -- 1,500,000
/*(중요!) NULL 처리 함수 */
-- NVL(컬럼명, 컬럼값이 NULL일 때 바꿀 값) : NULL인 컬럼값을 다른 값으로 변경
/* NULL과 산술 연산을 진행하면 결과는 무조건 NULL */
SELECT EMP_NAME, SALARY, NVL(BONUS, 0), SALARY * NVL(BONUS, 0)
FROM EMPLOYEE;
-- NVL2(컬럼명, 바꿀값1, 바꿀값2)
-- 해당 컬럼의 값이 있으면 바꿀값1로 변경,
-- 해당 컬럼이 NULL이면 바꿀값2로 변경
-- EMPLOYEE 테이블에서 보너스를 받으면 'O', 안받으면 'X' 조회
SELECT EMP_NAME, NVL2(BONUS, '0', 'X') "보너스 수령"
FROM EMPLOYEE;
---------------------------------------------------------------------
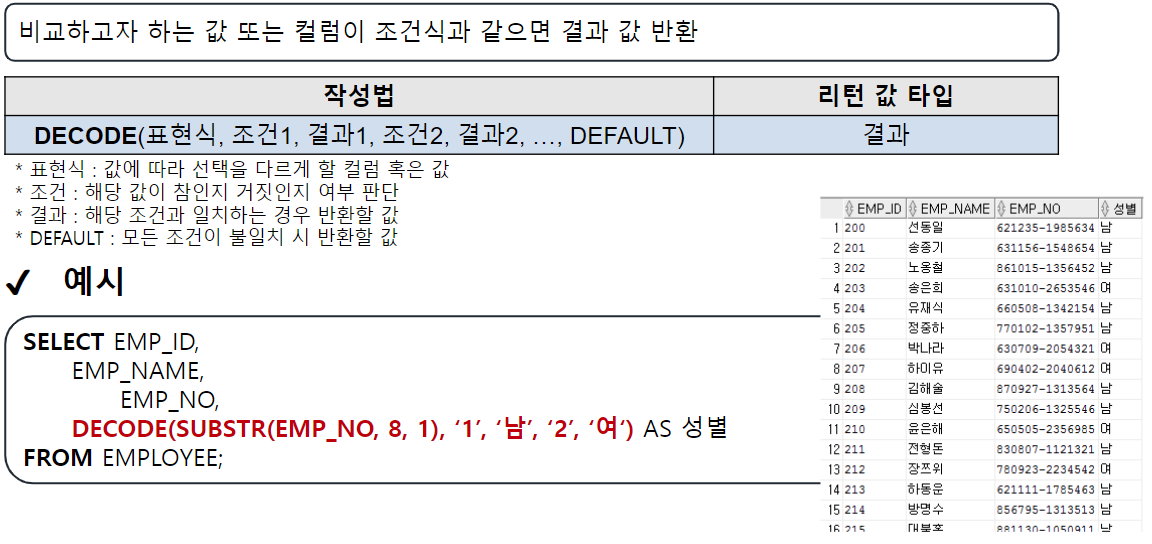
/* 선택 함수 */
-- 여러 가지 경우에 따라 알맞은 결과를 선택할 수 있음.
-- DECODE(계산식 | 컬럼명, 조건값1, 선택값1, 조건값2, 선택값2, ..., 아무것도 일치하지 않을 때)
-- 비교하고자 하는 값 또는 컬럼이 조건식과 같으면 결과값 반환
-- 일치하는 값을 확인(자바의 SWITCH 비슷함)
-- 직원의 성별 구하기 (남 : 1 / 여 : 2)
SELECT EMP_NAME, DECODE ( SUBSTR(EMP_NO, 8, 1) , '1' , '남성', '2', '여성') 성별
FROM EMPLOYEE;
-- 직원의 급여를 인상하고자 한다.
