Querying Data의 Select 문(Distinct) - PostgreSQL
일반적으로 데이터베이스작업 중 테이블에서 데이터를 검색하기 위해서 select문을 사용한다. DB에서 가장 복잡한 문법 중 하나가 select이지만 원하는 쿼리를 구성하는데 다양한 clause로 도움을 받을 수 있다.
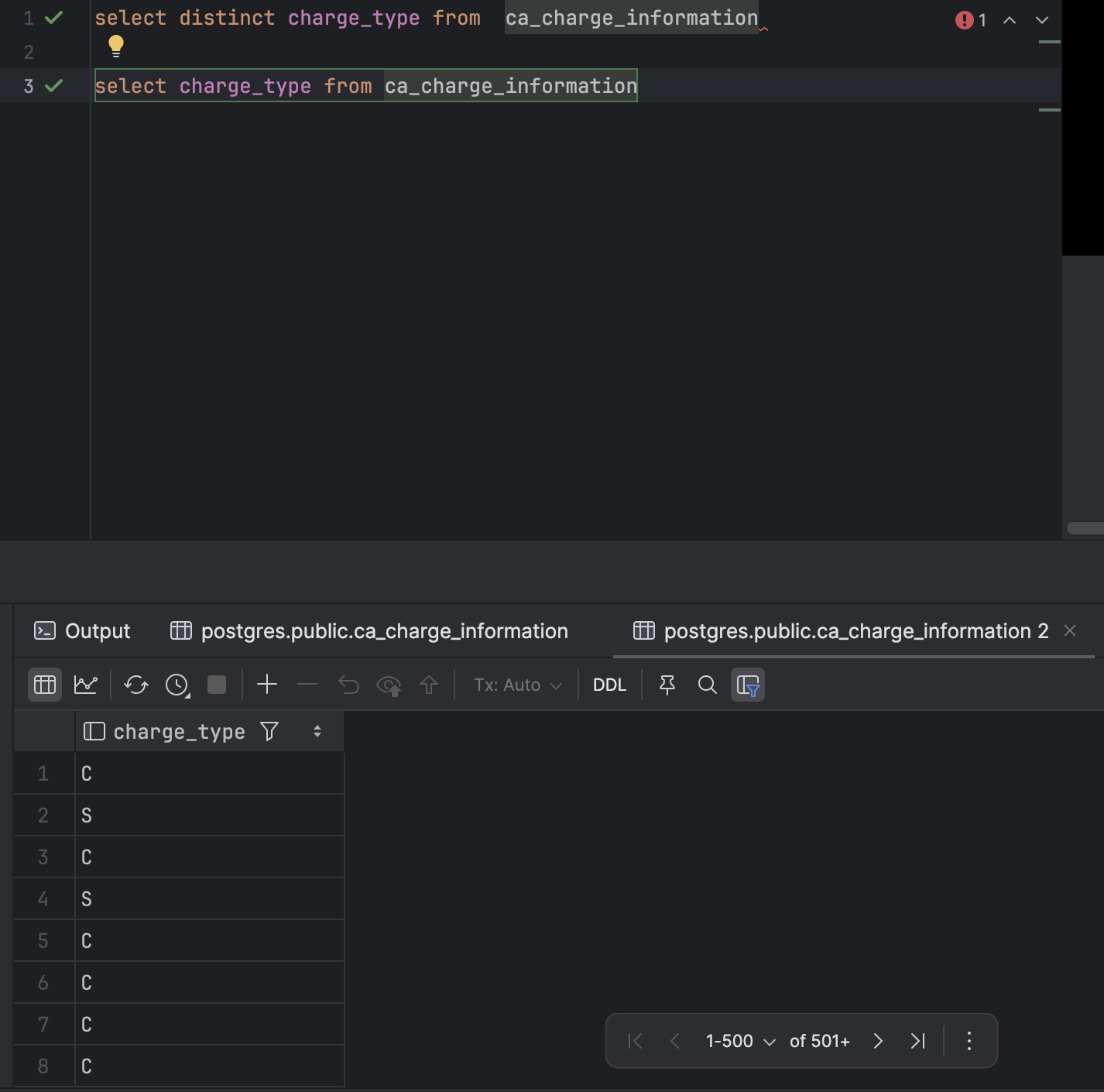
