Introduction
대부분의 zero-shot multi-speaker TTS(ZS-TTS) 시스템은 한 가지 언어에 대한 TTS만 지원하고 있다.
YourTTS, VALLE X, Mega-TTS 2, Voicbox같은 대표적인 Multilingual ZS-TTS 조차도 몇몇 개의 high/medium source language에만 적용가능하다는 한계가 있다. 즉, 지원하는 언어도 적을 뿐 아니라, 잘하는 언어만 잘한다는 것!
high/medium/low source language :
NLP, 음성 모델 학습을 위해 얼마나 많은 자원이 마련되어있는지에 따라 High, medium, low로 나뉨.
영어/서유럽 언어에 비해 아시아/아프리카 언어는 대부분 데이터가 부족 → medium/low resource language에 해당.
이에 따라 TTS 모델이 해당 언어를 얼마나 잘 처리할 수 있는지도 High, medium, low로 나뉨.
(발음과 억양, 문법적 요소나 특정 표현들로 고려)
XTTS는 이러한 문제를 해결하기 위해 제안된 1. 16개 언어를 지원하는, 2. 높은 성능의 voice cloning도 동시에 진행 가능한 3. 빠른 학습과 추론이 가능한 TTS 모델이다.
Related Work
대부분의 ZS-TTS 모델은 하나의 언어를 지원하고 있었다. 아래는 대표적인 multilingual ZS-TTS들
[YourTTS] → 3개 언어 지원 | ❌한국어 지원❌
처음 등장한 multilingual ZS-TTS model
- VITS 모델 구조 기반
- 영어 - 1k speakers, 프랑스어 - 5 speakers, 포르투갈어 - 1 speaker
- 영어에 대해서 SOTA 성능 도달, 프랑스어/포르투갈어도 좋은 성능
- cross-lingual TTS를 통해 native accent를 보임
- 적은 speaker로도(low-resource scenario에서도) 음성 합성이 가능
💡
Cross-lingual TTS란?
한 언어로 훈련되었지만, 다른 언어의 음성을 생성할 수 있는 기능을 가진 TTS.
즉, A 언어를 사용하는 화자의 목소리로 B 언어의 음성을 합성하는 것.
대표적으로 YourTTS에서 사용.
Cross-lingual TTS가 가능한 이유는?
1. 여러 언어에서 사용되는 공통적인 음소/발음 패턴을 기반으로 학습
→ 언어들의 차이를 이해하고, 언어들간에 필요한 변환을 수행하여서 다른 언어로의 자연스러운 변환 가능!
2. 언어 식별 후, 인식
입력된 텍스트의 언어를 식별하고, 그 언어에 맞게 발음 규칙을 적용함.
→ 타겟 언어에 대해 native accent를 구현 가능하게 됨
[VALL-E X] → 2개 언어 지원 | ❌한국어 지원❌
- VALL-E 구조 기반 + multilingual TTS + speech-to-speech 번역
- cross-lingual TTS로, 타겟 언어에 대해 자연스러운 억양 가능
[Mega-TTS 2] → 2개 언어 지원 | ❌한국어 지원❌
- 임의 길이의 음성 프롬프트 처리가 가능!
- 38k 시간의 multi-domain, 영어/중국어 언어-balanced speech
- 짧은 프롬프트에 대해서 SOTA 성능 도달, 긴 프롬프트에 대해서도 좋은 성능.
[Voicebox] → 6개 언어 지원 | ❌한국어 지원❌
- 비자기회귀(Non-autoregressive) 모델
- 과거/미래의 맥락을 파악 가능
- 6개 언어 데이터셋으로 학습(English, French, German, Spanish, Polish, and Portuguese)
- cross-lingual ZS-TTS에서 SOTA 성능 도달
[XTTS] → 16개 언어 지원 | ⭕한국어 지원⭕
- 16개 언어에 대해 multilingual ZS-TTS 가능 + SOTA 성능 달성!
- medium/low resource language를 지원하는 것이 가장 큰 특징!
