
1. 개념 정리
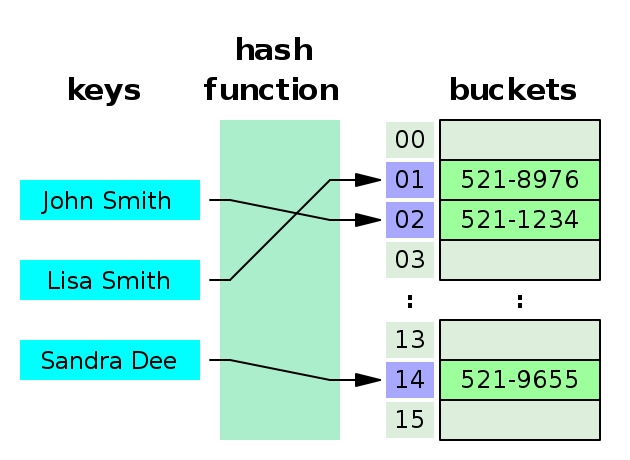
1.1 해시 테이블(Hash Table)
키(Key), 값(Value)으로 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조이다. 해시 테이블은 각각의 키(Key) 값에 해시함수(Hash Function)를 적용해 배열의 고유한 인덱스를 생성하고, 이를 활용해 값을 저장하거나 검색하게 된다.
그렇기 때문에 키(Key) 값으로 값(Value)을 찾을 때 해시 함수를 1번만 수행하면 되기 때문에 평균적으로
O(1)의 사긴 복잡도로 삽입/삭제/조회를 할 수 있다.
2. 문제 설명
2.1 전화번호 목록
전화번호부에 적힌 전화번호 중, 한 번호가 다른 번호의 접두어인 경우가 있는지 확인하려 합니다.
전화번호가 다음과 같을 경우, 구조대 전화번호는 영석이의 전화번호의 접두사입니다.
- 구조대 : 119
- 박준영 : 97 674 223
- 지영석 : 11 9552 4421
전화번호부에 적힌 전화번호를 담은 배열 phone_book 이 solution 함수의 매개변수로 주어질 때, 어떤 번호가 다른 번호의 접두어인 경우가 있으면 false를 그렇지 않으면 true를 return 하도록 solution 함수를 작성해주세요.
2.2 제한 조건
- phone_book의 길이는 1 이상 1,000,000 이하입니다.
- 각 전화번호의 길이는 1 이상 20 이하입니다.
- 같은 전화번호가 중복해서 들어있지 않습니다.
2.3 입출력 예시
| phone_book | return |
|---|---|
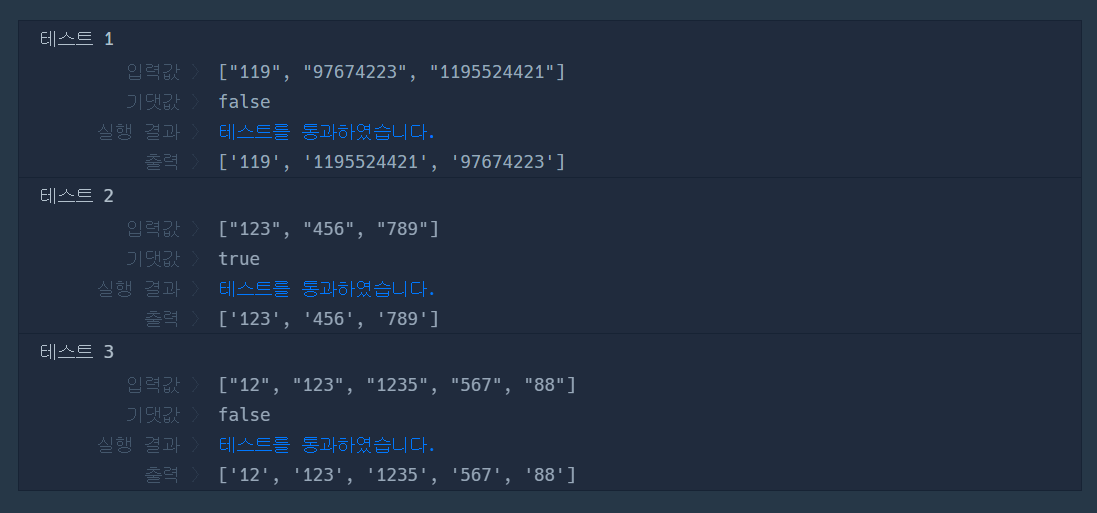
| ["119", "97674223", "1195524421"] | false |
| ["123","456","789"] | true |
| ["12","123","1235","567","88"] | false |
3. 풀이 과정
중복이 없는 전화번호들 중 어떤 하나라도 다른 번호의 접두사가 되는 것이 있는지 찾는 문제이다. 문제 자체는 어렵지 않은 문제이지만, 제한 조건 때문에 시간 초과가 날 수 있는 문제이므로 주의해서 풀어야 한다.
