
" 상관관계 "
상관관계
상관관계
두 변수 간에 함께 변하는 정도의 강도와 방향을 나타내는 개념
- 두 변수가 서로 어떤 관계를 가지는지를 수치적으로 표현
- 일반적으로 상관계수(correlation coefficient)로 표현
- 양적 변수끼리만 계산 가능
- 범주형 변수에는 적용 불가능
- 해결 : 교차표, 카이제곱 검정, 평균 차이 검정 등
- 상관관계는 인과관계를 의미하지는 않음
상관계수
- 관계의 방향(+ / -)과 강도(약 / 중 / 강)를 알려줌
- 필요성 : 산점도의 패턴을 숫자 하나로 요약하여 해석이 용이함
- 산점도는 사람마다 해석이 다를 수 있고 데이터 수가 많으면 해석이 어려움
- 값의 범위 : -1 ~ +1
- +1 : 완벽한 양(+)의 상관관계
- 한 변수가 증가하면 다른 변수도 일정하게 증가
- ex ) 공부한 시간 ↑ :: 시험 점수 ↑
- 0 : 상관관계 없음
- 두 변수는 선형적 관계가 없음
- ex ) 신발 사이즈 :: 국어 시험 점수
- -1 : 완벽한 음(-)의 상관관계
- 한 변수가 증가하면 다른 변수는 일정하게 감소
- ex ) 운동량 ↑ :: 체지방률 ↓
fig = plt.figure(figsize=(8,6), facecolor='k')
ax= fig.add_subplot()
ax.patch.set_facecolor('k')
sns.heatmap(corr_numeric, annot=True, cmap="Blues")
ax.tick_params(colors='w')
ax.spines['bottom'].set_color('w')
ax.spines['left'].set_color('w')
plt.show()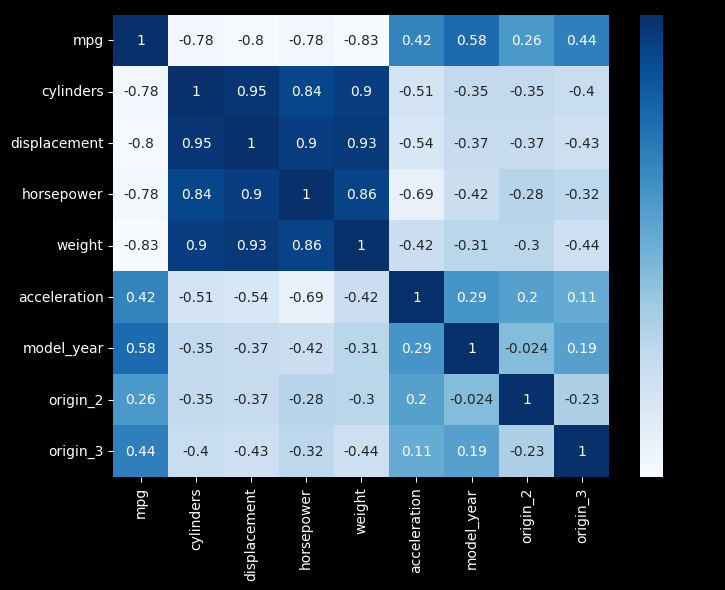
산점도
- 두 변수의 값을 각각 x축과 y축에 점으로 표시한 그래프
- 필요성 : 숫자는 왜곡될 수 있지만, 그림은 직관적으로 관계를 보여줌
- 양의 상관관계
- 점들이 ↗️ 오른쪽 위 방향으로 퍼져 있음
→ x 값이 커질수록 y 값도 커지는 경향
- 점들이 ↗️ 오른쪽 위 방향으로 퍼져 있음
- 상관관계 없음
- 점들이 흩뿌려져 특정한 패턴이 없음
- 음의 상관관계
- 점들이 ↘️ 오른쪽 아래 방향으로 퍼져 있음
→ x 값이 커질수록 y 값은 작아지는 경향
- 점들이 ↘️ 오른쪽 아래 방향으로 퍼져 있음
- 양의 상관관계
상관계수와 산점도 모두 표현 필요
" 상관계수 "
피어슨 상관계수
공분산
- 두 확률변수가 함께 변하는 정도를 나타내는 값
- 하나의 변수가 평균보다 클 때 다른 변수도 평균보다 큰 경향이 있는지, 아니면 반대인지를 수치로 표현
- 계산
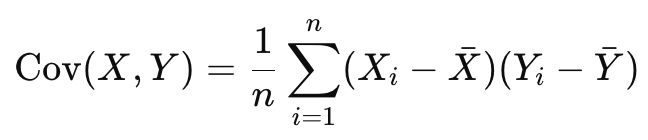
- 해석
- Cov(X, Y) > 0 → 양의 공분산
- X가 평균보다 클 때 Y도 평균보다 큰 경향 (같이 움직임)
- Cov(X, Y) ≈ 0 → 두 변수 사이에 선형적 관계가 거의 없음
- Cov(X, Y) < 0 → 음의 공분산