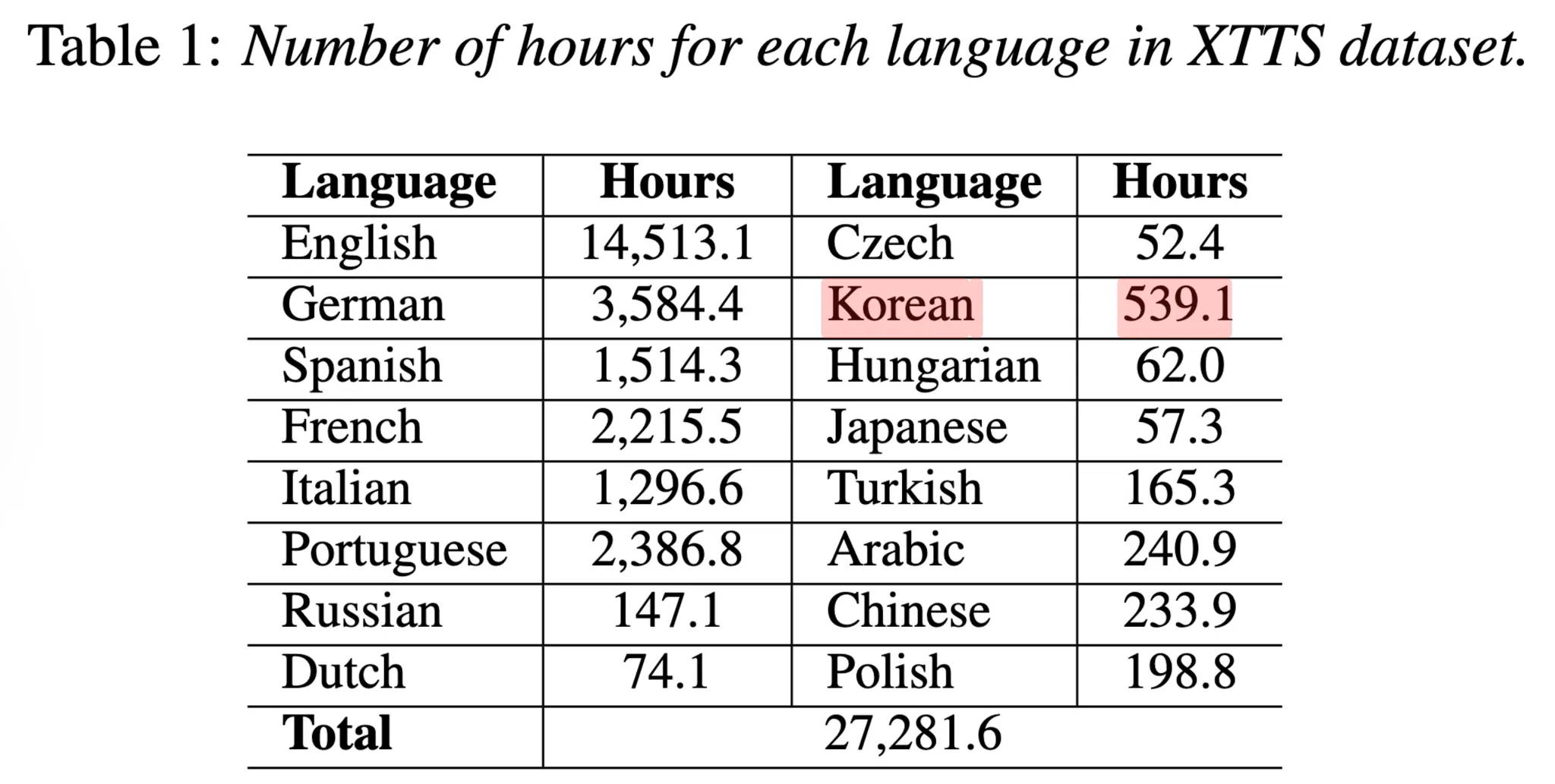
- 영어, 스페인어, 프랑스어, 독일어, 이탈리아어, 포르투갈어, 폴란드어, 터키어, 러시아어, 네덜란드어, 체코어, 아랍어, 중국어, 헝가리어, 한국어, 일본어
- 병렬 학습 데이터셋 없이도 cross-language ZS-TTS가 가능!
