LAUGH NOW CRY LATER
날짜: 2024년 10월 28일
URL: https://arxiv.org/pdf/2407.12229
LAUGH NOW CRY LATER: CONTROLLING TIME-VARYING EMOTIONAL STATES OF FLOW-MATCHING-BASED ZERO-SHOT TEXT-TO-SPEECH
타이완 국립대학과 Microsoft Corporation에서 나온 논문
이 논문을 선택한 이유
맡은 한국어 TTS 프로젝트에서 주된 피드백이 “감정이 부족한 것 같다. 조금 더 자연스러운 TTS를 원하는데, 이 자연스러움이 감정에서 오는 것 같다.”였다.
태스크 정의에서 감정 표현은 포함되지는 않기는 했지만, 기존 TTS의 퀄리티를 해치지 않는 범위 내에서 감정을 추가할 수는 없을까 고민하다가 감정 관련 TTS 논문을 찾게 되었다.
Introduction
사람의 실제 발화에서는 톤이 계속 변화하며, non-verbal vocaliztions(NVs, 웃음소리나 울음소리 같은..)이 풍부하다.
그러나 기존의 감정 표현 TTS에서는 아래의 단점들이 존재한다.
- 이러한 감정 표현이 서툴 뿐 아니라,
- 한 문장에는 한 가지의 감정만 들어가게 된다.
- 웃음소리, 울음소리 같은 비언어적인 NVs는 만들지 못한다.
- 제한된 수의 speaker 데이터셋으로 학습되는 경우가 대부분이다. (1명의 화자로 훈련된 TTS도 있음)
- 음성 합성에서 감정을 표현할 때, 해당 화자의 감정 표현만 학습하여, 다양한 화자/감정을 생성하는 데에 어려움
EmoCtrl-TTS
: an emotion-controllable zero-shot TTS system
EmoCtrl-TTS에서는 감정 pseudo-labeling 데이터(27,000시간 이상)를 통해 풍부한 감정을 가지는 zero-shot TTS를 보낸다.
- 대규모 훈련 데이터 사용:
- 약 27,000 시간의 감정적인 데이터를 사용하여 훈련.
- (기존 시스템들은 보통 100시간 이하의 데이터로 훈련)
- 많은 데이터는 모델이 다양한 상황에서 감정을 잘 표현할 수 있도록 도와줌.
- 감정 및 비언어적 표현 동시 생성:
- 텍스트에 있는 내용뿐만 아니라, 감정의 변화를 캐치해서 울음소리나 웃음과 같은 비언어적 표현(NV)도 생성
- 다양한 화자에 대한 적응 능력
- flow-matching 기반 zero-shot TTS : 감정의 시간 가변 특성을 모방하기 위해 "valence"와 "arousal" 값을 활용
→ 표현력과 강인함 업
- 감정조절 zero-shot TTS의 Evaluate Metrics제안
Related Work
Controlling emotion in TTS
- MsEmoTTS
- 음절 수준에서 감정 강도를 예측하여 생성된 음성의 감정 강도를 조절
- ELaTE
- 모든 감정 상태를 완벽하게 제어하지는 못함
- (laugh만 가능)
기존 연구들과의 차이점
- 한 문장에 대해서 세밀한 감정 정보를 컨트롤 가능
- 다양한 NVs를 생성 가능
- 많은 학습 데이터를 사용
- 화자의 수가 많음
- 실제 감정인지/연기 감정인지 → EmoCtrl-TTS는 실제 감정 데이터를 사용(더 자연스럽다고 함)
Flow-matching-based TTS
학습된 음성 데이터의 특성 분포에서 우리가 만들고자 하는 화자의 음성 특성 분포로 변환과정을 학습하는 것.
이 학습된 Flow-matching을 통해 새로운 화자의 스타일로 쉽게 변환이 가능해 지는 것이다.
Conditional flow matching
Continuous Normalizing Flows (CNFs): 연속적인 변환 과정을 통해 데이터 분포를 조정하고 샘플링
- 정확한 데이터 분포로 매핑 가능
- 연속적인 변환을 사용 → 기존의 이산적인 변환과는 다르게, 시간의 흐름에 따라 TTS 생성 가능하도록 하는 요소
- 시간에 따라 감정 상태가 변하는 발화를 생성 가능
Voicebox
2023 Meta https://arxiv.org/pdf/2306.15687
CNFs를 TTS 학습에 가장 먼저 사용한 시스템!
