Tokenization (eng)
- 기계에게 어느 구간까지가 문장이고, 단어인지를 알려주어야 함
- 문장 토큰화, 단어 토큰화, subword 토큰화 등 다양한 단위의 토큰화가 존재
- 목적과 상황에 따라 적절한 토큰화를 사용하는 것이 중요
1) TreebankWordTokenizer (단어)
영어권 언어의 단어 토크나이저 중 하나. 표준 토큰화 규칙인 Penn Treebank Tokenization을 따른다.
- 규칙 1. 하이픈으로 구성된 단어는 하나로 유지
- 규칙 2. doesn't와 같이 아포스트로피로 '접어'가 함께하는 단어는 분리(does, n't)
2) 문장 토크나이저
영어 - 마침표로 구분하면 될 것 같지만 Ph.D. 등 분리되어서는 안되는 부분도 있다.
한국어 - !나 ?는 꽤 명확한 구분자가 되지만 온점을 판단하는 것은 생각보다 잘 동장하지 않는다
2-1) NLTK Sentence Tokenizer
단순 온점 기준으로 구분하지 않고 잘 동작
2-2) KSS(Korean Sentence Splitter)
한국어의 자연어 처리
- 영어보다 자연어 처리가 훨씬 어려움
띄어쓰기 보정: KoSpacing
- 잘못된 띄어쓰기를 보정해 주는 딥 러닝 기반의 패키지
주어생략, 어순이 자유로움
교착어, 형태소 분석기
- 교착어란 실질적인 의미를 가지는 어간에 조사나, 어미와 같은 문법 형태소들이 결합하여 문법적인 기능이 부여되는 언어를 말함
- 예) 은, 는, 이, 가, 를 등과 같은 조사
그래서...
- 형태소 분석기를 사용하는 것이 보편적: Mecab, Kkma, Okt, Hannanum, Khaii, Soynlp
Cleaning and Normalization
1) Cleaning(정제): 불필요한 데이터를 제거하는 일
- 정규 표현식을 이용한 노이즈 데이터 제거
- 인코딩 문제 해결
- 등장 빈도가 적은 단어 제거: 등장 빈도가 2회 이하 (등장 빈도가 적으나 의미있는 단어들을 위해서 이런 단어들은 \로 표기하는 등의 방법이 있음)
- 길이가 짧은 단어 제거(영어의 경우): I, by, at 등
- 불용어 제거: I, at, for, by, at, 은, 는, 이, 가
- 불용어는 절대적인 기준이 아니라, 어떤 데이터인지, 어떤 문제를 푸는지, 어떤 토크나이저를 사용하는지에 따라 달라진다.
희귀 단어들을 처리하는 방법
- 제거
- \로 표시
- word embedding
- 서브 워드 기반 모델: BPE, WordPiece (BERT)
2) Nomalization(정규화): 같은 의미를 갖고 있다면 하나로 통일하여 복잡도를 줄임
- am, are, were, was -> be (lemmatization)
- has, had -> have (lemmatization)
- 10, 159, 123 -> num (숫자가 중요하지 않을 경우)
- ㅋ, ㅋㅋ, ㅋㅋㅋㅋㅋㅋ -> ㅋㅋ
- Hmmmmmm, Hmm, Hmmmmmmmm -> hmm
- 대소문자 통합
Stemming
am → am
the going → the go
having → hav
Lemmatization
am → be
the going → the going
having → have
실습(nltk)
from nltk.tokenize import sent_tokenize
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
import nltk
#download
nltk.download('punkt')
nltk.download('stopwords')
text = "What about this?"
text = sent_tokenize(text) # 문장 토큰화
print(text)
sentence = []
stop_words = set(stopwords.words('english')) #NLTK 불용어
for i in text:
sentence = word_tokenize(i) # 단어 토큰화
result = []
for word in sentence:
word = word.lower() # 모든 단어를 소문자화하여 단어의 개수를 줄입니다.
if word not in stop_words: # 불용어를 제거 합니다.
if len(word) > 2:
result.append(word)
sentence.append(result)
print(sentence)
['What about this?']
['What', 'about', 'this', '?', []]- nltk를 사용하기 위해서는 설치도 해야하고 데이터도 다운로드 해야함
- 다운로드 받는 데이터는, 문장 토큰화 모델 (훈련된 규칙, 통계 데이터 파일)
- 단어를 소문자화 하면 알파벳이 통일 되어 단어의 개수가 줄 수 있음
["Apple", "apple", "APPLE"] -> ["apple", "apple", "apple"]
Integer Encoding
- 단어 토큰화 혹은 형태소 토큰화 우헤 각 단어에 고유한 정수를 부여 (중복 허용 X)
- 중복이 허용되지 않는 모든 단어들의 집합을 단어 집합(Vocabulary)라고 한다.
Padding
- 모든 문장에 대해 정수 인코딩을 수행하였을 때 길이는 서로 다를 수 있다.
- 이 때 가상의 단어를 추가하여 길이를 맞춤 (기계가 병렬 연산 가능)
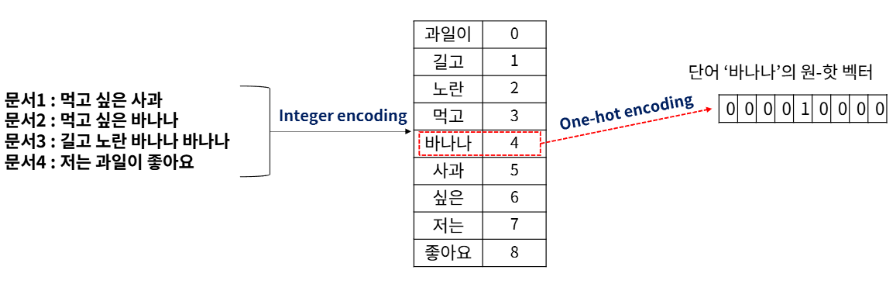
Vectorization: One-Hot encoding
- 원-핫 인코딩은 전체 단어 집합의 크기(중복은 카운트 하지 않은 단어들의 개수)를 벡터의 차원으로 가진다.
- 각 단어에 고유한 정수 인덱스를 부여하고, 해당 인덱스의 원소는 1, 나머지 원소는 0을 가지는 벡터로 만듦
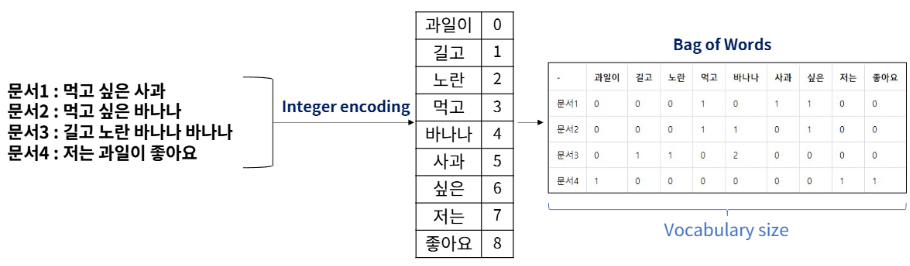
Vectorization: Document Term Matrix, DTM
- 벡터가 단어 집합의 크기를 가지며, 대부분의 원소가 0
- 각 단어는 고유한 정수 인덱스를 가지며, 해당 단어의 등장 횟수를 해당 인덱스의 값으로 가짐
One-hot encoding = "단어 자체를 표현"
vs
DTM(Document-Term Matrix) = "문서 안의 단어 분포를 표현"

오랜시간 망설였던 코딩을 다시 해보려고 노력하고 있는 사람