- 모델 체크포인트와 코드, 데모를 모두 오픈소스로 공개! → Coqui-ai TTS 깃허브에서 쉽게 사용가능
Method
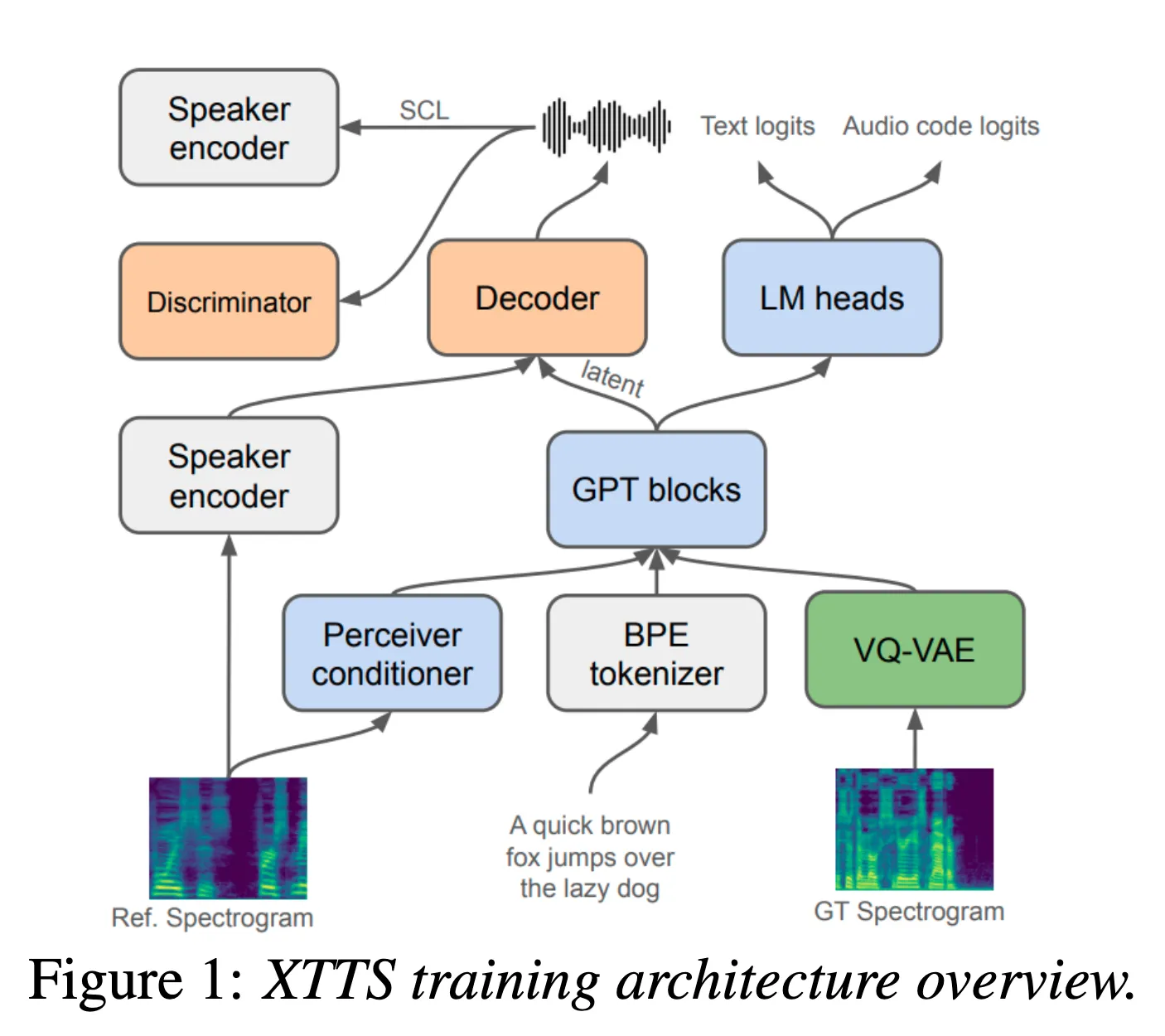
XTTS 모델은 Tortoise 모델을 기반으로 하며, 3가지의 대표적인 component들로 구성되어있다.