- 음성 컨텍스트와 프레임 단위의 음소 시퀀스를 시간에 따른 condition으로 하여 음성을 생성
- 연속적인 변환(CNFs)을 통해 음소 시퀀스와 시간 정보를 반영 가능하여 자연스러운 음성을 생성할 수 있게 됨
ELaTE
- 자연스러운 웃음 소리를 생성하고 조절하기 위한 시스템
- flow-matching-based zero-shot TTS로, 프레임 수준의 웃음을 표현
- 그러나 다양한 감정 상태들 중, 웃음만 표현 가능
- 울음소리 등의 NVs가 필요한 상황에서도 웃음 소리만 나타나는 경향이 있음
Method
EmoCtrl-TTS
모델 구조
- 기본적으로 Voicebox의 구조를 따름 CNFs를 TTS 학습에 가장 먼저 사용한 시스템!
- 용어 Audio sample
sTranscription(Text)yMel-filterbank$\hat{s}$← 프레임 단위 Mel-filterbank-
F: Feature Dimension -
T: Sequence length -
멜 스케일에 기반하여 설계된 필터뱅크
-
즉, 각 음성 샘플에서 F개의 Mel-Spectrogram 특징 X 시간 프레임 수 = 시간 길이에 대한 멜스펙트로그램(특징) 개념
Phoneme Embedding
$a$← 프레임 단위 음소 임베딩 -
$D^{phn}$: Phoneme embedding dimensionNV
$h$← 프레임 단위 비언어적 소리 임베딩 -
$D^{NV}$: dimensions of NVemotion
$e$← 프레임 단위 비언어적 소리 임베딩 -
$D^{emo}$: dimensions of emotion embeddings
-
[Model training]
- 오디오와 텍스트 쌍의 데이터셋에서
- Mel-spectrogram에 기반한 Mel-Filterbank를 생성하고, (멜 스케일 버전의 주파수 대역 필터)
- text-audio force alignment와 phoneme(음소) 임베딩 레이어를 사용하여 프레임 단위의 음소 임베딩을 추출 (함께 학습)
- NV와 emotion 정보를 pre-train된 각각의 detector로 추출
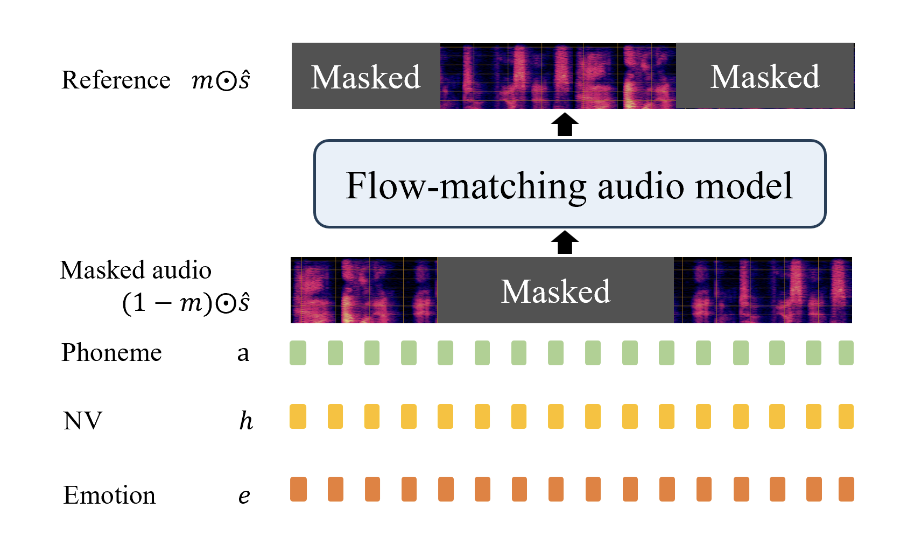
- 위 정보들을 사용하여 speech infilling task을 통해 오디오 모델을 학습 → 마스킹 처리된 부분의 Mel-spectrogram을 채우도록!
- conditional flow-matching model을 학습하여
- distribution 를 estimate하는 것!
