LGBM의 특징, 시계열 모형 학습시 주의사항
GBM vs XGB vs LGBM vs CATB
출처 : https://wyatt37.tistory.com/5
GBM -> XGB.
GBM은 강력한 알고리즘이었지만 단점이 많았습니다. 그렇기 때문에 XGB는 GBM이 가지고 있지 않은 많은 부분을 개선해서 나왔습니다. 그만큼 XGB는 여전히 많이 쓰이고 있고, 여전히 강력합니다.
XGB가 GBM으로부터 개선한 부분은 드라마틱합니다.
1) 병렬 처리 지원: 본래 부스팅은 알고리즘의 특성상 순차적으로 모델을 생성하고 학습합니다. 그래서 GBM은 학습 속도가 매우 느립니다. 그런데 XGB는(그리고 이후의 모든 모델이) 병렬 처리를 지원합니다. 따라서 학습 속도가 매우 빨라졌습니다.
2) 가지치기 방식 변화: 다른 부스팅 알고리즘들은 Leaf-wise (Best-first) 방식, 즉 보통 Information Gain을 기준으로 가지를 뻗쳐나갑니다. Information Gain이 없다면 굳이 가지를 뻗쳐나갈 이유가 없습니다. 그러나 XGB는 반대로 지정된 최대 깊이(max_depth)까지 분할 한 다음, 이득이 없는 가지를 쳐냅니다. 때로는 Information Gain이 없는 가지 밑에도 Information Gain이 있는 가지가 생겨날 수 있다는 가정입니다. (물론 XGB도 하이퍼 파라미터 튜닝으로 Leaf-wise를 선택할 수 있습니다.)
XGB -> LGBM
XGB에서 LGBM으로 넘어오면서 변경된 부분은 앞서 언급한 Leaf-wise 방식을 들고 나왔다는 것입니다. LGBM은 GOSS(Gradient-based One-Side Sampling)을 채택합니다. 부스팅이 오차를 기반으로 해당 데이터를 증폭시켜 샘플링될 확률을 높이고, 그로 인해 오차 부분을 더 잘 학습하도록 설계되어 있다는 것을 잘 아실 겁니다.(wyatt37.tistory.com/1) GOSS방식은 Information Gain이 적은 가지의 데이터를 증폭시켜서 데이터 분포를 많이 바꾸지 않더라도 훈련이 잘 되지 않은 부분에 초점을 잘 맞출 수 있게 하였습니다.
이러한 방식은 학습 속도를 더 많이 개선하고, 성능 또한 높일 수 있었습니다. 다만 데이터가 적을 경우 과대 적합될 가능성이 있기 때문에 데이터가 많아야 합니다.
LGBM -> CATB
CATB는 이름부터 Categorical Boosting Machine인 것처럼 범주형 변수를 잘 처리하기 위한 모델이라는 것을 알 수 있습니다. 트리 기반 모델들은 범주형 변수를 정수로 인코딩해서 학습시키면 연속형 변수라고 인식하기 때문에 인코딩 방식이 매우 중요합니다. CATB는 범주형 변수에 대한 인코딩 방식으로 원핫인코딩(One-hot Encoding)과 Advanced Mean Encoding을 사용합니다. 범주형 변수가 많지 않은 경우에는 원핫인코딩을 사용하지만, 범주형 변수가 많은 경우에는 Advanced Mean Encoding을 사용합니다. 그러나 이러한 인코딩은 모델의 학습 속도를 늦추는 단점이 있습니다.
또한 CATB는 샘플링 방식에서 MVS(Minimum Variance Sampling) 방식을 가지고 나왔습니다. 최소 분산 샘플링이라고 하는 이 방식은 샘플링 가중치를 분할 단계가 아닌 트리 단계에서 준다고 합니다.
시계열 모형 학습시 주의사항
출처 : https://diane-space.tistory.com/316
이런 방식으로 우리는 함수가 100% 예측가능하진 않지만, 반응변수가 예측치에 의존한다는 것과, 반응 변수에 대해 이전의 예측치에 대한 시차 (lags)의 효과로 유발된 시간 의존성 (time dependency) 이 있다는 것을 확실히 할 수 있습니다.