(1) Distinct 연산자 : 고유한 행 선택하여 출력하기
select (컬럼명) from (테이블 이름) 중복된 데이터를 제외하고 조회할 때 사용함(고유값을 찾을 때 도움)
select (컬럼명1), (컬럼명2), (컬럼명3) from (테이블 명) 여러 열을 출력할 수도 있음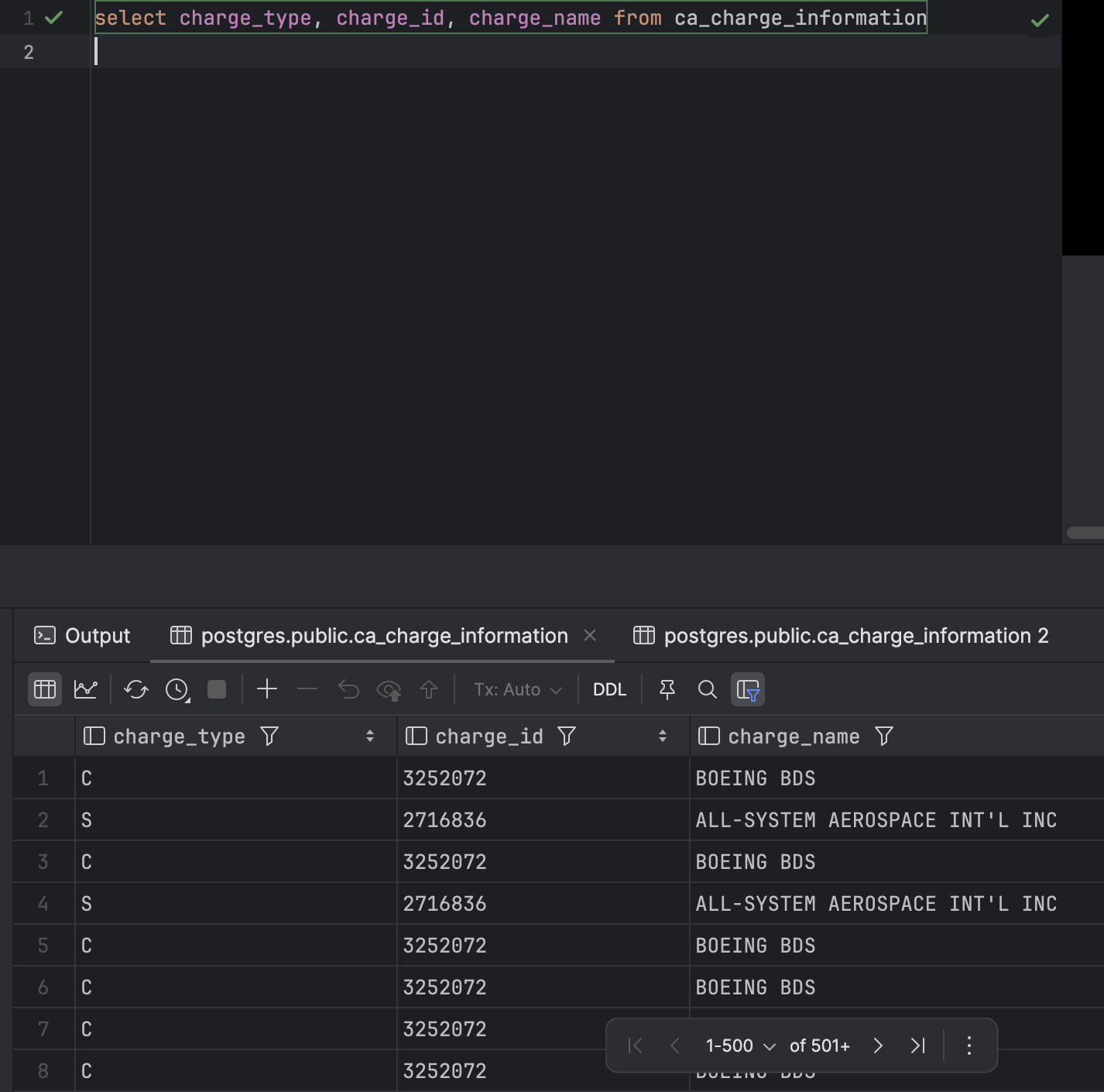
