Vectorization
1. 벡터화에 신경망을 사용하지 않을 경우
- 단어에 대한 벡터 표현 방법: 원-핫 인코딩
- 문서에 대한 벡터 표현 방법: Decoment Term Matrix, TF-IDF
2. 벡터화에 신경망을 사용하는 경우 (2008 ~ 2018)
- 단어에 대한 벡터 표현 방법: 워드 임베딩(Word2Vec, GloVe, FastText, Embedding layer)
- 문서에 대한 벡터 표현 방법: Doc2Vec, Sent2Vec
3. 문맥을 고려한 벡터 표현 방법: ELMo, BERT (2018 - present)
- Pretrained Language Model의 시대
Vectorization: One-Hot Encoding
- 원-핫 인코딩은 전체 단어 집합의 크기(중복 카운트하지 않은 단어들의 집합)를 벡터의 차원으로 가짐
- 각 단어에 고유한 정수 인덱스를 부여하고, 해당 인덱스의 원소는 1, 나머지 원소는 0을 가지는 벡터로 만듦
- 전체 단어 집합의 크기를 벡터의 차원으로 가짐
- 단어 벡터 간 유의미한 유사도를 구할 수 없다는 한계가 있음
| 구분 | One-hot |
|---|---|
| 단어 vs 단어 | ❌ 의미 없음 |
| 문장 vs 문장 | ⭕ (단어 겹침 기준) |
| 의미 반영 | ❌ 없음 |
| 차원 | 매우 큼 (vocab size) |
Vectorization: Word Embedding
- 실수값 벡터를 가지며 차원이 보통 100~300정도.
- 학습을 통해 값이 결정된다.
- 의미가 벡터에 반영됨
단어 → 정수 인덱스 (이론적으로 one-hot encoding) → (embedding layer) → dense vector
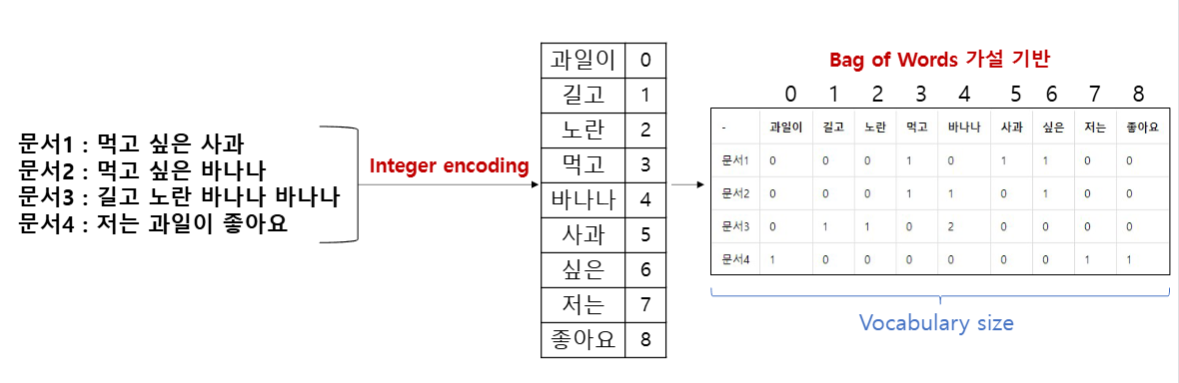
Vectorization - Document Term Matrix, DTM (문서)
DTM (Document Term Matrix)
- DTM은 벡터가 단어 집합의 크기를 가짐, 대부분의 값이 0을 가진다.
- 단어의 순서는 무시하고, 오직 단어의 빈도수에만 집중하는 방법.
