[PAPER REVIEW] How well do LLMs cite relevant medical references? An evaluation framework and analyses
MedicalNLP

**아래에서 사용한 용어 설명!
LLM이 답변을 할 때, 그 답변의 출처를 URL로 같이 출력하도록 실험합니다.
여기서 출력한 URL 내의 내용이 답변의 근거가 된다면 “support”, “support된다”로 작성하였습니다. 또한, 제공한 URL은 ‘source’, ‘URL’로 작성하였습니다.
Summary
LLM이 medical decision making을 할 때, source URL로 그 주장을 입증할 수 있는가? → 없다.
- 유효하지 않은 URL을 제공하는 경우가 많다.
- statement 수준 : statement가 URL의 내용으로 입증될 수 없는 경우가 많다. (GPT-4 RAG의 30%)
- responce 수준 : 전체 응답이 URL의 내용으로 입증될 수 없는 경우가 많다. (전체 응답의 90%가. 해당 응답의 내용의 절반이 support되지 않는다.)
** LLM은 질문에 답변으로 response를 출력하고, 한 response는 여러 개의 statement로 구성되어 있다. URL을 여러 개 제공하는 경우, 그 중 적어도 하나의 URL에서 support하는 내용을 찾을 수 있다면 “입증 가능”한 것이다.
평가를 진행한 Models
five top-performing LLMs : GPT-4 (RAG), GPT-4 (API), Claude v2.1 (API), Mistral Medium (API), and Gemini Pro (API).
Contributions
- SourceCheckup이라는, LLM의 답변을 자동으로 평가하는 framework를 제작했다. 이 프레임워크는 US의사 3명이 평가한 결과, 88%의 정확도(의사들의 agreement)를 가진다.
- SourceCheckup으로 5개의 LLMs에 대해 평가를 진행했다.
→ RAG(access to the Web)이 없는 경우 40~70%는 invalid URL을 출력했다. RAG가 가능한 경우에는 invalid URL을 출력하지는 않았지만, 절반의 경우 답변을 support하지 못하는 source를 출력했다.⇒ LLM의 문제 : 관련없거나 틀린, 답변을 support할 수 없는 URL을 출력한다는 것을 증명 - Medical question과 평가를 위한 전문가의 annotation 데이터셋 제작 및 공개.
Proposed method
SourceCheckup이라는 LLM의 답변을 자동으로 평가하는 framework를 제작.
SourceCheckup의 구조
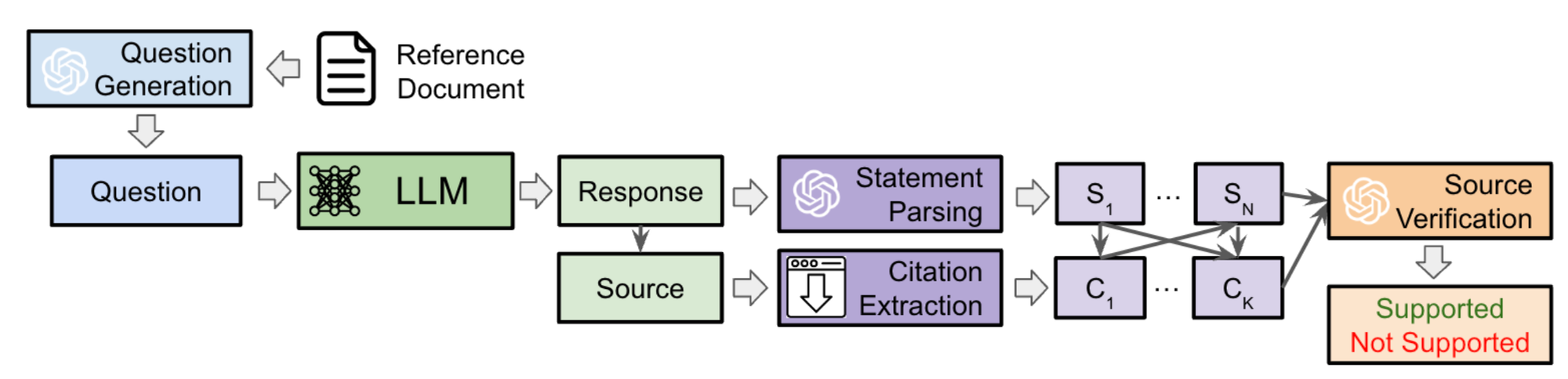
Question Generation → LLM QA → Parsing → Source Verification → (Supported or Not Supported)
1. Question Generation (by GPT-4)
real-world clinical QA를 반영한 질문 리스트 생성.