- X가 평균보다 클 때 Y는 평균보다 작은 경향 (반대로 움직임)
- Cov(X, Y) > 0 → 양의 공분산
피어슨 상관계수
- 공분산은 단위의 영향을 받아 값의 크기만으로 비교가 어려움
- 공분산을 표준화한 값이 바로 상관계수(r)
- 계산
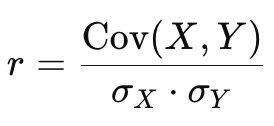
- 해석
- | r | < 0.3 → 약한 상관관계
- 0.3 ≤ | r | < 0.7 → 중간 상관관계
- | r | ≥ 0.7 → 강한 상관관계
- r = 0 → 두 변수는 관계가 전혀 없음 X
- 선형관계가 없을 뿐, 곡선 관계는 가능
- 이상치에 민감
- 평균과 분산 기반으로 계산하기 때문
- 실제 값 기반 → 선형 관계 측정
스피어만 상관계수
스피어만 상관계수
- 순위 기반 → 값이 아니라 순서만 반영
- 계산

- 해석
- p = +1 : 순위가 완벽히 일치 (X ↑ → Y ↑)
- p = 0 : 순위 간에 특별한 패턴 없음
- p = -1 : 순위가 완벽히 반대 (X ↑ → Y ↓)
- 이상치에 덜 민감
- 곡선(비선형)관계도 잡아낼 수 있음
" 상관계수와 가설검정 "
가설검정의 이유
- 상관계수 값이 단순히 우연(표본의 무작위성) 때문인지 아닌지를 확인하기 위해
가설 설정
- 귀무가설(H0) : 모집단에서 상관이 없다 (상관계수=0)
- 귀무가설(H1) : 모집단에서 상관이 있다 (상관계수!=0)
판정 기준
- p < α : 우연이라고 보기 어려움 → 유의한 상관
- p ≥ α : 우연일 수 있음 → 단정할 수 없음
신뢰구간이 0 포함
- 상관계수의 신뢰구간(CI)은 모집단의 상관계수가 있을 수 있는 값의 범위를 제시
- 신뢰구간이 0을 포함
- 항상 p-value ≥ α
- “모집단에서 실제 상관계수가 0일 가능성도 배제할 수 없다”
- 통계적으로 유의한 상관관계가 있다고 말할 수 없다
" 데이터 분석에서의 상관관계 "
주의할 점
EDA 도구
- 데이터 분석에서 상관관계는 EDA 도구일 뿐
- 예측, 인과 추론을 위한 단독 근거로는 부적절함
- 보고서에는 반드시 산점도 + 상관계수 + 해석 포함
- 산점도 → 상관계수 → 해석
- ex ) 광고비와 매출은 r=0.65로 중간 정도 양의 상관관계를 보이며 이것이 인과관계를 의미하지는 않음
적절한 상관계수 활용
- 피어슨 상관계수 : 연속형 변수만 가능, 선형 관계
- 스피어만 상관계수 : 순위형 변수도 가능, 단조 관계
- 비선형 관계(곡선)도 가능
상관계수 해석 기준
- 연구 분야 & 데이터 특성에 따라 해석이 달라짐
- 분석에 따른 맥락 해석 필요
- 의학/생명과학 : 복잡한 요인들이 많아 r = 0.2~0.3도 중요한 상관으로 해석될 수 있음
" 인과관계 "
인과관계
변수 A의 변화가 변수 B의 변화를 직접적으로 일으킨다는 관계
- 즉 A가 원인, B가 결과
상관관계 != 인과관계
- 상관이 있다고 해서 원인이라 단정하지 않는다
- ex ) 아이스크림 판매량 ↑ <-> 익사 사고 ↑
- 원인은 아이스크림이 아니라 여름 더위