- : 이진 시계열 마스크
- 는 하다마드 곱
- 활성화된(마스킹처리되지 않은) 부분의 phoneme, NV, emotion을 통해 마스킹 처리된 부분의 Mel-filterbank(음성)을 생성하도록 학습하는 것
- → 정확한 음소 align된 NV와 감정 표현 가능한 TTS의 학습
[Inference]
Input: 한 개의 텍스트 프롬프트와 세 개의 오디오 프롬프트
- text prompt
- speaker prompt audio
- NV prompt audio
- emotion prompt audio
위 2~4번이 각각 화자 특징/NV/감정을 조절하는 파라미터
*) speech-to-speech translation scenario
입력이 , , 와 번역된 로 들어가게 됨
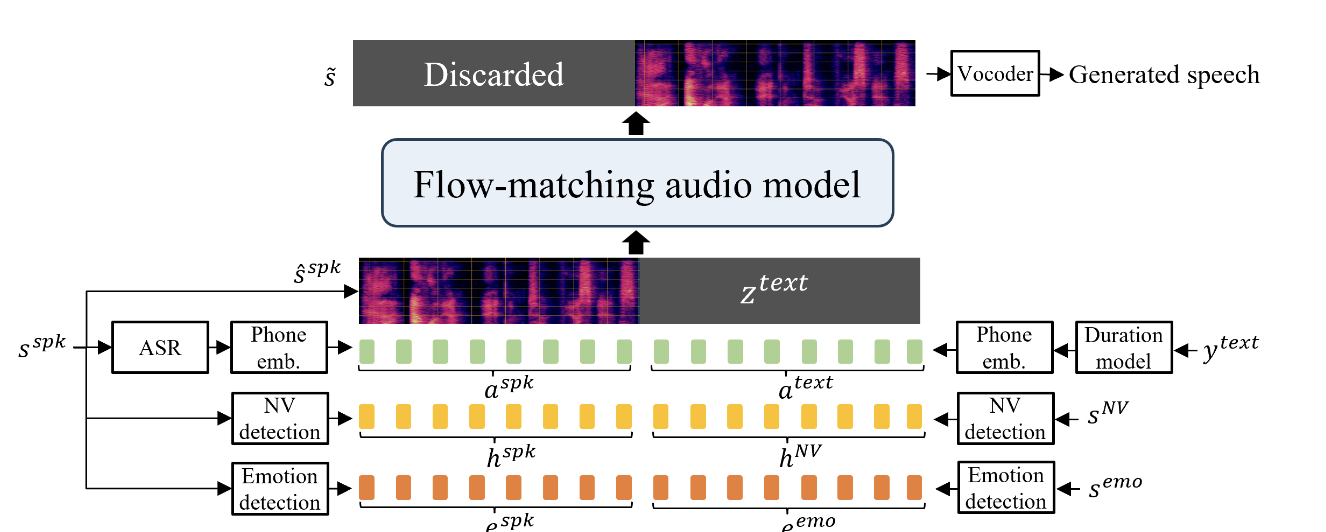
Inference 단계: 텍스트 프롬프트, 화자 음성, 감정 샘플, NV 샘플을 입력으로 받아 해당 화자의 감정과 음성을 유지하며 음성을 생성합니다.
- 입력된 텍스트 프롬프트()는
- phone duration model을 통해 음소가 발음되는 시간과 텍스트를 align
- 음소 임베딩 레이어을 통과
- 텍스트 프롬프트 임베딩()으로 변환
- 입력된 화자 프롬프트 음성()은
- Mel-filterbank features()로 변환됨
- ASR(자동 음성 인식)→ 음소 임베딩 레이어를 거쳐 음소 임베딩() 추출
: 화자의 톤과 억양 패턴등을 더 잘 모사하기 위해 음소 임베딩 추출이 필요함 - NV detector를 거쳐 NV 임베딩() 추출
- 감정 detector를 거쳐 감정 임베딩() 추출
- 입력된 NV 프롬프트 음성()은
- NV detector를 거쳐 NV 임베딩()으로 변환
- 입력된 감정 프롬프트 음성()은
- 감정 detector를 거쳐 감정 임베딩()으로 변환
- 와 , 는 linear interpolation을 통해 모두 같은 길이(기준)로 맞춰짐
- figure의 왼쪽과 오른쪽이 concat된 상태로 mel-filterbank features인 를 generate
- 는 all-zero matrix.
- vocoder를 통해 음성으로 변환
NV embeddings
ELaTE라는 모델에서 사용한 웃음 임베딩이 웃음 뿐만 아니라 더 넓은 범위의 NV 유형을 포함함
→ NV 임베딩으로 웃음 감지 모델에서 추출한 32차원 임베딩을 사용하여, 울음이나 신음 같은 다양한 NV를 생성!
Emotion embeddings
Russell’s circumplex model of emotion에 따르면,
- 감정은 행복과 슬픔같은 서로 다른 감정 상태로 분류된다. → distinct emotional states를 반영!
- 감정은 arousal과 valence라는 두 가지 속성으로 설명된다. 때때로는 dominance라는 세 번째 속성이 추가된다.
- Arousal: 감정의 강도 또는 활성화 수준을 나타내는 “각성”. ( 차분한 상태 ~ 매우 자극된 상태) 까지의 범위
- Valence: 감정이 얼마나 즐겁거나 불쾌한지를 나타내는 “유쾌감”. ( 매우 긍정 ~ 매우 부정 )까지의 범위
- Dominance: 감정에 대한 통제력을 얼마나 느끼는지를 다루는 “지배성”.
