last modified 2024.02.13
🤖 https://github.com/StonyBrookNLP/ircot/tree/main
📄 https://arxiv.org/abs/2212.10509
- Extend CoT : question → CoT → 앞선 Q, CoT 통해 새로운 CoT.
- Expand retrieved information : last CoT sentence를 query로 하여 retrieve 진행.
💡[Datasets]
- HotpotQA
- 2WikiMultihopQA
- MuSiQue
- IIRC
💡 [Model] without any training
- Retriever : BM25
- READER
- MAIN : OpenAI GPT3(code-davinci-002)
- SMALLER : Flan-T5 models (11B, 3B, 0.7B)
ReAct와의 비교를 위한 ReAct의 단점 언급 : These steps are much more complex, rely on much larger models (PaLM-540B), and require fine-tuning to outperform CoT for multi-step ODQA. + smaller models without any training에서는 효율적이지 X
[Baseline]
one-step, question-based retrieval
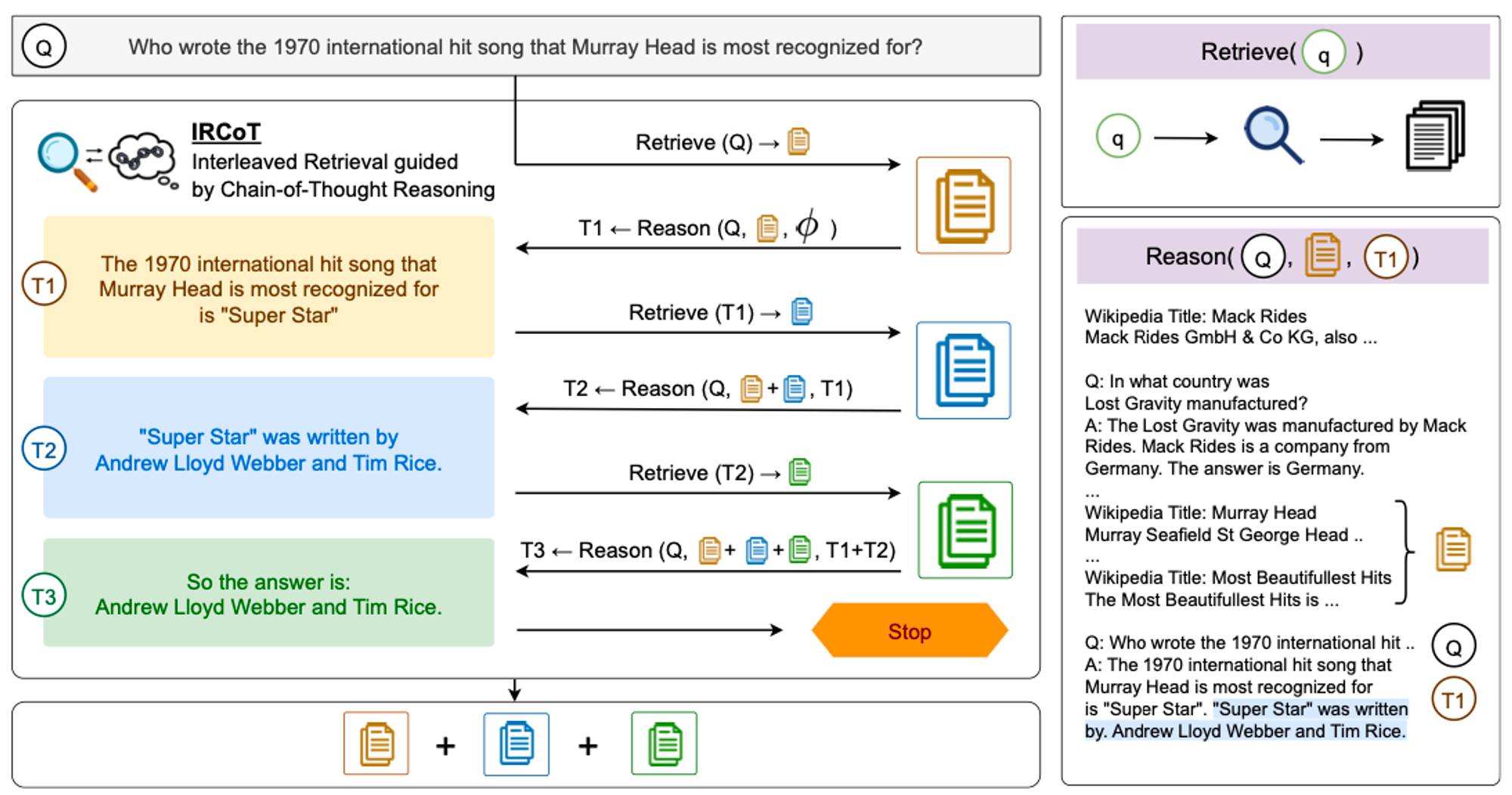
[IRCoT]
1. RETRIEVE STEP : retriever retrieves documents [contribution]
2. READ STEP : QA model reads the retrieved documents and the question → generate the final answer [use standard prompting]
[전체 프로세스]
retrieve K paragraphs → iteration of (reason and retrieve) → termination
RETRIEVE STEP
[ Retrieve ]
-
retriever model : BM25.
