CheckPoint Solution
INSERT INTO 문제
이번 문제는 users 라는 테이블에 있는 column 들에 원하는 값들을 채워주는 문제였다.
INSERT INTO users
VALUES('Dog', 'chasing cars', 64);그러나 이번 문제는 우리가 채워야 하는 values 가 4개. 특히 PRIMARY_KEY 항목은 무조건 채워줘야 한다. 우리가 빼먹었던 id 는 unique 한 속성이기 때문에 반드시 넣어주어야 하는 것.
INSERT INTO users(id, name, Hobby, Age)
VALUES(10, 'Dog', 'chasing cars', 64);나도 저렇게 요구하는 column 에 대한 데이터를 세 개만 넣었지, id 라는 Primary Key 를 넣지 않아서 오답을 받았었다. 왜 그런지 이제 알았다! 변명을 하자면 문제에서 저런 요구사항이 명시되어있지 않아서 틀리게 되었다!
INSERT INTO 와 Primary Key 에 대한 중요성을 알게 해 주는 문제였다
Schema of DataBase 와 관련한 문제
user 가 여러 개의 comment 를 가지는 관계라고 할 때, 유저가 여러 comment 를 가지는 관계를 만들기 위해서는 어떻게 처리해주어야 하는가?
물론 user 에 "HaveComment" 라는 column 을 만들고, 거기에 comment ID 를 넣어주면 괜찮겠지만(HaveComment 에 1, 4, 7, 10... 등등이 들어간 경우), 동아리 번호를 AESC/DESC 순으로 sort 하는게 쉽지가 않다.
다시 한 번 생각해보는 대원칙
- KEY 는 반드시 Unique 해야한다 (중복 및
NULL도 불가능하다) - 하나의 Attribute 는 하나의 값만을 가지고 있어야 한다
JOIN 과 관련한 문제 - INNER JOIN
그냥 JOIN 만 쓰게 되면 INNER JOIN 으로 기본적으로 인식한다.
Difference between JOIN and INNER JOIN
Help Desk 에서 물어본 것도 있고, 찾아보니까 이런 stackoverflow 의 질문글도 있었는데, 차이는 없지만 코드의 명시성을 확보하기 위해 "INNER" 라는 키워드를 명시한다고 한다.
그러나 나는 지금 처음 배우는 입장이기 때문에, INNER JOIN 과 같이 꼭 명시해주도록 하자!
They are functionally equivalent, but
INNER JOINcan be a bit clearer to read, especially if the query has other join types (i.e. LEFT or RIGHT or CROSS) included in it.
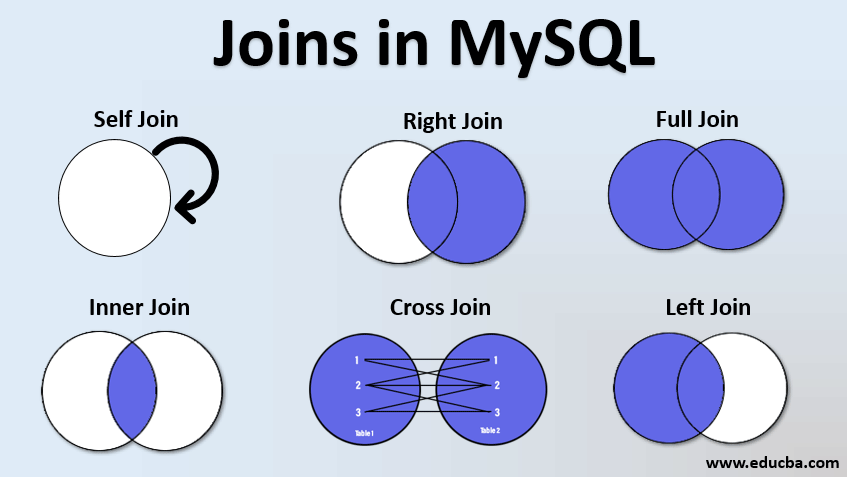
두고두고 봐야 할 것. JOIN 과 관련된 diagram.
추가 : Aliases 도 축약이 가능하다!
SELECT *
FROM users u JOIN pets p
ON u.id = p.owner_id위에 배운 Aliases 의 AS 키워드는 이런 식으로 축약해도 된다
SELECT *
FROM users AS u JOIN pets AS p
ON u.id = p.owner_idFM 대로 적는다면, 이런 식으로 AS 를 다 적어주어야 한다!
그리고 이렇게 만들어준 Aliases 의 scope(?) 는 해당 쿼리문 안에서만 유효하다. 축약으로 만들든, AS 를 명시해주든간에. 뭐든간에!
ALIAS문은 쿼리문중에서 가장 먼저 작동하게 됩니다.
작동시 치환을 시켜버리기 때문에 select문 첫 절에서 바로 접근이 가능한 것이며, 치환전에 대한 접근이 불가능한것입니다.
JOIN 과 관련한 문제 - LEFT / RIGHT JOIN
원하는 것만 한쪽으로 몰아서 가져간다는 건가요?
어떤 테이블을 기준으로 덧붙일거냐의 차이입니다.
join문을 기준으로 table좌측이 주가된다면 left join, table우측이 주가 된다면 right join이 됩니다.
Left : 왼쪽으로 몰아라, RIght : 오른쪽으로 몰아라 그냥 이런차이인거죠?
사람들이 해당 내용과 관련해서 질문한 것 중, 엔지니어분께서 "괜찮은 이해 방식이다" 라고 해 준 것들을 일단 싹 긁어왔다
LEFT JOIN 과 RIGHT JOIN
A RIGHT JOIN B === B LEFT JOIN A 이거는.... 조금 더 이해해서 내 것으로 만들어봐야겠다... 바로 와닿지 않는다.