[arousal과 valence을 추출하는 방법]
pre-trained arousal-valence-dominance extractor를 사용
- wav2vec 2 model로 초기화, MSP-PODCAST data로 파인튜닝된 모델
- arousal, valence, dominance를 예측하는 데 사용
- 청크별 arousal-valence values는 0.5초의 window size, 0.25초의 hop size의 슬라이딩 윈도우로 추출됨.
Experiments
Data
학습 데이터
- Libri-light: 60K 시간 분량의 영어 오디오 데이터
- NV와 감정의 임베딩이 없는 오디오북 데이터
- pre-training 할 때 사용한 데이터
- 모델의 성능을 향상시키기 위해 파인튜닝 중 일정 확률로 사용
- pre-trained Kaldi ASR model로 transcription을 생성 (STT)
- In-house Emotion Data (IH-EMO): 200K 시간 분량의 영어 오디오 데이터 → 27K 시간 분량 선별
- Collecting large-scale emotional data with pseudo-labeling
- 모델을 파인튜닝할 때 사용한 데이터
- 데이터 큐레이션 절차
- emotion2vec 모델로 emotion confidence score을 예측 → confidence가 1.0인 샘플만 유지
- 예측된 감정이 {angry, disgusted, fearful, sad, surprised} 와 {neutral, happy} 중 어디에 속하는지 분류
- DNSMOS(Clarity, naturalness, consistency, overall quality..)를 적용하여 OVLR 점수가 3.0 이상인 샘플만 유지
- 최종 선별된 27K 시간 음성에 대해서 pre-trained Kaldi ASR model로 transcription을 생성 (STT)
- LAUGH: 460 시간 분량의 웃음 소리가 포함된 발화 음성 데이터
- 모델을 파인튜닝할 때 사용한 데이터
평가 데이터
-
JVNV speech-to-speech translation (S2ST)
- emotion transferability를 평가하기 위해, S2ST 데이터(번역과 STS를 동시에 진행하는 데이터)를 사용 TTS 모델의 감정 전이 가능성을 평가하기 위해 speech-to-speech translation (s2st) 데이터를 사용하는 이유: 실제 응용 시나리오 반영: TTS 기술은 실제로 음성의 감정을 유지하면서 텍스트를 음성으로 변환해야 하는 애플리케이션에서 자주 사용됩니다. s2st는 이러한 상황을 잘 반영하므로 감정 전이 능력을 평가하기에 적합합니다. 감정 전달의 중요성: speech-to-speech translation 시나리오에서는 번역된 음성이 원본 음성과 유사한 감정적 특성을 유지해야 합니다. 따라서 감정 전이 능력을 테스트하는 데 있어 실제 감정 변화를 모니터링할 수 있는 좋은 방법입니다. 다양한 감정 상태 표현: s2st 데이터는 다양한 감정 상태를 포함한 음성을 다루기 때문에, 모델이 감정의 복잡성과 시간 변화를 잘 분리하고 유지하고 있는지를 평가할 수 있습니다. 제한된 스피커 세트의 문제 해결: TTS 모델 평가 시 단순히 음성과 텍스트만 사용하는 경우, 모델이 훈련된 특정 스피커에 묶일 수 있습니다. 그러나 s2st는 다양한 스피커로부터 유래한 오디오를 다루기 때문에 모델의 일반화 능력을 더 효과적으로 평가할 수 있습니다. 비언어적 요소 포함: TTS에서는 비언어적 vocalizations(예: 웃음, 울음) 표현이 중요하지만, 단순 텍스트-투-스피치에서 이들을 정확히 평가하기 어렵습니다. s2st 데이터는 이러한 비언어적 요소들이 포함된 실제 감정 표현을 기반으로 평가할 수 있어 더 정밀한 테스트가 가능합니다. 결론적으로, s2st 데이터를 사용함으로써 EmoCtrl-TTS와 같은 모델의 감정 전이 능력을 보다 실제적이고 효과적으로 평가할 수 있습니다.
