swagger autogen in Node.js
- swagger를 사용하려면 일반적으로 문법을 알아야하는데, swagger autogen 자동생성 라이브러리를 사용하면 swagger 문법을 이용하지 않더라도, 내가 개발한 api들을 자동으로 하나의 문서로 정리해준다.
- 보통 swagger를 YAML 이나 JSON 형식으로 하는 방식을 많이 봤어서 나도 그냥 당연하게 이 방식으로 swagger를 써보려고 했는데 찾아보다가 autogen을 발견하고 좀 더 편할수도 있겠다고 판단되어 autogen을 사용하였다.
swagger autogen 사용
1. package 설치
npm install swagger-ui-express
npm install swagger-autogen2. app.js에 swagger 미들웨어 추가
const swaggerUi = require("swagger-ui-express");
const swaggerFile = require("../swagger-output.json");
app.use("/swagger", swaggerUi.serve, swaggerUi.setup(swaggerFile));3. swagger.js 파일을 src 밖으로 추가해주고 다음 내용을 넣어주었다. endpointsFiles에는 api들이 기록되는 router 경로가 적힌 js들을 모두 포함시킨다. (app.js에 router 미들웨어가 있어서 app.js만 넣어주었다.)
const swaggerAutogen = require('swagger-autogen')();
const options = {
swaggerDefinition: {
openapi: '3.0.0',
info: {
title: 'pillnuts',
version: '1.0.0',
description: 'a REST API using swagger and express.',
},
servers: [
{
url: 'https://localhost:3000',
},
],
},
apis: [],
};
const outputFile = './swagger-output.json'
const endpointsFiles = ['./src/app.js']
swaggerAutogen(outputFile, endpointsFiles, options);4. package.json 파일에 추가해주기
"start-gendoc": "node ./src/swagger.js"명령어를 실행시, swagger-output.json파일이 자동으로 생성된다. 이때 swagger-output.json파일에는 라우터에 담긴 모든 api정보들이 자동으로 생성된다. 이 점이 매우 편리했다.
api들에 swagger 문법으로 description, tag등을 작성하면, 해당 내용들이 swagger-output.json에 포함되어 생성된다. api들이 엄청나게 많은 양은 아니었지만 각 api별로 구분해서 분류해줘야할 필요가 있다고 생각되어 tag에 각 api별로 구분해주었다.
{
"swagger": "2.0",
"info": {
"version": "1.0.0",
"title": "pillnuts",
"description": "pillnuts's API"
},
"host": "api.geniuskim.shop",
"basePath": "/api",
"schemes": ["https"],
"paths": {
"/users/login/normal": {
"post": {
"tags": ["Users API"],
"description": "로컬 로그인 API",
"parameters": [
{
"name": "body",
"in": "body",
"schema": {
"type": "object",
"properties": {
"email": { "type": "string" },
"password": { "type": "string" }
}
}
}
],
"responses": {
"201": { "description": "OK" },
"400": { "description": "Bad request" },
"412": {
"description": "unauthorized"
}
}
}
},
"/users/login/google": {
"get": {
"tags": ["Users API"],
"description": "구글 소셜 로그인 조회",
"parameters": [],
"responses": {
"201": { "description": "OK" },
"400": { "description": "Bad request" }
}
}
},이렇게 하나씩 설정해주면 내가 설정해준 localhost:3000/swagger에 들어가서 확인해볼 수 있다.