- ex ) 아이스크림 판매량 ↑ <-> 익사 사고 ↑
- 항상 우연 or 교란 변수 존재 가능성을 의심해야 함
- 광고비와 매출 사이의 상관 발견
- 프로모션, 계절 요인, 경제 상황 같은 교란 변수 가능
- 광고비와 매출 사이의 상관 발견
교란변수
- A와 B 모두에 영향을 주면서, 실제 인과관계를 왜곡시키는 숨은 변수
- A와 B 사이의 경로에 개입해 “마치 인과처럼 보이게” 만드는 요인
교란변수의 문제점
- 가짜 상관(spurious correlation) 발생
- 실제 효과를 과대평가하거나 과소평가할 수 있음
- 잘못된 의사결정을 유도할 수 있음
- ex ) "커피를 마시는 사람일수록 폐암 위험이 높다”
- 사실은 흡연자가 커피를 더 많이 마시기 때문에 발생한 교란
교란변수 다루는 법
- 실험적 접근 (가장 확실)
- 무작위 통제 실험(RCT)으로 교란변수를 무작위화
- 통계적 접근
- 회귀분석에서 교란변수를 통제 변수(control variable)로 포함
무작위 통제 실험(RCT)
- 두 집단을 비교할 때 필요한 조건
- 원인만 다르고 나머지는 똑같아야 한다
- 구조
- 무작위 배정(Randomization)
- 교란변수가 두 집단에 골고루 분배되도록 하여 편향 최소화
- 처치(Treatment)
- 실험군 : 신약, 새로운 광고, 특정 교육 프로그램 등
- 대조군 : 위약(placebo), 기존 광고, 교육 없음 등
- 비교(Comparison)
- 두 집단의 결과 차이를 통계적으로 분석
- 유의한 차이가 있으면, 그 차이를 처치 효과로 해석
- 무작위 배정(Randomization)
- 주요 방법
- 매칭 (Matching)
- 비슷한 특성을 가진 집단끼리 짝지어 비교
- ex ) 연령/성별/소득이 같은 사람 → 적용군 vs 미적용군
- 자연실험 (Natural Experiment)
- 외부 환경 덕분에 “우연히 발생한 상황”을 실험처럼 활용
- ex ) 특정 지역만 우연히 규제를 먼저 적용
- 차분의 차분 (Difference-in-Differences, DiD)
- 정책 / 처치 전후의 변화를 처리군과 대조군의 차이로 비교해서 인과효과 추정
- ex ) 최저임금 인상 지역 vs 비인상 지역의 고용률 변화
- 매칭 (Matching)
사례
광고 효과 검증 (A/B 테스트)
- "광고비가 매출을 끌어올릴까?"
- 고객을 무작위로 두 집단으로 나눔
- 광고 노출군 vs 비노출군
- 두 그룹 매출 차이 → 광고 효과 확인 가능
- 고객을 무작위로 두 집단으로 나눔
- "A/B 테스트 결과, 광고 노출군의 매출은 비노출군보다 평균 12% 높았다 (p<α). 이는 광고 효과일 가능성을 시사한다."
신약 임상시험
- 한 그룹 : 신약 투여
- 다른 그룹 : 위약(가짜 약) 투여
- 무작위 배정으로 두 그룹 조건을 동일하게
- "임상시험에서 신약 투여군의 증상 개선률은 대조군보다 유의하게 높았다. 무작위 배정으로 다른 요인을 배제했으므로 이는 약효로 해석할 수 있다."