일본어 → 영어를 위한 S2ST 데이터로 JVNV corpus 사용
- 4명(남2, 여2)의 일본어 화자가 6가지 감정(anger, disgust, fear, happiness, sadness, surprise)를 표현하는 음성 데이터
- 일본어 음성을 STT(Whisper large-v3 model)한 후, 영어로 번역(GPT-4)
- a total-duration-aware (TDA) duration model을 사용하여 프레임별 음소 alignment를 맞춤
- EmoCtrl-TTS의 입력으로 (영어로 번역된 텍스트, 감정을 포함하는 JVNV 일본어 음성과 여기에서 추출한 NV 임베딩과 감정 임베딩)
- emotion transferability를 평가하기 위해, S2ST 데이터(번역과 STS를 동시에 진행하는 데이터)를 사용 TTS 모델의 감정 전이 가능성을 평가하기 위해 speech-to-speech translation (s2st) 데이터를 사용하는 이유: 실제 응용 시나리오 반영: TTS 기술은 실제로 음성의 감정을 유지하면서 텍스트를 음성으로 변환해야 하는 애플리케이션에서 자주 사용됩니다. s2st는 이러한 상황을 잘 반영하므로 감정 전이 능력을 평가하기에 적합합니다. 감정 전달의 중요성: speech-to-speech translation 시나리오에서는 번역된 음성이 원본 음성과 유사한 감정적 특성을 유지해야 합니다. 따라서 감정 전이 능력을 테스트하는 데 있어 실제 감정 변화를 모니터링할 수 있는 좋은 방법입니다. 다양한 감정 상태 표현: s2st 데이터는 다양한 감정 상태를 포함한 음성을 다루기 때문에, 모델이 감정의 복잡성과 시간 변화를 잘 분리하고 유지하고 있는지를 평가할 수 있습니다. 제한된 스피커 세트의 문제 해결: TTS 모델 평가 시 단순히 음성과 텍스트만 사용하는 경우, 모델이 훈련된 특정 스피커에 묶일 수 있습니다. 그러나 s2st는 다양한 스피커로부터 유래한 오디오를 다루기 때문에 모델의 일반화 능력을 더 효과적으로 평가할 수 있습니다. 비언어적 요소 포함: TTS에서는 비언어적 vocalizations(예: 웃음, 울음) 표현이 중요하지만, 단순 텍스트-투-스피치에서 이들을 정확히 평가하기 어렵습니다. s2st 데이터는 이러한 비언어적 요소들이 포함된 실제 감정 표현을 기반으로 평가할 수 있어 더 정밀한 테스트가 가능합니다. 결론적으로, s2st 데이터를 사용함으로써 EmoCtrl-TTS와 같은 모델의 감정 전이 능력을 보다 실제적이고 효과적으로 평가할 수 있습니다.
-
EMO-change
- 모델의 세밀한 감정 생성을 평가하기 위해 RAVDESS 데이터셋으로 만든 데이터셋
- calm, happy, sad, angry, fearful, surprised, and disgusted의 감정을 표현하는 영어 감정 발화 데이터
- 2 문장을 앞뒤로 concat하는데, 두 문장이 서로 다른 감정을 가지도록 처리 (앞은 happy, 뒤는 sad같이)
- 동일한 텍스트와 동일한 오디오 프롬프트를 주었을 때, 변화하는 감정들을 잘 모방할 수 있는지 테스트
-
Laughter-test
- 웃음 음성 생성을 평가하기 위해 만든 S2ST 데이터를 사용 (ELaTE에서 사용한 데이터)
- DiariST-AliMeeting에서 웃음을 포함하는 154개의 중국어 발화를 사용
- 중국어 음성을 STT한 후, 영어로 번역하여 텍스트 프롬프트로 사용
- a total-duration-aware (TDA) duration model을 사용하여 프레임별 음소 alignment를 맞춤
- 웃음을 포함하는 중국어 음성을 오디오 프롬프트로, 여기서 추출한 NV 임베딩과 감정 임베딩을 각각의 프롬프트로 사용
-
Crying-test
- 울음소리 생성을 평가하기 위해 만든 중국어-영어 S2ST 데이터셋을 만들어 사용
- (ELaTE와 동일하게 제작)
Evaluation metrics
[Objective evaluation metrics]
-
Word error rate (WER)
Whisper-Large를 사용하여 생성된 오디오의 WER를 계산. (백분율로 표현)
-
Speaker SIM-o
생성된 음성과, 입력된 오디오 프롬프트(화자 특징)가 얼마나 유사하는지 → 화자 임베딩 간의 코사인 유사도를 계산 및 평균
microsoft의 WavLM-large-based speaker verification model사용
-
Aro-Val SIM
시간에 따라 변하는 감정 상태의 유사성을 평가
생성 음성과 입력 오디오 프롬프트 각각의 arousal-valence values를 각 프레임 별로 계산한 후, 코사인 유사도를 계산 및 평균
[Subjective evaluation metrics]
- SMOS(Speaker similarity mean opinion score)
- 화자 프롬프트 음성과 생성된 음성의 화자 특징 유사성을 1(전혀 유사하지 않음)부터 5(매우 유사함)까지 평가
- NMOS(Naturalness MOS)
- 생성된 음성이 얼마나 자연스러운지를 1(전혀 자연스럽지 않음)부터 5(매우 자연스러움)까지 평가
- EMOS (Emotion MOS)
- 감정 프롬프트 음성과 생성된 음성의 화자 특징 유사성을 1(전혀 유사하지 않음)부터 5(매우 유사함)까지 평가
Model configuration
- Voicebox와 유사한 구조
- Libri-light 데이터로 pre-train되어 기본 모델인 Voicebox의 성능을 reproduction.