🐢
[TorToiSe TTS]
- Autoregressive Decoder를 기반으로 한 TTS. voice cloning 능력도 가지고 있음!
- 음성 → diffusion model → melspectrogram → … → Univnet vocoder → 음성
- BPE : 256토큰 BPE 사전을 사용하여 입력 텍스트를 토큰화.
- GPT-2 인코더 모델 사용
- VQ-VAE: 음성 데이터 압축의 역할.
- 미리 학습된 코드북을 통해 음성 데이터를 강제로 양자화.(이산적인 형태로 인코딩)
- 압축된 음성데이터를 토큰으로 변환하게 됨.
- 22kHz로 샘플링된 음성 데이터 →(256배 압축)→ Mel-spectrogram → VQ-VAE(4배 압축) → 1024배 압축된 음성 데이터.(트랜스포머 적용 가능)
- 단점: 매우 느림! (parallel TTS인 VITS에 비해)
- 장점: 정확도↑ 자연스러움↑
VQ-VAE
Vector Quantized-Variational AutoEncoder
Mel-spectrogram → VQ-VAE(벡터 양자화를 통해 압축하는 인코딩 진행) → 코드북
- Mel-spectrogram을 입력으로 받아 각 프레임을 1개의 codebook으로 인코딩하는 역할.
- 즉, Mel-spectrogram을 음성 신호의 특징으로 변환하는 역할.
- 이렇게 생성된 음성 인코딩(코드북과 매칭된)은 추후 GPT-2에 조건으로 입력됨.
- 13M의 파라미터를 가짐.
💡
VQ-VAE란?: “VQ-VAE: Neural Discrete Representation Learning” 논문에서 등장한 개념.
VAE: 일반적인 오토인코더 구조를 따르며, 입력 데이터를 낮은 차원의 잠재 공간으로 인코딩하고 다시 원래 데이터로 복원하는 방식.
VQ벡터 양자화: 입력 데이터를 보다 의미있게 인코딩. 잠재공간에서 discrete 코드를 사용하여 데이터의 표현을 생성.사전에서 학습된 여러 벡터 중 하나로 데이터를 근사하는데 사용.
VQ-VAE: 전통적인 VAE와는 달리 확률 분포를 직접적으로 다루지 않고, 최적화 과정에서 이산적인 코드 선택을 통해 데이터를 생성. → 더 간단한 학습 구조, 더 나은 생성 품질.
[XTTS VQ-VAE의 codebook]
- 8192개의 코드로 구성 Mel spectrogram을 처리하기 위해 작은 residual convolutional network를 통해 spectrogram을 4배 압축하고 8192개의 토큰으로 구성된 코드북을 생성
- 프레임 속도는 21.53Hz로 설정
- VQ-VAE의 학습 후에, 코드북을 필터링하여 가장 많이 사용되는 1024개의 코드만 남기게 됨.
- 덜 자주 사용되는 코드를 필터링함으로서, 모델의 표현력을 향상시킬 수 있음
Encoder
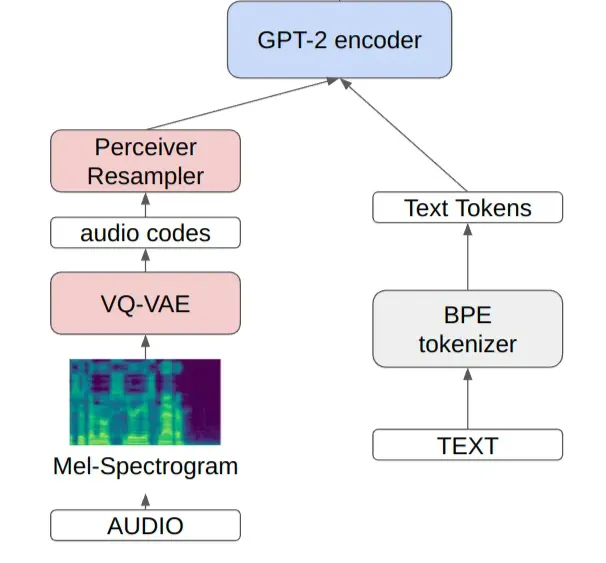
XTTS는 decoder-only transformer인 GPT-2 encoder를 사용
Byte-Pair Encoding(BPE)방식으로 텍스트가 토큰화되고, 이 텍스트 토큰이 GPT-2 encoder에서 VQ-VAE audio code를 예측하게 됨.