" 다중공선성 "
다중공선성
설명변수(독립변수)들끼리 강하게 상관관계를 가지는 상황
- 인과관계 X, 상관관계 O
문제
- 회귀계수(β) 추정 불안정
- 변수들이 서로 겹치면, 모델이 어떤 변수의 효과인지 구분하기 어려움
→ 계수 추정치가 크게 흔들리거나(불안정), 해석이 모호해짐
- 변수들이 서로 겹치면, 모델이 어떤 변수의 효과인지 구분하기 어려움
- 표준오차 증가 → p-value 커짐
- 회귀계수 유의성이 떨어져서 “중요한 변수인데도 불구하고 통계적으로 의미 없음”으로 나올 수 있음
- 과적합 위험 증가
- 변수가 많고 중복된 정보가 많을수록 모델이 일반화 성능이 떨어질 수 있음
확인 방법
- 상관계수 행렬
- 독립변수끼리의 상관계수가 0.8~0.9 이상이면 의심
- VIF (Variance Inflation Factor, 분산팽창계수)
- VIF < 5 : 문제 없음
- VIF 5~10 : 다소 문제
- VIF ≥ 10 : 심각한 다중공선성
# 다중회귀에 쓴 변수들
X = df[["weight", "displacement", "cylinders"]]
# 상수항 추가
X = sm.add_constant(X)
# VIF 계산
vif_df = pd.DataFrame()
vif_df["variable"] = X.columns
vif_df["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
print(vif_df)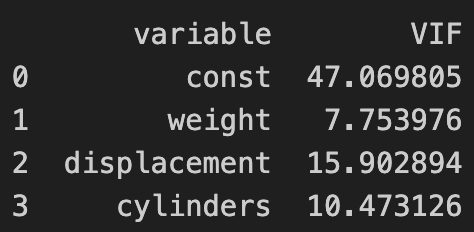
해결 방법
- 변수 제거
- 높은 상관관계를 가진 변수 중 하나를 빼기
- 변수 결합
- 비슷한 변수를 묶어 합산/평균/주성분으로 변환
- 차원 축소
- PCA(주성분분석) 등으로 상관된 변수를 새로운 축으로 요약
- 규제 회귀 사용
- Lasso 회귀(L1 정규화) → 중요하지 않은 변수 계수 = 0으로 만들어 변수 선택 효과
- Ridge 회귀(L2 정규화) → 계수 크기를 줄여 안정화
" 회귀분석 "
회귀분석
회귀
하나의 변수(Y)가 다른 변수(X들)와 어떤 규칙적인 관계를 가지는지를 수학적 함수(모델)로 표현하는 방법
- X가 변할 때 Y가 어떻게 변하는가?
회귀분석
종속변수 Y가 독립변수 X들에 어떻게(얼마만큼) 영향을 받는지 추정하고 예측하는 것
종류
단순 선형 회귀
- X → Y 관계를 단 하나의 직선으로 설명하는 모델
- 독립변수 1개
- 종속변수 Y가 연속형
- Y = β0 + β1X + ε
- β0 : 절편 (X=0일 때 Y값)
- β1 : 기울기 (X가 1 증가할 때 Y가 얼마나 변하는지)
- 현실은 여러 변수가 얽혀있기 때문에 확장 필요
다중 선형 회귀
- Y에 영향을 주는 X가 여러 개일 때
- 독립변수가 여러 개
- 종속변수 Y가 연속형
- Y = β0 + β1X1 + β2X2 + ... + βkXk + ε
- 장점 : 다양한 요인을 통제 가능
- 단점 : 다중공선성(multicollinearity) 문제
- 변수들이 서로 강한 상관관계 → 해석 어려움
다항 회귀
- 직선으로는 설명이 안 될 때, 곡선 형태를 반영
- Y = β0 + β1X + β2X² + β3X³ + ... + ε
- 선형 회귀의 확장 → 독립변수의 제곱, 세제곱 같은 항 추가
로지스틱 회귀
- 종속변수 Y가 이진형(0/1)일 때 사용
- 단순 직선 대신 시그모이드 함수(확률로 변환)로 모델링
- 해석 : 특정 조건에서 사건이 발생할 확률 추정
- ex ) 고객이 이탈할까(Yes=1 / No=0)?
