명령어들
-
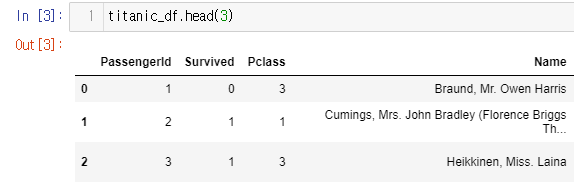
head()
DataFrame의 맨 앞 일부 데이터만 추출.
-
DataFrame의 생성
dic1 = {'Name': ['Chulmin', 'Eunkyung','Jinwoong','Soobeom'],
'Year': [2011, 2016, 2015, 2015],
'Gender': ['Male', 'Female', 'Male', 'Male']
}
# 딕셔너리를 DataFrame으로 변환
data_df = pd.DataFrame(dic1)
print(data_df)
print("#"*30)
# 새로운 컬럼명을 추가
data_df = pd.DataFrame(dic1, columns=["Name", "Year", "Gender", "Age"])
print(data_df)
print("#"*30)
# 인덱스를 새로운 값으로 할당.
data_df = pd.DataFrame(dic1, index=['one','two','three','four'])
print(data_df)
print("#"*30)
- DataFrame의 컬럼명과 인덱스
print("columns:",titanic_df.columns)
print("index:",titanic_df.index)
print("index value:", titanic_df.index.values)

- DataFrame에서 Series 추출 및 DataFrame 필터링 추출
# DataFrame객체에서 []연산자내에 한개의 컬럼만 입력하면 Series 객체를 반환
series = titanic_df['Name']
print(series.head(3))
print("## type:",type(series))
# DataFrame객체에서 []연산자내에 여러개의 컬럼을 리스트로 입력하면 그 컬럼들로 구성된 DataFrame 반환
filtered_df = titanic_df[['Name', 'Age']]
print(filtered_df.head(3))
print("## type:", type(filtered_df))
# DataFrame객체에서 []연산자내에 한개의 컬럼을 리스트로 입력하면 한개의 컬럼으로 구성된 DataFrame 반환
one_col_df = titanic_df[['Name']]
print(one_col_df.head(3))
print("## type:", type(one_col_df))
- shape: DataFrame의 행(Row)와 열(Column) 크기를 가지고 있는 속성
- Index는 차원에 포함 X
print('DataFrame 크기: ', titanic_df.shape)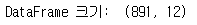
- info(): DataFrame내의 컬럼명, 데이터 타입, Null건수, 데이터 건수 정보를 제공.
titanic_df.info()
- describe(): 데어터값들의 평균, 표준편차, 4분위 분포도를 제공. 숫자형 컬럼들에 대한 해당 정보를 제공.
titanic_df.describe()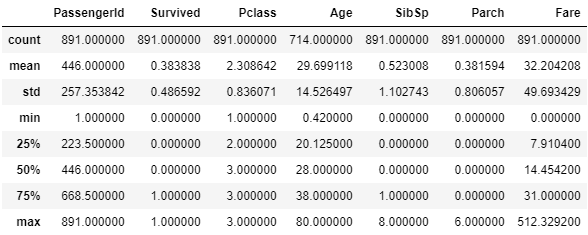
- value_counts(): 동일한 개별 데이터 값이 몇 건이 있는지 정보를 제공. 즉 개별 데이터값의 부포도를 제공.
- 주의: value_counts()는 Series객체에서만 호출 가능하므로 반드시 단일 컬럼으로 입력하며 Series로 변환한 뒤 호출.
value_counts = titanic_df['Pclass'].value_counts()
print(value_counts)
- sort_values(): by=정렬컬럼, ascending=True/False(오름차순/내림차순) 정렬
#titanic_df.sort_values(by='Pclass', ascending=True)
#titanic_df[['Name','Age']].sort_values(by='Age')
titanic_df[['Name','Age','Pclass']].sort_values(by=['Pclass','Age'])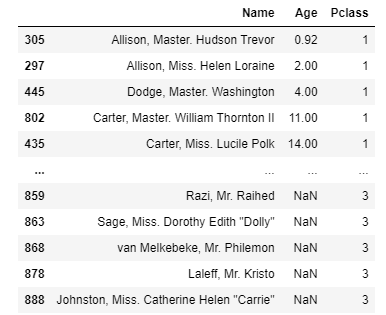

유니콘을 위하여