GloVe
Windows Based Co-occurrence Matrix
- Document Term Matrix와 마찬가지로 고차원을 가지는 행렬 표현 방법
- Window 크기에 따라서 행렬의 값이 결정된다는 특징이 있음
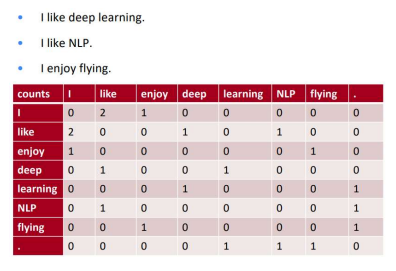
- 윈도우 크기가 1일때의 예시, 일반적으로 윈도우 크기 5-10
- 동시 등장 행렬은 기본적으로 대칭 행렬
- 행과 열이 단어 집합(vocabulary size)의 크기
- DTM, OHE와 마찬가지로 저장 공간 낭비
- 행렬이 매우 희소하다는 특징이 있음
이 행렬을 Dense하도록 임베딩 하면 GloVe(Global Vectors for Word Representation)
- 동시 등장 확률을 정의
- GloVe는 이 단어와 다른 단어가 얼마나 같이 등장하는가를 학습
- 중심 단어 벡터와 주변 단어 벡터의 내적(dot product)이 동시 등장 확률이 되도록 학습
- 두 단어의 내적이 동시 등장 빈도의 로그값의 차이가 최소화 되도록 학습한다.
동시 등장 확률(Co-occurrence Probability)
동시 등장 확률 P(k|i)는 동시 등장 행렬로부터 특정 단어 i의 전체 등장 횟수를 카운트 하고, 특정 단어 i가 등장했을 때 k가 등장한 횟수를 카운트하여 계산한 조건부 확률
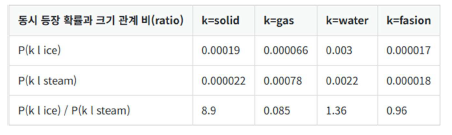
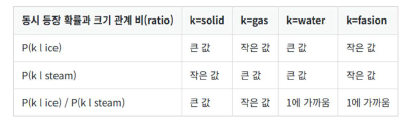
- ratio ≫ 1 → ice와 강하게 연관 (ex. solid)
- ratio ≪ 1 → steam과 강하게 연관 (ex. gas)
- ratio ≈ 1 → 중립 단어, 구분력 없음 (ex. water, the 등)
GloVe: 용어 정리
- X: 동시 등장 행렬 (Co-occurrence Matrix)
- Xᵢⱼ: 중심 단어 i가 등장했을 때 윈도우 내 주변 단어 j가 등장하는 횟수
- Xᵢ = Σⱼ Xᵢⱼ: 동시 등장 행렬에서 i행의 값을 모두 더한 값
- Pᵢₖ = P(k | i) = Xᵢₖ / Xᵢ
-> 중심 단어 i가 등장했을 때 윈도우 내 주변 단어 k가 등장할 확률 - 비율 (ratio)
- wᵢ: 중심 단어 i의 임베딩 벡터
- wₖ: 주변 단어 k의 임베딩 벡터
GloVe -> 임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 코퍼스에서 동시 등장 확률이 되도록 만드는 것
확률 비율 (Ratio)
두 중심 단어 i, j와 주변 단어 k에 대해:
이 값이 단어 간 의미 차이를 나타낸다.
로그 변환 (Log Transformation)
확률 비율을 다루기 쉽게 로그를 취하면:
벡터 차이로 표현
GloVe는 이 값을 벡터 차이로 근사한다:
- : 중심 단어 벡터
- : 주변 단어 벡터
최종 형태 (로그 + 내적)
결국 다음 관계를 학습:
GloVe의 실제 학습 목표 (Objective Function)
GloVe는 직접 ratio를 쓰지 않고,
동시 등장 횟수 자체를 로그로 맞추는 방식을 사용한다:
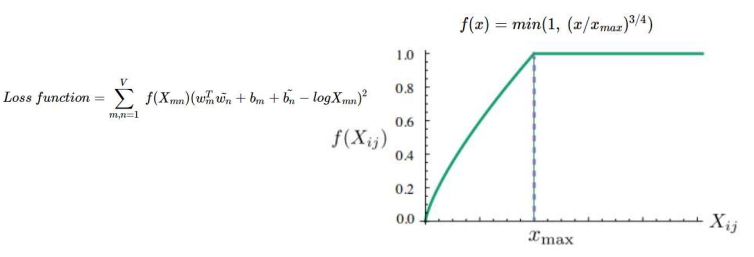
손실 함수 (Loss Function)
가중치 함수
"자주 나오는 말은 너무 흔해서 무시하고,
한두 번 나온 말은 우연일 수 있으니 덜 믿고,
적당히 자주 나온 말을 가장 믿는다"
빈도가 너무 큰 값의 영향을 줄이기 위해:
- 보통:
왜 GloVe는 로그(log)를 사용할까?
GloVe에서 로그를 사용하는 이유는 크게 세 가지다.
1. 곱셈 관계 → 덧셈 구조로 변환
GloVe의 핵심은 확률 비율:
여기에 로그를 취하면:
비율(곱셈 구조)이 차이(덧셈 구조)로 바뀜
왜 이게 중요한가?
GloVe는 이 값을 다음처럼 표현하려고 한다:
벡터 연산은 기본적으로 덧셈/뺄셈 구조이기 때문에
-> 로그를 써야 자연스럽게 맞아떨어진다.
2. 데이터 스케일 안정화 (Long-tail 문제 해결)
동시 등장 횟수 는 다음처럼 분포한다:
- 어떤 단어 쌍: 수천~수만 번 등장
- 대부분 단어 쌍: 거의 등장 안 함
극단적으로 치우친 분포 (long-tail)
로그를 쓰면?
큰 값은 압축되고 작은 값은 상대적으로 유지됨
-> 학습이 훨씬 안정적
3. "의미"는 비율에 있고, 로그가 그걸 보존함
언어에서 중요한 건 절대 빈도가 아니라:
-> "얼마나 더 자주 같이 나오느냐"
예:
- 10 vs 1 → 의미 있음
- 1000 vs 100 → 비율은 같음 (둘 다 10배)
로그를 취하면:
-> 같은 의미 차이를 동일하게 표현
Word Embeding의 한계
- 동형어, 다의어에 대해서는 제대로 훈련되지 않음
- 단순히 주변 단어만을 고려하므로 문맥을 고려한 의미를 담고 있지는 않음