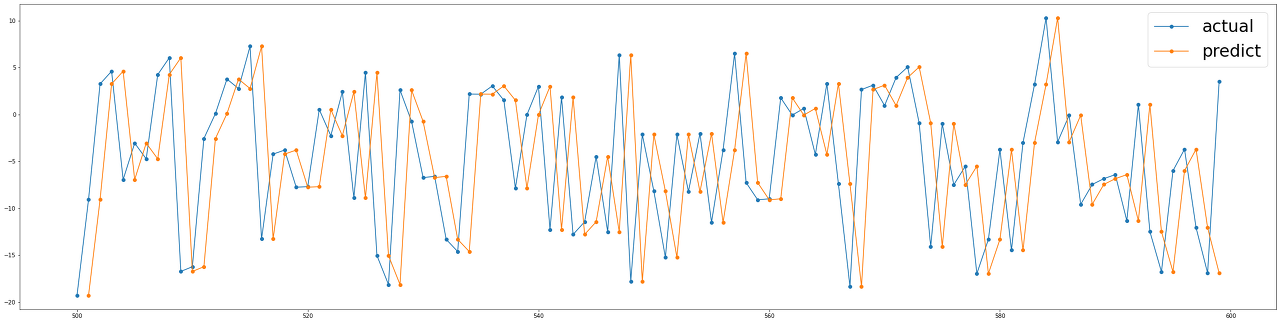
결론 우리는 이미 다가오는 결과를 비교할 가치가 있습니다.
우리는 주어진 현재 값을 예측 값으로 고려하는 단순한 룰을 적용해보았습니다. 시계열에서 반응 변수의 값이 더욱 안정적이라면(stable) (a.k.a stationary) , 이 방식은 때때로 ML 알고리즘보다 놀랍게도 더 나은 성능을 보여줄 것입니다. 이런 경우에 데이터의 지그재그(zig-zag)는 악명이 높아 예측력이 떨어지는 것으로 이어집니다.
출처 : https://brunch.co.kr/@gimmesilver/72
예측 모델을 이용해 어떤 서비스를 만든다면 무엇을 예측할 것인지 예측 대상과 예측 모델을 통해 얻고자 하는 목표가 명확해야 합니다. 예측 대상은 레이블을 결정하고, 목표는 모델을 어떻게 활용할 것인지 실행 전략과 모델 평가 방법을 결정합니다. 따라서 최대한 구체적으로 정의해야 합니다.
예를 들어, '주가를 정확히 예측하겠다.' 는 좋은 정의가 아닙니다. 적어도 어느 시점의 주가를 예측할 것인지가 정의되어야 합니다. 특히, 대개의 경우 실전 서비스에서 '정확한 예측' 은 좋은 목표가 아닙니다. 여기서 얘기하는 '정확한 예측'이란, accuracy, F1 score, AUC, RMSE 등의 (우리가 흔히 논문에서 사용하는) 지표가 높은 값을 기록하는 것을 의미합니다. 이런 지표들이 비록 모델의 예측 성능을 비교하기 위해 많이 사용하는 방법이지만, 현실 서비스에서 목표를 정의할 때는 그리 적절한 방법이 아닙니다.
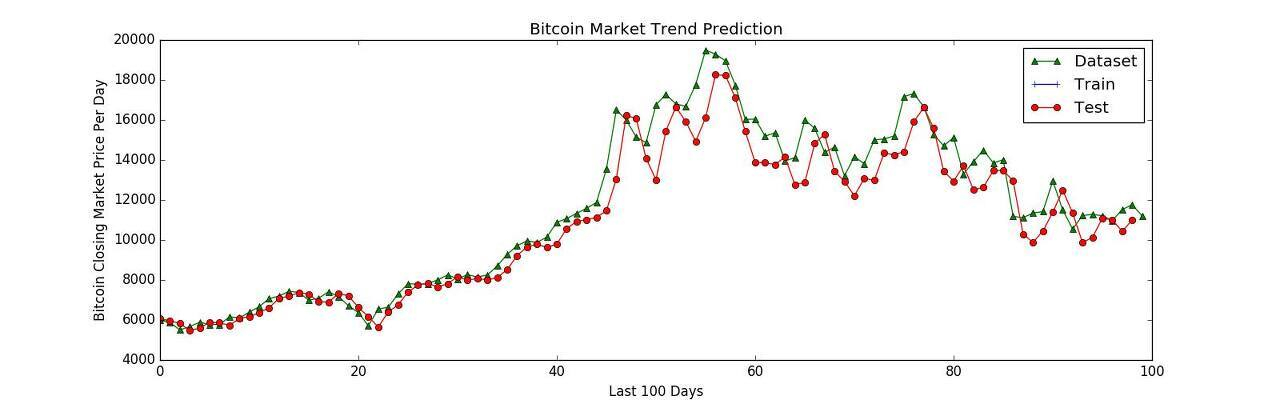
실전에서는 실행 전략을 고려한 목표를 정의해야 합니다. 적어도 '오늘보다 내일 주가가 오른다고 예측되면 매수하고, 내린다고 예측되면 매도하는 전략을 취할 경우 기대 이익이 최대가 되는 모델을 만들겠다.' 정도가 되어야 합니다.