- 390K steps 학습, mini-batch size of 307,200 audio frame
- linear-decay learning rate scheduler with a peak learning rate at 7.5e-5
- 20K steps of linear warmup
- combining Libri-light, LAUGH, and IH-EMO으로 파인튜닝
- 40K steps 학습, mini-batch size was set to 307,200 audio frames
- A linear-decay learning rate scheduler was used with a peak learning rate of 7.5e-5
- MelGAN-based vocoder 로 음성 생성
Results and discussion
- [Objective evaluation]
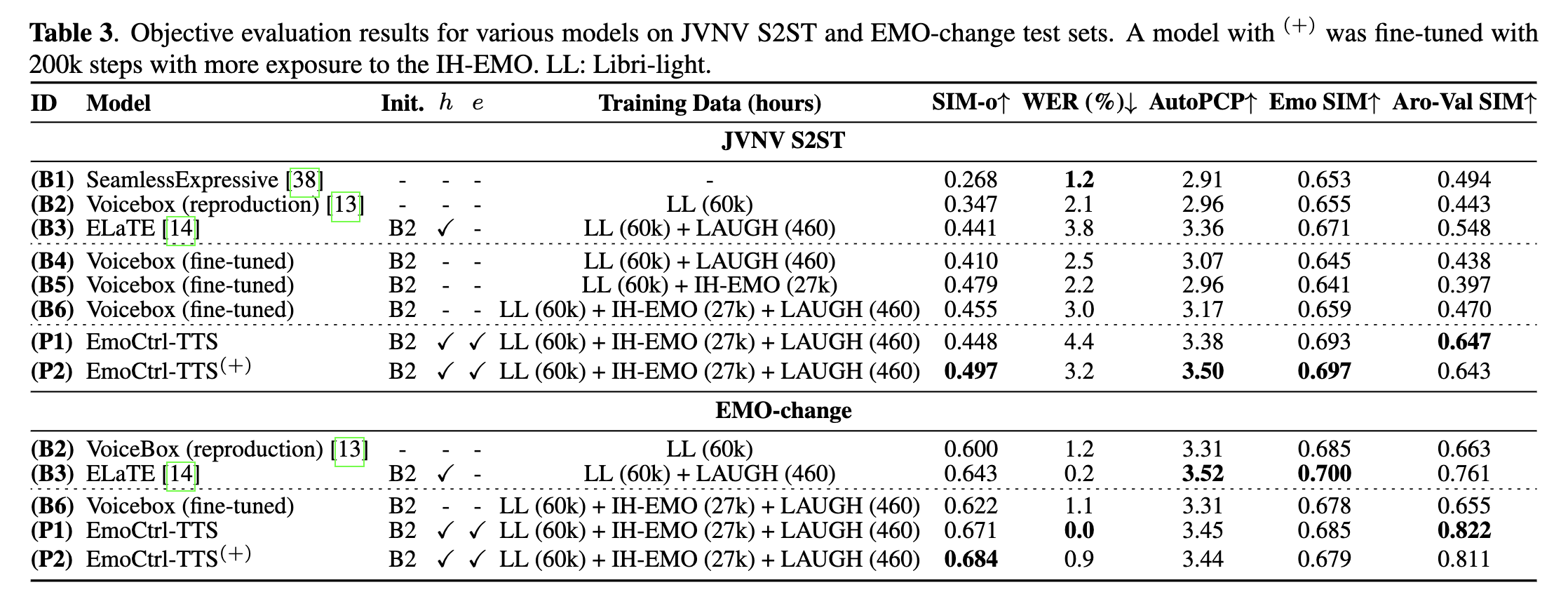
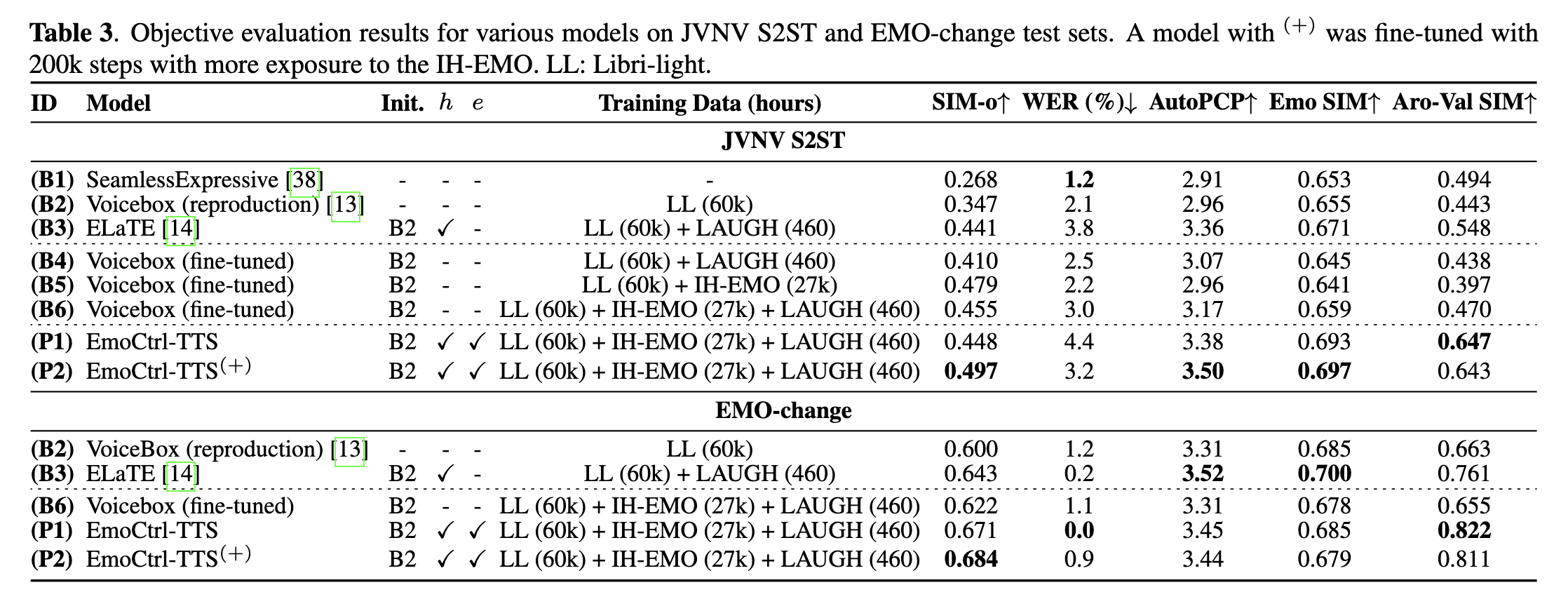
- B2와 B4,B5,B6의 비교
- Voicebox를 LAUGH 데이터셋, IH-EMO로 파인튜닝하며 다양한 메트릭에서 더 좋은 성능을 보임