select * from (테이블 명) 해당 테이블의 모든 열 조회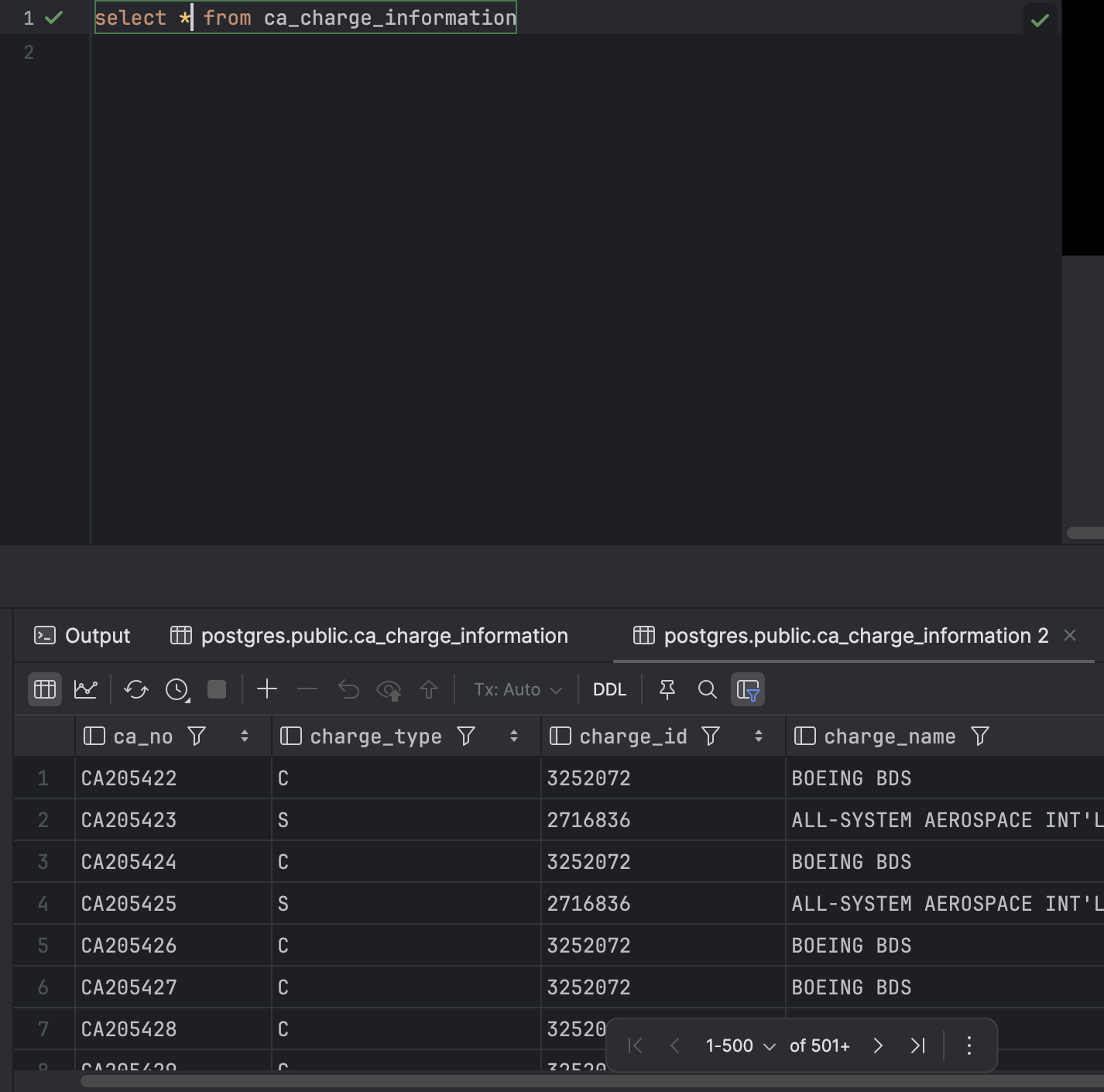
- 연결 연산자 이용하여 출력되는 내용을 이어 붙일수도 있다. 타입과 이름을 이어붙여 보겠다. ||만 쓰면 그냥 이어붙여지고 ||'(사이 연결원하는 문자나 띄어쓰기)||를 하면 사이에 원하는대로 표현할 수 있다.
