Pre-requisite
- Probability
distribution, random variable, expectation, conditional probability, variance, density
- Linear algebra
matirx multiplication, eigenvector
- Basic programming
python, Numpy
수업에서는 ML의 basic 을 배우고, 수학적 증명을 하지는 않지만 유도는 한다
Definition of ML
Arthur samuel: ML 은 컴퓨터가 프로그래밍 되지 않은 채로 스스로 학습 할 수 있는 능력을 부여하는 연구분야다.
Tom Mitchell: 과제 (task)T 를 성능 (performance measure)P 로 측정했을때 경험 experience E 가 향상되면 잘 정의된 ML 이다.
ex. 체커게임
T : play a game
P : winning rate + number of performance, 즉 측정기준
E : games 즉 데이터.
Taxonomy(분류) of ML
supervised learning
unsupervised learning
reinforcement learning
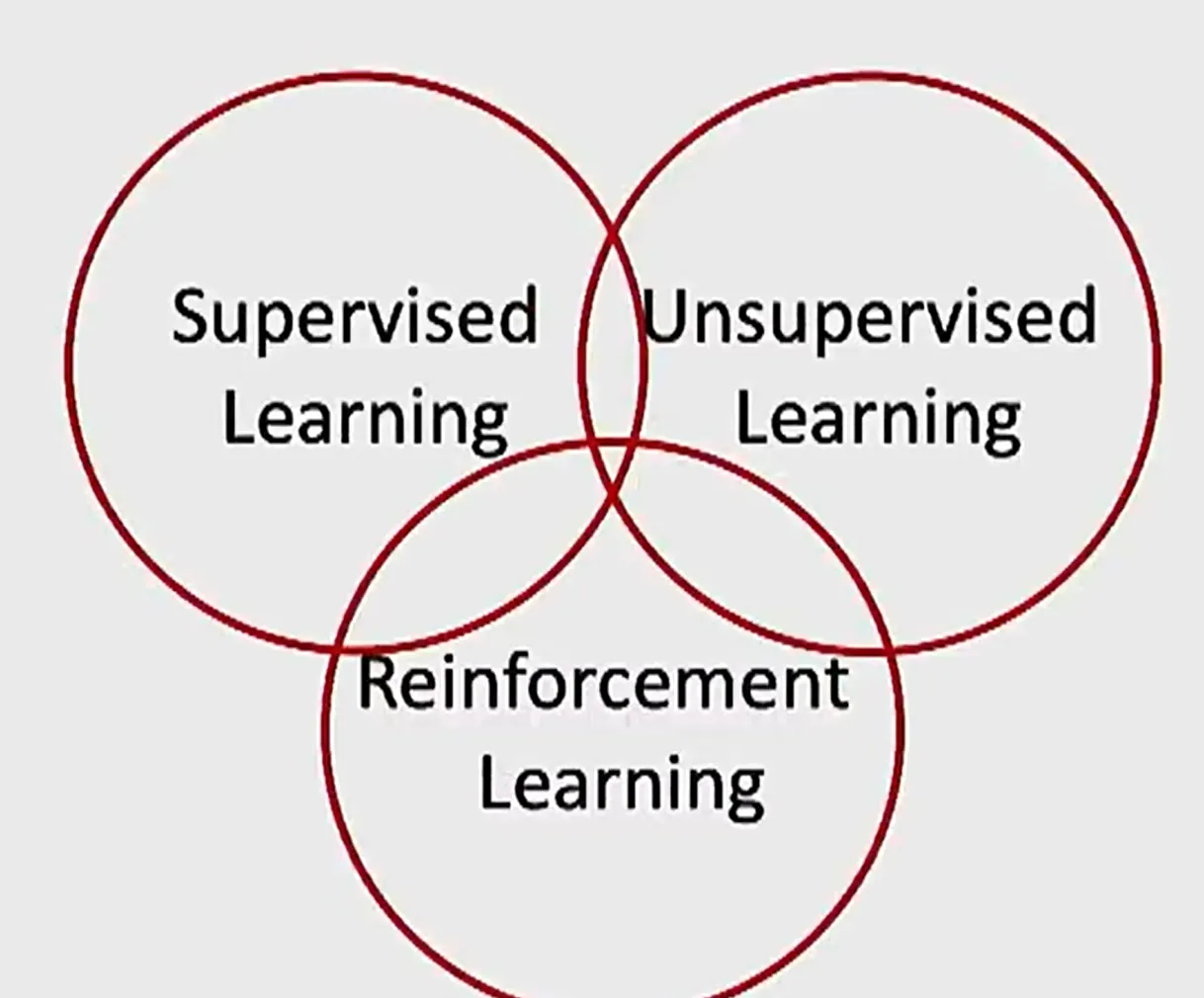
⇒ 종종 몇몇 task 들은 여러종류의 ml 을 동시에 필요로 하기도 한다.
Supervised learning
: 답이 있는, label이 있는 데이터를 가지고 training 시키는 학습법
ex) house price prediction
(x,y) 데이터셋들을 training 한다. x는 features, input 이고 y는 output, label, supervision 이라고 부른다
새로운 x(집크기) 값이 주어졌을때 y(집가격) 값을 예측하는것이 목표. 즉 데이터들이 어떤 경향을 가지는지(그래프처럼) 예측하는 것이다.