- 그러나, Voicebox를 파인튜닝해도, ELaTE보다 좋은 성능을 보이지는 못함
→ 단순히 감정 데이터를 추가하는 것이 emotion transferability를 향상시키는 것은 아니다!
**EmoCtrl-TTS**은 baseline보다 더 개선된 성능. 추가 파인튜닝을 진행했을 때, 성능이 더 향상됨
→ NV와 감정 임베딩을 사용함으로서 emotion transferability가 향상됨!-
[Subjective evaluation]
JVNV S2ST 데이터 24샘플과 EMO-change 데이터 28개 샘플을 무작위로 추출하여 원어민 영어 테스터가 평가
- SMOS는 9명, NMOS는 11명, EMOS는 10명의 테스터가 평가 / EMO-change는 모두 12명 테스터가 평가
- SMOS는 9명, NMOS는 11명, EMOS는 10명의 테스터가 평가 / EMO-change는 모두 12명 테스터가 평가
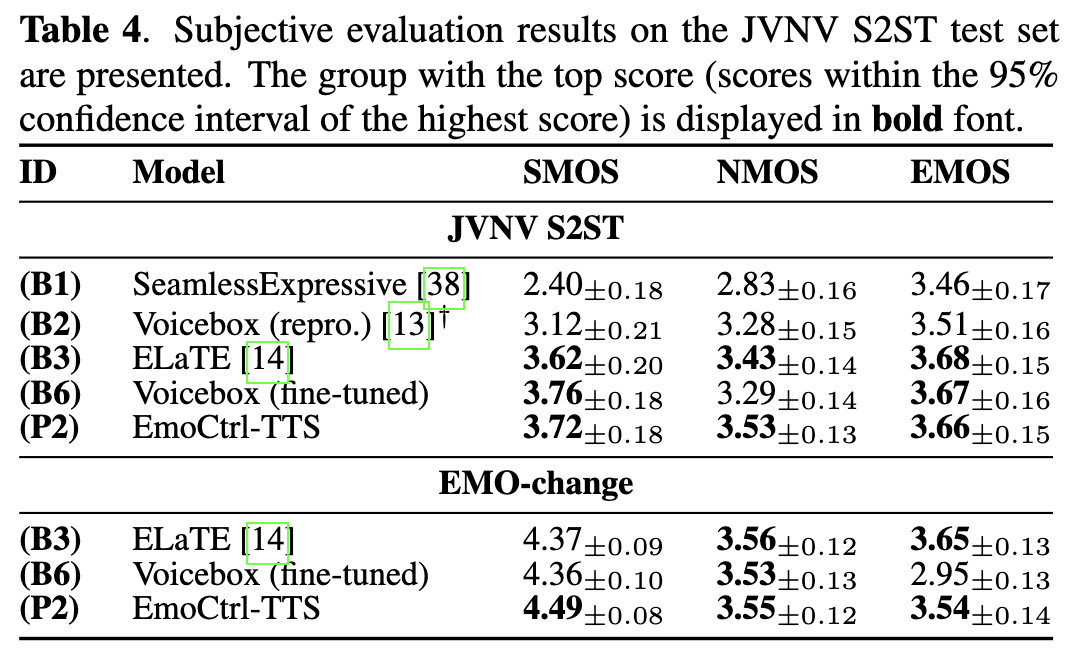
- Voicebox : 감정 포함 데이터로 파인튜닝되었을 때 성능 개선.