-- 직급 코드가 J7인 직원은 20% 인상,
-- 직급 코드가 J6인 직원은 15% 인상,
-- 직급 코드가 J5인 직원은 10% 인상,
-- 그 외 직급은 5% 인상
SELECT EMP_NAME,
DECODE( JOB_CODE, 'J7', '20%', 'J6', '15%', 'J5', '10%', '5%') 인상률,
DECODE ( JOB_CODE, 'J7', SALARY * 1.2, 'J6', SALARY * 1.15, 'J5', SALARY * 1.1, SALARY * 1.05) "인상된 급여"
FROM EMPLOYEE;
-- CASE WHEN 조건식 THEN 결과값
-- WHEN 조건식 THEN 결과값
-- ELSE 결과값
-- END
-- 비교하고자 하는 값 또는 컬럼이 조건식과 같으면 결과 값 반환
-- 조건은 범위 값 가능
-- EMPLOYEE 테이블에서
-- 급여가 500만원 이상이면 '대'
-- 급여가 300만 이상 500만 미만이면 '중'
-- 급여가 300만 미만 '소'으로 조회
SELECT EMP_NAME, SALARY,
CASE WHEN SALARY >= 5000000 THEN '대' -- if
WHEN SALARY >= 3000000 AND SALARY < 50000000 THEN '중' -- else if
WHEN SALARY < 3000000 THEN '소' -- ELSE '소'
END "급여 받는 정도"
FROM EMPLOYEE;
---------------------------------------------------------------------
/* 그룹 함수 */
-- 하나 이상의 행을 그룹으로 묶어 연산하여 총합, 평균 등의 하나의 결과 행으로 반환하는 함수
-- SUM(숫자가 기록된 컬럼명) : 합계
-- 모든 직원의 급여 합
SELECT SUM(SALARY) FROM EMPLOYEE;
-- AVG(숫자가 기록된 컬럼명) : 평균
-- 모든 직원의 급여 평균
SELECT ROUND( AVG(SALARY) ) FROM EMPLOYEE;
-- 부서코드가 'D9' 인 사원들의 급여 합, 평균 조회
/* 3. */SELECT SUM(SALARY), ROUND(AVG(SALARY))
/* 1. */FROM EMPLOYEE
/* 2. */WHERE DEPT_CODE = 'D9';
-- MIN(컬럼명) : 최소값
-- MAX(컬럼명) : 최대값
--> 타입 제한 없음(숫자: 대/소, 날짜: 과거/미래, 문자열: 문자 순서)
-- 급여 최소값, 가장 빠른 입사일, 알파벳 순서가 가장 빠른 이메일
SELECT MIN(SALARY), MIN(HIRE_DATE), MIN(EMAIL)
FROM EMPLOYEE;
-- 급여 최대값, 가장 늦은 입사일, 알파벳 순서가 가장 느린 이메일
SELECT MAX(SALARY), MIN(SALARY), MAX(EMAIL)
FROM EMPLOYEE;
-- EMPLOYEE 테이블에서 급여를 가장 많이 받는 사원의
-- 이름, 급여, 직급 코드 조회
SELECT EMP_NAME, SALARY, JOB_CODE
FROM EMPLOYEE
WHERE SALARY = ( SELECT MAX(SALARY) FROM EMPLOYEE );
-- 서브쿼리 + 그룹함수
-- * COUNT(* | 컬럼명) : 행 개수를 헤아려서 리턴
-- COUNT([DISTINCT] 컬럼명) : 중복을 제거한 행 개수를 헤아려서 리턴
-- COUNT(*) : NULL을 포함한 전체 행 개수를 리턴
-- COUNT(컬럼명) : NULL을 제외한 실제 값이 기록된 행 개수를 리턴
-- EMPLOYEE 테이블의 행의 개수
SELECT COUNT(*) FROM EMPLOYEE;
-- BONUS를 받는 사원의 수
SELECT COUNT(*) FROM EMPLOYEE
WHERE BONUS IS NOT NULL; -- 9명
SELECT COUNT(BONUS) FROM EMPLOYEE; -- 9명
SELECT DISTINCT DEPT_CODE FROM EMPLOYEE; -- 7
SELECT COUNT(DISTINCT DEPT_CODE) FROM EMPLOYEE; -- 6
-- COUNT(컬럼명)에 의해서 NULL을 제외한 실제 값이 기록된 행 개수만 조회
-- EMPLOYEE 테이블에서 성별이 남성인 사원의 수 조회
SELECT COUNT(*)
FROM EMPLOYEE
WHERE SUBSTR(EMP_NO, 8, 1) = '1';
초보자