SELECT p.Name, u.name
FROM users u
RIGHT JOIN pets p ON u.id = p.owner_idN : M 관계에서의 LEFT / RIGHT JOIN
여기서는 만들어 준 JOIN Table 을 통해 (favorite food) 엮어주는 방식이다
Learn MySQL
PART 3
.env 파일 활용하기
참조 문서 :
npm 에 있는 dotenv 라는 모듈을 사용하고, 나와있는 설명대로 사용한 걸 보았다. config 는 optional 한 기능이라 error handling 을 하는 용도로 사용하고, 아니면 말고 라고 한다.
왜 .env 가 .gitignore 에 존재하는가?
우리의 DB 계정 ID/PW 같은 사항이 git 에 올라가면 안 되기 때문이다.
An Introduction to Environment Variables and How to Use Them
사실상의 목적 : Decoupling configuration from the application
.env.example 파일은 왜 필요한가요?
환경세팅을 하는 사람들이 감을 잡고 .env 를 편하게 만들기 위한 skeleton 같은 느낌으로 존재하는것 같다.
DEFAULT 를 통한 기본값 할당, 그리고 CURRENT_TIMESTAMP() 함수
CREATE TABLE content (
id int NOT NULL AUTO_INCREMENTD,
title varchar(255) NOT NULL,
body varchar(255) NOT NULL,
created_at timestamp DEFAULT CURRENT_TIMESTAMP() NOT NULL,
userId int,
PRIMARY KEY (id),
FOREIGN KEY (userId) REFERENCES user(id)
);계속 막혔던 부분인데 해결했다. DEFAULT 키워드를 통해서 그 기본값으로 CURRENT_TIMESTAMP() 함수의 값을 ( () 로 실행하니, 값이 나온다) 할당해주어서 해결할 수 있었다.
PART 4
여태까지 했던 대부분의 statement 들을 활용해서 해결할 수 있는 문제들이었다
PART 5
AUTO INCREMENT 속성이 있는 column 은 무조건 PRIMARY KEY 로 unique 함을 보장해야한다.
There can be only one auto column
일단은 통과를 다 했다. 여러번의 JOIN 을 통해서 통과할 수 있었는데, 근처 개발자 분에게 물어보니 여러번 JOIN 요청을 날리면 DB 성능의 저하가 발생하여 최대한 그런 쿼리를 줄이는 게 좋다고 한다.
그리고 지금 내가 짠 쿼리문들을 다시 한 번 둘러봤는데 뭔가 마음에 안 드는 게 많아 일단은 다시 풀어보려고 한다. 오늘안에 그나마 해결이 되어서 리팩토링을 할 수 있는게 참 다행이다. 계속해서 안 되면 무작정 잡고있기보단 운동도 하고 밥도 먹고 씻고 다시 한 번 봐야 잘 된다는 사실을 알게 되었다(너무 길게 쉬고 오진 말고)
PART 6(?) - Refactoring
Aliases 의 활용으로 쿼리를 조금 더 명료하게 만들기
먼저 다시 내 쿼리들을 둘러봤을 때 가장 먼저 눈에 띄는 건, Aliases 를 전혀 적용하지 않았다는 점이다. 지금이야 그렇게 데이터베이스가 많지 않아서 손으로 일일히 치지 끌어와야 할 테이블이 많아진다거나 하면, 안 된다.
const PART5_2_6 = `
SELECT category.name
FROM user
INNER JOIN content ON user.roleId = content.userId
INNER JOIN content_category ON content.id = content_category.contentId
INNER JOIN category ON content_category.categoryId = category.id
`;일단 이런 쿼리문에서 content_category 등에 aliases 를 적용한다면 조금 편하지 않을까 싶다.
다시 W3School 의 MySQL - Aliases 문서 를 읽어보았고, 거기서 다시 한 번 개념을 잡았다.
SQL aliases are used to give a table, or a column in a table, a temporary name.
table 과 colum 에 임시로 이름을 부여할 수 있다고 한다. 그렇다는 이야기는 content_category 와 같은 table 과 categoryId 와 같은 colum 을 전부 간단하게 바꿔줄 수 있다는 이야기이다.
SELECT category.name
FROM user AS u
INNER JOIN content AS con
ON u.roleId = con.userId
INNER JOIN content_category AS con_cat
ON c.id = con_cat.contentId
INNER JOIN category ON con_cat.categoryId = con.id그래서 일단은 리팩토링을 해 봤지만, 올바르지 않은 문법이라 실패하였다. 예제를 보니 대부분 SELECT 부분에서 AS 를 걸어주던데, 그래서 구글링을 해 본 결과 글 하나를 찾게 되었다. 요약하자면 "An alias can be used in a query select list to give a column a different name. You can use the alias in GROUP BY, ORDER BY, or HAVING clauses to refer to the column", 다시 말 해 column 을 참조하는 aliases 는 GROUP BY, ORDER BY, 그리고 HAVING Clauses 에서만 사용가능하다는 이야기이다.
Using column alias in WHERE clause of MySQL query produces an error
MySQL :: MySQL 8.0 Reference Manual :: B.3.4.4 Problems with Column Aliases
위의 stackoverflow 문서에 들어가서 MySQL 공식문서를 참조한 결과 알 수 있게 되었다.
그 덕분에 내 원래 쿼리에서 column(예를 들자면 roleId 나 contentId )들에 aliases 를 사용할 수 없다는 결론을 내릴 수 있었다.
이 문서의 "Example - ALIAS a Table" 예시들도 참고해 보았다. 궁금증이 해결되었다.
When you create an alias on a table, it is either because you plan to list the same table name more than once in the FROM clause (ie: self join), or you want to shorten the table name to make the SQL statement shorter and easier to read.
FROM 에서만 해 줄 필요는 없다고 한다. 어디서든지 다 된다고 한다.