3.1 반복문 중첩 : 실패😂
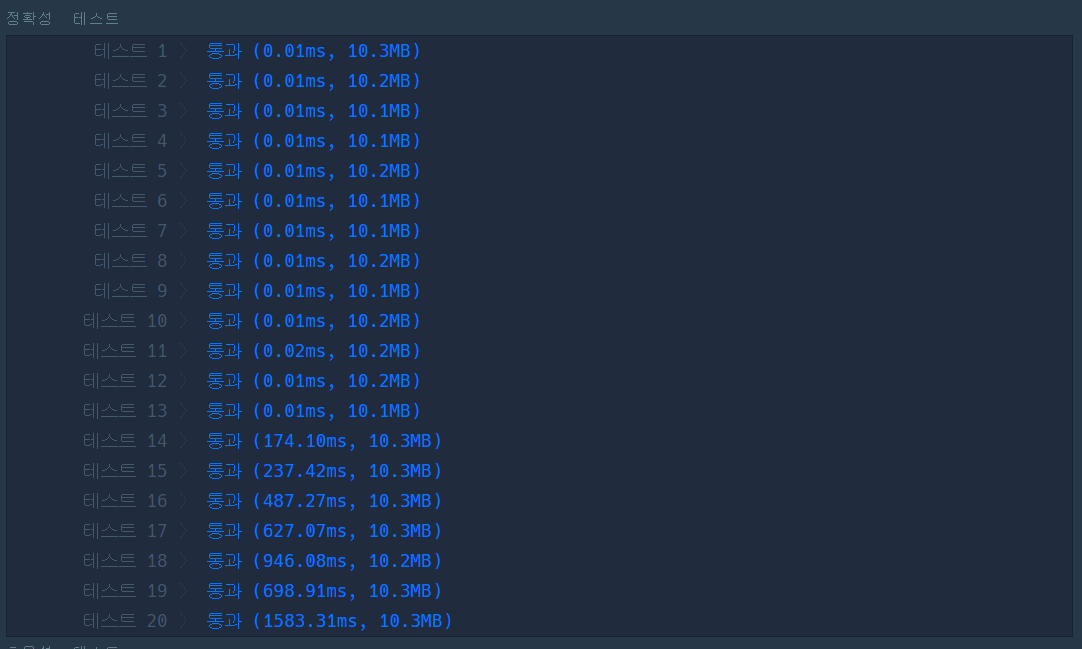
가장 간단하게 생각할 방법이다. 시간 초과가 날 것이라 예상했고 실제로도 시간 초과가 났다. 하지만 3.2의 문제 해결 방법이 생각나지 않아서 한 번 시도해본 풀이 방식이다.
풀이 과정은 간단하다. 반복문을 중첩해서 돌려서 phone_book[i]와 phone_book[i+1:]을 비교해서 2개의 번호 중 더 짧은 길이를 기준으로 인덱싱을 해서 두 문자열이 일치하는지 판별해서 접두사가 되는지를 파악하는 방식이다.
- 전체 코드 (python)
def solution(phone_book):
for i, phone_1 in enumerate(phone_book):
for j, phone_2 in enumerate(phone_book[i+1:]):
length = min(len(phone_1), len(phone_2))
if phone_1[:length] == phone_2[:length]:
return False
return True- 실행 결과

3.2 정렬 : 성공😋
위에서 O(n*n)은 시간 초과가 날 수밖에 없고, 주어진 제한 조건은 n = 1,000,000 이하이니 O(nlogn) 이하로 푸는 방법을 생각하다 정렬을 떠올리게 되었다. 해시 문제이긴 하지만 해시로 사용하는 방법이 떠오르지 않아서 시도해본 방법이다.
정렬을 사용할 때 가장 중요한 포인트는 앞, 뒤 전화번호만 확인하면 된다는 것이다. 정렬된 상태이기 때문에 바로 뒤의 전화번호가 앞 전화번호를 접두사로 가지고 있지 않는다면 그 이후도 가질 수 없기 때문이다. 그렇기 때문에 phone_book[i]와 phone_book[i+1]을 비교해서 접두사이면 return을 해주고 그렇지 않을 경우 계속 반복문을 돌면 된다. 아래 정렬한 모습을 보고 왜 그렇게 되는지 생각해보면 좋을 것 같다.