규제 회귀
- 독립변수 많거나 다중공선성 심할 때 사용
- 다중 회귀에서 변수가 많으면 과적합(overfitting) 문제 발생
- 이를 방지하고 예측 안정성을 위해 패널티 부여
- 릿지(Ridge) : 계수를 작게 만들어 안정화 (L2 규제)
- 라쏘(Lasso) : 불필요한 계수를 아예 0으로 만들어 변수 선택 효과 (L1 규제)
- Elastic Net : L1 + L2 혼합
가정
선형 회귀
- 선형성
- X가 변할 때 Y는 일정한 비율로 변해야 한다
- 독립성
- 관측치들끼리 서로 독립적이어야 한다
- 등분산성
- 독립변수의 값에 상관없이 오차의 분산이 일정해야 한다
- 만약 X가 클수록 오차가 점점 커진다면 → 이분산성(Heteroscedasticity) 문제 발생
- 표준오차가 왜곡되어 p-value, 신뢰구간이 잘못됨
- 독립변수의 값에 상관없이 오차의 분산이 일정해야 한다
- 정규성
- 오차항(ε)이 정규분포를 따른다고 가정
- 다중공선성 없음
- 독립변수끼리 강한 상관관계가 없어야 한다
- VIF(Variance Inflation Factor)로 확인
다항 회귀
- 등분산성, 독립성
- X와 Y의 관계가 비선형 함수로 표현된다는 차이
로지스틱 회귀
- 등분산성, 독립성, 다중공선성 없음, 큰 표본에서 근사적 정규성 (중심극한정리)
- 선형성은 로짓(logit) 공간에서 성립해야 함 → X와 logit(p)의 관계가 선형
규제 회귀
- 선형성, 독립성, 등분산성
- 다중공선성 문제를 완화하기 위해 쓰는 게 특징
회귀분석에서의 가설검정
R² (결정계수, Coefficient of Determination)
- 회귀분석에서 모델이 데이터를 얼마나 잘 설명하는가를 나타내는 지표
- 값의 범위 : 0 ~ 1
- 높을수록 설명력 좋음
- 예측 정확도가 높다는 보장은 아님
- 비선형 관계라면 단순 선형회귀 R²은 낮게 나올 수 있음
- 예측 정확도가 높다는 보장은 아님
- 가끔 음수가 나올 수도 있음 → 모델이 오히려 평균보다 못함
- 높을수록 설명력 좋음
- 계산

- 모델의 오차가 데이터의 총 변동에 비해 얼마나 작은가
수정된 R² (Adjusted R²)
- 변수가 많아질수록 R²는 무조건 증가
- 쓸데없는 변수 넣어도 R²는 커짐
- 수정된 R² : 불필요한 변수가 들어가면 패널티 → 진짜 설명력만 반영
- 계산
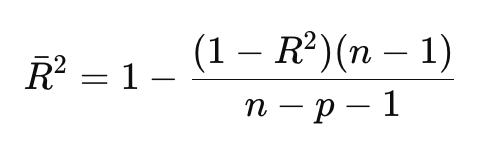
회귀계수
- 독립변수가 종속변수에 주는 영향력의 크기와 방향을 나타내는 값
- 얼마나(크기) 영향을 주는지
- 어느 방향(+) 또는 (-)으로 영향을 주는지
- 다중 회귀에서는 “다른 변수들을 통제한 조건에서의 효과” → 인과처럼 해석하면 위험
회귀모형 전체에 대한 검정 (F-검정)
- 귀무가설(H₀) : β₁ = β₂ = … = βk = 0
- 즉, 모델 자체가 의미 없다. (X들이 Y를 전혀 설명 못한다)
- 대립가설(H₁) : 적어도 하나의 계수는 0이 아니다
- 즉, 모델이 Y를 어느 정도 설명한다.