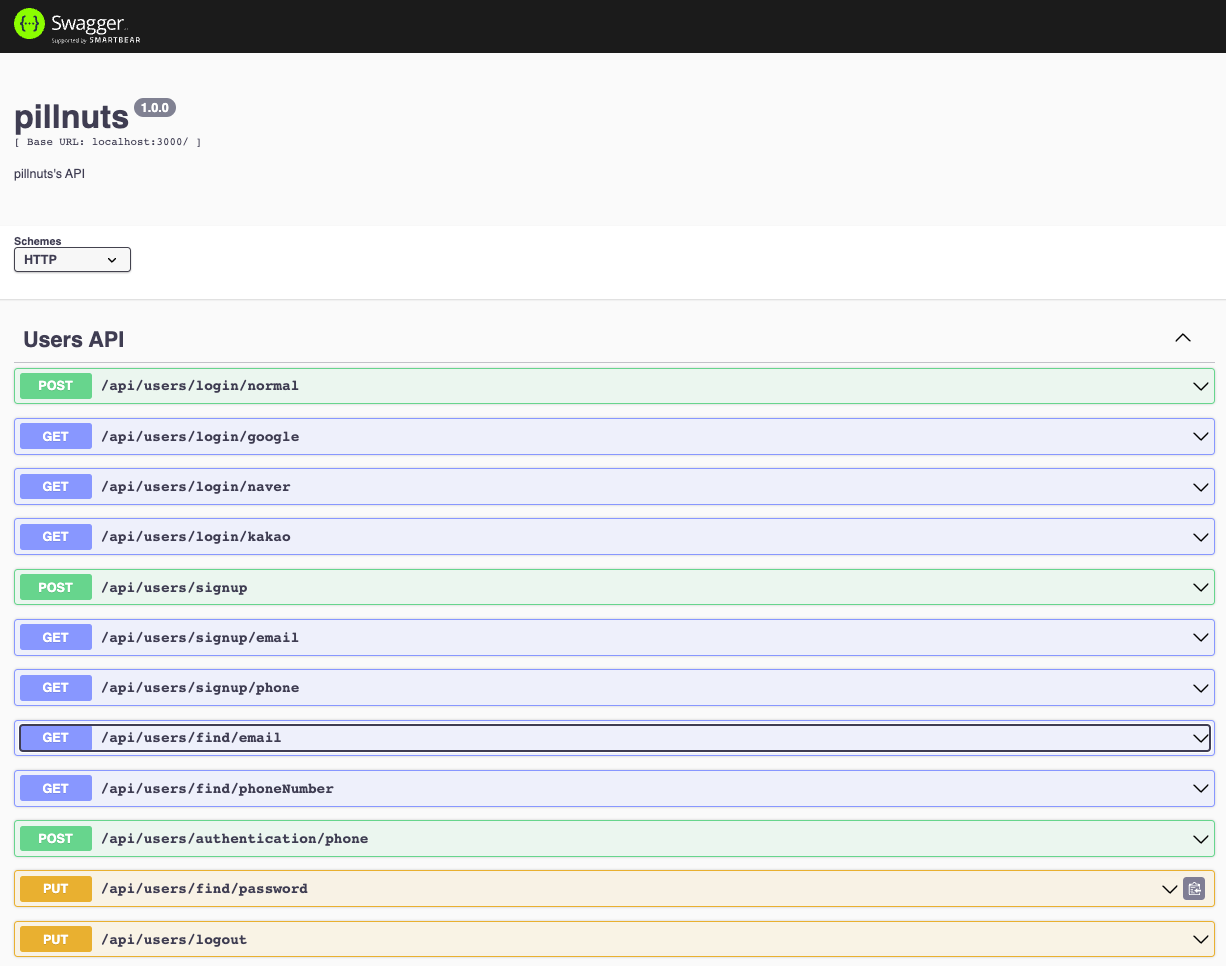
이 프레임워크를 사용하면서 배운 점
swagger 자체가 실제 내가 만든 api들과 연결시켜서 작동시켜보는 것인데 이때 내가 테스트용으로 try했을 때, 실제 우리 배포용 DB에 데이터가 저장되는 것을 발견할 수 있었다.
그렇다면 누군가가 우리 local/swagger로 들어와서 악의적으로 테스트를 하면서 우리 DB에 불필요한 데이터들이 쌓인다면?
그렇지만 스웨거 자체가 API문서들 기록/관리를 자동화 시켜주는건데 그런 위험이나 데이터에 불필요한 데이터들이 쌓이면서까지 이걸 사용해야하는 이유는 뭘까? 라고 생각해보았는데,
결국에는 혼자 계속 고민하다가 기술매니저님의 조언으로 만약 스웨거를 돌릴 때 로컬에서 돌린다면 local .env에는 테스트용 DB URL을, 배포 .env에는 배포용 DB URL을 입력할 수 있는 방법이 있다는 것을 알게 되었다.
그렇다면 실제 배포용 DB에는 테스트를 해도 불필요한 데이터들이 안쌓이게 될테니까!