3.2.1 인덱싱 활용
- 전체 코드 (python)
def solution(phone_book):
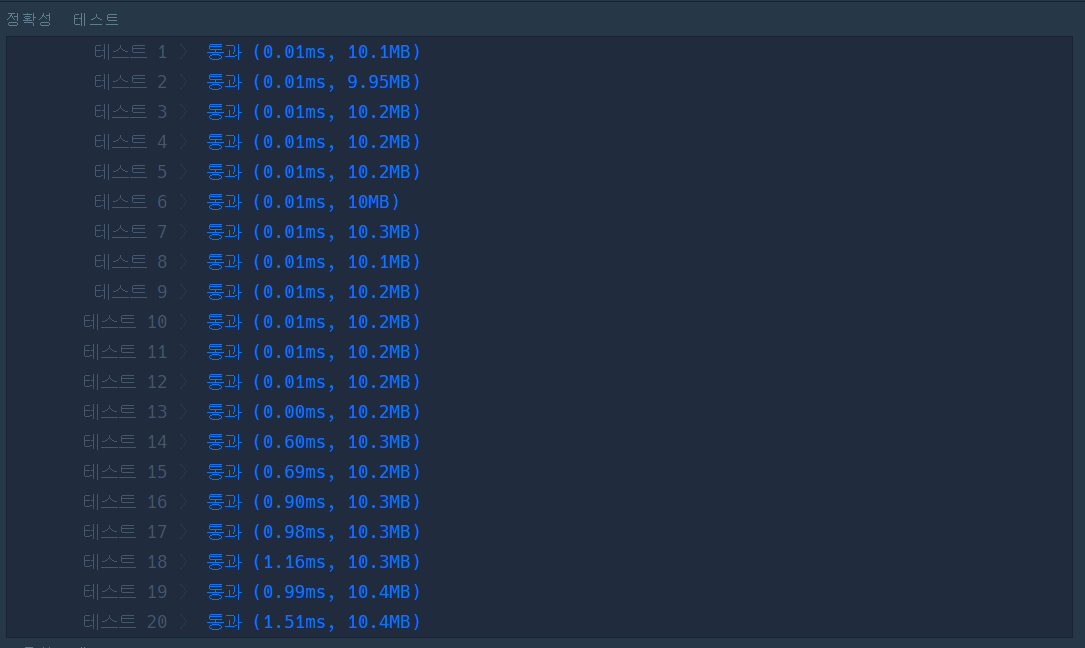
phone_book.sort()
for i, phone in enumerate(phone_book[:-1]):
if phone == phone_book[i+1][:len(phone)]:
return False
return True- 실행 결과

3.2.2 startswith 활용
위와 동일한 알고리즘이지만 문자열이 접두사인지 비교할 때 인덱싱이 아닌 startswith를 활용하여 풀어보았다. 다른 사람 풀이에서 사용되는 방식이라 효율성 비교 겸 사용해보았다.
실제 비교해보니 크게 시간 차이가 나지는 않지만, n이 많으면 startswith가 인덱싱보다 시간이 더 많이 나오는 것을 알 수 있었다.
str.startswith(str, beg=0,end=len(string));문자열이 특정 문자로 시작하는지를 True or False로 반환해준다.