텍스트 → BPE tokenizer → (6681 token) → GPT-2 encoder → next audio latent vector
💡 Byte-Pair Encoding(BPE)
텍스트를 문장, 단어, 음소 등의 기준으로 나눔.
XTTS에서는 6681개의 고유한 토큰을 사용
다른 토크나이저 대신 BPE를 사용하는 이유?
다양한 언어와 다양한 음성 데이터에 효과적으로 대응하기 위해!
이때, GPT-2 encoder는 conditioning encoder로 condition됨.
-
perceiver resampler
mel-spectrogram을 입력으로 받아 각 오디오 샘플에 대해 32개의 1024-D 임베딩을 생성
(입력의 길이에 상관없이 출력 임베딩 수를 고정→ 다양한 길이의 오디오 샘플을 처리하는 데 유리)
-
6개의 16-head scaled dot-product attention layer와 perceiver resampler로 구성되어 고정된 임베딩을 생성
정리)
- 텍스트 →
BPE tokenizer(6681 token)→ 텍스트 토큰 - 몇 초의 음성 샘플 → Mel-spectrogram →
VQ-VAE→ audio codes →perceiver resampler→ 각 음성 샘플에 대한 32개의 1024-D 임베딩 - 1)텍스트 토큰 + 2)codes(condition) →
GPT-2 encoder→ autoregressive한 방법으로 다음에 오는 음성 신호를 예측
비영문 문자의 텍스트 처리 방식) 로마니안으로 변경 후 처리
- Korean →
hangul-romanize - Japanese →
Cutlet - Chinese →
Pypinyin
Decoder
HiFi-GAN vocoder를 기반으로 한 디코더로 26M의 파라미터를 가짐.
HiFi-GAN decoder는 GPT-2 encoder에서 추출된 latent vector를 입력받아, 실제 음성을 생성.
이때, VQ-VAE 코드를 입력으로 받지 않는 이유? :
VQ-VAE 출력은 많이 압축되어 발음이나 artifact의 문제가 생길 수 있다.
- VQ-VAE 출력은 고도로 압축된 오디오 신호로, 코드북에서 각 프레임을 특정 코드로 변환한 값이다. 이러한 과정은 높은 압축률로 인해 바로 오디오를 재구성하게 되는 경우 여러 문제가 발생할 수 있다.
- 발음 문제: 미세한 정보가 손실되거나 왜곡되어 발음 문제가 생길 수 있다.
- Artifact 발생: VQ-VAE의 코드북을 통해 오디오를 복원하는 과정에서, 음질저하나 아티팩트(왜곡된 소리)가 발생할 수 있다.
- VQ-VAE의 출력은 이산적 코드이므로, 연속성을 제공하지 못해 오디오 생성에서 자연스러움이 떨어짐.
- 이와 달리, GPT-2 인코더를 통해 추출된 잠재 공간에서는 더 많은 세부 정보(발음, 억양, 음색 등)를 담고 있어 더 자연스럽고 고품질의 오디오 생성이 가능해진다.
→ 따라서 GPT-2 encoder의 출력 값인 latent space의 값을 입력으로 사용하는 것!
GPT-2 encoder의 출력(latent vector) → HiFi-GAN decoder → 고해상도의 음성 신호
디코더에서 여러 단계의 업샘플링(upsampling)을 거쳐 최종 음성 신호가 되는 것!
🗯️ [ HiFi-GAN vocoder ]
고품질 음성 생성이 가능, 빠른 속도로 음성 생성 가능 → 실시간! 효율적인 학습
GAN기반. 디코더의 학습
Speaker Encoder
H/ASP 모델로 speaker embedding을 만든 후, 디코더에 condition으로 추가해준다.
(디코더의 upsampling layer들에 linear projection을 통해 스피커 임베딩을 추가해준다.
