FastText
- Word2Vec의 개량 알고리즘으로 Subword를 고려한 알고리즘
- Word2Vec은 하나의 단어에 고유한 벡터를 할당하므로 단어의 형태학적 특징을 반영할 수 없음
Word2Vec의 문제점
1) OOV(Out-of-Vocabulary) 문제
"tensor"와 "flow"가 vocabulary에 있더라고 "tensorflow"가 없다면 벡터값을 얻을 수 없음
2) 형태학적 특징을 반영할 수 없음
eat, eats, eaten, eater, eating - 이 단어들은 eat이라는 동일한 어근을 가진다. 그러나 Word2Vec에서는 각각 벡터를 가질 뿐
n-gram
FastText 단어를 Character 단위의 n-gram으로 간주. n을 몇으로 하느냐에 따라 단어가 얼마나 분리되는지 결정됨
예) eating
1) 단어 eating에 시작과 끝을 의미하는 <와 >를 추가
2) n-gram을 기반으로 단어를 분리

3) n은 주로 범위로 설정해 준다
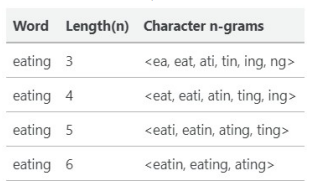
4) word가 아니라 subwords들이 최종 학습 목표이며 이들의 합을 Word의 vector로 간주
Pre-training
I am eating food now 에서 eating을 통해, am 과 food를 예측하기
1) eating과 context word인 am과 food의 내적값에 시그모이드 함수를 지난 값이 1이 되도록 학습
2) eating과 nagativate word인 paris, earth의 내적값에 시그모이드 함수를 지난 값이 0이 되도록 학습

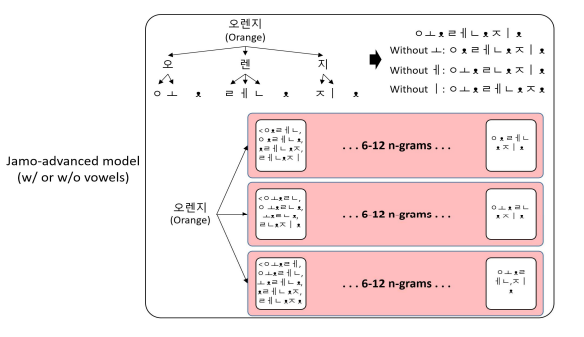
한국어에서의 FastText
한국어는 다양한 용언 형태를 가지며, 다양한 용언들이 Word2Vec의 경우에는 독립된 단어로 표현된다.
이에 대응하기 위해 FastText의 n-gram 단위를 자모 단위(초성, 중성, 종성)으로 하기도 한다.

오랜시간 망설였던 코딩을 다시 해보려고 노력하고 있는 사람