Machine Learning
1.#1 머신러닝의 개념

1. 머신러닝 개념 애플리케이션을 수정하지 않고도 데이터를 기반으로 패턴을 학습하고 학습된 모델을 통해서 결과를 추론하는 알고리즘 기법을 통칭. => 인간의 인지능력만이 해결 가능하다고 여겨졌던 다양한 분야 (ex. 데이터 마이닝, 영상인식, 음성인식, 자연어 처리
2.#2 파이썬 기반 머신러닝의 특징

파이썬 머신러닝 생태계를 구성하는 주요 패키지. 머신러닝 패키지 사이킷런 배열/선형대수/통계 패키지
3.#3 파이썬 기반 머신러닝을 위한 SW의 설치
아나콘다 설치
4.#4 넘파이 배열 ndarray
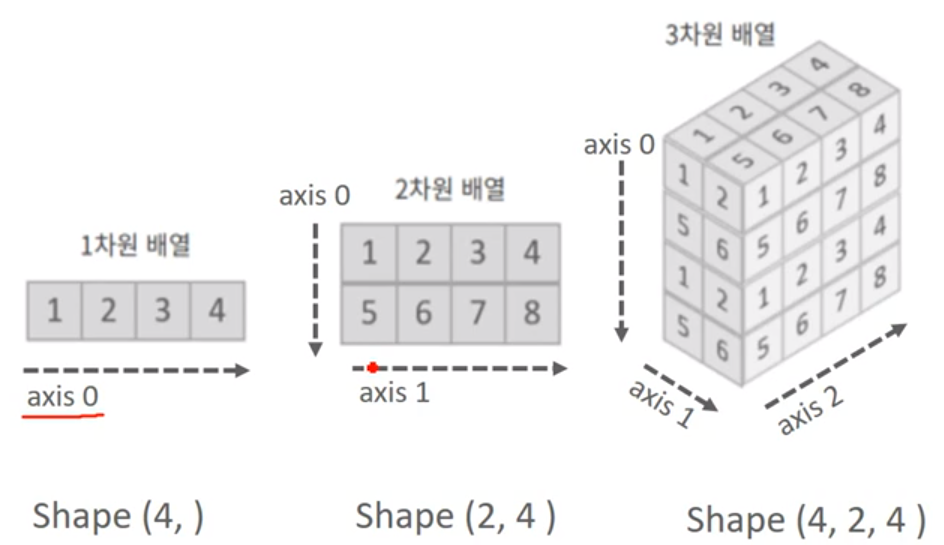
ndarray: N차원(Dimension) 배열(Array) 객체=> Numpy 모듈의 array() 함수로 생성. 인자로 주로 파이썬 list or ndarray 입력.ndarray의 shape는 ndarray.shape 속성으로, 차원은 ndarray.ndim 속성
5.#5 넘파이 ndarray 초기화 방법과 ndarray차원과 크기를 변경하는 방법

arange()np.arange(10) => 0 1 2 3 4 5 6 7 8 9 np.zeros((3, 2), dtype='int32') => \[ 0 0 0 0 0 0 ]np.ones((3, 2))=> \[ 1. 1. 1. 1.
6.#6 넘파이 ndarray의 Indexing을 통한 데이터 세트 선택하기

특정 위치의 단일값 추출원하는 위치의 인덱스 값을 지정하면 해당 위치의 데이터가 반환.슬라이싱(Slicing)연속된 인덱스상의 ndarray를 추출하는 방식. ':' 기호 사이에 시작 인덱스와 종료 인덱스를 표시하면 시작 인덱스와 종료 인덱스 -1 위치에 있는 ndar
7.#7 넘파이 ndarray의 정렬과 선형대수 연산
np.sort(ndarray): 원 행렬은 그대로 유지한 채 원 행렬의 정렬된 행렬을 반환.ndarray.sort(): 원 행렬 자체를 정렬한 형태로 변환하며 반환 값은 None.np.sort(ndarray)::-1: 내림차순 정렬.np.sort(A,axix=0) \[
8.#8 판다스 개요와 기본 API
판다스(Pandas) 파이썬에서 데이터 처리를 위해 존재하는 가장 인기 있는 라이브러리 인간이 가장 이해하기 쉬운 행과 열의 2차원 데이터를 효율적으로 가공/처리할 수 있는 다양하고 훌륭한 기능을 제공. 주요 구성 요소: DataFrame, Series, Index
9.#9 판다스 개요와 기본 API_2
두번째 시간
10.#10 판다스 DataFrame의 변환, 컬럼 세트 생성/수정, 삭제 및 Index 객체 소개
DataFrame과 리스트, 딕셔너리, 넘파이 ndarray 상호 변환
11.#11 판다스 데이터 셀렉션과 필터링
컬럼 기반 필터링 또는 불린 인덱싱 필터링 제공명칭/위치 기반 인덱싱을 제공명칭(Label) 기반 인덱싱은 컬럼의 명칭을 기반으로 위치를 지정하는 방식. '컬럼 명' 같이 명칭으로 열 위치를 지정하는 방식.위치(Position) 기반 인덱싱은 0을 출발점으로 하는 가로
12.#12 판다스 Aggregation 함수와 Group by 수행
Aggregation 함수 sum(), max(), min(), count() 등의 함수는 DataFrame/Series에서 집합(Aggregation)연산을 수행. DataFrame의 경우 DataFrame에서 바로 aggreation을 호출할 경우 모든 컬럼에
13.#13 판다스 람다식 적용하여 데이터 가공하기 및 판다스 Summary
판다스 apply lambda - 파이썬 lambda식 이해 >일반함수 >파이썬 lambda식
14.파이썬 기반의 머신러닝과 생태계 이해 요약
머신러닝이란
15.#14 사이킷런 소개, 첫번째 머신러닝 app - 붓꽃 품종 예측

사이킷런 파이썬 기반의 다른 머신러닝 패키지도 사이킷런 스타일의 API를 지향할 정도로 쉽고 가장 파이썬스러운 API를 제공.
16.#15 사이킷런의 기반 프레임 워크 익히기
Estimator와 fit(), predict() 학습: fit() 예측: predict() 주요 모듈 예제 데이터 sklearn.datasets - 사이킷런에 내장되어 예제로 제공하는 데이터 세트 데이터 분리, 검증 & 파라미터 튜닝 sklearn.model_selection - 교차 검증을 위한 학습용/테스트용 분리, 그리드 서치(Grid Searc...
17.#16 학습과 테스트 데이터 세트의 분리

Model Selection 학습 데이터 세트 머신러닝 알고리즘의 학습을 위해 사용 데이터의 속성들과 결정값(레이블)값 모두를 가지고 있음 학습 데이터를 기반으로 머신러닝 알고리즘이 데이터 속성과 결정값의 패턴을 인지하고 학습 테스트 데이터 세트 테스트 데이터 세트에서 학습된 머신러닝 알고리즘을 테스트 테스트 데이터는 속성 데이터만 머신러닝 알고리즘에 제...
18.#17 교차검증: K-Fold와 Stratified K-Fold

일반 K 폴드Stratified K 폴드불균형한(imbalanced) 분포도를 가진 레이블(결정 클래스) 데이터 집합을 위한 K 폴드 방식학습데이터와 검증 데이터 세트가 가지는 레이블 분포도가 유사하도록 검증 데이터 추출