select (컬럼1) ||' '|| (컬럼2) from (테이블 명)이러면 사이에 띄어쓰기 하나만 넣고 이어붙이는 연결 연산자를 사용한 것이다.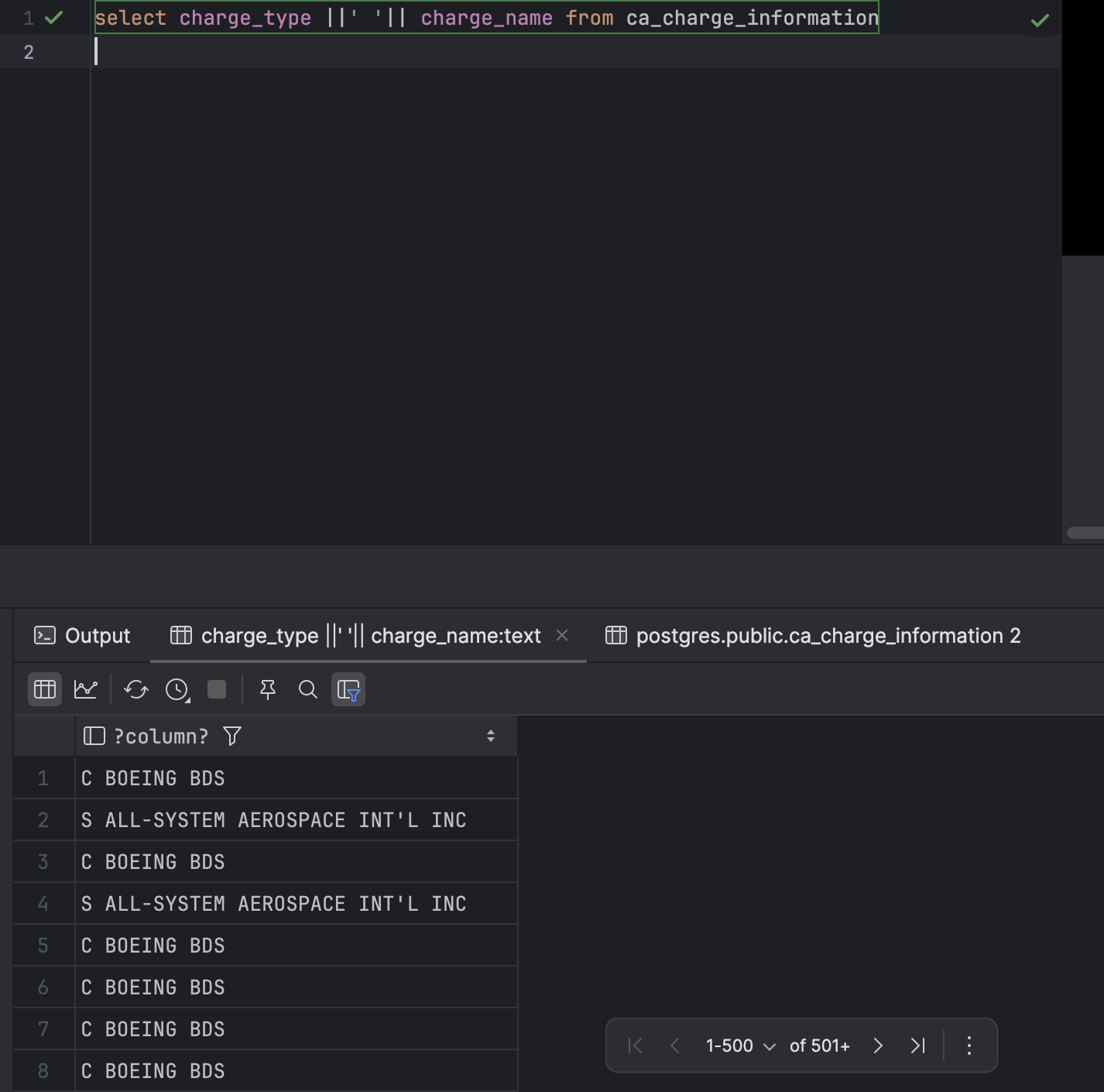
이어붙인 것에 새로운 이름을 붙일 수도 있다. 바로 AS 키워드를 사용하면 된다.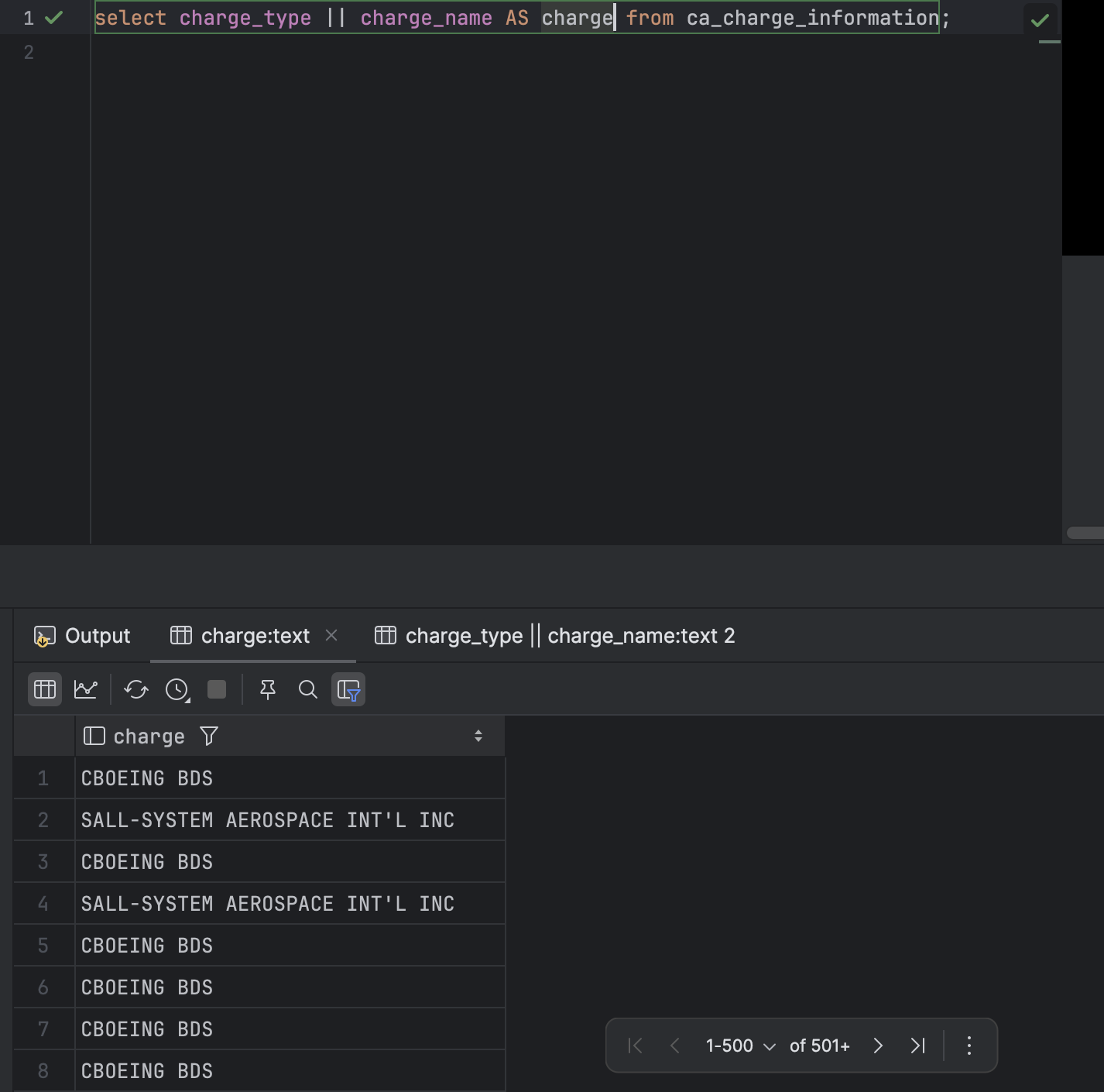
이번에는 열(컬럼) column alias(별칭)과 쿼리의 열에 임시 이름을 할당하는 법도 정리해보겠다.
먼저 열 별칭은select (컬럼명) AS (별칭) from (테이블 명);끝이다. 간단하다.
SELECT (expression) AS alias_name 출력하려는 expression의 이름도 마음대로 지정 가능하다.
그리고 select (컬럼명) ||' '|| (컬럼명2) AS "(원하는 별칭)"이렇게도 지정이 가능하다.
select문만 해도 이렇게 많다니... 사실 엄청 많진 않고 알고보면 간단한데, 내가 처음 접해보고 자료가 영어라 좀 오래 걸린 듯 하다. 그렇다면 많이 접해보고, 영어에 익숙해지면 되겠다(간단한 해결책이다...
아래 내용들은 데이터 조회의 항목들이다. 여기서 1, Select에서 distinct만 완료한 것이다.
다음 글에서 (2)부터 아래 내용들을 차차 추가해나가도록 하겠다.
(2) Order By절 : 행 정렬
오름차순이나 내림차순으로 정렬
(3) Where절 : 행 필터링
(4) Limit, Fetch절 : 행의 하위 집합을 선택
(5) Group by절 : 행을 그룹화
(6) Having절 : 그룹을 필터링
(7) Inner Join, Left Join, Full Outer Join, Cross Join절을 사용하여 다른 테이블과 조인하기
(8) Union, Intersect, Except를 통해 연산
아래 2~4 명령도 차차 올려보도록 하겠다.
2. Column aliases : 쿼리 내의 열, 표현식에 임시 이름을 지정
3. Order By : 쿼리에서 반환된 결과 집합을 정렬하기
4. Select Distinct : 결과 집합에서 중복행 제거하기