- 전체 코드 (python)
def solution(phone_book):
phone_book.sort()
for i, phone in enumerate(phone_book[:-1]):
if phone_book[i+1].startswith(phone):
return False
return True- 실행 결과
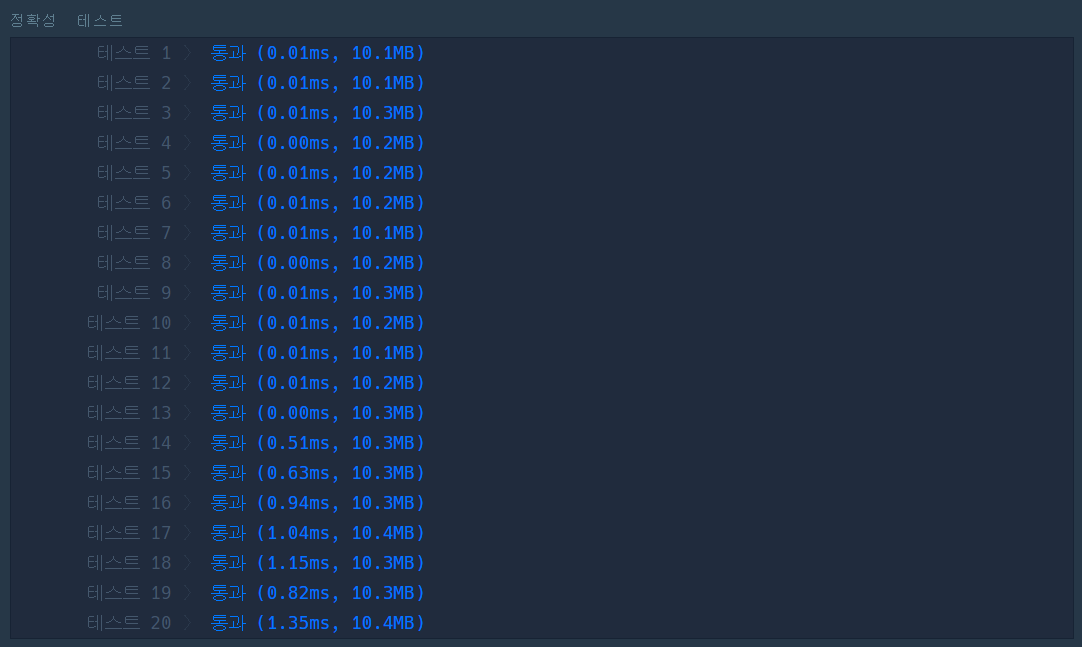

3.3 해시 : 성공😋
직접 생각해 낸 방식은 아니고, 다른 사람들의 풀이를 보면서 조금 변형해본 코드이다. 개념적으로는 해시를 이해하고 있지만, 실제 문제에 적용하는 방식을 떠올리는 것은 아직은 조금 어려운 것 같다. 실제 문제를 많이 풀어보면서 익혀나가야 할 것 같다. 해시를 사용한 풀이 과정은 다음과 같다.
phone_book을 사전으로 변환한다. (파이썬에서는 사전으로 해시를 구현할 수 있다.)
phone_book을 순회한다.
phone을 순회하면서 해당 숫자를temp에 덧붙인다.temp가hash_map에 포함되어있으며,temp != phone이면False를 반환한다.- 위에서 반환되지 않았다면 접두어가 없는 것이니
True를 반환한다.
기본적으로 알고리즘 자체는 리스트에도 적용할 수 있는 부분이라서 리스트와 해시 탐색의 시간 복잡도를 비교해보기 위해 두 가지 방식 모두 시도해보았다.
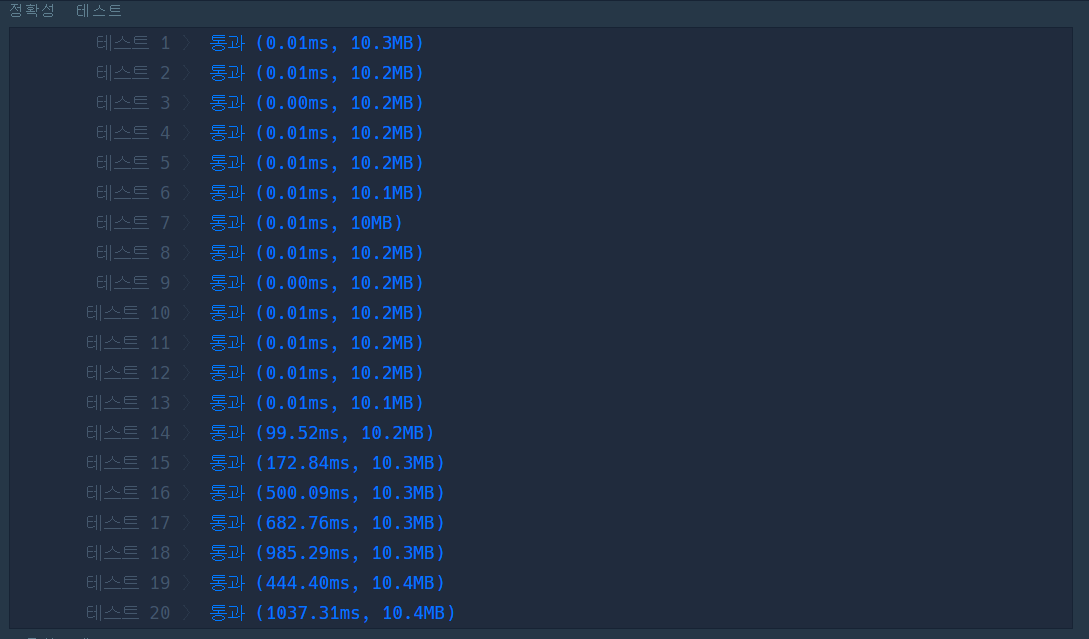
3.3.1 리스트 활용
리스트를 활용한 방식의 경우는 시간 초과가 나는 모습을 볼 수 있었다. 탐색 시간이 O(n)이 걸리기 때문에 결과적으로는 O(n*n)이 되기 때문이다.