SELECT p.product_id, p.product_name, suppliers.supplier_name
FROM products p
INNER JOIN suppliers
ON p.supplier_id = suppliers.supplier_id
ORDER BY p.product_name ASC, suppliers.supplier_name DESC;SELECT p.product_id, p.product_name, s.supplier_name
FROM products p
INNER JOIN suppliers s
ON p.supplier_id = s.supplier_id
ORDER BY p.product_name ASC, s.supplier_name DESC;이렇게 INNER JOIN 이나 ON 에서도 잘 된다
const PART5_2_6 = `
SELECT user.name AS user, category.name
FROM user
LEFT JOIN content c
ON user.id = c.userId
LEFT JOIN content_category ON c.id = content_category.contentId
LEFT JOIN category ON content_category.categoryId = category.id
WHERE user.name = 'jiSungPark'
`;자꾸 깨져서 일단은 content 만 aliases 를 c 로 잡아봤는데, 잘 된다.
const PART5_2_6 = `
SELECT user.name AS user, cat.name
FROM user
LEFT JOIN content c
ON user.id = c.userId
LEFT JOIN content_category cc
ON c.id = cc.contentId
LEFT JOIN category cat
ON cc.categoryId = cat.id
WHERE user.name = 'jiSungPark'
`;이렇게 바꾸어 봤는데도 잘 되었다. 그래서 나머지 쿼리들도 aliases 를 이용해 조금 더 간단하게 했다.
const PART5_2_6 = `
SELECT user.name AS user, cat.name
FROM user
LEFT JOIN content c ON user.id = c.userId
LEFT JOIN content_category cc ON c.id = cc.contentId
LEFT JOIN category cat ON cc.categoryId = cat.id
WHERE user.name = 'jiSungPark'
`;이렇게 JOIN 이 들어가는 부분에서 붙여써도 똑같이 쿼리는 잘 날아가지만, 사람이 읽는다는 가정 하에는 위처럼 개행을 하는게 더욱 읽기가 쉬울 것 같다. 의미 기준으로 나눠지니까(내가 지금부터 aliases 기능을 이용해서 임시로 이름을 줄 것이다 라고 코드를 읽는 "사람에게" 명시하는 구간)
- 레퍼런스 코드를 봤는데
JOIN만 사용하고 있었다. 내가 지금 하는LEFT JOIN과 성능차이가 있을까? 궁금하다. 이거는 좀 물어봐야겠다.
나온 질문들
어떻게 해야 모든 테이블이 관계맺기 좋은 형태일까여?
위의 대원칙을 지키는 걸로부터 시작하낟. KEY 가 Unique 하고, 하나의 Attribute 에는 하나의 값만을 가지는 상황을 먼저 만들어주자. KEY 가 Unique 하지 않다면 Unique 하게 만들어주고, Attribute 가 중복이 된다면, Attribute 도 분류해주면 된다.
또한 N : M 의 관계와 1 : N 의 관계도 고려해야 한다.
추가로 대성님의 이야기, "모든테이블이 꼭 관계를 구성할 필요가 없습니다. 관계라는 필요에 의해 테이블을 나누어 구성하게 되는 것일 뿐입니다"
Schema & Query Design
Schema
DB에서 데이터가 구성되는 방식과 서로 다른 엔티티(entity) 간의 관계에 대한 설명, 다시 말 하자면 "DB의 청사진"
예시로 보는 Schema
수강신청 시스템을 만들어 본다고 가정할 때, 가장 먼저 "화면" 을 그려보자. 화면을 그린다는 이야기는, "데이터가 어떻게 표현되느냐" 를 그려본다는 이야기이다. 그렇다면, 우리는 이것을 그리기 이전에 해야 할 일이 또 하나 생긴다. 바로 "데이터란 무엇인가" 에 대해 정의하는 것이다.
그림으로 그려보기 + 용어 정리
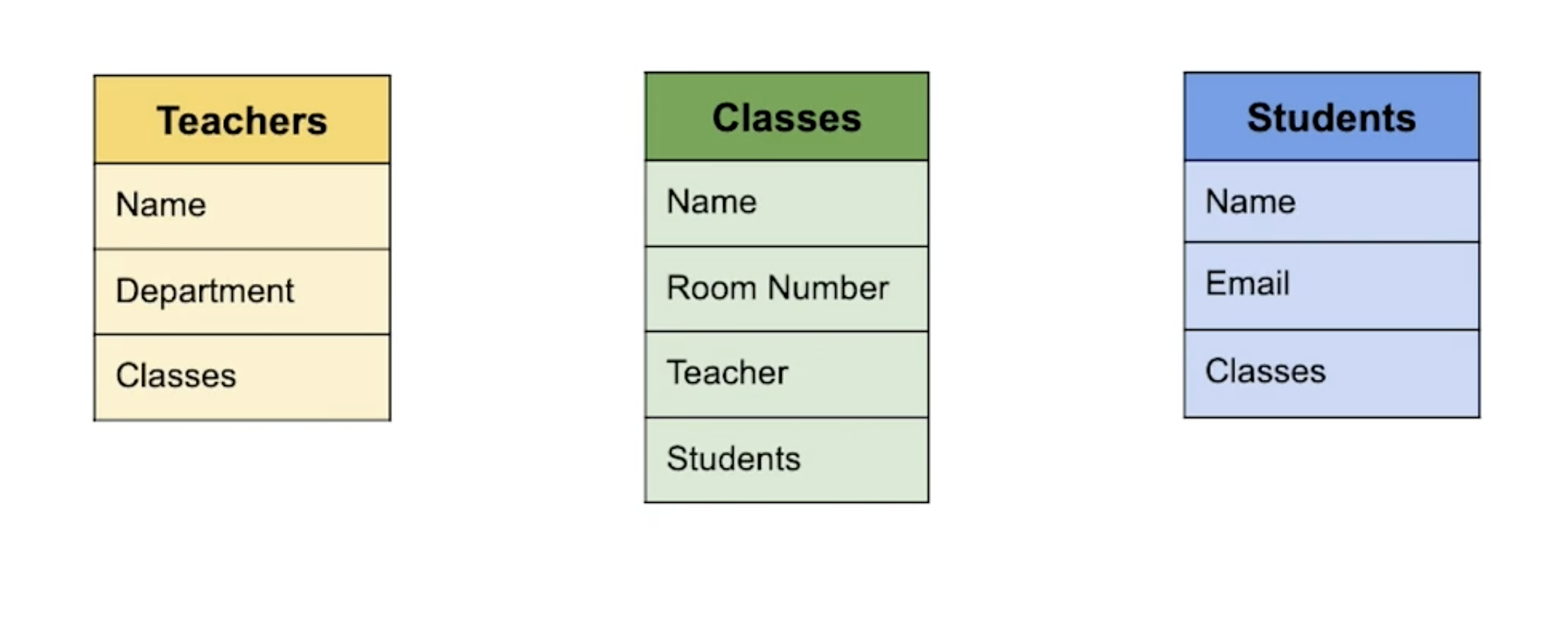
이런 식으로 도식화 할 수 있을 듯 하다. 위에서 말 한 과정들을 다시 시작하기 전에 여기서 위에 나온 용어들("DB에서 데이터가 구성되는 방식과 서로 다른 엔티티(entity) 간의 관계에 대한 설명") 을 짚고 넘어가보자.