- 검정 방법 : F-통계량
- F값이 크고, p-value < 유의수준 → 모델이 전체적으로 유의
개별 회귀계수에 대한 검정 (t-검정)
- 각 독립변수 Xj가 종속변수 Y에 영향을 주는지 확인
- 귀무가설(H₀) : βj = 0
- 대립가설(H₁) : βj != 0
- 검정 방법 : t-통계량
- (추정량 - 가설값) / 표준오차
- t값이 크고 p-value < α → 해당 변수는 Y에 유의한 영향
단순 선형 회귀
import statsmodels.api as sm
X = df["weight"]
y = df["mpg"]
X = sm.add_constant(X)
model = sm.OLS(y, X).fit()
print(model.summary())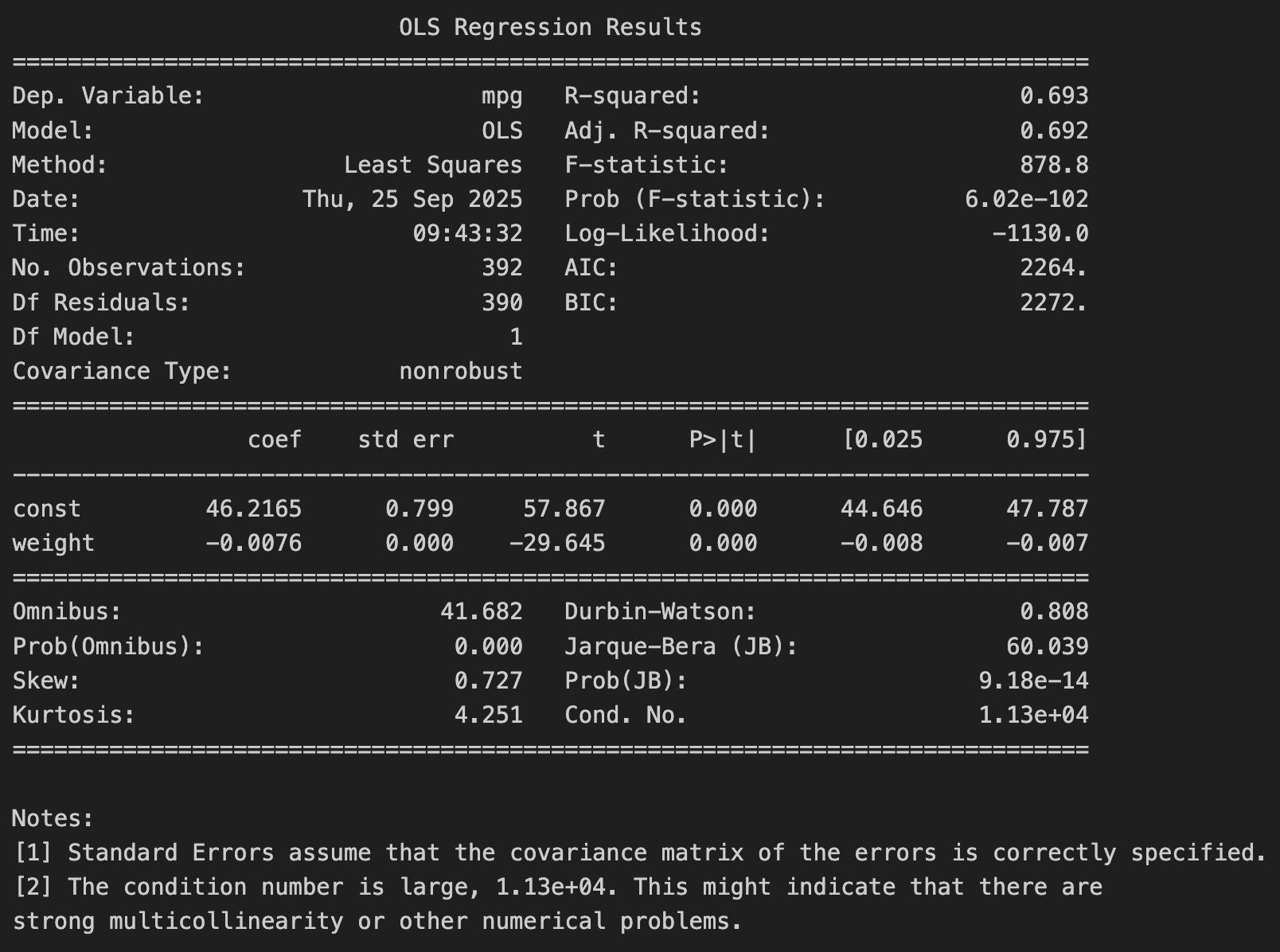
R-squared = 0.693
- 차량 무게(weight) 하나만으로 연비(mpg) 변동의 약 69.2%를 설명할 수 있음
- 단일 독립변수치고는 상당히 높은 설명력
F-statistic (878.8, p < 0.000)
- p-value < α → 모델이 통계적으로 유의함
회귀계수
- const(절편) = 46.2165
- 이론적으로 차량 무게가 0일 때 예상 연비는 약 46.2 mpg
- 실제 의미는 없고 기준선 역할