이 과정을 통해 화자의 음색과 스타일이 정확하게 반영될 수 있음)
speaker similarity를 학습하기 위해서는 SCL(Speaker Consistency Loss)를 추가한다.
이 loss를 추가하여 reference speaker의 특성을 가진 발화를 생성할 수 있게 되며,
다화자 환경에서 훈련된 모델이 음성 합성 시에 각 화자의 고유한 음질을 유지할 수 있음
🗯️ [ H/ASP ] - Clova Baseline System > Speaker Encoder https://arxiv.org/pdf/2009.14153
VoxCeleb 2 Dataset에서 Prototypical Angular Plus Softmax loss function을 사용하여 학습된 Speaker Encoder
VoxCeleb 1 Test Dataset에서 SOTA 성능.
TTS에서 특정 화자의 목소리를 모방하거나, 여러 화자의 목소리를 합성하는 데 사용 가능!
비슷한 Speaker Encoder 모델들: ECAPA-TDNN, d-vector, x-vector, …

XTTS Inference과정
→ VQ-VAE와 인코더는 22.5 kHz의 오디오 신호로 훈련하여 추론 속도를 높였고, 최종적으로 디코더에서 24 kHz의 고음질 오디오를 생성하기 위해 입력 신호를 선형적으로 업샘플링합니다.
Experiments
XTTS dataset
- 영어 데이터
LibriTTS-R: 541.7h,LibriLight: 1812.7h- audiobook-like data(internal)
- 영어를 제외한 언어 데이터
- Common Voice dataset(Public)
Experimental setup
다른 TTS 모델들은 대부분 monolingual이거나, 소수의 언어에 대해서만 multilingual이기 때문에 XTTS와 성능을 단순 비교하는데 적절하지 않다.
따라서, YourTTS 모델을 LibriTTS + XTTS dataset으로 학습시킨 후 비교를 진행했다.
(YourTTS와 XTTS의 1저자가 같음,, 그래서 굳이 YourTTS와의 비교를 많이 하는 것 같음)
실험 1. YourTTS 모델을 LibriTTS 영어 데이터셋(약 460 시간)으로만 학습
실험 2. YourTTS 모델을 XTTS 데이터셋(16개 언어, 2,700만 시간)으로 학습
실험 3. XTTS 모델을 XTTS 데이터셋(16개 언어, 2,700만 시간)으로 학습
Training Setup
- Coqui TTS repository
- NVIDIA A100 with 80GB GPUs
- YourTTS - single GPU
- XTTS - 4 GPUs
[ Training Loss ]
TTS 모델의 예측 음성이 실제 정답 음성과 얼마나 차이가 있는지 값
- text cross entropy
- mel spectrogram cross entropy
Results
기존 SOTA ZS-TTS 모델들과의 비교 : StyleTTS 2, Tortoise, YourTTS, HierSpeech++, and Mega-TTS 2
이 중, YourTTS는 XTTS와 동일한 데이터셋으로 학습시켜서 multilingual ZS-TTS에 대해서도 비교.
[ Evaluate Dataset ]
비교를 위해서는 FLORES+ 데이터셋의 의 240 문장을 사용.
[ Evaluate Metrics ]
🗯️
SECS
음성 합성 시스템이 얼마나 정확하게 소리를 생성하는지 측정하는 지표!
SECS가 높다는 것은, 초당 더 많은 오류를 발생시킨다는 것. 즉, 명료하지 않은, 알아듣기 어려운, 부정확한 발음의 TTS라는 것.
CER (Character Error Rate)
문자 오류율. 텍스트와 음성의 일관성.
생성된 음성을 텍스트로 변환했을 때, 원래 입력한 텍스트와 얼마나 일치하는지의 지표.
보통 문자 단위에서 잘못된 부분(삽입, 삭제, 치환)이 얼마나 발생했는지 비교하면서 계산하게 됨.
UTMOS (Universal Text-to-Speech Mean Opinion Score)
TTS가 생성한 음성의 자연스러움과 품질을 평가하는 지표.
사람이 주관적으로 자연스러움의 정도를 1~5점으로 점수를 주고, 평균 점수로 비교하는 방식.