Entity
고유한 정보의 단위. 여기서는 Teachers, Classes, Students 가 entity 로서 존재한다. Entity 는 DB에서 Table 의 개념으로 표시된다.
Field
각 Entity 의 특성을 설명하는 단위.Teacher 라는 entity 안에는 Name, Department, Classes 라는 Field 가 존재한다. DB에서는 table 안의 column 에 해당된다.
Record
Table 에 저장된 각 항목들. 예를 들어 Teacher 라는 entity 안에 Name 라는 field 값이 John, Department 라는 field 값이 Computer Science, 그리고 Classes 라는 field 값이 OOP 라는 일련의 정보들을 의미한다.
데이터간의 관계에 대해서
1 : N
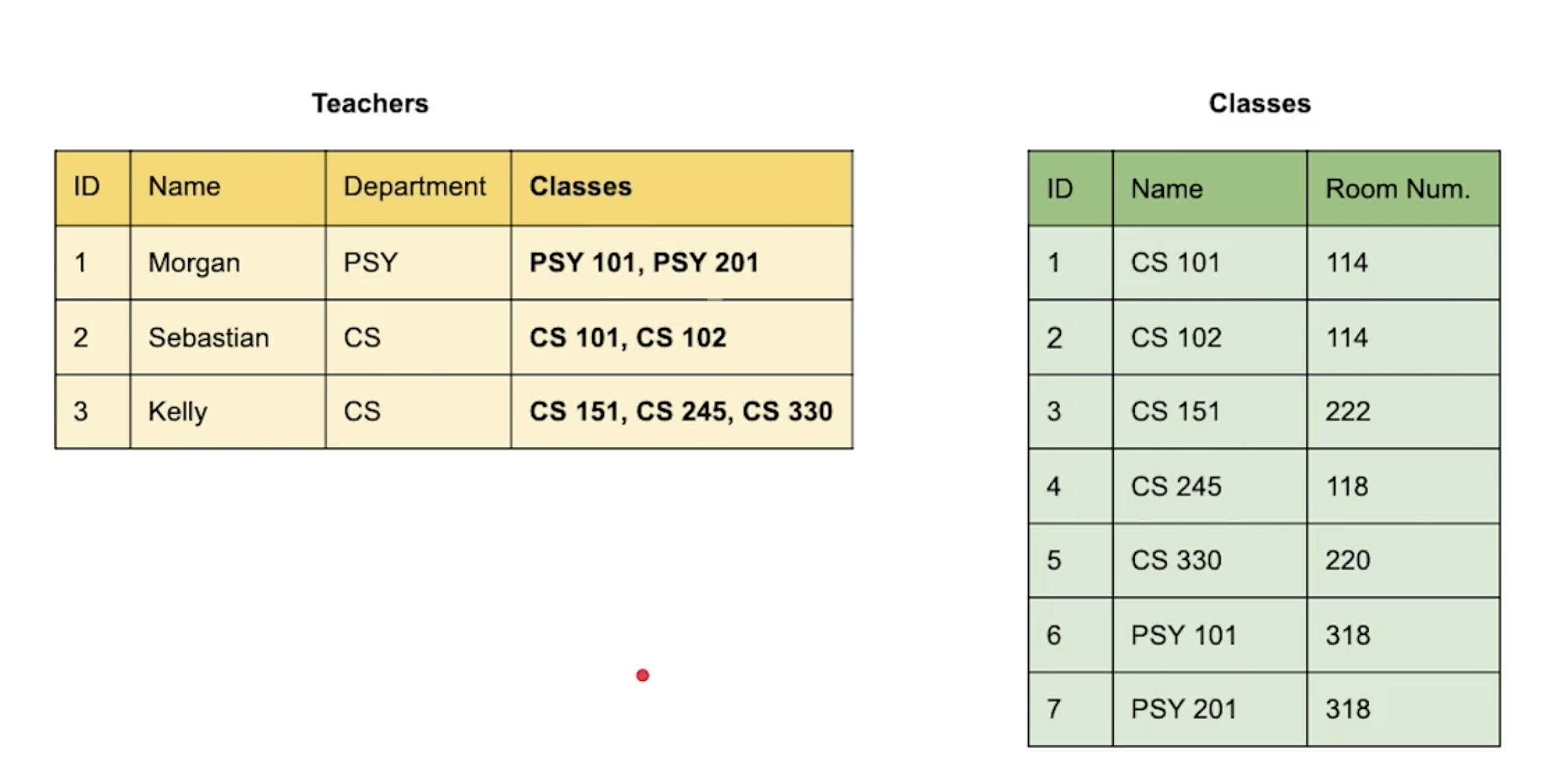
Teachers 와 Classes 간의 관계를 한 문장으로 표현한다면, 어떻게 할 수 있을까? "선생님이 수업을 한다" 라고 간단하게 생각해보는 것을 시작으로, "갯수" 라는 개념을 추가해보자. 일반적인 경우를 생각해서. 한 교수님(Teacher) 이 여러 강의(Classes) 를 가르치는 경우가 일반적이다. 우리는 이 경우를 1 : N 의 관계라고 한다.