- weight = -0.0076
- 차량 무게가 1 파운드 늘어날 때마다 연비는 평균적으로 0.0076 mpg 감소
통계적 유의성
- weight의 p-value = 0.000
- p-value < α → 무게가 연비에 유의미한 영향을 준다고 볼 수 있음
신뢰구간
- weight의 95% 신뢰구간: [-0.008, -0.007]
- 계수가 음수임이 확실하다 : 무게 증가 → 연비 감소
fig = plt.figure(figsize=(8,6), facecolor='k')
ax= fig.add_subplot()
ax.patch.set_facecolor('k')
sns.regplot(x="weight", y="mpg", data=df, scatter_kws={"alpha":0.3, "color":"#7FFFD4"}, color="#4169E1")
ax.set_title("weight & mpg", color='w')
ax.set_xlabel("weight", color='w')
ax.set_ylabel("mpg", color='w')
ax.tick_params(colors='w')
ax.spines['bottom'].set_color('w')
ax.spines['left'].set_color('w')
plt.show()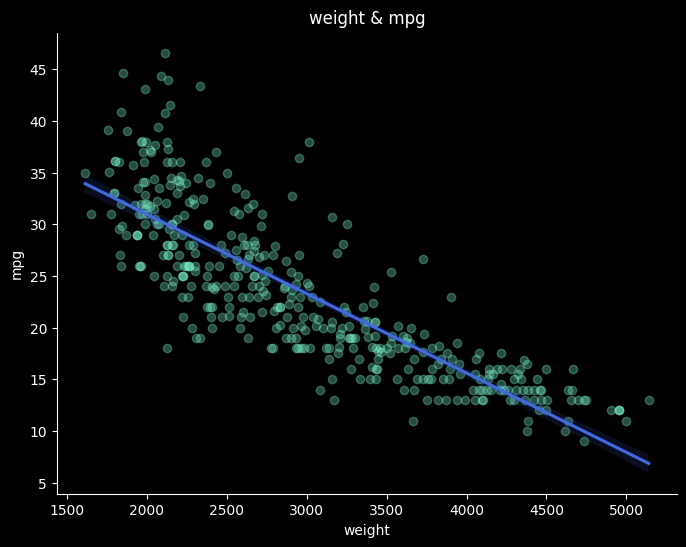
