
많은 그룹들
ORDER BY
SELECT한 컬럼에 대해 정렬을 할 때 작성하는 구문으로
SELECT 구문의 가장 마지막에 작성하며 실행 순서 역시 가장 마지막에 수행됨

GROUP BY
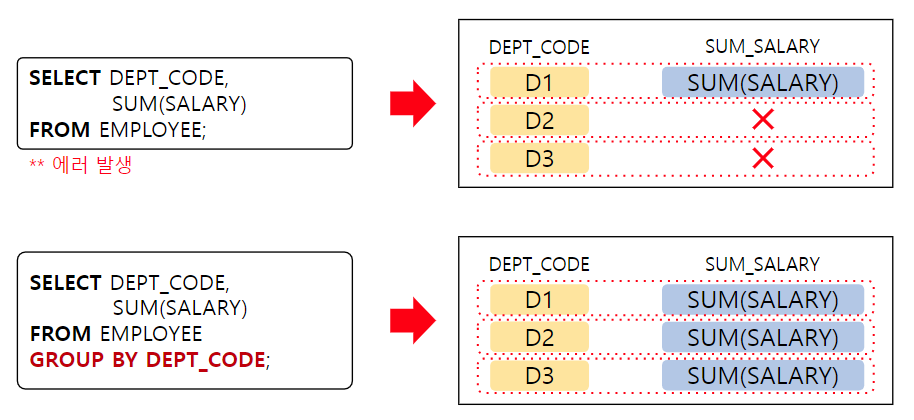
그룹 함수는 단 한 개의 결과 값만 산출하기 때문에 그룹이 여러 개일 경우 오류 발생
여러 개의 결과 값을 산출하기 위해 그룹 함수가 적용될 그룹의 기준을 GROUP BY절에 기술하여 사용


HAVING
그룹 함수로 값을 구해올 그룹에 대해 조건을 설정할 때 HAVING절에 기술
(WHERE절은 각 컬럼 값에 대한 조건)