위 그림에서는 한 선생님이 여러 개의 수업을 하기 때문에, Teachers 라는 entity 에 Classes 라는 field 를 새로 만들어 참조시켰다.
그런데 이 경우 생길 수 있는 문제들도 한 번 생각해보자. 먼저, CS 101 이라는 수업의 이름이 바뀌는 경우, DB는 어떻게 업데이트 되어야 하는가? 그렇게 된다면, 모든 Teachers entity 의 Classes 라는 field 들을 전부 뒤진 뒤 있는 경우 바꿔주고 없는 경우 넘어가는... 그런 복잡한 과정들을 거쳐야 한다. 이렇게 된다면, 조금 비효율적이다.
물론 Classes 의 Name 이 아니라, ID 를 참조하면 조금 더 연산에 걸리는 부하 자체는 조금 더 줄어들 수도 있다. 그러나, 그렇게 해도 위에 나온 것처럼 여러 번의 연산을 거쳐야 한다는 사실은 변하지 않는다. 그리고 본질적인 문제가 있다. Class 라는 field 의 용량 제한이 있을 수 있기에 무한한 값을 넣을 수 없으며, 검색도 오래 걸린다. 한 명의 교사에서 학생을 검색하기 위해 교사의 Classes 라는 열의 값을 다 반복해야 할 것이다.
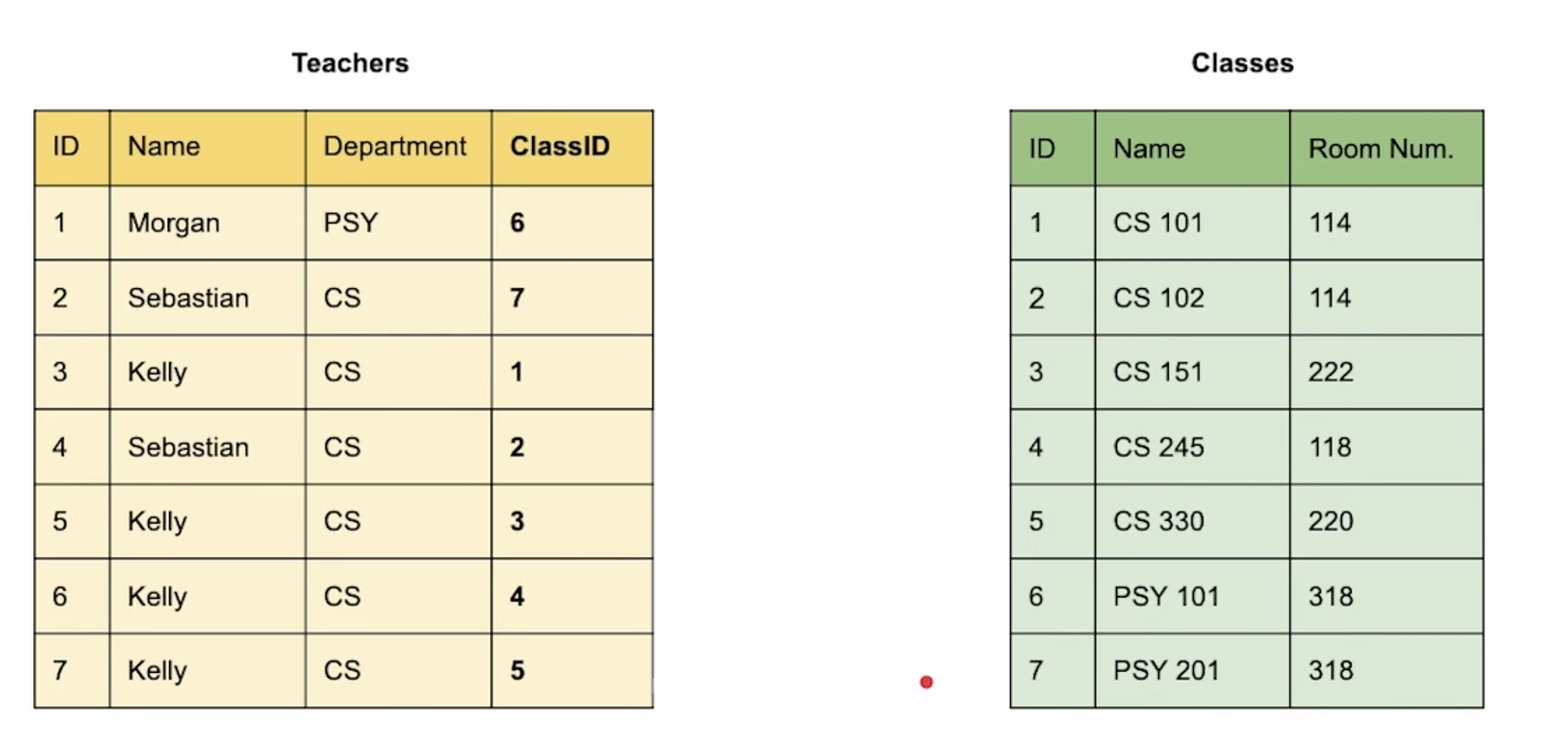
이렇게 만든다면 어떨까? 그냥 수업마다 하나씩 Record 를 만들어 준다면? 물론 이렇게 해도 문제가 생긴다. 만약 Name 이 Kelly 인 records 들의 Name 을 전부 다른 값으로 바꿔줘야 한다면? 만약 그 과정이 잘 실행이 안 되었을 때 한두개쯤 Kelly 라는 이전 값의 상태가 남아있다면? DB 가 꼬여버릴 수도 있다. 즉, 정합성을 보장할 수 없는 상황이 벌어질 수 있다.