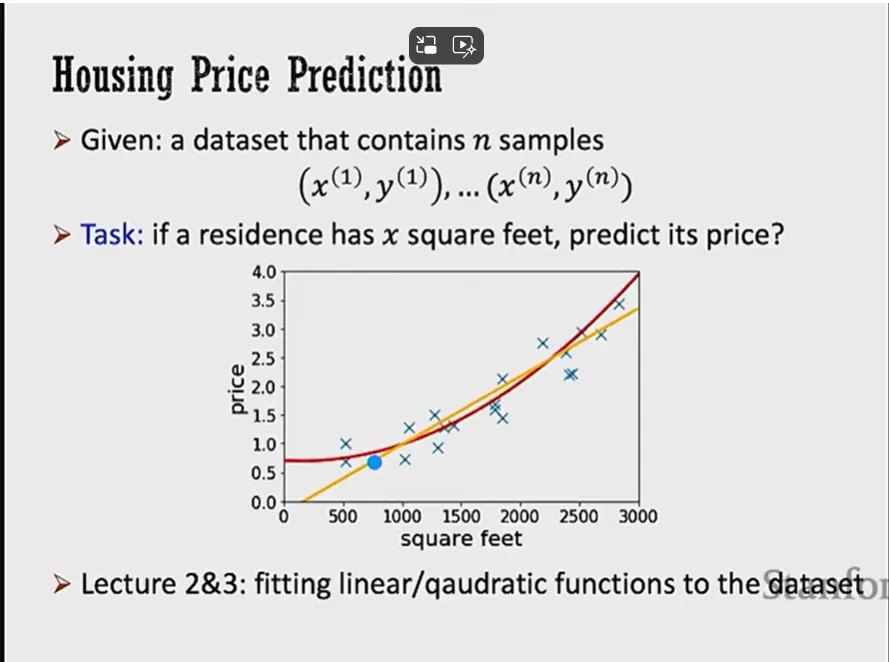
BUT,, 실제상황을 분석할때는, 값을 도출해내기 위해 1개의 특징이 아닌 여러 특징들을 고려한다.
그러면 입력 차원이 커지는 것!!


-
Regression (회귀)
: y 값, 즉 output 값이 연속적이면 회귀분석이다.
-
Classification(분류)
: y 값, 즉 output 값이 그룹으로 분류되는것 처럼 이산적이면 분류분석이다.
ex)
computer vision 분야에서는
1) 이미지 분류(x는pixel, y는 물체)
2) 물체 감지(x는 raw pixel, y는 bounding box의 두 끝점)를 다룬다
NLP 분야에서는
번역(x는 입력문장 y는 번역문장)⇒ 얘도 classification 에 속한다
Unsupervised learning
: 답이 없는, label 이 없는 데이터를 가지고 training 시키는 학습법.
Clustering
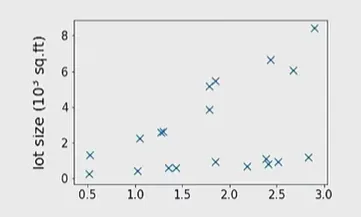
이렇게 라벨 없이 주어진 데이터를 보고
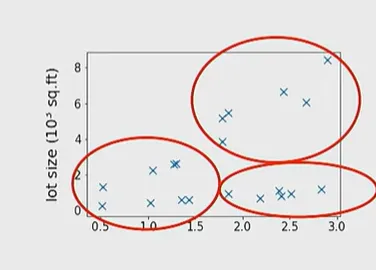
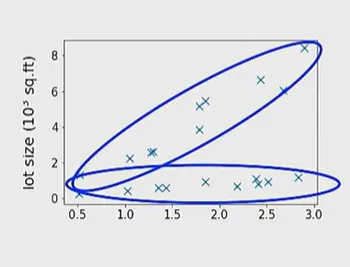
이처럼 그룹화 시키는것. 빨간색보다는 파란색이 좋은 그룹화의 예시다
ex)
-
Clustering genes
사람들이 약에 어떻게 반응하는지 분석 할 수 있으면 이에 맞는 약을 처방해 줄 수 있다
-
Latent semantic analysis
사전에 나오는 단어의 빈도를 분석해 묶으면 인사이트를 도출 할 수 있다


왼쪽 결과를 가지고 그룹화 시키면 오른쪽이 된다
데이터 셋에 있는 주제의 종류를 파악 할 수 있게된다.
Word embedding
단어를 수치화 해야하기 때문에 각각의 단어를 vector 로 표현했다.
이렇게 되면 비슷한 단어들끼리 그룹화도 되고, 관계를 정의하는 단어들도 두 점 사이의 vector로 정의할 수 있게 되기 때문이다. 또한 단어 사이의 계층도 알 수 있다!
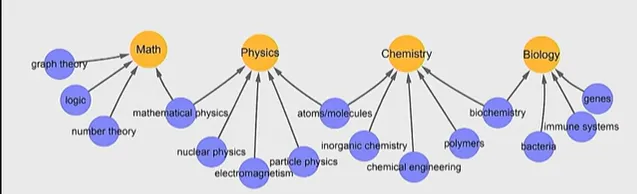
Large Language Model
GPT-3 와 같은 대규모 언어 모델.
정보를 주고 질문할수도, 알파벳을 정렬시키거나 계산 물어보기 등을 할 수 있다
Reinforcement Learning
: 위 두 학습과 다르게 prediction이 아닌 연속된 decision을 하는 학습. 피드백을 통해 데이터를 학습시킨다. 주로 순차적인 결정을 내릴때 학습시킨다.
ex) 알파고, 로봇이 오른쪽으로 걷는 방법,
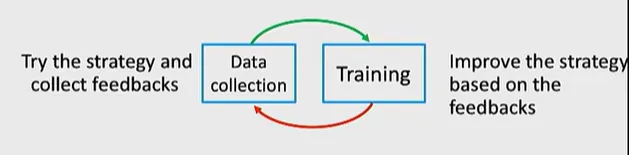
훈련과 데이터 수집 사이에 루프가 존재한다.
Deep learning basics
: 뉴런 네트워크 이용하는 학습
등등,,, 나중에 자세히 배우거임!