ROLLUP과 CUBE
그룹 별 산출한 결과 값의 집계를 계산하는 함수
ROLLUP

CUBE




GROUP BY_HAVING
/* SELECT 문 해석순서
*
* 5 : SELECT 컬럼명 AS별칭, 계산식, 함수식
* 1 : FROM 참조할 테이블명
* 2 : WHERE 컬럼명 | 함수식 비교연산자 비교값
* 3 : GROUP BY 그룹을 묶을 컬럼명
* 4 : HAVING 그룹함수식 비교연산자 비교값
* 6 : ORDER BY 컬럼명 | 별칭 | 컬럼순번 정렬방식 [NULLS FIRST | LAST]
*
*/
-------------------------------------------------------------------------------------
-- GROUP BY 절 : 같은 값들이 여러개 기록된 컬럼을 가지고 같은 값들을 하나의 그룹으로 묶음
-- 같은 값들을 하나의 그룹으로 묶음
-- GROUP BY 컬럼명 | 함수식, ...
-- 여러개의 값을 묶어서 하나로 처리할 목적으로 사용함
-- 그룹으로 묶은 값에 대해서 SELECT절에서 그룹함수를 사용함
-- 그룹 함수는 단 한개의 결과값만 산출하기 때문에
-- 그룹이 여러개일 경우 오류 발생
-- EMPLOYEE 테이블에서 부서코드, 부서별 급여 합 조회
-- 1) 부서코드만 조회
SELECT DEPT_CODE FROM EMPLOYEE; -- 23행
-- 2) 전체 급여 합 조회
SELECT SUM(SALARY) FROM EMPLOYEE; -- 1행
SELECT DEPT_CODE, SUM(SALARY) -- 5
FROM EMPLOYEE; -- 1
GROUP BY DEPT_CODE; -- 3 DEPT_CODE가 같은 행끼리 하나의 그룹이 됨
--SQL Error [937] [42000]: ORA-00937: 단일 그룹의 그룹 함수가 아닙니다
-- EMPLOYEE 테이블에서
-- 직급 코드가 같은 사람의 직급코드, 급여 평균, 인원수를
-- 직급코드 오름 차순으로 조회
SELECT JOB_CODE, ROUND(AVG(SALARY)), COUNT(*)
FROM EMPLOYEE
GROUP BY JOB_CODE
ORDER BY JOB_CODE;
-- EMPLOYEE 테이블에서
-- 성별(남/여)와 각 성별 별 인원 수, 급여합을
-- 인원수 오름 차순으로 조회
SELECT DECODE( SUBSTR(EMP_NO, 8, 1), '1', '남', '2', '여' ) 성별,
COUNT(*) "인원 수",
SUM(SALARY) "급여 합"
FROM EMPLOYEE
GROUP BY DECODE( SUBSTR(EMP_NO, 8, 1), '1', '남', '2', '여' ) -- 별칭 사용 X (SELECT절 해석X)
ORDER BY "인원 수"; -- 별칭 사용 O (SELECT절 해석 완료)
-------------------------------------------------------------------------------------
-- * WHERE절 GROUP BY절을 혼합하여 사용
--> WHERE절은 각 컬럼에 대한 조건
-- EMPLOYEE 테이블에서 부서코드가 D5, D6인 부서의 부서별 평균 급여, 인원 수 조회
SELECT DEPT_CODE, ROUND(AVG(SALARY)), COUNT(*)
FROM EMPLOYEE
WHERE DEPT_CODE IN ('D5', 'D6')
GROUP BY DEPT_CODE;
-- EMPLOYEE 테이블에서 직급별 2000년도 이후(2000년 포함) 입사자들의 급여합을 조회
-- (직급코드 오름차순)
SELECT JOB_CODE, SUM(SALARY) "급여 합"
FROM EMPLOYEE
WHERE HIRE_DATE >= TO_DATE('2000-01-01')
GROUP BY JOB_CODE
ORDER BY 1;
-------------------------------------------------------------------------------------
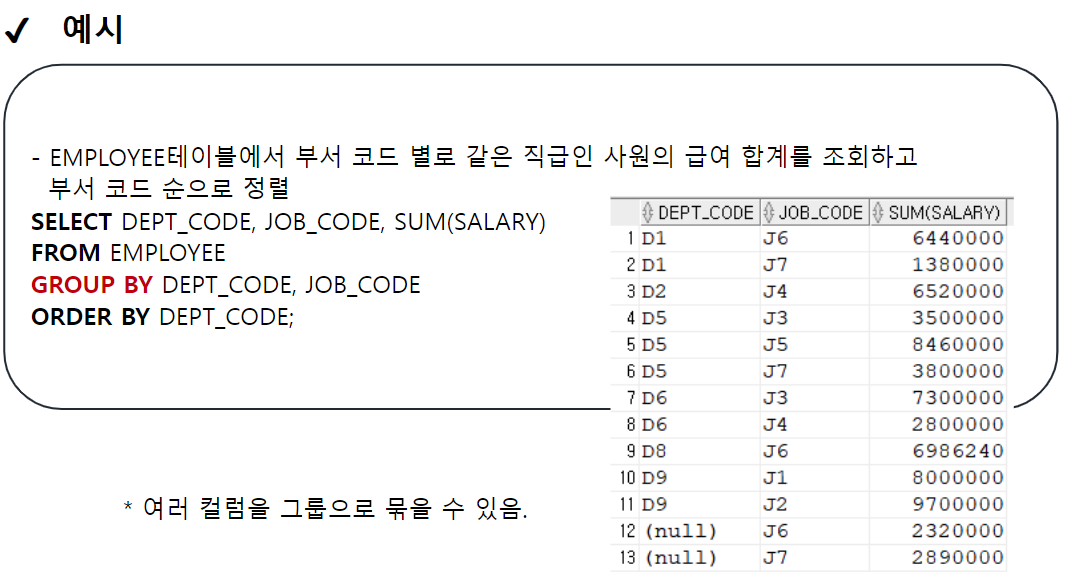
-- * 여러 컬럼을 묶어서 그룹으로 지정 가능 --> 그룹내 그룹
-- EMPLOYEE 테이블에서 부서별로 같은 직급인 사원의 수를 조회
SELECT DEPT_CODE, JOB_CODE, COUNT(*)
FROM EMPLOYEE
GROUP BY DEPT_CODE, JOB_CODE -- DEPT_CODE로 그룹을 나누고,
-- 나눠진 그룹내에서 JOB_CODE로 또 그룹을 분류