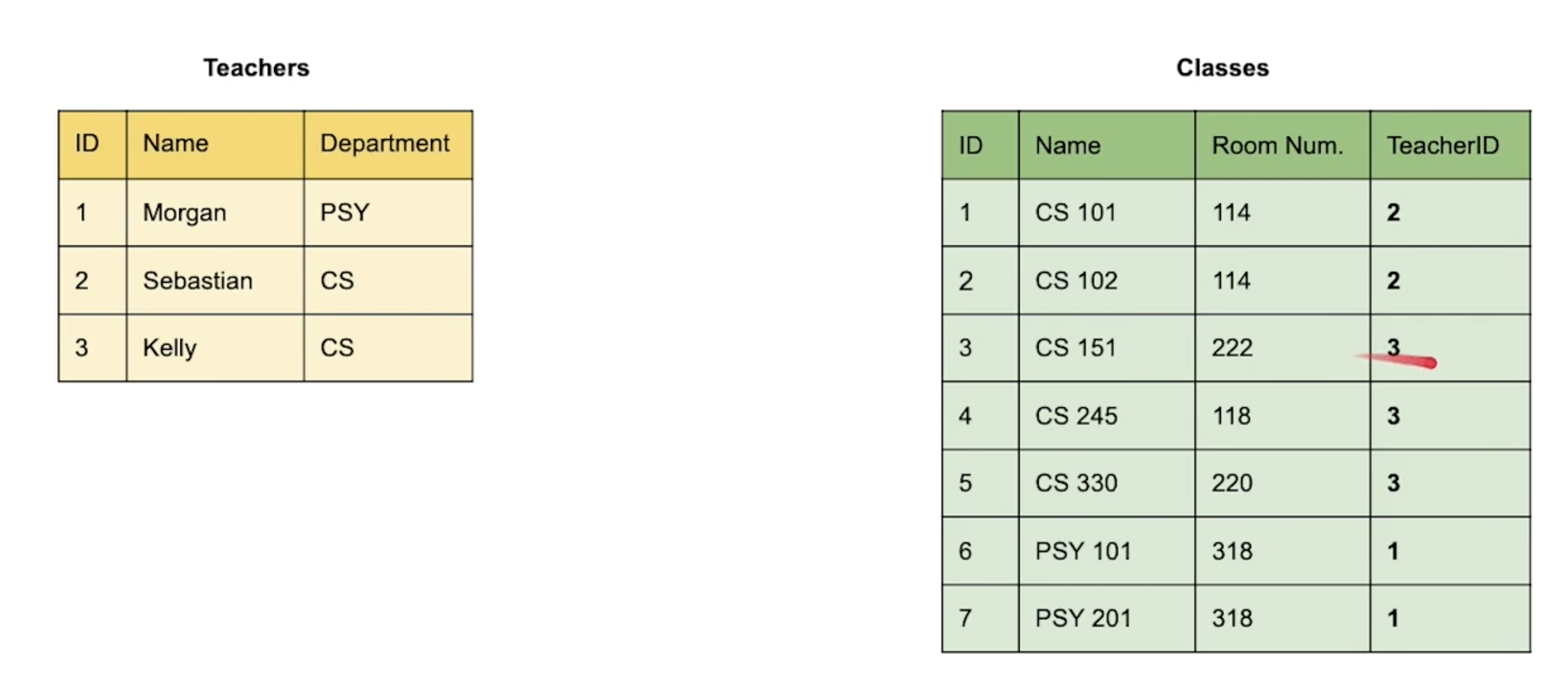
가장 좋은 시도(The Best Practice) 이렇게 Classes Entity 에 Teacher ID 를 추가해서 참조하는 방식이다. 위에서도 말했듯이 "하나의" 선생이 "여러개의" 수업을 가르치는 상황이기 때문에 중복되는 Records 들도 만들어지지 않아서 정합성도 보장할 수 있고, TeacherID 라는 참조하는 Column 의 용량 제한 문제도 해결할 수 있다.