- 전체 코드 (python)
def solution(phone_book):
for phone in phone_book:
temp = ""
for number in phone:
temp += number
if temp in phone_book and temp != phone:
return False
return True- 실행 결과

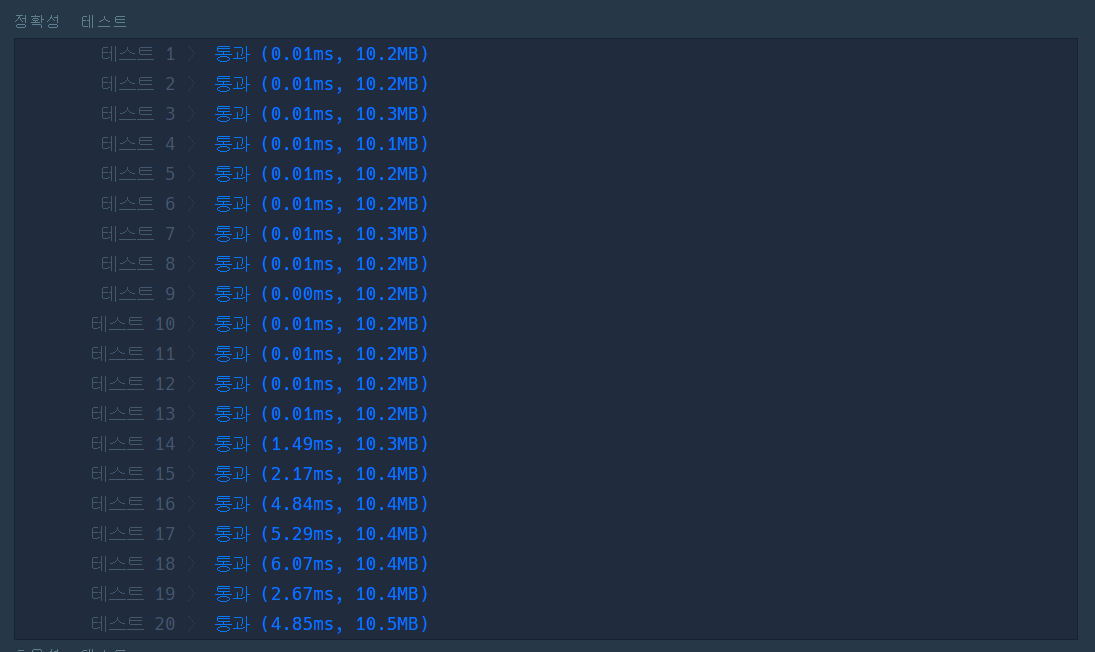
3.3.2 해시 활용
위의 알고리즘과 동일하지만 시간 초과 없이 문제를 해결할 수 있었다. 해시의 경우 탐색의 시간 복잡도가 O(1)이기 때문에 두 번째 for문의 문자열의 길이 제한이 20인 것까지 고려하면 대략 O(20n) => O(n)의 시간 복잡도를 가진다. 하지만 실제 실행 시간을 비교했을 때 3.2의 정렬을 활용한 방식보다 시간이 더 걸리는 것을 볼 수 있었다. ( O(nlogn) < O(20n) 이었거나 해시에서는 문자열 연결이 있어 더 걸렸을 수도 있겠다고 추측해보았다.)
- 전체 코드 (python)
def solution(phone_book):
hash_map = dict.fromkeys(phone_book, 0) # 리스트 -> 사전
for phone in phone_book:
temp = ""
for number in phone:
temp += number
if temp in hash_map and temp != phone:
return False
return True- 실행 결과

4. 핵심 정리
4.1 🔥 최종 풀이 🔥
결과적으로는 정렬 + 인덱싱을 사용한 풀이가 가장 효율성이 좋아서 최종 풀이로 결정하게 되었다.
def solution(phone_book):
phone_book.sort()
for i, phone in enumerate(phone_book[:-1]):
if phone == phone_book[i+1][:len(phone)]:
return False
return True4.2 핵심 포인트
- 제한 조건에 따라 시간 초과 고려하기
- 문자열 정렬은 숫자 정렬과 다름
- 리스트 탐색
O(n)vs 해시 탐색O(1)
4.3 주요 라이브러리
4.4 참고 링크