MayoClinic, UpToDate, Reddit r/AskDocs에 있는 데이터를 사용하여, GPT-4로 질문 생성 (3개의 데이터셋에서 400개의 다른 topic pages, 총 1200개의 reference documents를 사용)
2. LLM Question Answering (by 5 Models)
5개 LLM 모델에 대해 답변과 이를 support하는 URL을 생성하도록 함.
*문서 최하단에 프롬프트 리스트 있음
*모델 : GPT-4 (RAG), GPT-4 (API), Claude v2.1 (API), Mistral Medium (API), Gemini Pro (API).*3. Statement and URL Source Parsing
1) STATEMENT PARSING (by GPT-4)
GPT-4를 사용하여, LLM의 답변이 하나의 정보만을 다루도록 parsing함.
(ex. 남자는 @@하고, 여자는 @@하다.라는 문장을
1. 남자는 @@하다., 2. 여자는 @@하다. 2개의 답변으로 쪼갬)
2) URL SOURCE PARSING
URL에 있는 content를 추출한다.
4. Source Verification (by GPT-4)
GPT-4를 사용하여, LLM의 답변이 source에 의해 support되는지 확인하는 과정.
3가지 metrics로 support 여부를 확인.
- Source URL Validity : “생성된 URL이 valid webpage인지”
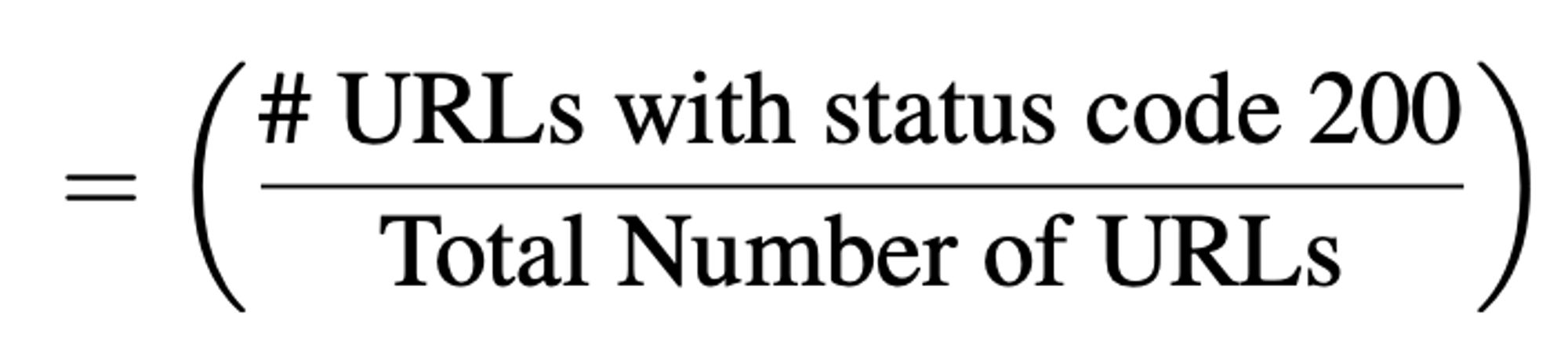
- Statement-level Support : “하나의 문장(사실)이 제공한 source 중 적어도 하나의 source로 뒷받침되는지”의 비율.
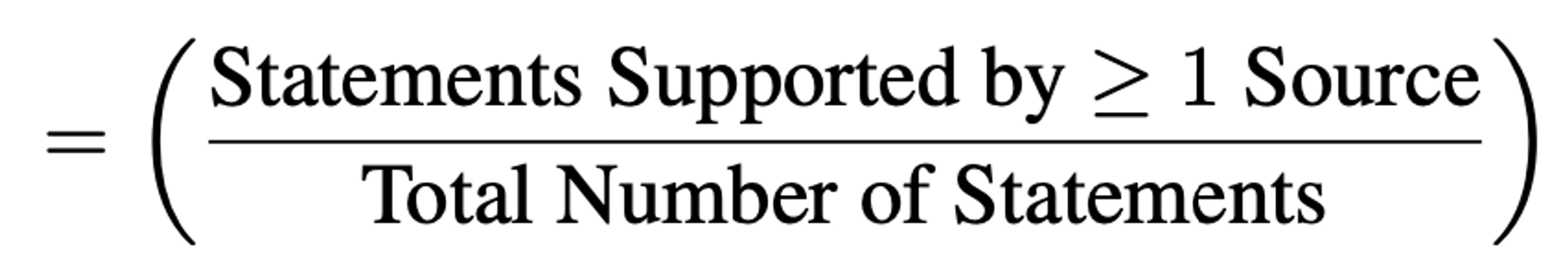
- Response-level Support : “답변의 모든 문장이 제공하는 source로 뒷받침되는지”의 비율
