Mac에 Deepseek 설치하여 Local AI로 이용하기
오늘은 나의 Macbook에 딥씨크를 설치해보려고 한다. 이에 앞서 커뮤니티를 찾아봤던 다음과 같은 과정, 장단점을 찾을 수 있었다. 설치과정은 AI model을 선정하는 것으로 시작하여 서빙 프로그램을 설치하고, 그 위에 LLM(대규모 언어모델)을 install하는 순서로 진행된다. 장점은 LLM을 사용할 때 클라우드 API로 접근할 때 발생하는 시간과 비용을 아낄 수 있다는 점인데 단점은 성능이 높지 않은 컴퓨터(프로세서, 메모리)를 이용하면 속도가 느려진다는 점이다. 그렇기에 m4 pro는 48GB 메모리, m4 max는 32GB 메모리 이상이 되야 유의미하다는 말들도 많았다. 나는 m4 기본에 32GB 메모리지만 한 번 해보고 별로면 지우도록 하겠다.
일단 난 내 노트북 성능과 관련하여 32GB 통합 Ram을 사용하고 있는데, Vram 기준으로 16~24기가 정도 할당할 수 있는 듯 하다. 이를 기반으로 보면 13~14B 모델을 사용하여 코드 생성 및 데이터 분석을 시킬 수 있는데 이것만 하는 것도 아니고 고성능 데스크탑도 아니니, 일단은 일반 노트북 용인 7~8B 모델을 사용하는게 맞지 않을까 생각되지만 코딩 도우미를 써야하니 14B는 써야 할 듯한데... 그냥 14로 쓰겠다.
다음으로 OSS LLM 서빙 프로그램을 설치해야 한다. 서빙 프로그램에는 Ollama, vLLM, OpenLLM, LocalAI, GPT4All 등이 있다. 이 중에 난 Ollama를 사용하려고 한다. 쉬운 설치 및 사용, 양자화 모델지원, 다양한 운영체제 지원이라는 장점이 있다. 다만 분산 처리 및 배칭 기능 부재와 AWQ가 미지원된다는 단점도 있으니 참고해야 한다. 그러나 GPU가 따로 없는 경우(NPU만 있는 경우)에 Ollama는 좋은 선택지가 된다고 한다.
https://ollama.com/download/mac 에서 다운로드 해주고, 실행해주면 open at login에 등록되면서 앱이 생성된다. 그러면 이 앱에서 install할 수 있도록 command line에 명령어를 입력하라고 한다. 그러면 앱에서 install 버튼 클릭하고 ollama run llama3.2를 입력하고 설치 완료를 기다리면 된다. 그렇게 다 설치가 되면 이 위치에 저장된다. ~/.ollama
난 중간에 올라마가 제대로 실행되지 않고 꺼져서, 그 이유를 찾기 위한 방법을 배웠다. Error: Post "http://127.0.0.1:11434/api/chat": dial tcp 127.0.0.1:11434: connect: connection refused라는 문구가 나오며 올라마가 종료되는데, 이걸 터미널에서 찾기 위해 top와 netstat -nlt -p tcp를 이용하여 찾을 수 있다고 한다. 이게 포트 연결 오류라서 이걸 통해 찾는 듯 하니, 새 글에서 따로 다뤄볼 생각이다.
이제 ollama 사이트에서 딥씨크를 다운받아야 한다. 난 deepseek-r1에서 14b 모델을 선택했다.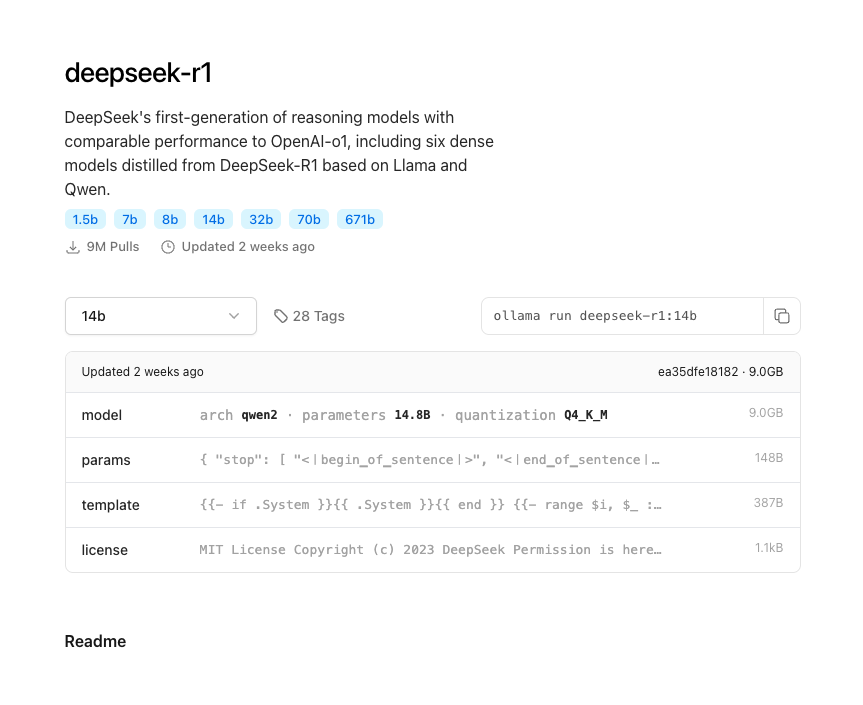
이제 28tags 옆에 ollama run deepseek-r1:14b를 복붙하여 터미널 창에 입력하면 된다. 설치가 완료되면 터미널 창에서 다시 위 명령어를 작동시키면 설치 없이 딥씨크를 사용할 수 있다.
마지막으로 Terminal 창이 아니라 제대로된 UI에서 딥씨크를 돌리고 싶다면 https://chatboxai.app 다운받거나 Docker에서 open-webui를 실행하면 된다.