- 그 이유 : ODQA를 위해 ‘elastic search’라는 무료 오픈 소스 검색 및 분석 엔진을 사용하는데, 이 엔진이 BM25 기반으로 되어있음.
-
retrieval 과정
-
Question 를 query로 K개의 paragraph를 retrieval.
-
collected paragraphs에 K개의 paragraph 추가.
-
last generated CoT sentence를 query로 K개의 paragraph를 retrieval.
-
collected paragraphs에 K개의 paragraph 추가.
-
3-4번 반복
retrieve 종료 기준: 1) total num of collected paragraphs가 15에 도달했을 경우 2) retrieval 실패 횟수가 기준치(default 9)를 넘어가는 경우
K : 인 hyperparameter.
last generated CoT sentence : + reasoning sentences
-
-
새로 검색한 (title, paragraph)와 누적된 collected (title, paragraph)의 fuzzy ratio을 계산하여 threshold(default 90)보다 작은 경우만 retrieval 결과로 사용 : 중복되는 paragraph의 누적을 방지
[ Reason ]
question , collected paragraphs, generated prior CoT sentences를 통해 generates the next CoT sentence
- reasoning 과정에서는 이전에 사용했던 모든 (retrieve-steps, CoT sentences)를 포함한다.
[PROMPT]
---------------------------------
Wikipedia Title: <Page Title>
<Paragraph Text>
...
Wikipedia Title: <Page Title>
<Paragraph Text>
Q: <Question>
A: <CoT-Sent-1> ... <CoT-Sent-n>** reasoning 종료 기준 : 1) “answer is:”가 존재하는 경우. 2) 최대 step(max=8)에 도달하는 경우
- 기본 decoding parameter
generate( prompt: str, max_input: int = None, max_length: int = 200, min_length: int = 1, do_sample: bool = False, temperature: float = 1.0, top_k: int = 50, top_p: float = 1.0, num_return_sequences: int = 1, repetition_penalty: float = None, length_penalty: float = None, eos_text: str = None, keep_prompt: bool = False, )
GPT-3 generator
class GPT3Generator:
def __init__(
self,
engine="text-davinci-002",
temperature=0,
max_tokens=300,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=["\n"],
retry_after_n_seconds=None,
n=1,
best_of=1,
logprobs=0,
remove_method="first",
):[QA Reader]
IRCoT는 Retriever의 능력을 CoT를 사용하여 향상시키는 것에 집중한다. 따라서 QA Reader의 prompt는 standard한 것을 사용.
- CoT Prompting :
[full generated CoT]
.....??full CoT from scratch
answer is: ... ** 예외 : 생성 문장의 마지막이 “answer is:…”가 아니라면? 전체 generation이 answer가 됨. [Chain-of-Thought annotations for HotpotQA ex - GPT3]
Q: How many episodes were in the South Korean television series in which Ryu Hye−young played Bo−ra?
A: The South Korean television series in which Ryu Hye−young played Bo−ra is Reply 1988. The number of episodes Reply
1988 has is 20. So the answer is: 20.
[Chain-of-Thought prompt ex - Flan-t5]
Q: Answer the following question by reason- ing step-by-step. <actual-question>-
Direct Prompting
Answer field : “A: “
HotpotQA 사용 방법
Convert HotPotQA dataset into SQUAD format
ex.

위의 정제된 hotpotQA를 elasticsearch 로 retrieval 하게 됨. ( elasticsearch 로 dataset, ODQA 모두 retrieve. dataset이 있는 경우, 데이터 내에서 검색하게 됨. )