--> 세분화
ORDER BY DEPT_CODE, JOB_CODE DESC;
-- *** GROUP BY 사용 시 주의사항 ***
-- SELECT문에 GROUP BY절을 사용할 경우
-- SELECT절에 명시한 조회하려는 컬럼 중
-- 그룹함수가 적용되지 않은 컬럼을
-- 모두 GROUP BY절에 작성해야함.
-------------------------------------------------------------------------------------
-- * HAVING 절 : 그룹 함수로 구해 올 그룹에 대한 조건을 설정할 때 사용
-- HAVING 컬럼명 | 함수식 비교연산자 비교값
-- 부서별 평균 급여가 3백만원 이상인 부서를 조회
SELECT DEPT_CODE, ROUND ( AVG(SALARY) )
FROM EMPLOYEE
-- WHERE SALARY >= 3000000 --> 한사람의 급여가 3백만 이상이라는 조건
GROUP BY DEPT_CODE
HAVING AVG(SALARY) >= 3000000 --> DEPT_CODE 그룹 중 급여 평균이 3백만 이상인 그룹만 조회
ORDER BY DEPT_CODE;
-- EMPLOYEE 테이블에서 직급별 인원수가 5명 이하인 직급코드, 인원수 조회(직급코드 오름차순)
SELECT JOB_CODE, COUNT(*)
FROM EMPLOYEE
GROUP BY JOB_CODE
HAVING COUNT(*) <= 5
ORDER BY 1;
-------------------------------------------------------------------------------------
-- 집계 함수(ROLLUP, CUBE)
-- 그룹 별 산출 결과 값의 집계를 계산하는 함수
-- (그룹별로 중간 집계 결과를 추가)
-- GROUP BY 절에서만 사용할 수 있는 함수!
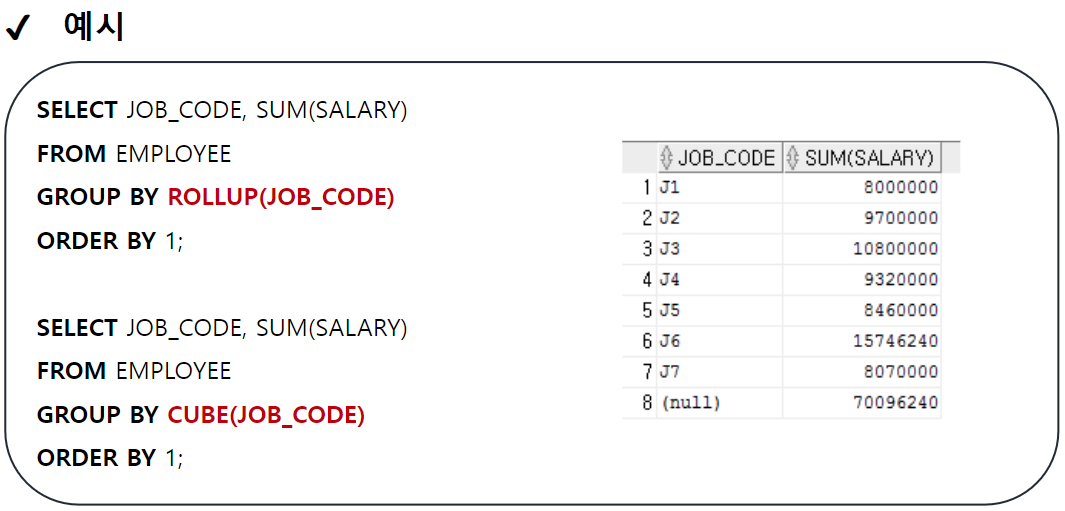
-- ROLLUP : GROUP BY절에서 가장 먼저 작성된 컬럼의 중간 집계를 처리하는 함수
SELECT DEPT_CODE, JOB_CODE, COUNT(*)
FROM EMPLOYEE
GROUP BY ROLLUP(DEPT_CODE, JOB_CODE)
ORDER BY 1;
-- CUBE : GROUP BY 절에 작성된 모든 컬럼의 중간 집계를 처리하는 함수
SELECT DEPT_CODE, JOB_CODE, COUNT(*)
FROM EMPLOYEE
GROUP BY CUBE(DEPT_CODE, JOB_CODE)
ORDER BY 1;
-------------------------------------------------------------------------------------
/* SET OPERATOR(집합 연산자)
*
* -- 여러 SELECT의 결과(RESULT SET)를 하나의 결과로 만드는 연산자
*
* - UNION(합집합) : 두 SELECT 결과를 하나로 합침
* 단, 중복은 한번만 작성
*
* - INTERSECT(교집합) : 두 SELECT 결과 중 중복되는 부분만 조회
*
* - UNION ALL : UNION + INTERSECT : 합집합에서 중복 부분 제거 X
*
* - MINUS (차집합) : A에서 A,B 교집합 부분을 제거하고 조회
*
*/
-- 부서코드가 'D5'인 사원의 사번, 이름, 부서코드, 급여 조회
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5'
--UNION
--UNION ALL
--INTERSECT
MINUS
-- 급여가 3백만 초과인 사원의 사번, 이름, 부서코드, 급여 조회
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY > 3000000;
-- (주의사항 !) 집합 연산자를 사용하지 위한 SELECT문들은
-- 조회하는 컬럼의 타입, 개수가 모두 동일해야 한다!
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5'
UNION
SELECT EMP_ID, EMP_NAME, DEPT_CODE, 1
FROM EMPLOYEE
WHERE SALARY > 3000000;
-- 서로 다른 테이블이지만 컬럼의 타입, 개수만 일치하면 집합연산자 사용 가능!
SELECT EMP_ID, EMP_NAME FROM EMPLOYEE
UNION
SELECT DEPT_ID, DEPT_TITLE FROM DEPARTMENT;
초보자