5점에 가까울수록 실제 사람의 발화와 비교가 어려움
+) MOS(Mean Opinion Score)는 일반적으로 다양한 음성 기술(예: 음성 통화 품질 등)에서 사용하는 평가 방식
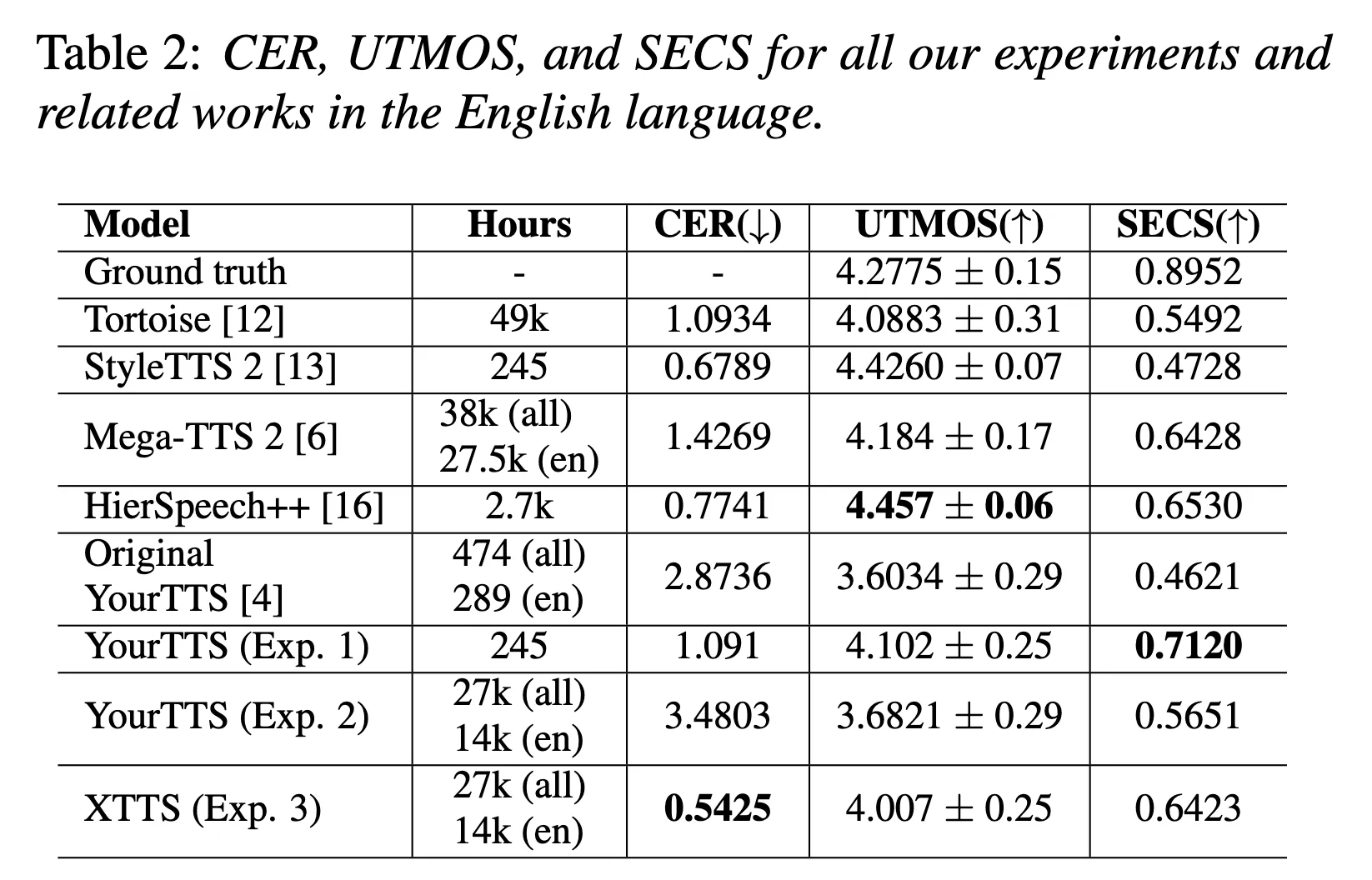
1. 영어 평가
XTTS는 CER이 매우 낮고, 우수한 성능을 보임. 영어 데이터에 대해서 UTMOS, SECS 점수에서도 꽤 좋은 결과를 얻음. → XTTS가 정확한 단어의 음성을 생성하면서도 발화오류가 적고 자연스럽다는 것.