N : M
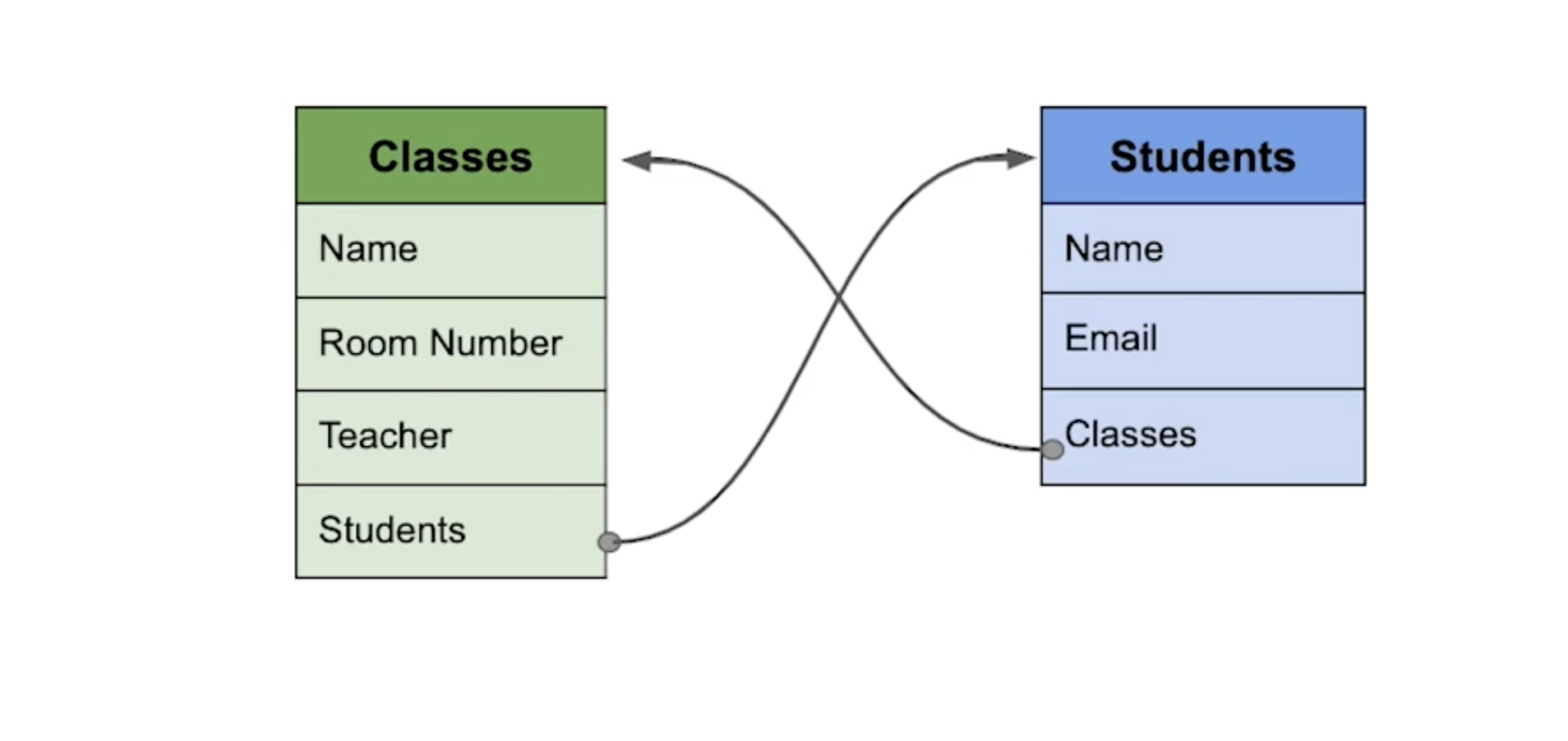
이번엔 "학생이 수업을 듣는" 과정을 DB로 만들면 어떻게 할 수 있을지를 고민해보자. 위에서도 일반적인 경우를 상정했듯이 이번에도 일반적인 경우를 상정해보자. "하나의 학생" 은 "여러개의 수업" 을 들을 수 있다. 거꾸로, "하나의 수업" 도 "여러명의 학생" 들이 들을 수 있다. 즉, 저 두 Entity 의 관계는 N : M (다대 다) 의 관계인 것이다.
이런 경우는 어떻게 하는 게 가장 좋은 시도일까? 일대 다의 상황이 아니기 때문에 각 테이블에 하나의 column 을 만들어 서로를 참조하게 하는, 일대 다 관계에서 사용하던 기존의 방식은 더 이상 합리적이지 않다.
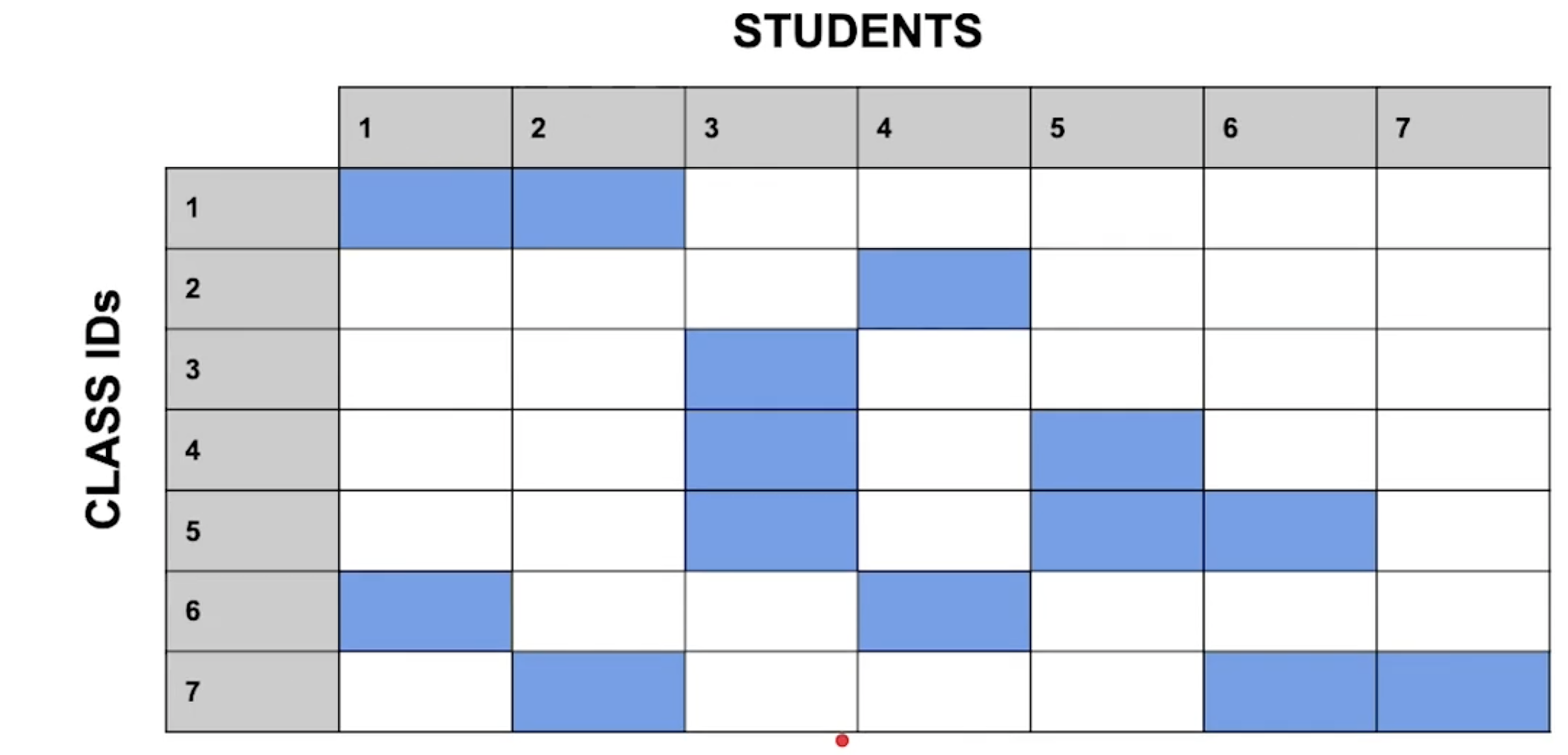
조금 더 보기 편하게 좌표계처럼 이렇게 만들어보았다. (1, 1), (1, 2), (2, 4)... 등으로 표현할 수 있다. 그리고 방금 적은 "유효한 좌표" 들을 모은 entity 를 또 하나 만들어서, 중간에 끼워넣어 보자.