다중 회귀
X = df[["weight", "displacement", "cylinders"]]
y = df["mpg"]
X = sm.add_constant(X)
model = sm.OLS(y, X).fit()
print(model.summary())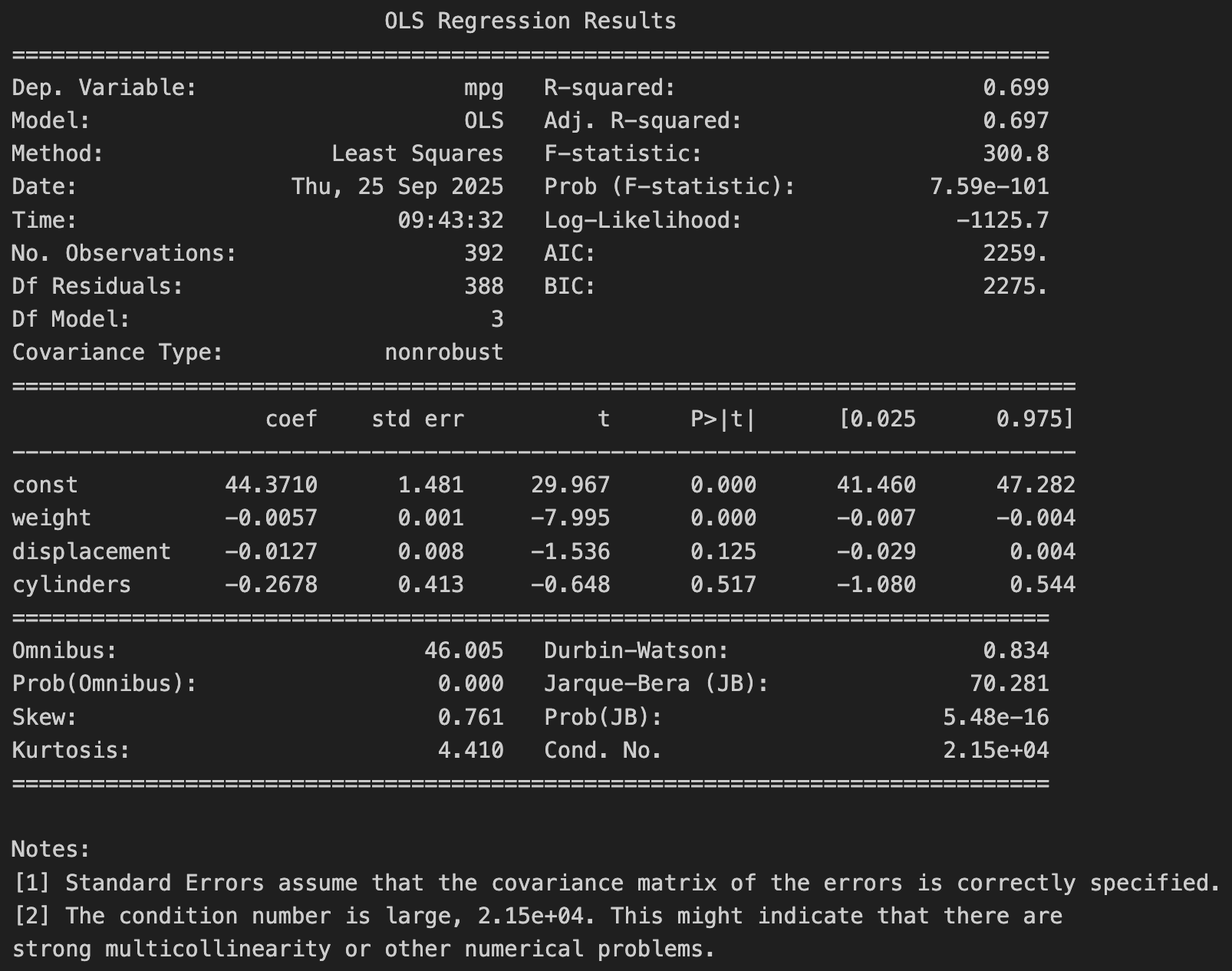
R-squared = 0.699, Adj. R-squared = 0.697
- 세 변수를 함께 쓰면 연비 변동의 약 69.8%를 설명
- 이전 단순회귀(weight만)와 비교하면 Adj. R-squared = 0.692 → 0.697로 거의 차이가 없음
- 추가 변수들이 설명력 개선에 별로 기여하지 못했음
F-statistic (300.8, p < 0.000)
- p-value < α → 모델이 통계적으로 유의함
회귀계수 & 유의성
- weight = -0.0057 (p = 0.000)
- 무게가 1 파운드 증가할 때 연비가 약 0.0058 mpg 감소 (유의미)
- displacement = -0.0127 (p = 0.125)
- p-value > α → 연비에 유의한 영향 못 줌
- cylinders = -0.2678 (p = 0.517)
- p-value > α → 연비에 유의한 영향 못 줌

화이팅구리