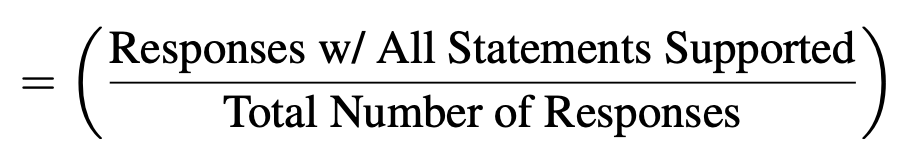
GPT-4를 사용한 Source Verification 결과
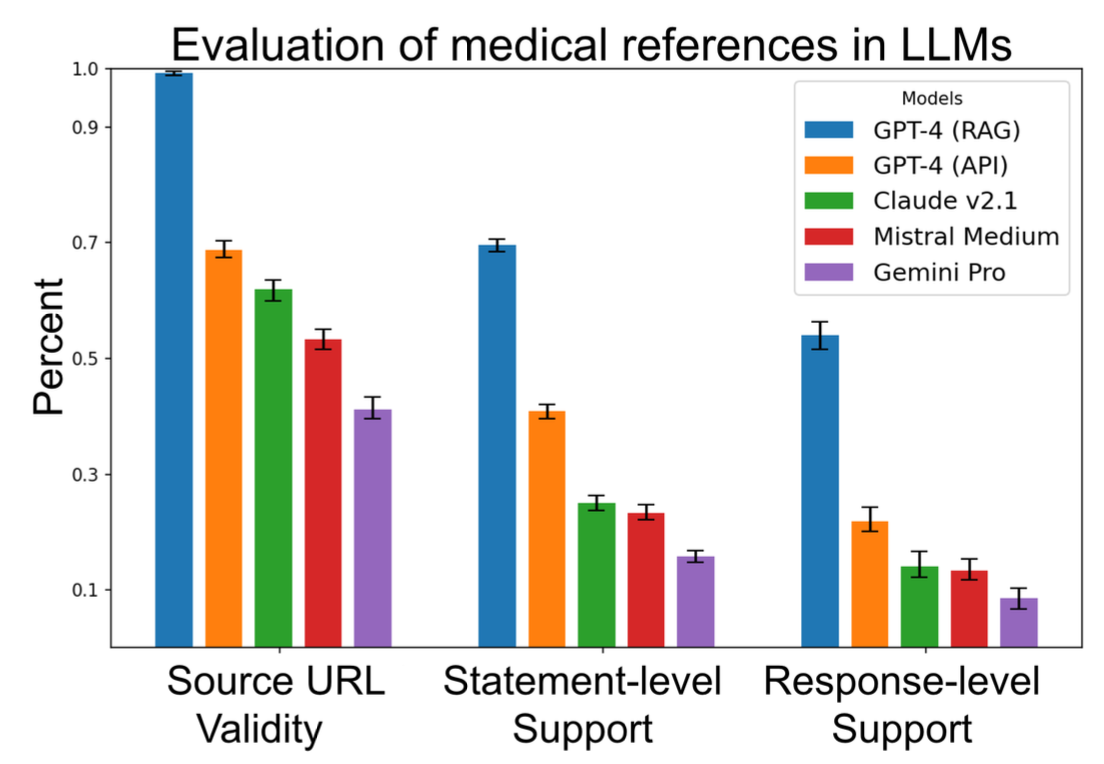

→ “Support”의 수치가 모든 모델에 대해 낮은 편임을 확인할 수 있다.
Expert validation of GPT-4 Automated Tasks
위 framework에서 (1) Question Generation, (3) Parsing, and (4) Source Verification의 과정은 GPT-4로 이루어진다. 논문에서는 3명의 US-licensed practicing medical doctors가 GPT-4의 작업을 평가한다.
- QUESTION GENERATION : 랜덤한 100개의 document-question pair에서 관련성과 논리적 무결성을 평가
→100개 question 모두 reference document와 연관되어 있으며, 답변 가능한 질문이라고 평가. - RESPONSE PARSER : 72개 questions에 대한 답변 내 330 statements에 대해서 평가 (답변에서 statement를 잘 추출해 내었는지를 평가)
→330개 statements 모두 response에서 추출된 것이 맞다고 평가. - SOURCE VERIFICATION : GPT-4가 “source가 statement를 잘 support한다”고 한 평가들(284개)에 대해 의사들이 평가. 랜덤하게 평가에 그 이유를 덧붙이기도 함.
→284개 모두 source verification을 잘 진행한다고 평가. (88%가 모든 의사와 평가모델이 동일 의견)
Prompts
Prompts used for each component of the SourceCheckup evaluation framework. 
RAG의 경우, web search RAG 기능을 사용하게 하기 위해 “Use Bing Search”라는 프롬프트로 명시함.