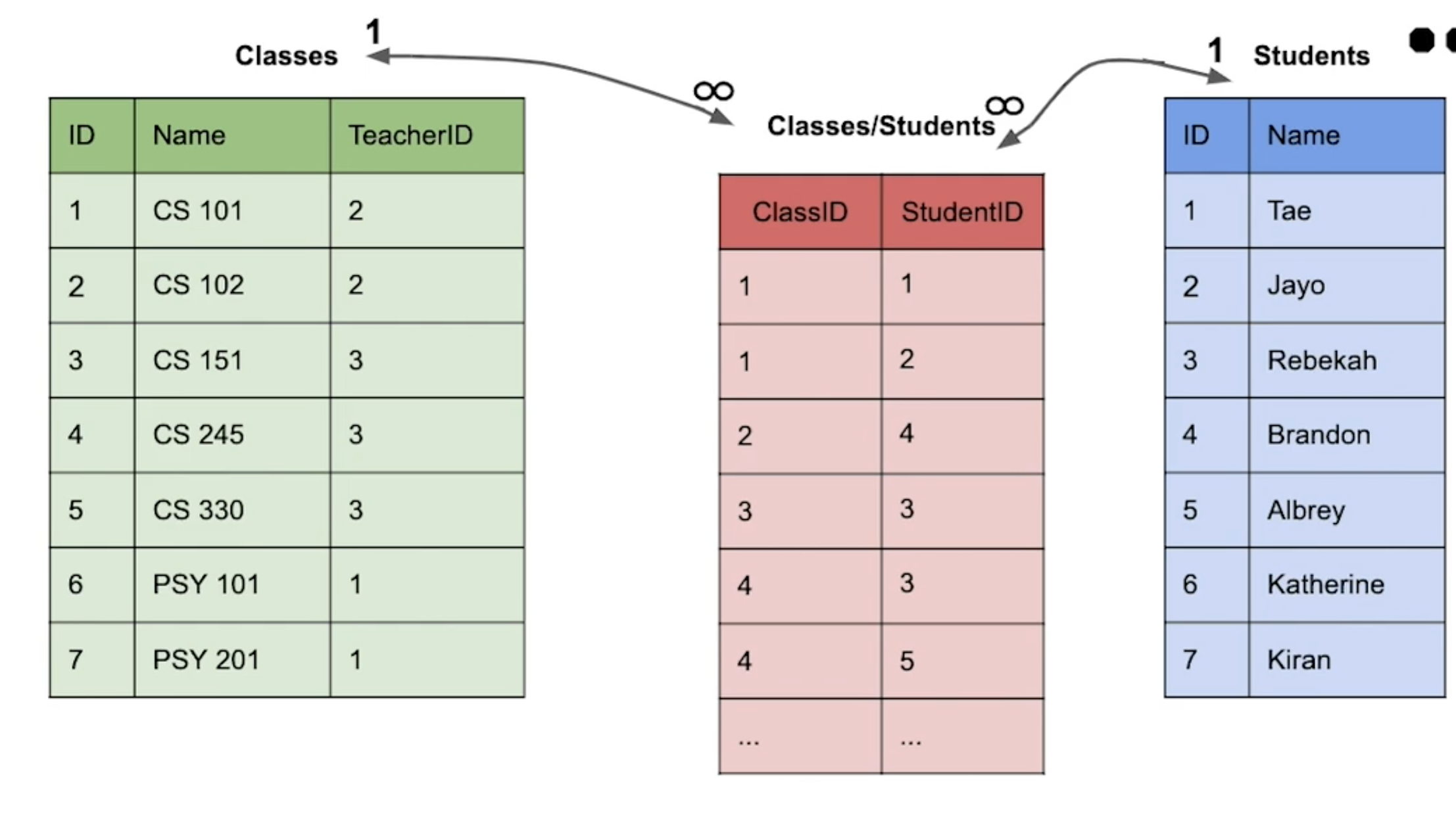
그렇게 되면 우리는 다대 다의 관계를 일대 다를 두 번 반복하는 방식으로 치환할 수 있다. 저 사이에 있는, 다대 다 간의 참조를 용이하게 만드는 저 테이블을 JOIN TABLE 이라고 한다.
요약하자면
- 일대 다의 경우 : "다" 에서 "일" 을 참조하는 관계
- 다대 다의 경우 : JOIN TABLE 을 통해, 일대 다를 두 번 하는 과정으로 치환시키기
DB 정규화와 DB 비정규화 관련해서도 검색해봤는데 아직 뭔가 와닿진 않는 내용이다. 그러나 효율적인 DB 운용을 위해서는 필수적인 역량이라는 생각이 들었다.
JOIN 과 관련해서는 이제 어떻게 쓰는지 감이 잡혔다. 오늘 스프린트로 여러가지 시도를 참 많이 해 본 덕분에 가능한 일이었다.