TF-IDF (Term Frequency-Inverse Document Frequency)
- DTM에서 추가적으로 중요한 단어에 가중치를 주는 방식
- TF-IDF 기준으로 중요한 단어는 값이 올라가고 중요하지 않은 값은 떨어짐
- TF-IDF는 TF와 IDF라는 두 값을 곱한 결과
- 문서의 유사도, 검색 시스템에서 검색 결과의 순위 등을 구하는 일에 쓰임
- 인공 신경망의 입력으로도 사용 가능 (텍스트 분류도 가능)
실습
import numpy as np
from numpy import dot
from numpy.linalg import norm
def cos_sim(A, B):
return dot(A, B)/(norm(A)*norm(B))
doc1 = np.array([0,1,1,1])
doc2 = np.array([1,0,1,1])
doc3 = np.array([2,0,2,2])
print('문서 1과 문서2의 유사도 :',cos_sim(doc1, doc2))
print('문서 1과 문서3의 유사도 :',cos_sim(doc1, doc3))
print('문서 2와 문서3의 유사도 :',cos_sim(doc2, doc3))문서 1과 문서2의 유사도 : 0.6666666666666667
문서 1과 문서3의 유사도 : 0.6666666666666667
문서 2와 문서3의 유사도 : 1.0000000000000002import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
data = pd.read_csv('/content/sample_data/data/movies_metadata.csv', low_memory=False)
data.head(2)# 상위 2만개의 샘플을 data에 저장
data = data.head(20000)# overview 열에 존재하는 모든 결측값을 전부 카운트하여 출력
print('overview 열의 결측값의 수:',data['overview'].isnull().sum())overview 열의 결측값의 수: 135# 결측값을 빈 값으로 대체
data['overview'] = data['overview'].fillna('')tfidf = TfidfVectorizer(stop_words='english')
tfidf_matrix = tfidf.fit_transform(data['overview'])
print('TF-IDF 행렬의 크기(shape) :',tfidf_matrix.shape)TF-IDF 행렬의 크기(shape) : (20000, 47487)cosine_sim = cosine_similarity(tfidf_matrix, tfidf_matrix)
print('코사인 유사도 연산 결과 :',cosine_sim.shape)코사인 유사도 연산 결과 : (20000, 20000)title_to_index = dict(zip(data['title'], data.index))
# 영화 제목 Father of the Bride Part II의 인덱스를 리턴
idx = title_to_index['Father of the Bride Part II']
print(idx)4def get_recommendations(title, cosine_sim=cosine_sim):
# 선택한 영화의 타이틀로부터 해당 영화의 인덱스를 받아온다.
idx = title_to_index[title]
# 해당 영화와 모든 영화와의 유사도를 가져온다.
sim_scores = list(enumerate(cosine_sim[idx]))
# 유사도에 따라 영화들을 정렬한다.
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# 가장 유사한 10개의 영화를 받아온다.
sim_scores = sim_scores[1:11]
# 가장 유사한 10개의 영화의 인덱스를 얻는다.
movie_indices = [idx[0] for idx in sim_scores]
# 가장 유사한 10개의 영화의 제목을 리턴한다.
return data['title'].iloc[movie_indices]
get_recommendations('The Dark Knight Rises')TF-IDF (Term Frequency-Inverse Document Frequency)
- TF-IDF는 tf(단어 빈도)와 idf(역 문서 빈도 - 안 나오는 빈도)라는 두 값을 곱한 결과이다.
- tf(d,t): 특정 문서 d에서의 특정 단어 t의 등장 횟수.
- df(t): 특정 단어 t가 등장한 문서의 수.
- idf(d, t): df(t)에 반비례하는 수.(df(t)가 커지면 작아지는 수)
N: 전체 문서 개수
- idf는 단어가 흔할 수록 중요도를 낮추고, 희귀할수록 중요도는 높이는 값
- log를 씌우는 이유는 미사용 시 idf의 값이 기하급수적으로 커질 수 있기 때문에
- log를 씌우지 않으면 희귀 단어들에 엄청난 가중치가 부여될 수 있는데 로그는 이런 격차를 줄이는 효과가 있다.
TF-IDF를 이용한 태스크
- 문서 클러스터링
- 유사한 문서 찾기
- 문서 분류 문제
인공 신경망으로 단어 임베딩과 유사하게 문서 임베딩 벡터를 얻는 방법도 존재:
Doc2Vec, Sent2Vec, Universal Sentence Encoder, ELMo, BERT

오랜시간 망설였던 코딩을 다시 해보려고 노력하고 있는 사람