- EMOS(감정유사도)가 낮음 → 파인튜닝만으로는 시간에 따라 변동되는 감정 상태를 모방하기 어렵다는 것
- ELaTE : NMOS(자연스러움)에서 뛰어난 성능 → 웃음 소리가 들어가면서 자연스러움을 향상
- EmoCtrl-TTS: 세 가지 메트릭에서 모두 높은 점수- Results of Laughter-test & Crying-test dataset
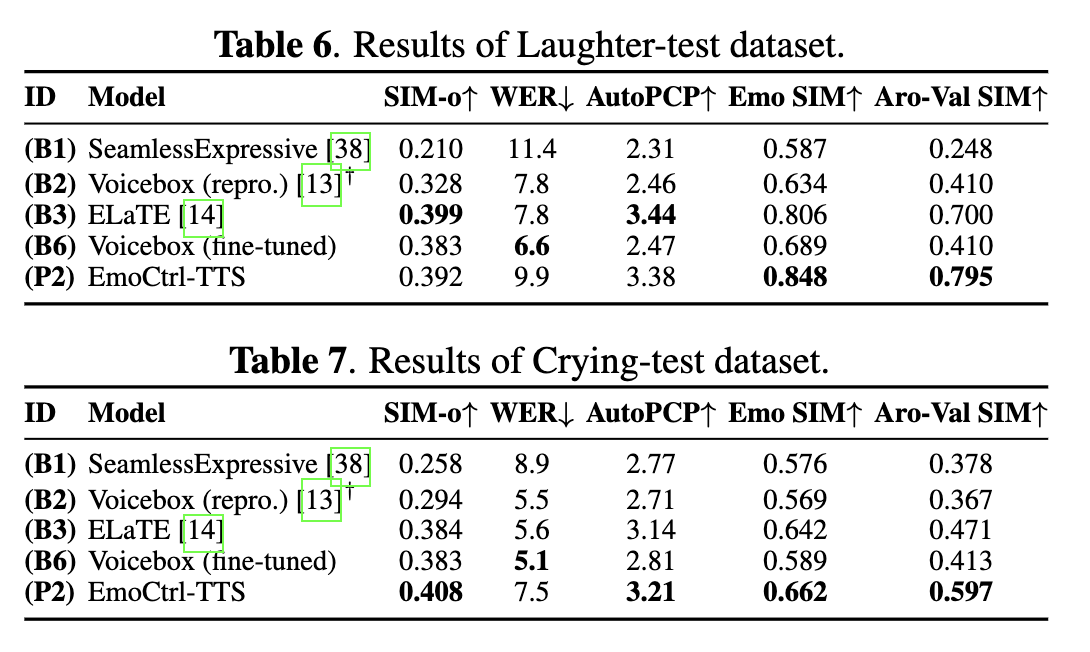
- EmoCtrl-TTS는 WER에서는 약간의 성능저하가 있지만 다른 감정관련 메트릭에서 좋은 성능을 보임Demo
https://www.microsoft.com/en-us/research/project/emoctrl-tts/
- EmoCtrl-TTS 모델은 입력받은 음성의 감정을 모방할 수 있다라는 것이 가장 큰 특징이다
- 그런데 프로젝트 필요한 기술은 감정을 모방하는 것이 아니라, 텍스트에서 감정을 분석해서 음성에 적용하는 것이다.
- EmoCtrl-TTS 모델이 오디오펍에 사용되기는 어려워보이나,
- (학습 코드/체크포인트도 없고, evaluate하는 코드만 있음)
- 나중에 감정을 모방하고, 다른 언어로 변역된 TTS가 필요한 경우 사용할 수 있을 것 같다.
- 그런데, 논문을 읽어보니 굳이 NVs가 필요한 것이 아니라면, Voicebox로 사용하는 것도 좋아보임