2. multilingual 평가
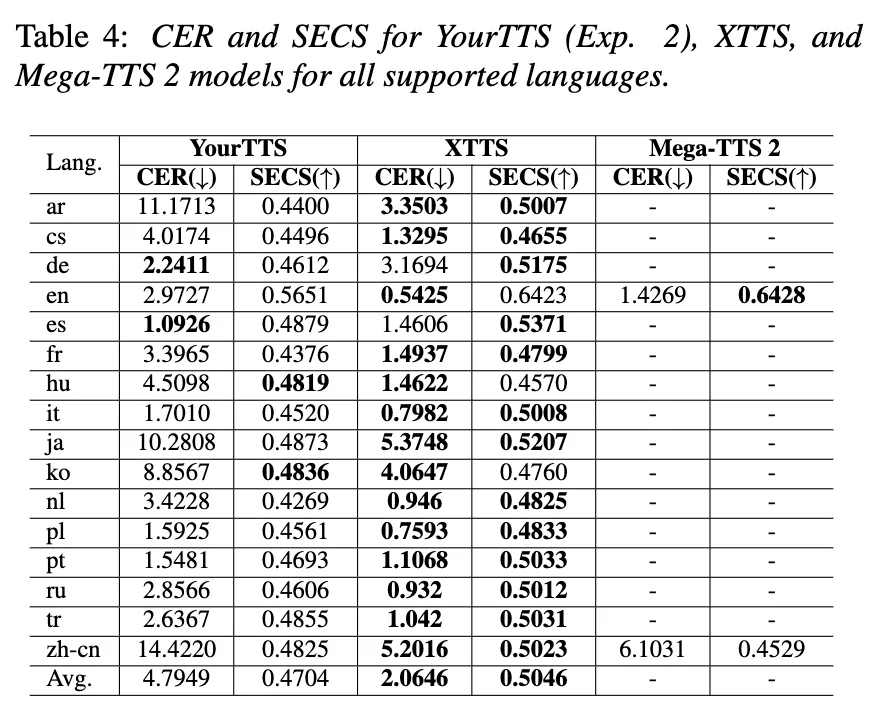
몇몇 언어에 대해서 YourTTS가 더 좋은 성능을 보이기는 하나, 대부분의 언어에서 XTTS가 CER, SECS 모두에서 더 좋은 성능을 보임.
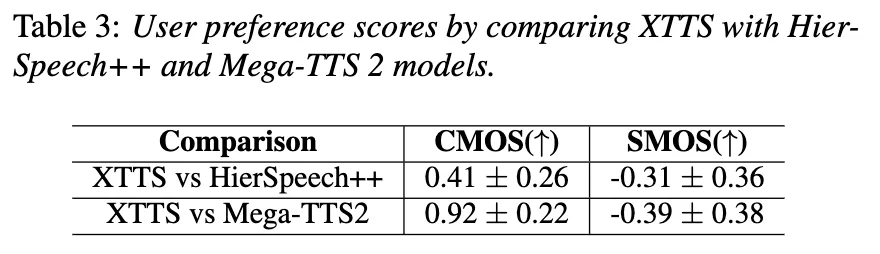
XTTS가 naturalness, acoustic quality 측면에서 더 사용자에게 선호되는 결과를 보인다.
그러나 합성된 음성이 원래 음성과는 크게 유사하지 않다 ← 복잡하고 많은 multilingual 학습을 진행했기 때문이라고 말함
- CMOS(Comparative Mean Opinion Score): 음성의 자연스러움, 음질, 인간 같은 음성을 평가
- SMOS(Speaker Similarity Mean Opinion Score): 합성된 음성이 원래 스피커와 얼마나 유사한지를 평가
XTTS는 모든 언어에 대해서 가장 우수한 성능을 보인다.
그러나 한국어에 대해서는 SECS가 조금 떨어지는 결과
